DeepSeek 最新论文成果,站在字节豆包的肩膀上


DeepSeek 现在是毫无疑问的顶流,不管是开源模型还是发表论文,都会第一时间引起大家围观。DeepSeek 最近关于 mHC 和 Engram 的两篇文章,已经有很多解读,而且大家发现,这两篇论文背后都有一些来自字节的工作基础。
其实这非常正常,科研本来是站在前人肩膀上做一些调优和缝补的工作,有些是提出想法,有些是实验论证,也有些是工程落地。这些工作都有价值,都在一砖一瓦地构建学术体系。
今天就梳理一下这两个技术的演进过程,一个是关于模型的「骨架」,另一个是关于模型的「记忆」。
从 RC 到 HC,再到 mHC,重塑「信息骨架」
在 2015 年之前,深度神经网络面临「退化问题」:网络并非越深越好,当层数堆叠到一定程度,模型的性能反而会下降。因为在深层网络中,梯度在漫长的反向传播路径中或消失、或爆炸。
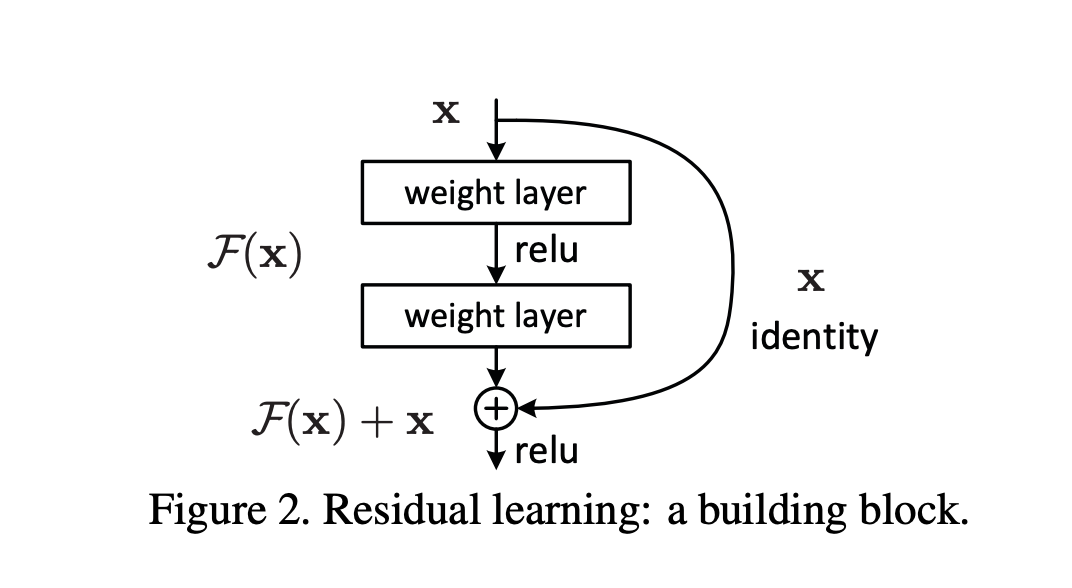
然后,何恺明提出了残差连接 (Residual Connection),以一种简洁优雅的方式解决了这个问题。
核心思想就是 y = F(x) + x,不再强迫网络层去学习一个完整的映射 H(x),而是去学习输入 x 与输出 y 之间的「残差」F(x)。
Image
这个种「跳跃连接」的方式,为信息和梯度提供了一条跨层的「高速公路」,使得训练成百上千层的超深网络成为可能。自此,残差连接成为从 CNN 到 Transformer 几乎所有现代 AI 模型的底层骨架。

Image
ResNet 的论文《Deep Residual Learning for Image Recognition》引用已经超过了 30 万,是引用量最高的 AI 论文。作为比较,开启了大模型时代的 Transformer 论文《Attention is all You Need》,现在的引用量刚过 21 万。
由此可见 ResNet 的江湖地位。
不过,残差虽然简洁优雅,但并不完美。因为它只是一条「单行道」,信息在网络中以单一向量的形式流动,带宽受限于模型的隐藏层维度,随着模型规模的扩大,信道逐渐成为了网络的瓶颈。
于是,在 2024 年的时候,字节豆包团队大胆地对经典发起了挑战。
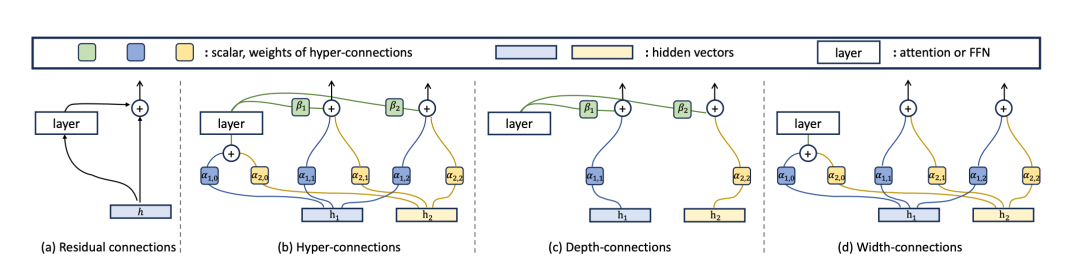
字节提出了「超连接」(Hyper-Connections, HC)架构,核心思想是,将单行道扩建成一座拥有 n 条车道(n 为扩展率)的「立交桥」。它不再只传递单一的向量 x,而是维护一个由 n 个并行信息流组成的「超隐藏矩阵」 H。
HC 通过引入可学习的「宽度连接」和「深度连接」矩阵,让网络可以动态地决定:
- 1. 层内:这 n 条车道的信息如何混合,以形成当前计算单元(如 Attention 或 FFN)的输入。
- 2. 层间:计算单元的输出如何与原始的 n 条车道信息结合,传递给下一层。
Image
通过这种设计,网络甚至可以自主学习出不同的层间拓扑结构,比如某些层并行计算,某些层串行计算,从而打破了传统残差连接固定的「串行+跳跃」模式。实验也证明,HC 在几乎不增加计算量的情况下,显著提升了模型性能。
那么,代价是什么呢?
