OpenClaw Agent 架构深度解析:AI 网关的设计哲学

OpenClaw Agent 架构深度解析:AI 网关的设计哲学

架构精进之路
发布于 2026-04-10 15:22:26
发布于 2026-04-10 15:22:26
导读:当 LangChain 还在解决"如何调用工具"时,OpenClaw 已经在思考"如何让 AI 助理安全地住进你的消息流"。本文从架构师视角,拆解一个自托管 AI 网关的核心设计决策。
一、问题的起点:为什么现有方案不够用
2024 年,几乎所有开发者都面临同一个困境:
想在 WhatsApp/Telegram 上有个 AI 助理,但不想数据出境、不想 API Key 托管、不想被厂商锁定...
LangChain 能帮你组装 LLM 调用链,但它不解决:
- 消息渠道怎么接?(自己写 Baileys?grammy?)
- 会话状态怎么持久化?(Redis?文件?)
- 多用户怎么隔离?(每个用户一个 Chain?)
AutoGPT 能自主执行任务,但它不解决:
- 消息来了怎么触发?(轮询?Webhook?)
- 执行结果怎么回传?(WebSocket?SSE?)
- 敏感操作怎么管控?(审批流?沙箱?)
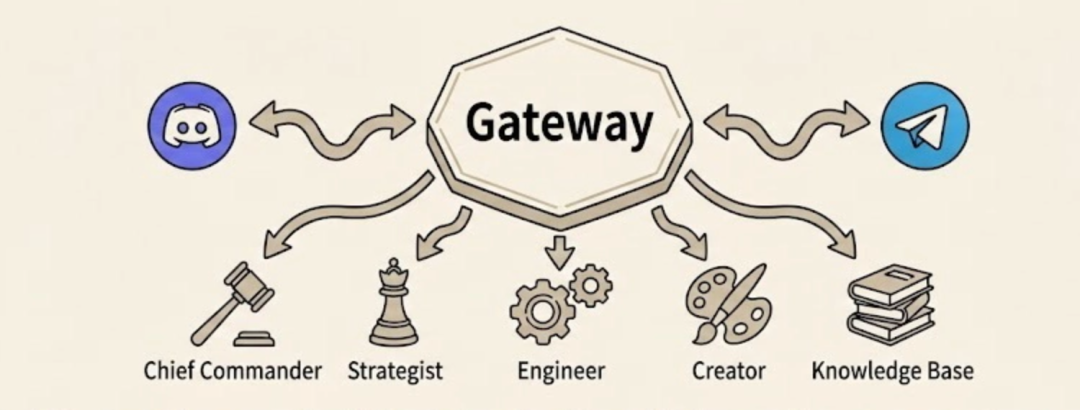
OpenClaw 的选择是:做一个"AI-Native 的消息网关",而不是"给消息系统加个 AI 插件"。
这里的顺序很重要,前者从 AI 出发设计架构,后者只是在旧瓶里装新酒。
二、核心架构:三层模型

2.1 网关层:单一进程,多路复用
设计决策:一个 Gateway 进程管理所有渠道连接,而不是每个渠道一个服务。
// Gateway 启动后,所有渠道收敛于一个 WebSocket 端口
// 默认:ws://127.0.0.1:18789
// 客户端连接示例
{
type: "req",
method: "connect",
params: {
auth: { token: "xxx" },
device: { id: "macbook-pro", platform: "darwin" }
}
}为什么这样设计?
