Nat. Commun. | RANGE:用全局编码突破图神经网络的长程信息瓶颈

Nat. Commun. | RANGE:用全局编码突破图神经网络的长程信息瓶颈

DrugOne
发布于 2026-04-10 17:17:04
发布于 2026-04-10 17:17:04
论文原题:Extending the range of graph neural networks with global encodings 发表期刊:Nature Communications,2026,17:1855 DOI:10.1038/s41467-026-69715-3 通讯作者:Frank Noé、Cecilia Clementi(Freie Universität Berlin / Rice University) 开源代码:https://github.com/ClementiGroup/range
目录
- 1. 研究背景与动机
- 2. 核心问题:GNN 的局域性困境
- 3. RANGE 框架设计
- 4. 数学形式化描述
- 5. 实验设计与数据集
- 6. 主要实验结果
- 7. 与竞争方法的系统对比
- 8. 分子动力学模拟验证
- 9. 可解释性分析
- 10. 局限性与未来方向
1. 研究背景与动机
1.1 机器学习力场(MLFF)的崛起
过去十年,图神经网络(GNN)和消息传递神经网络(MPNN)在学习图结构数据方面取得了突破性进展,成为分子物理、社会科学和经济学建模多体相互作用的主流工具。在分子科学领域,GNN 被广泛应用于机器学习力场(Machine-Learned Force-Fields, MLFF)的开发:
- • 原子级力场(Atomistic FF):节点对应原子,直接预测量子化学精度的能量与力,代表工作包括 SchNet、PaiNN、MACE、NequIP 等;
- • 粗粒化力场(Coarse-Grained FF):节点对应"珠子"(bead),在粗粒化层面建模,代表框架有 MLCG 等。
这些 MLFF 通常以密度泛函理论(DFT)计算的能量和力作为训练标签,在精度和效率上远超传统经验力场。
1.2 长程相互作用的物理重要性
然而,分子体系中存在两类关键的长程相互作用,对体系的结构与动力学起决定性作用:
相互作用类型 | 物理起源 | 特征范围 | 典型场景 |
|---|---|---|---|
静电相互作用 | 电荷分布、极化效应 | 数十埃甚至更远 | 带电分子、蛋白质-配体对接、离子通道 |
