WeClaw 是什么:把微信接到 Claude、Codex 和 OpenClaw 的 AI Agent 桥

WeClaw 是什么:把微信接到 Claude、Codex 和 OpenClaw 的 AI Agent 桥

山行AI
发布于 2026-04-09 21:08:32
发布于 2026-04-09 21:08:32
WeClaw 是什么:把微信接到 Claude、Codex 和 OpenClaw 的 AI Agent 桥
如果说过去很多 AI 编程工具解决的是“在终端里怎么更高效地和模型协作”,那
WeClaw想解决的,就是另一个非常现实的问题:能不能把微信直接变成 AI Agent 的对话入口,让 Claude、Codex、Gemini、Kimi、OpenClaw 这类代理,不用额外 App,就能在微信里收发消息、图片和文件?
WeClaw 给出的答案是肯定的。
它把微信和多种 AI 代理连接起来,充当一层桥接服务。用户在微信里发消息,后端把这些消息转发给选定代理;代理返回的文本、Markdown 图片、文件链接等内容,再由 WeClaw 转换后发回微信。
这个项目的定位很清晰: 它不是另一个大模型本身,而是一座“微信 <-> AI Agent”之间的协议与消息桥。
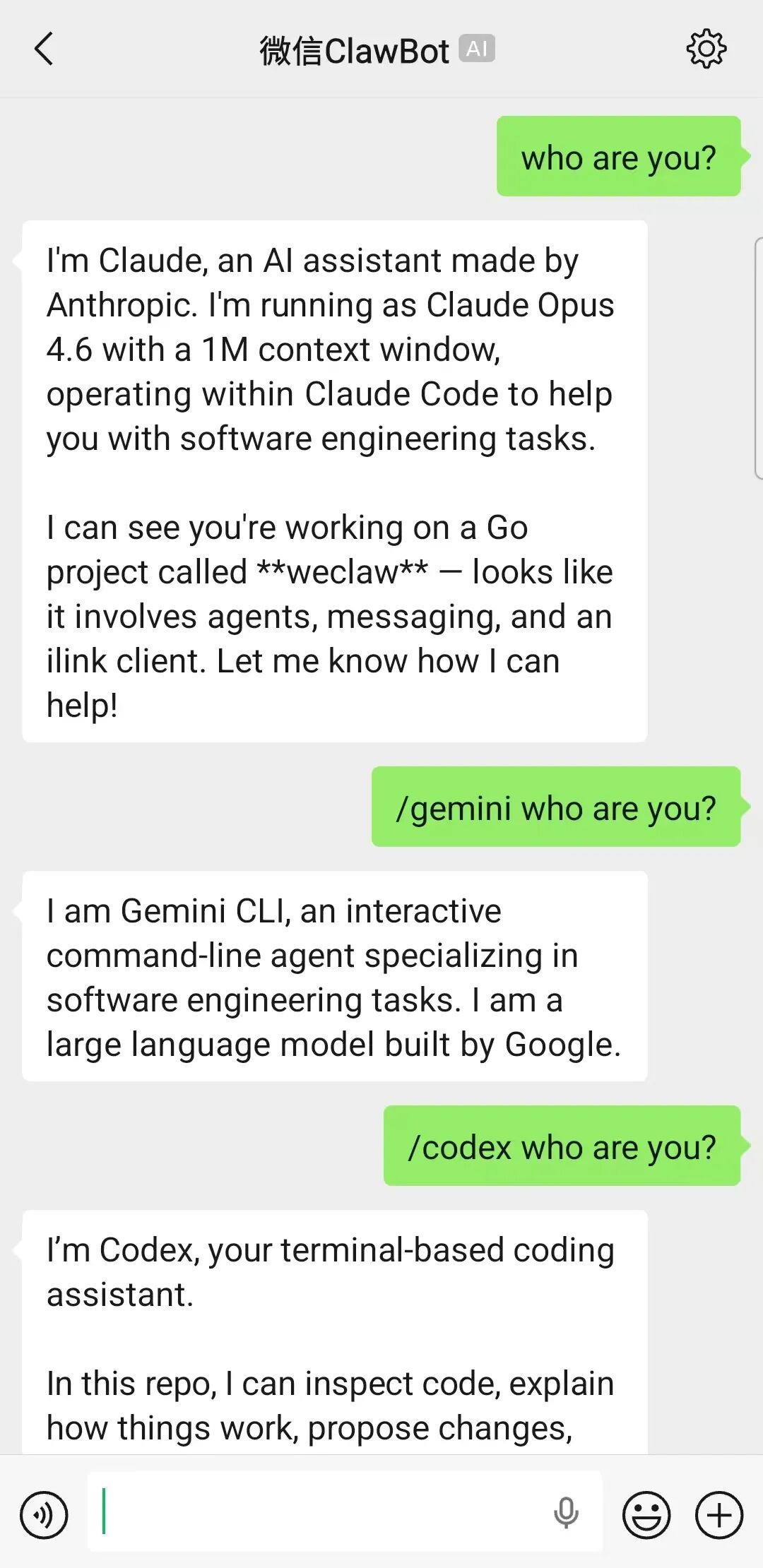
WeClaw 预览界面
README 中给出的预览图,展示了它把微信消息接入 AI 代理后的基本使用效果。
一、WeClaw 想解决什么问题
很多人已经习惯在终端里用 Claude Code、Codex、Gemini CLI 或 OpenClaw。 但这些工具有一个共同问题:
- 很强,但入口偏技术;
- 很适合开发者自己用,不一定适合“随手就发一条消息”的场景;
- 如果你希望把 AI 代理接到微信这个高频入口上,往往要自己搭消息桥、管会话、处理媒体、兼容不同代理协议。
WeClaw 试图把这些脏活和重活收起来。
从 README 的描述看,它的核心价值主要有三点:
- 把微信变成一个统一的 AI Agent 消息入口;
- 同时兼容多种代理实现方式,而不是只绑定单一模型;
- 自动处理 Markdown、图片、文件和主动发送等细节,让用户真正能用起来。
二、上手为什么这么快
README 的 Quick Start 非常短,核心只有两步:
curl -sSL https://raw.githubusercontent.com/fastclaw-ai/weclaw/main/install.sh | sh
weclaw start
第一次启动后,它会自动完成一整套初始化动作:
- 展示微信登录二维码;
- 扫码登录;
- 自动探测本机已安装的 AI 代理;
- 把配置写入
~/.weclaw/config.json; - 开始接收并回复微信消息。
如果需要挂多个微信账号,还可以继续用:
weclaw login
这套体验之所以顺滑,关键就在于它不要求用户先手动拼装太多中间层。 项目默认假设的不是“你要做二次开发”,而是“你要尽快把微信连到现成代理上”。
三、它真正有意思的地方,是同时支持三种 Agent 接入模式