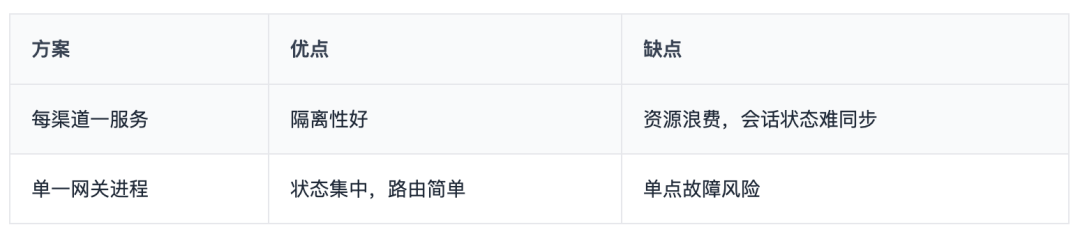
OpenClaw 的选择基于一个判断:个人/小团队场景下,运维复杂度比水平扩展更重要。
2.2 执行层:嵌入式 Agent,非子进程
关键区别:OpenClaw 不 spawn 一个 pi 子进程,而是直接用 SDK 创建会话。
// 传统方式(子进程)
const child = spawn('pi', ['--prompt', message]);
child.stdout.on('data', handleOutput);
// OpenClaw 方式(嵌入式)
const { session } = await createAgentSession({
cwd: workspaceDir,
model: 'claude-sonnet-4-20250514',
tools: openClawTools, // 自定义工具集
sessionManager: SessionManager.open(sessionFile)
});
await session.prompt(message);收益:
- 工具可以动态注入(消息工具、渠道特定工具)
- 事件可以实时订阅(流式输出、工具执行状态)
- 会话可以精确控制(压缩、分支、恢复)
三、Agent Loop:从消息到行动的完整链路
sequenceDiagram
participant Channel
participant Gateway
participant Agent
participant Tools
Channel->>Gateway: 消息到达
Gateway->>Gateway: 入队 (Session Lane)
Gateway->>Agent: 创建会话 + 注入上下文
Agent->>Agent: 构建系统提示 (Skills + Bootstrap)
Agent->>Agent: 调用 LLM
Agent->>Tools: 执行工具 (exec/read/browser...)
Tools-->>Agent: 返回结果
Agent-->>Gateway: 流式输出 (assistant/tool 事件)
Gateway-->>Channel: 回复消息
Gateway->>Gateway: 持久化会话 (JSONL)3.1 队列设计:防止消息风暴
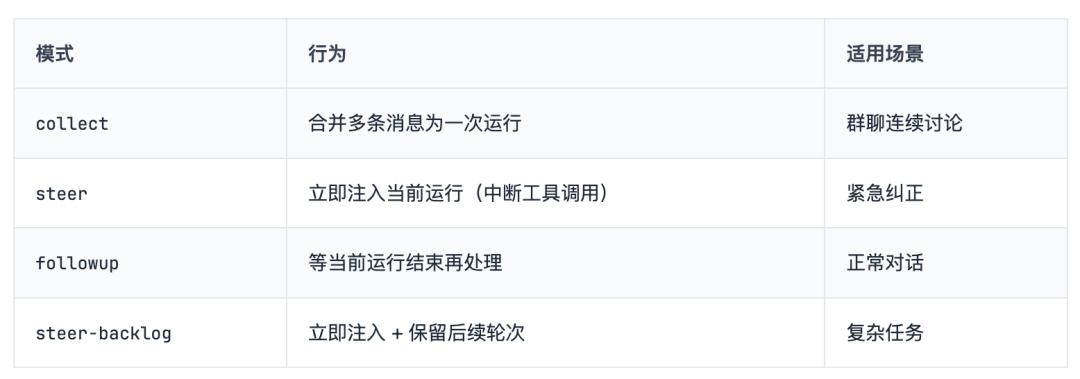
问题:群聊里连续 10 条消息,要不要触发 10 次 Agent 运行?