色散力(van der Waals) | 瞬时偶极-诱导偶极 | 数至十余埃 | 非极性分子堆积、疏水效应、界面稳定性 |
在生物膜界面、低介电常数溶剂等环境中,静电作用尤为显著,长程效应可对集体构象变化产生决定性影响(Rossi et al., 2015;Stöhr & Tkatchenko, 2019)。
2. 核心问题:GNN 的局域性困境
2.1 截断半径与感受野
在标准 MPNN 框架中,每个节点的邻域定义为以截断半径 为界的球形区域。经过 轮消息传递后,节点的感受野半径为 。为控制计算成本,主流 MLFF 普遍采用 Å,这意味着捕捉 30 Å 以上的长程效应需要超过 6 层消息传递——然而这会引发两个经典病理:
2.2 过平滑(Oversmoothing)
随着消息传递层数增加,不同节点的表示趋于一致,节点特征的区分度指数级衰减。这是因为多次聚合本质上等价于图上的低通滤波,使节点嵌入收敛到全图的平均表示,丧失局部结构信息。
2.3 过度压缩(Oversquashing)
图中存在"拓扑瓶颈"(topological bottleneck)时,指数增长的信息量被压缩进有限维度的节点嵌入中,导致远程节点的信息在传递过程中被严重稀释乃至完全丢失(Alon & Yahav, ICLR 2021)。本文的实验数据(图 3)清晰地展示了这一现象:随截断半径增大,基线模型的预测误差很快饱和,无法继续受益于更大的感受野。
2.4 计算代价的平方律陷阱
若直接将截断半径扩展至覆盖整个体系,对 个粒子的体系,需要评估 对相互作用,推理和训练成本随体系规模急剧膨胀,对大体系完全不可行。
2.5 已有方案的不足
方案 | 原理 | 缺陷 |
|---|---|---|
Ewald 消息传递(Ewald MP) | 将节点嵌入投影到倒空间,用傅里叶展开分离长短程贡献 | 计算开销大,相对基线推理时间增至 3.4× |
Neural P³M | 引入快速傅里叶变换(FFT)网格加速 Ewald 求和 | 内存占用高达基线的 4×,MD 模拟中每步需重建 FFT 网格,难以扩展至大体系 |
全局自注意力 | 借鉴 Transformer,对所有节点对计算注意力权重 | 复杂度 ,即使引入近似方案,内存开销仍然显著 |
单虚拟节点 | 引入一个连接所有节点的全局虚拟节点 | 单一固定维度向量无法充分表达大规模体系的全局信息,依赖于底层 MPNN 的消息传递机制,架构耦合度高 |