README 里最值得关注的一部分,是它对代理接入方式做了明确分层。
WeClaw 并不是把所有代理都当成一类程序,而是分成三种模式:
1. ACP 模式
ACP 是一种长驻子进程模式,通过 stdio 上的 JSON-RPC 通信。
README 里明确说,这是最快的一种方式,因为它可以复用同一个进程和会话。
适合的代理包括:
- Claude
- Codex
- Kimi
- Gemini
- Cursor
- OpenCode
- OpenClaw
这个模式的关键优势,不只是快,而是天然适合“连续对话、持续上下文”的场景。 对于微信这样的消息式入口来说,这一点尤其重要。
2. CLI 模式
CLI 模式更简单:每条消息启动一个新进程处理。
README 里提到它支持通过 --resume 恢复会话,适配像下面这种命令式代理:
claude -pcodex exec
这种模式虽然没有 ACP 高效,但兼容性更广,也更容易在现有工具链上快速落地。
3. HTTP 模式
HTTP 模式面向 OpenAI 兼容的 Chat Completions API。 README 里特别举了 OpenClaw 的 HTTP fallback 作为例子。
这意味着即使某个代理不是本机 CLI,也不是 ACP 进程,只要能暴露一个兼容 API,WeClaw 依然能把它接到微信里。
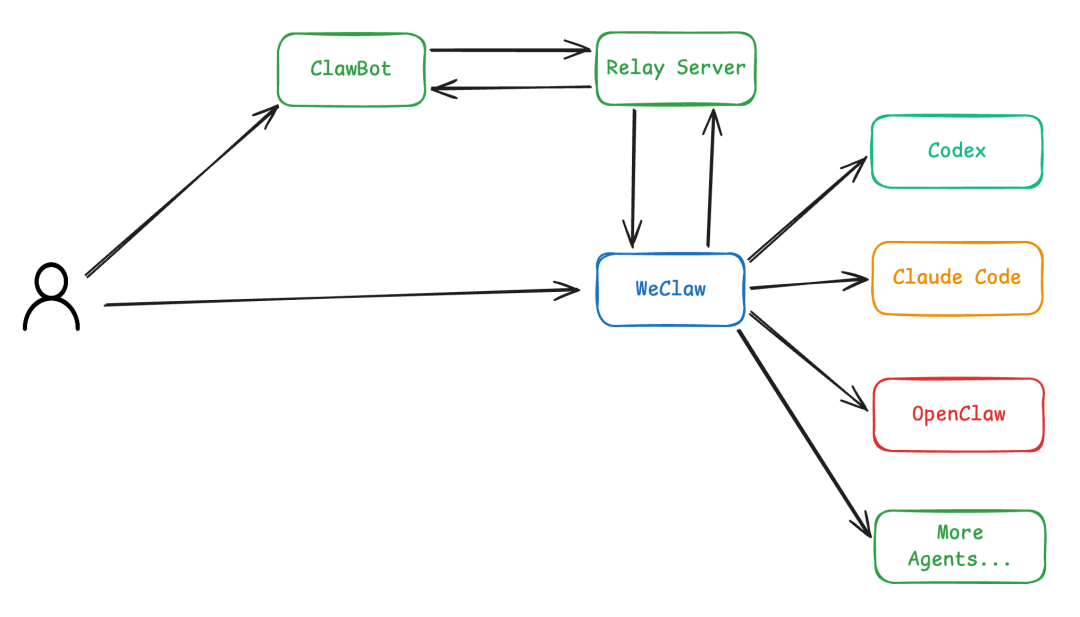
WeClaw 架构图
README 中的架构图展示了微信、WeClaw、不同 Agent 模式之间的桥接关系。
项目还做了一个很实用的默认策略:
当同一个代理同时具备 ACP 和 CLI 两种方式时,自动优先选 ACP。
这个默认值很合理,因为它直接优先了更好的交互性能和会话复用体验。
四、微信里怎么和不同代理说话
WeClaw 没有把微信端做成复杂控制台,而是用了很轻的聊天命令方式。
README 中列出的主要命令包括:
hello发给默认代理;/codex write a function指定把消息发给某个代理;/cc explain this code用别名发给代理;/claude切换默认代理;/status查看当前代理信息;/help查看帮助。
同时它还内置了一组别名:
/cc->claude/cx->codex/cs->cursor/km->kimi/gm->gemini/ocd->opencode/oc->openclaw
而且默认代理切换是持久化到配置里的,也就是说服务重启后不会丢。
这个设计很聪明。 它没有试图在微信里复制一个“终端 UI”,而是尽量用用户已经熟悉的聊天命令完成代理切换和分发。
五、Markdown 图片和媒体消息,是它非常实用的一层能力
很多“消息桥”项目的问题在于,文本能发,媒体就开始崩。
WeClaw 在这方面做得比较完整。
README 里明确提到:
- 如果代理返回的是 Markdown,里面带有图片链接
; WeClaw会自动提取图片 URL;- 下载图片;
- 上传到微信 CDN;
- 然后把它作为图片消息发回微信。
这意味着代理不需要了解微信媒体协议本身,只要按正常 Markdown 返回图片,桥接层就会代为处理。