OpenClaw 的答案:Session Lane + Global Lane 双层队列。
// Session Lane:每会话一个队列,保证串行
// Global Lane:所有会话共享,控制并发上限
// 配置示例
{
agents: {
defaults: {
maxConcurrent: 4 // 最多 4 个会话并行执行
}
},
messages: {
queue: {
mode: "collect", // 合并多条消息为一次运行
debounceMs: 1000, // 等待 1 秒静默期
cap: 20, // 最多排队 20 条
drop: "summarize" // 溢出时生成摘要
}
}
}队列模式对比:
3.2 会话持久化:JSONL 文件树
不是数据库,不是 Redis,是 JSONL 文件。
{"id":"turn-1","parentId":null,"role":"user","content":"帮我查天气"}
{"id":"turn-2","parentId":"turn-1","role":"assistant","content":"好的..."}
{"id":"turn-3","parentId":"turn-2","role":"tool","name":"exec","result":"25°C"}为什么选 JSONL?
- 可追溯:每条消息有 ID 和 ParentID,支持分支对话
- 可压缩:自动压缩长对话,保留关键摘要
- 可恢复:进程崩溃后直接读取文件继续
- 可审计:纯文本,方便调试和合规检查
四、Skills 系统:可扩展的能力边界
4.1 技能加载优先级
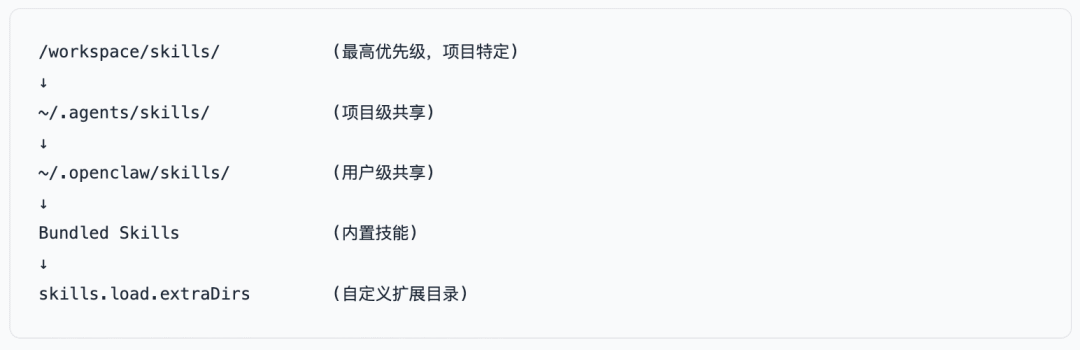
设计哲学:越靠近项目的配置优先级越高,允许局部覆盖全局。
4.2 运行时过滤 (Gating)
Skill 不是加载就能用,要通过"门禁检查":
---
name: feishu-bitable
description: 飞书多维表格管理
metadata: {
"openclaw": {
"requires": {
"bins": ["node"],
"env": ["FEISHU_APP_ID"],
"config": ["channels.feishu.enabled"]
}
}
}
---检查项:
- 二进制文件是否存在(bins)
- 环境变量是否配置(env)
- 配置项是否启用(config)
- 操作系统是否匹配(os)