3. RANGE 框架设计
RANGE(Relaying Attention Nodes for Global Encoding)是一个模型无关(model-agnostic)的 GNN 扩展框架,其核心贡献在于通过多主节点注意力机制,以线性时间复杂度实现全图范围的长程信息传递。
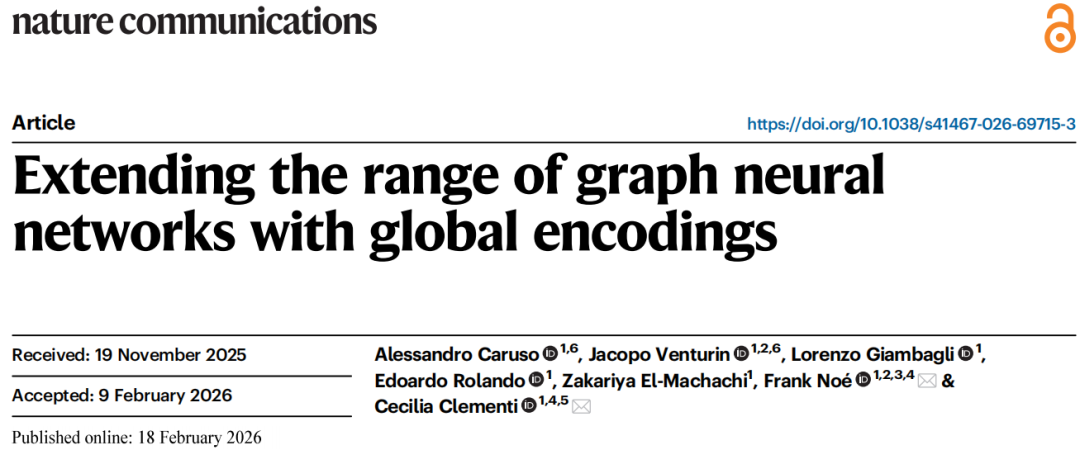
3.1 主节点(Master Nodes)
RANGE 在原始图 的基础上引入一组虚拟节点——主节点(master nodes)。与物理原子节点不同,主节点不对应任何实际粒子,但通过虚拟边与图中所有真实节点相连。每个主节点位于整个图的几何中心,以保证边特征定义的一致性。
多个主节点共同构成一个可扩展的全局信息存储空间,其数量通过动态正则化机制根据体系大小自适应调整(见第 3.4 节),从而避免单节点的信息容量瓶颈。
3.2 两阶段信息流:聚合与广播
RANGE 的核心操作由两个对称的阶段组成,插入在标准消息传递步骤之后:
阶段一:聚合(Aggregation)
将所有真实节点的嵌入 通过多头自注意力机制(GATv2 风格)压缩进主节点的虚拟嵌入中:
其中 为第 个主节点的嵌入, 为节点 到主节点的位置编码向量, 为主节点数量。注意力权重由查询(Query)、键(Key)和位置编码共同决定,每个头产生独立的聚合表示,捕获系统不同方面的全局统计信息。
阶段二:广播(Broadcast)
将所有主节点的虚拟嵌入 通过第二个注意力模块重新分发到每个真实节点:
广播阶段引入自环(self-loop),使每个节点在接收全局信息的同时保留其局部消息传递的结果,在全局与局部信息之间实现动态平衡。最终通过多层感知机(MLP)混合不同头的输出。
3.3 SE(3) 不变位置编码
主节点到真实节点的位置编码是 RANGE 实现能量连续性(力场稳定性的必要条件)的关键。设节点 到主节点(置于几何中心)的距离为 ,编码定义为:
其中 GRB 为高斯径向基函数展开,将归一化距离(值域 )投影到高维空间。该设计满足:
- • SE(3) 不变性:仅依赖于距离标量,与旋转和平移无关;
- • 连续性:距离从 到 连续映射到 ,不存在截断导致的梯度不连续;
- • 泛化性:编码不依赖于训练集的距离分布,可迁移至任意大小的体系。
3.4 动态正则化与主节点数自适应