简单来说,立交桥虽然扩展了车道,但缺乏「交通管制」。
HC 为了追求表达的灵活性,打破了 ResNet 的「恒等映射」基石。HC 可学习的连接矩阵是无约束的,就意味着信号在经过多层累积后,可能会被急剧放大或衰减,直接导致训练的不稳定性。
再然后,就是 DeepSeek 最新提出的 mHC(Manifold-Constrained Hyper-Connections) 了,虽然论文发表的时间还短,但这是一篇十分 solid 的工作。
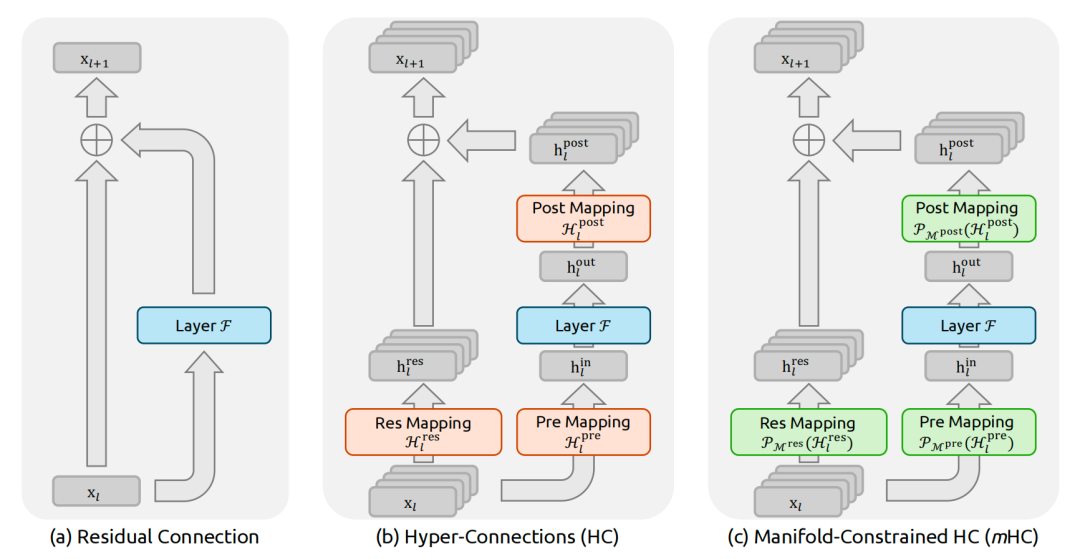
DeepSeek 做的事情,就是在字节 HC 立交桥的基础上,设计一套稳定、高效的「智能交通系统」,做法就是给 HC 中连接矩阵,套上一个「流形约束」。
具体而言,他们强制要求这个连接矩阵必须是一个「双随机矩阵」,这种矩阵的性质是:所有元素非负,并且每行、每列的元素之和都严格等于 1。
Image
这种做法的巧妙之处在于:
- 1. 信号守恒:当信息流通过一个双随机矩阵进行变换时,其输出本质上是输入信号的一种「凸组合」(加权平均)。这意味着信号的总能量在传递过程中是守恒的,从根本上杜绝了信号爆炸或消失的风险。
- 2. 组合封闭性:双随机矩阵的乘积依然是双随机矩阵。这意味着无论网络堆叠多深,整个系统的稳定性都得到了保证。
同时,DeepSeek 还为这套优雅的理论提供了坚实的工程支撑。他们手写了底层的 CUDA 算子,并通过算子融合、选择性重计算、流水线并行优化等一系列系统工程,将 mHC 带来的额外训练时间开销压缩到了 6.7%。
总结一下,何恺明修了一条信息高速公路,字节团队将其拓宽为超级立交,DeepSeek 为立交桥设计并安装了稳定高效的智能交通系统,使其真正具备了在大规模模型上安全高效传递信息的能力。
从 N-gram 到 Over-Encoding,再到 Engram,优化「记忆范式」
与模型的信息骨架并行的,是关于模型如何「记忆」的探索。
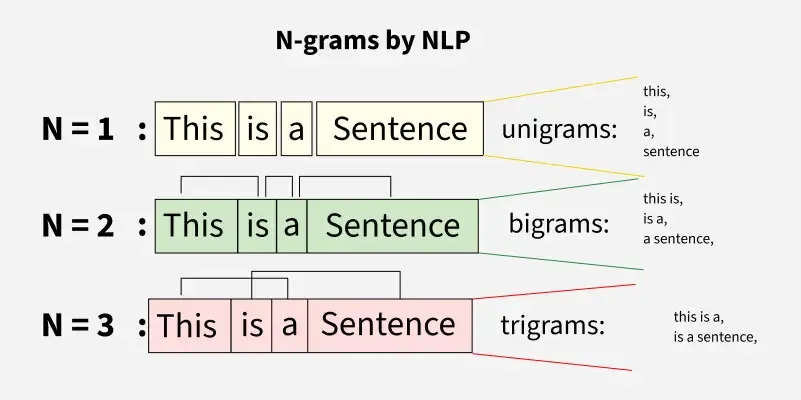
在神经网络时代之前,N-gram 曾是 NLP 模型的主力。它通过统计语料库中连续 N 个词的共现频率来预测下一个词。