收益:技能可以声明依赖,系统自动判断是否可用,而不是运行时才报错。
4.3 环境注入:Scoped 而非全局
// Agent Run 开始前
process.env.FEISHU_APP_ID = "app_123"; // 注入技能所需环境变量
// Agent Run 结束后
process.env.FEISHU_APP_ID = original; // 恢复原始环境关键设计:环境变量注入是每次 Agent Run 的临时行为,不是全局修改。这避免了技能之间的环境污染。
五、与传统后端的对比
5.1 架构范式差异维度
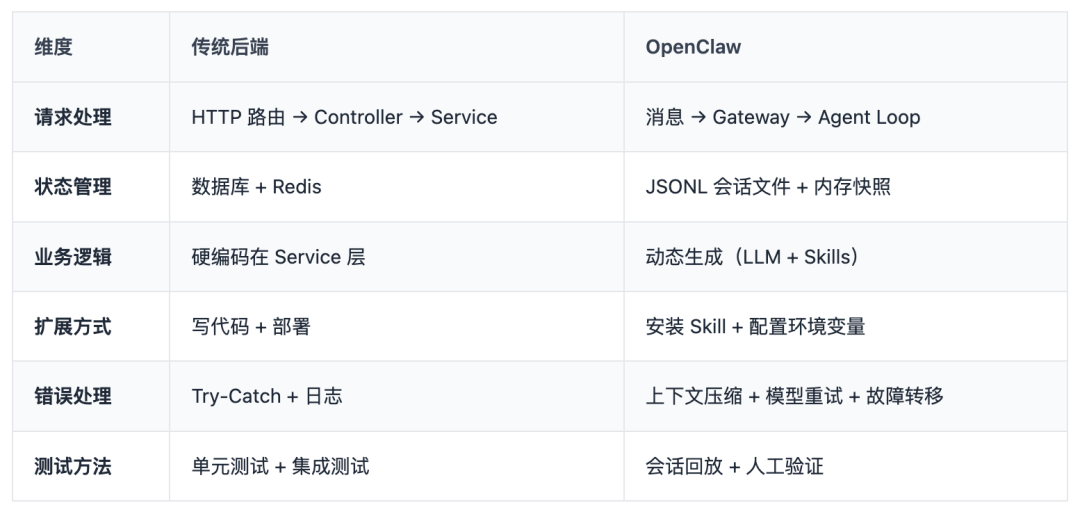
5.2 一个具体场景对比
需求:用户发消息"查一下北京天气,然后发到群里"
传统后端实现:
// Controller
@PostMapping("/weather")
public Response checkWeather(@RequestBody Message msg) {
String weather = weatherService.getWeather("北京");
messageService.sendToGroup(msg.getGroupId(), weather);
return Response.ok();
}
// 需要:API 路由、参数校验、服务层、消息队列、错误重试...OpenClaw 实现:
# SKILL.md 定义能力
当用户查询天气时,使用 `weather` 工具获取数据
当用户要求发送消息时,使用 `message` 工具发送
# 系统自动处理
- 意图识别(LLM)
- 工具调用(weather → message)
- 错误重试(自动)
- 结果回复(流式输出)本质区别:传统前者是确定性流程,OpenClaw 是概率性生成。
六、AI-Native 架构的思考
6.1 什么是 AI-Native?
不是"加了 LLM 的系统",而是从 LLM 的特性出发重新设计架构。
LLM 的核心特性:
- 概率性输出(不是 deterministic)
- 上下文窗口有限(需要压缩/截断)
- Token 成本敏感(需要精简提示)
- 工具调用延迟高(需要异步/流式)
OpenClaw 的应对设计:
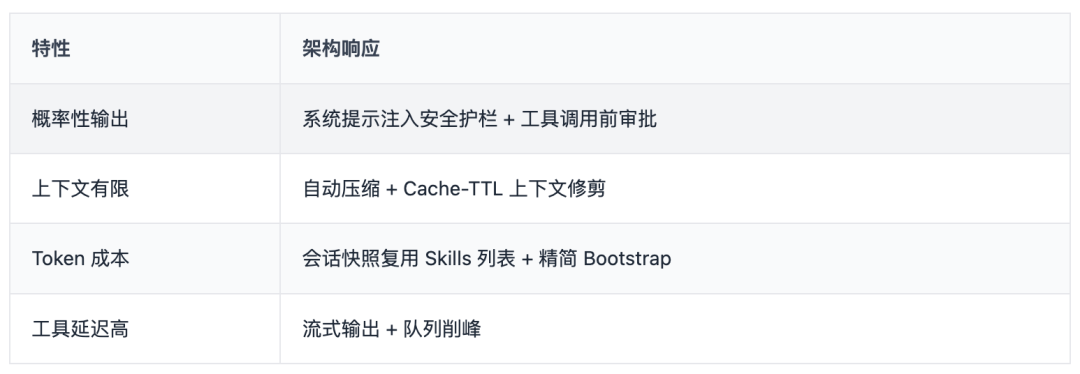
6.2 信任模型的重构
传统系统:代码是可信的,输入是不可信的 → 验证输入
AI 系统:代码是可信的,AI 输出也是不可信的 → 验证输出
// OpenClaw 的工具审批机制