若直接增加主节点数量,不同主节点的注意力权重可能趋于退化(degenerate),导致多个主节点学习到相同的表示,精度反而下降(见补充图 3)。为此,RANGE 引入一个可学习的正则化参数,动态控制激活的主节点数量:
其中 为有效激活的主节点数, 为体系原子数, 为正则化强度。这一机制使主节点数随体系规模平滑增长,实现全局信息容量的自适应扩展。
4. 数学形式化描述
4.1 标准 MPNN 回顾
给定图 ,其中节点集 ,边特征 。节点嵌入在每个交互层 按下式更新:
其中 为可微更新函数, 为消息函数, 为关于图对称性的池化操作。
4.2 RANGE 聚合块(GATv2 风格)
定义线性投影矩阵 (节点空间到注意力空间)和 (位置编码空间),第 个主节点的聚合权重为:
其中 为逐元素非线性激活, 为可学习注意力向量, 为主节点初始嵌入。
4.3 RANGE 广播块
自环通过 项显式保留,保证局部信息不被全局信息覆盖。
4.4 计算复杂度分析
操作 | 复杂度 |
|---|---|
标准消息传递(截断半径 ) | , 为平均邻居数 |
RANGE 聚合 | |
RANGE 广播 | |
RANGE 总额外开销 | , 时线性于 |
Ewald MP / Neural P³M | (FFT)或更高 |
全局自注意力 |
5. 实验设计与数据集
5.1 基线 MPNN 架构
文章选取了四个覆盖从不变到等变的代表性 MPNN 架构:
模型 | 类型 | 特点 |
|---|---|---|
SchNet | 不变(Invariant) | 连续滤波卷积,基础分子建模基线 |
PaiNN | 等变(Equivariant) | 消息传递中引入方向性等变特征 |
SO3krates | 等变 | 融合 SO(3) 等变性与自注意力 |
MACE | 等变 | 高阶等变消息传递,当前最强基线之一 |
所有模型均采用 2 个交互层、5 Å 截断半径的统一配置进行长程任务测试,以排除感受野扩展带来的混淆效应。
5.2 长程基准数据集
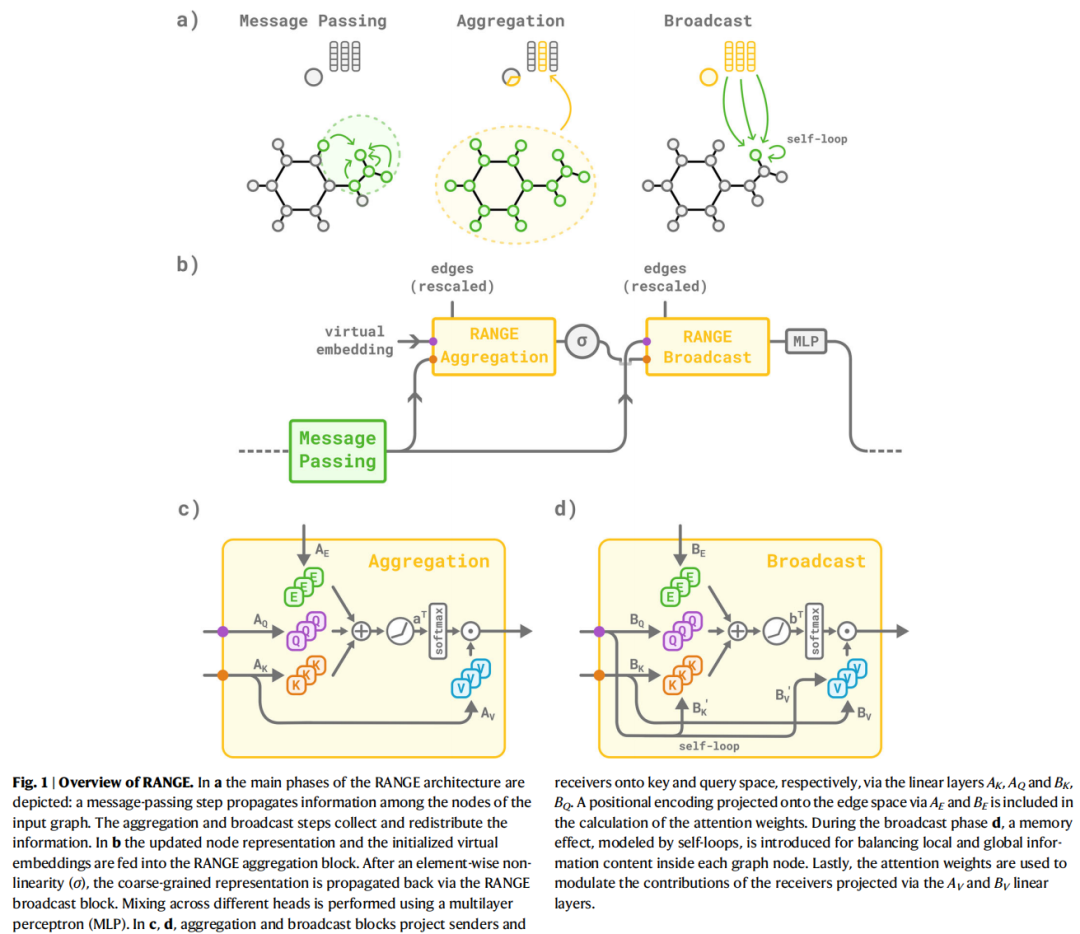
(a) NaCl 晶体掺杂(NaCl dataset)
在 晶体一端额外引入一个 Na 原子,同时保持电荷守恒,制造类掺杂效应,迫使电子密度重新分布。任务为预测 Na 原子位移过程中体系的能量剖面。该任务特别考验模型对电荷重分布引起的长程静电效应的感知能力。
(b) Au₂/MgO 界面(AuMgO dataset)