Image
N-gram的优点在于,它擅长捕捉局部、固定的文本模式,本质上是一种基于查找表的「统计式记忆」,缺点就在于数据稀疏性问题和无法捕捉长距离依赖。在深度学习浪潮中 N-gram 逐渐被取代。
不过,N-gram 的思想并没有被完全抛弃。字节 Seed 团队在之前的「OverEncoding」中,将 N-gram 融入了现代 Transformer 架构。
简单来说,模型的输入端和输出端不必对称。我们可以极大地扩展输入词表的规模,用它来容纳海量的 N-gram 组合,而保持输出端仍然预测单个词。由于输入端的 Embedding 查找是稀疏操作,这样做几乎不增加模型的计算量。
Over-Encoding 通过层级化的 N-gram 嵌入,将输入词表规模扩展到了千万级别。
Seed 团队通过实验发现了对数线性定律:模型的训练损失会随着输入词表规模的对数增长而稳定下降。这意味着,一个仅有 4 亿参数、但配备了巨大 N-gram 输入词表的模型,其性能可以媲美一个 10 亿参数的基线模型。
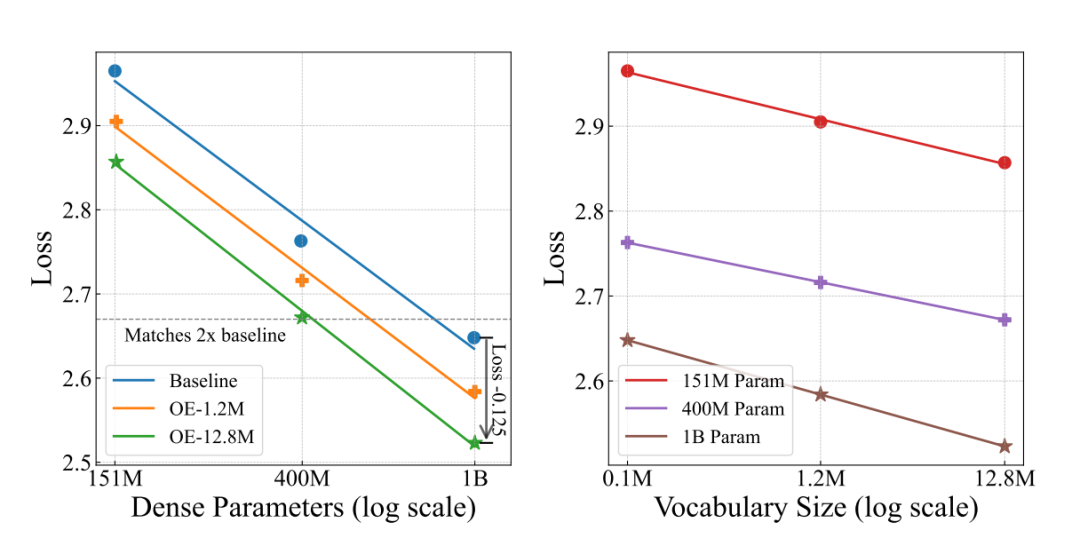
Image
这相当于用「记忆」(更大的查找表)换取了等效的「算力」(更少的模型参数),证明了「记忆缩放」是一条独立且有效的性能提升路径。
但其局限在于,这种记忆是静态的、无差别的,所有 N-gram 信息被简单地相加融合进输入表示,缺乏上下文的动态选择。
DeepSeek 的 Engram 模块,正是在 Over-Encoding 等工作的基础上,将「静态记忆增强」升级为了「动态条件记忆」。
Engram 的核心观点是,大模型的工作负载可以分为两部分:
- 1. 组合推理:需要消耗算力,由 MoE 等「条件计算」模块负责。
- 2. 知识回忆:对静态、固定模式(如实体名、常用短语)的重构,这部分工作应该交给更高效的「条件记忆」模块。
为此,DeepSeek 设计了一套完整的系统:
- 1. 查找:它构建了一个巨大的、可扩展的 N-gram 哈希嵌入表(参数可达百亿甚至千亿),通过 O(1) 复杂度的查找操作直接获取静态知识。