README 还提到,文本回复里的 Markdown 也会被自动转成更适合微信展示的纯文本,例如:
- 去掉代码围栏;
- 链接只保留展示文字;
- 去掉粗体和斜体标记。
对最终用户来说,这一步很重要。 因为微信不是 Markdown 渲染器,如果原样把 Markdown 扔过去,体验会非常差。
六、它不只支持“被动回复”,还支持主动发消息
这也是 WeClaw 一个很实用的特性。
你不需要等用户先来找你,服务也可以主动向指定微信用户发消息。
README 里同时给了 CLI 和 HTTP API 两种入口。
例如 CLI:
weclaw send --to "user_id@im.wechat" --text "Hello from weclaw"
weclaw send --to "user_id@im.wechat" --media "https://example.com/photo.png"
weclaw send --to "user_id@im.wechat" --text "Check this out" --media "https://example.com/photo.png"
HTTP API 则默认跑在:
127.0.0.1:18011
也就是说,它不仅能做“聊天机器人入口”,也可以被其他系统当成一个微信发送网关来调用。
这个能力特别适合:
- 通知型消息;
- 自动报告;
- 运营触达;
- AI 代理主动回传任务结果。
七、配置方式并不复杂,但保留了足够扩展性
README 里的配置文件示例放在:
~/.weclaw/config.json
结构很直观,核心是:
- 一个默认代理
default_agent - 一个
agents对象 - 每个代理声明自己的类型、命令或 endpoint、模型等参数
例如:
- Claude 可以配置成 ACP;
- Codex 也可以配置成 ACP;
- OpenClaw 可以配置成 HTTP endpoint。
README 同时提供了几个环境变量:
WECLAW_DEFAULT_AGENTOPENCLAW_GATEWAY_URLOPENCLAW_GATEWAY_TOKEN
从工程角度看,这种设计有两个好处:
- 配置文件足够简单,适合直接上手;
- 同时又保留了通过环境变量切换默认行为的能力,适合部署环境和自动化脚本。
八、它也考虑到了“权限确认在微信里不好处理”的现实问题
这部分 README 很实在。 很多 CLI 代理默认会在执行工具调用时要求交互式权限确认,但这种确认流程在微信里显然不太适合。
所以 WeClaw 支持在 agent 配置中加 args,为不同代理加上绕过交互确认的参数,例如:
- Claude CLI:
--dangerously-skip-permissions - Codex CLI:
--skip-git-repo-check
README 也明确给了警告:
这些参数会关闭一部分安全检查,只有在你理解风险的前提下才应该开启。
这部分让我觉得项目比较靠谱,因为它不是只讲“怎么能跑起来”,也明确告诉你“为了在微信里跑起来,你到底牺牲了什么”。
九、后台运行、系统服务和 Docker 都已经考虑到了