Au₂ 二聚体逐渐靠近周期性 MgO(001) 表面,分为有/无 Al 掺杂两种情形。Al 掺杂改变了二聚体在表面的优先取向(平行→垂直,即润湿→非润湿),这一构型切换完全由长程静电效应驱动,任务为预测 Au-O 能量曲线。
(c) 生物二聚体外推(Biodimers dataset)
包含极性(P)、非极性(A)、带电(C)三类有机分子二聚体,训练集覆盖 4 Å 以内的平衡距离构型,测试集外推至 4 Å 以外的距离。该测试同时考察模型的长程捕获能力和域外泛化能力。
5.3 实际分子体系数据集
AQM dataset(Aquamarine)
30-92 个原子的多样化有机分子,参考数据通过多体色散(MBD)方法显式处理量子长程效应。用于评估模型在实际分子建模任务中的精度-效率权衡。
MD22 dataset
包含三个具有代表性的大分子体系:
体系 | 原子数 | 帧数 | 主要长程效应 |
|---|---|---|---|
二十二碳六烯酸(DHA) | 56 | ~70,000 | 分子内构象间长程色散 |
巴克球捕手(CC) | 148 | ~6,000 | 宿主-客体 π-π 相互作用 |
双壁碳纳米管(DW) | 370 | ~5,000 | 管壁间范德华相互作用 |
6. 主要实验结果
6.1 长程基准任务
在 NaCl 和 AuMgO 数据集上,所有基线模型(包括 MACE 在内的最强等变架构,AuMgO 任务除外)均无法重现正确的能量剖面:能量曲线对体系结构变化(添加/移除 Na 原子、引入 Al 掺杂)几乎无响应,清晰地暴露了局部消息传递在长程信息交换上的根本缺陷。
施加 RANGE 后,无论是不变架构(SchNet)还是等变架构(PaiNN、SO3krates、MACE),均能准确重现参考能量曲线,包括区分有/无掺杂两种情形下的能量剖面差异。
在生物二聚体外推任务中,RANGE 相对基线模型的误差降低幅度:
- • 非极性(AA):能量 MAE 降低约 50%
- • 极性(PP):能量 MAE 降低约 40%
- • 带电(CC):能量 MAE 降低最高达 4 倍
带电二聚体误差降低最显著,与静电长程效应在该类分子中的主导地位完全吻合。
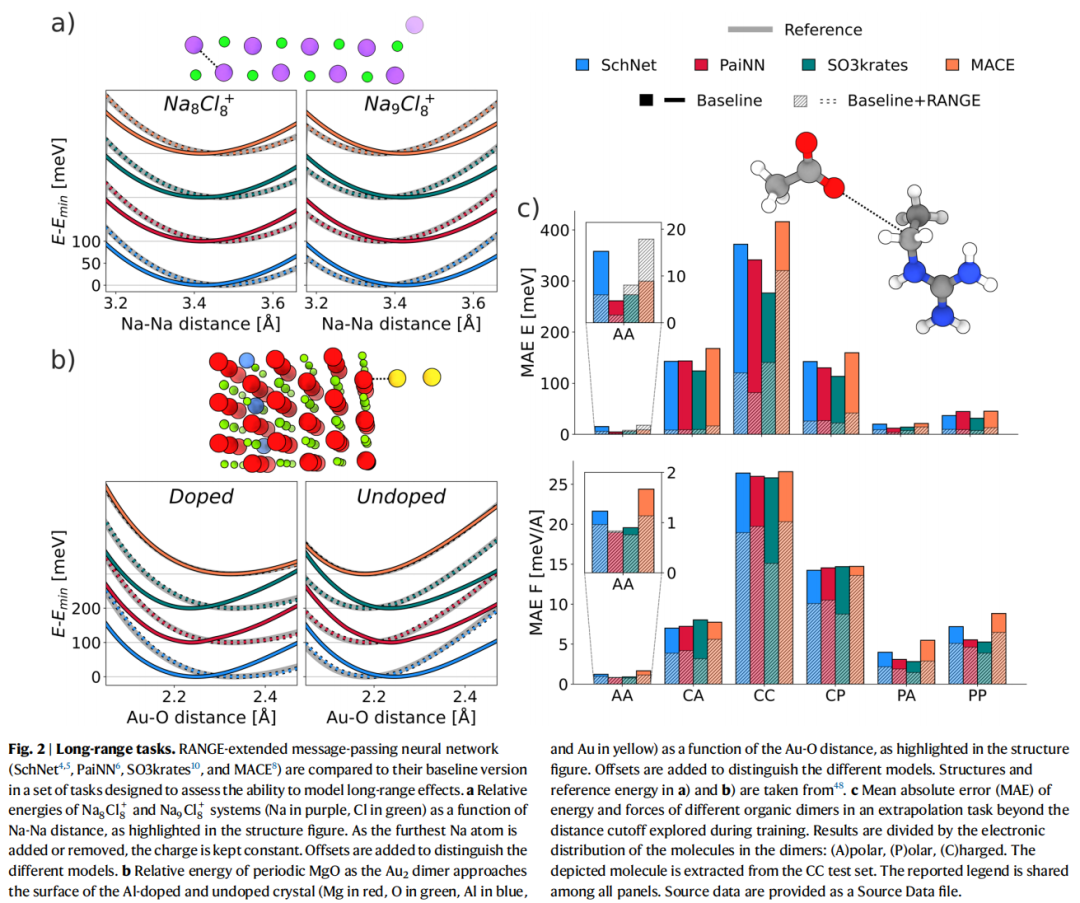
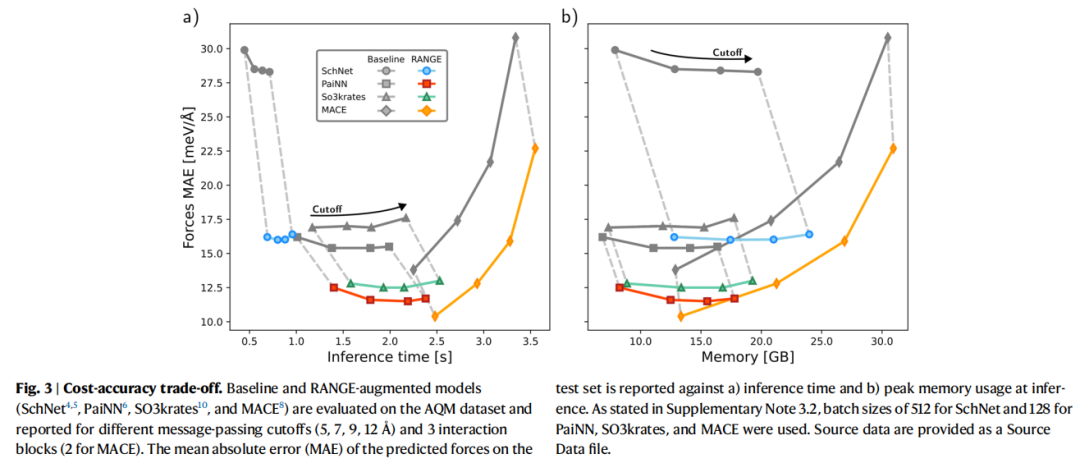
6.2 AQM 数据集精度-效率权衡
关键发现:
- 1. 截断半径的边际效用递减:基线模型在 5→12 Å 截断半径范围内,力的 MAE 提升迅速饱和,证实过度压缩导致的信息瓶颈是性能上限的根源;
- 2. RANGE 在最小截断(5 Å)下即超越最大截断(12 Å)的基线:这一结果说明 RANGE 提供的信息质量根本性地优于单纯扩大感受野;
- 3. 时间和内存开销随体系大小线性增长:每个截断半径下,RANGE 相对于对应基线的时间和内存增量为常数,验证了 的理论复杂度(补充图 2、4);
- 4. 正则化的必要性:未引入正则化时,增加主节点数会因注意力权重退化而导致精度下降;引入正则化后,所有 RANGE 变体的精度均低于任何截断半径下基线的最小可能误差。
7. 与现有方法的系统对比
在 MD22 数据集上,以 PaiNN(5 Å 截断)为基础模型,对比 RANGE、Ewald MP 和 Neural P³M 的表现(均为 4 次独立训练的平均值):
7.1 定量结果
DHA(56 原子)
方法 | MAE 能量 (kcal/mol) | MAE 力 (kcal/mol/Å) | 相对推理时间 | 相对内存峰值 |
|---|---|---|---|---|
Baseline | 0.199 ± 0.004 | 0.238 ± 0.004 | 1× | 1× |
Ewald MP | 0.191 ± 0.003 | 0.243 ± 0.002 | 3.35× | 1.70× |
Neural P³M | 0.113 ± 0.007 | 0.126 ± 0.007 | 2.80× | 3.97× |
RANGE | 0.110 ± 0.002 | 0.160 ± 0.004 | 1.47× | 1.22× |
CC(148 原子)
方法 | MAE 能量 | MAE 力 | 相对推理时间 | 相对内存峰值 |
|---|---|---|---|---|
Baseline | 0.37 ± 0.06 | 0.285 ± 0.006 | 1× | 1× |
Ewald MP | 0.36 ± 0.08 | 0.289 ± 0.006 | 1.49× | 1.54× |
Neural P³M | 0.18 ± 0.06 | 0.182 ± 0.034 | 1.40× | 1.79× |
RANGE | 0.22 ± 0.03 | 0.211 ± 0.005 | 1.24× | 1.17× |
DW(370 原子)
方法 | MAE 能量 | MAE 力 | 相对推理时间 | 相对内存峰值 |