- 2. 门控:与 Over-Encoding 最本质的区别是,Engram 会利用当前层的隐藏状态(即上下文信息)作为查询(Query),与查找到的 N-gram 记忆进行一次「匹配」,生成一个门控信号。只有与当前上下文相关的记忆才会被激活并融入到后续计算中,不相关的则被抑制。
- 3. 解耦:由于查找地址是确定性的,Engram 可以被设计为与主计算流程解耦的独立模块。其巨大的参数表可以被卸载到成本更低的 CPU 内存甚至 SSD 上,只在需要时异步加载,从而绕过昂贵的 GPU 显存限制。
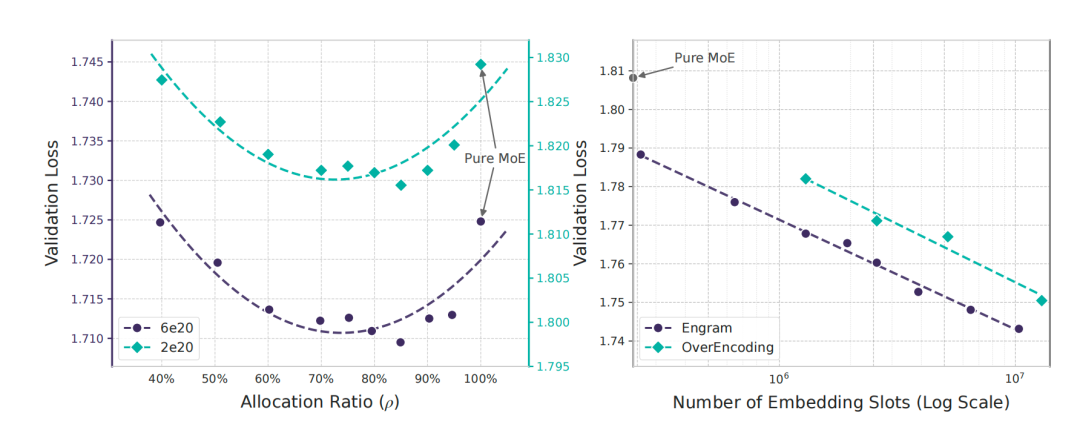
Image
DeepSeek 通过实验发现了「计算」与「记忆」资源分配的 U 型定律:无论是纯粹的计算(100% MoE)还是纯粹的记忆(100% Engram),都非最优解。将大约 20%-25% 的稀疏参数预算从计算专家再分配给记忆模块,才能达到最佳性能。
小结
总的来说,mHC 和 Engram 体现出相似的演进路线,一种相互学习、相互启发的螺旋迭代。
我感觉计算机领域的研究还是比较 open 和友好的。大家其实也不确定哪个点的优化会带来范式变化,一些真正有效的做法也许需要时间和机遇,比如谷歌当年就严重低估了 Transformer,才把大模型的先发机会让给了 OpenAI,反而 OpenAI 现在不怎么发论文了。
字节 Seed 和 DeepSeek 团队,都敢于挑战传统的架构和范式,都愿意投入资源在更大规模参数的模型上验证,更可贵的是,都愿意把思考过程和实践结果,分享给整个学术界。
所以,学术研究不是零和博弈,而是让思想流动、碰撞、演进的过程,新的理念配合上扎实的工程验证,前人的探索成为后人的阶梯。
这也是中国 AI 研究和生态日趋成熟的一个缩影,这种合作共赢、不懈优化、持续攀登的精神,比任何一个单一的模型、论文,都更让人振奋。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-01-18,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号