{
tools: {
exec: {
approval: "always", // 所有 exec 命令需要人工审批
allowlist: ["git", "npm test"], // 或者白名单命令
denylist: ["rm -rf", "curl | bash"] // 或者黑名单命令
}
}
}设计哲学:AI 可以提议,人类做决定。
6.3 会话即状态
传统后端:状态在数据库,会话是无状态的
AI 网关:会话本身就是状态,它包含了:
- 对话历史(用户说了什么)
- 工具执行记录(AI 做了什么)
- 上下文窗口(AI 还记得什么)
- 压缩摘要(AI 忘记了但应该记得的)
这意味着:
- 会话文件是核心资产,需要备份和版本控制
- 会话隔离是安全边界,不同用户/渠道不能串
- 会话压缩是性能关键,决定 Token 消耗和响应速度
七、关键总结
7.1 架构决策清单
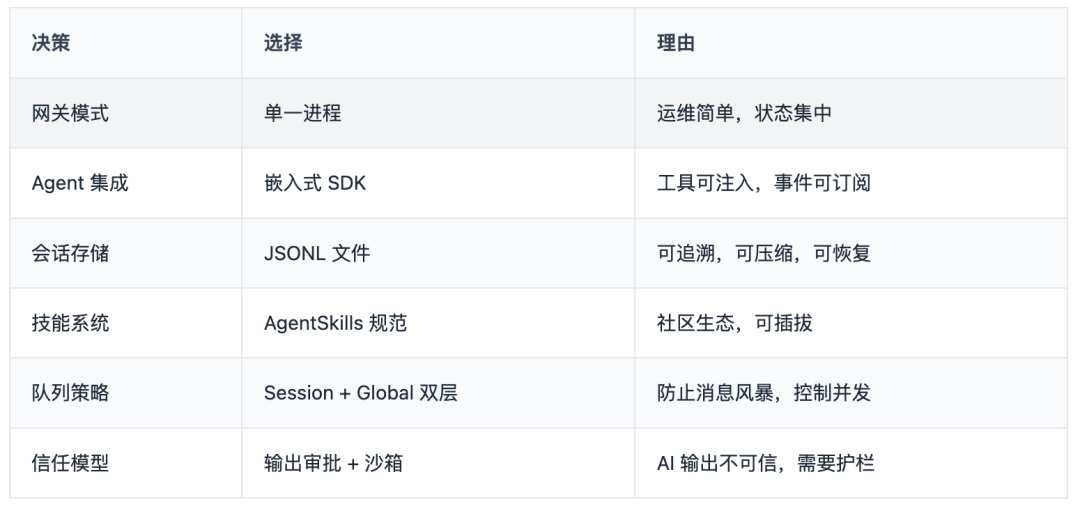
7.2 适用场景
适合用 OpenClaw:
- 个人/小团队自托管 AI 助理
- 需要多渠道统一入口
- 对数据隐私有要求
- 愿意接受概率性系统
不适合用 OpenClaw:
- 高并发企业级应用(>1000 并发会话)
- 需要 100% 确定性输出
- 已有成熟消息中台
- 无法接受 LLM 成本波动

OpenClaw Agent 架构深度解析:AI 网关的设计哲学
结语
OpenClaw 不是一个"更好的 LangChain",它是一个不同的东西:
LangChain 问:"如何用代码调用 LLM?" OpenClaw 问:"如何让 LLM 住进你的消息流,同时保持可控和可信?"
这个问题没有标准答案。但自托管、多渠道、Agent 原生的设计方向,值得架构师们思考。
最后送上一句:
在 AI 时代,最好的架构不是最优雅的,而是最能适应不确定性的。
参考资料:
- OpenClaw 官方文档:https://docs.openclaw.ai
- GitHub 源码:https://github.com/openclaw/openclaw
- 技能市场:https://clawhub.ai
- 社区 Discord:https://discord.com/invite/clawd
END
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-03,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号