|---|---|---|---|---|
Baseline | 0.96 ± 0.19 | 0.71 ± 0.02 | 1× | 1× |
Ewald MP | 0.89 ± 0.11 | 0.73 ± 0.03 | 1.44× | 1.37× |
Neural P³M | 0.40 ± 0.08 | 0.56 ± 0.03 | 1.59× | 2.42× |
RANGE | 0.47 ± 0.06 | 0.52 ± 0.02 | 1.57× | 1.13× |
7.2 综合评价
- • 精度:RANGE 与 Neural P³M 精度相当,均显著优于 Ewald MP 和基线;
- • 推理效率:RANGE 在所有体系中推理时间开销最低(1.2-1.6×),而 Neural P³M 在 DHA 上高达 2.8×;
- • 内存效率:RANGE 内存峰值增量始终低于 1.25×,Neural P³M 在 DHA 上高达 4×;
- • MD 可行性:Neural P³M 的 FFT 网格需在每个 MD 步重建,在大体系 MD 模拟中内存不可行;RANGE 无此问题,可直接用于长时 MD 模拟。
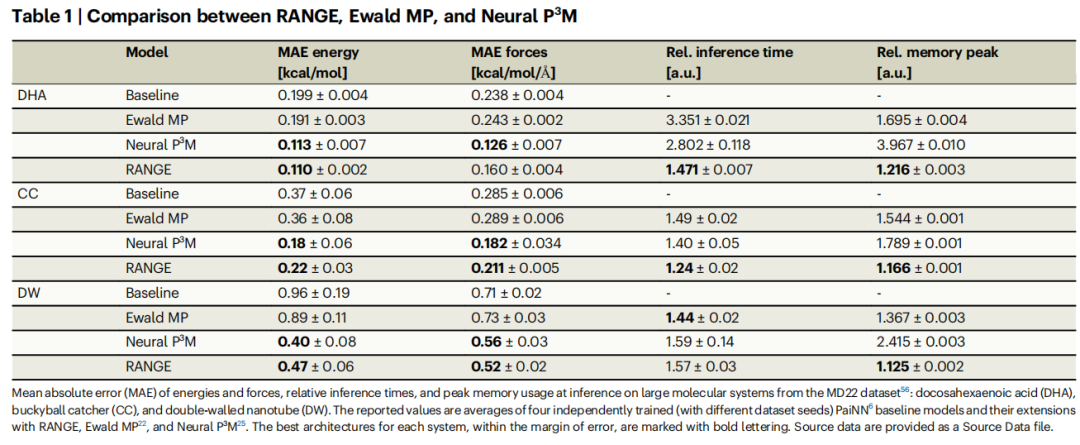
8. 分子动力学模拟验证
8.1 实验设置
以 PaiNN + RANGE(5 Å 截断)为力场,在气相条件下进行 MD 模拟:
- • 积分器:Langevin,温度 300 K,时间步长 1 fs
- • 模拟时长:16 ns
- • 独立轨迹数:DHA 10 条,CC 5 条,DW 2 条
- • 框架:MLCG package
8.2 稳定性结果
16 ns 的全部模拟轨迹均无失稳迹象,证明 SE(3) 不变位置编码带来的能量函数连续性在长时模拟中得到充分保持。三个体系的代表性 2 ns 轨迹段展示:
- • DHA:回转半径在紧凑与伸展构象之间频繁切换,充分采样了构象空间;
- • CC(巴克球捕手):宿主与客体之间的质心距离在多个区间振荡,对应不同结合模式;
- • DW(双壁纳米管):外管相对内管的轴向距离在 5 个明显的亚稳态之间转换,揭示了双壁间相对滑移的复杂动力学。
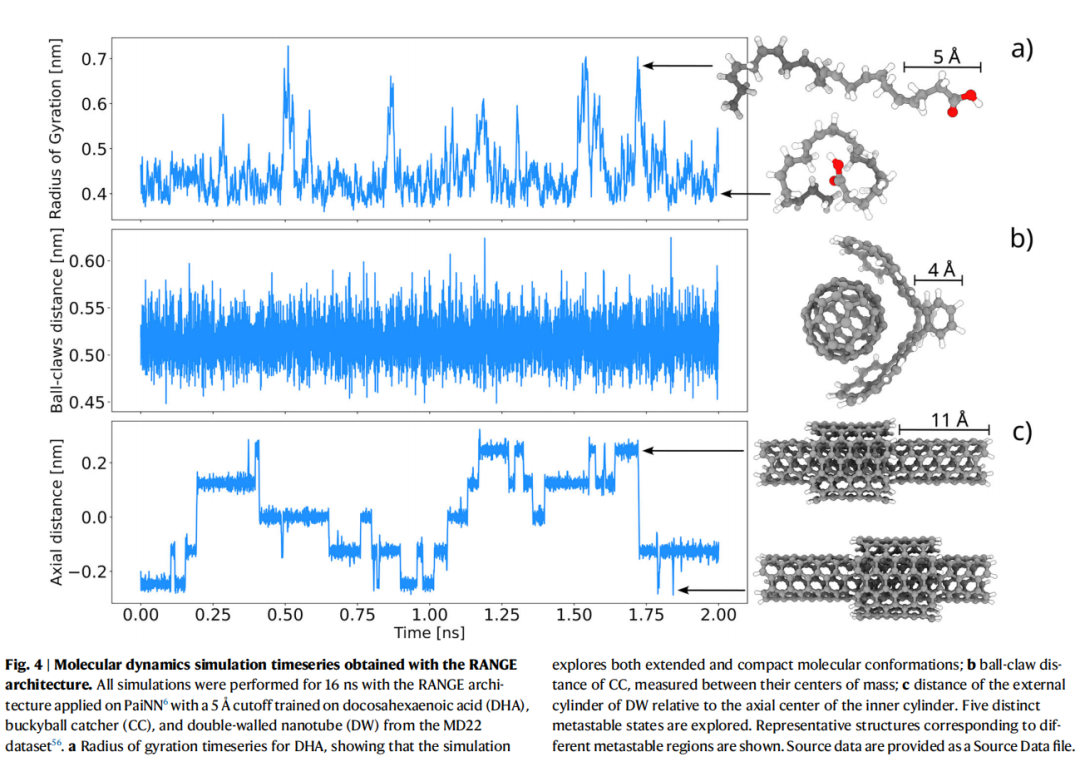
9. 可解释性分析
9.1 基于注意力权重的 SVD 分析