WeClaw 不是一个只适合临时 demo 的工具,README 里已经把常见运行方式铺好了。
例如后台模式:
weclaw start
weclaw status
weclaw stop
weclaw start -f
日志默认写到:
~/.weclaw/weclaw.log
系统服务方面,它还给了:
- macOS 的
launchd - Linux 的
systemd
如果你偏向容器化部署,也有 Docker 用法,包括:
- 登录;
- 启动;
- 注入 OpenClaw 的 HTTP 配置;
- 查看日志。
README 里也解释得很清楚:
- 如果走 ACP 或 CLI,容器里必须有对应代理二进制;
- 如果走 HTTP agent,则可以直接工作。
这类说明非常关键,因为很多人第一次容器化这类桥接服务时,最容易踩的坑就是“服务本体在容器里,但代理不在容器里”。
十、我对 WeClaw 的一个简化理解
如果用一句更直白的话来总结:
WeClaw本质上是在做“微信版的 AI Agent 路由器 + 消息桥 + 媒体适配层”。
它把几个平时很容易散落在不同脚本里的能力,揉进了一起:
- 微信登录和会话承载;
- 多代理路由;
- ACP / CLI / HTTP 三类协议适配;
- Markdown 与媒体消息转换;
- 主动发送;
- 后台常驻与部署。
从产品形态看,它最适合两类人:
- 已经在用 Claude、Codex、OpenClaw 等代理,希望把能力接入微信的人;
- 想把微信作为 AI 服务入口、通知入口、运营入口的人。
结语
WeClaw 这种项目有意思的地方,不在于它提出了多么全新的模型能力,而在于它把“怎么把现有 AI 代理接入一个高频沟通渠道”这件事做得足够工程化、足够可落地。
如果你已经有一套代理系统,下一步想解决的是:
- 如何接入微信;
- 如何切多个代理;
- 如何处理 Markdown 图片和媒体消息;
- 如何支持主动触达;
那 WeClaw 会是一个非常值得参考的实现。
它不是在重新发明代理,而是在把代理真正带进实际沟通场景。
参考来源
- 仓库主页:https://github.com/fastclaw-ai/weclaw[1]
- README:https://raw.githubusercontent.com/fastclaw-ai/weclaw/main/README.md[2]
- 中文文档:https://github.com/fastclaw-ai/weclaw/blob/main/README_CN.md[3]
引用链接
[1]https://github.com/fastclaw-ai/weclaw
[2]https://raw.githubusercontent.com/fastclaw-ai/weclaw/main/README.md
[3]https://github.com/fastclaw-ai/weclaw/blob/main/README_CN.md
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-24,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号