RANGE 使用加性注意力(additive attention,而非点积注意力)机制,理论上具有更强的可解释性。对 DHA、CC、DW 三个体系,对每个注意力头的权重矩阵进行奇异值分解(SVD),取最大奇异值对应的奇异向量映射至图节点。
9.2 主要发现
- 1. 每个注意力头具有单一主导自由度:SVD 分析显示,8 个注意力头各自的权重矩阵均只有一个显著奇异值,表明每个头学习了一种定义明确的聚类策略,而非混乱的随机加权;
- 2. 聚合与广播的非局域性:聚合阶段中获得高权重的节点与广播阶段接收强信息的节点空间上跨越整个体系,确认了信息流的非局域本质;
- 3. 平均场诠释:聚合步的加权平均输出等价于一种可学习的平均场效应(learnable mean field)——每个主节点汇总来自整个体系的贡献,广播时每个节点通过主节点感受到其他所有节点的有效相互作用;
- 4. N 体本质:由于多个主节点同时激活,信息传递本质上是 N 体的——节点间的通信不经过固定的成对路径,而是通过动态加权的全局中介。
10. 局限性与未来方向
10.1 现有局限
- • 等变性的边界:本文测试的等变架构(PaiNN、SO3krates、MACE)通过 RANGE 获得了精度提升,但作者也指出,等变性提供的增益本质上是短程的——在严格的长程任务中,等变模型与不变模型的差距因过度压缩而缩小。RANGE 对等变架构的最优集成方式(如是否在主节点层面也引入等变表示)有待进一步探索;
- • 溶剂化体系未测试:当前实验均在气相条件下进行,复杂溶液环境(如蛋白质水溶液、膜蛋白)中的长程静电屏蔽效应、溶剂重组能等对 RANGE 的性能影响尚不明确;
- • 周期性边界条件:Ewald 类方法天然适配周期系统,RANGE 对周期性体系的位置编码方案需要针对性设计;
- • 超大体系的极限:线性复杂度在理论上适配任意规模体系,但 70,000 原子以上的实际表现仍需验证。
10.2 未来方向
- • 将 RANGE 扩展至溶剂化生物大分子(蛋白质、核酸)和固体材料体系;
- • 探索将 RANGE 与等变主节点嵌入结合,进一步提升等变力场的长程准确性;
- • 开发适配周期性边界条件的位置编码方案;
- • 研究 RANGE 与粗粒化力场(CG FF)的结合,应用于更大尺度的分子动力学模拟。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-07,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号