Autoresearch 全自动写代码、写论文,Claude、Codex、龙虾纷纷复现

Autoresearch 全自动写代码、写论文,Claude、Codex、龙虾纷纷复现

Ai学习的老章
发布于 2026-04-13 12:17:42
发布于 2026-04-13 12:17:42
Karpathy 最近搞了一个叫 autoresearch 的项目,一出手就在圈内炸了锅。
核心思路简单到离谱:你去睡觉,AI 帮你通宵做实验
一觉醒来,100 多个实验结果整整齐齐地摆在面前。
更猛的是,社区在此基础上迅速衍生出了好几个项目,把这套"自主研究"的范式推向了更广的场景——从代码质量优化,到直接帮你写论文。
我觉得这可能是 2026 年最有意思的 AI Agent 落地方向之一
Karpathy 的 autoresearch:用 Markdown 编程的研究机构
项目地址:https://github.com/karpathy/autoresearch
Karpathy 在 README 里写了一段非常有画面感的话:
曾经,前沿 AI 研究是由肉体大脑完成的,他们在吃饭、睡觉和其他娱乐之间挤出时间做研究,偶尔通过名为"组会"的仪式用声波互联来同步进展。那个时代早已过去。研究现在完全属于在天空中计算集群巨型建筑上运行的自主 AI Agent 群。
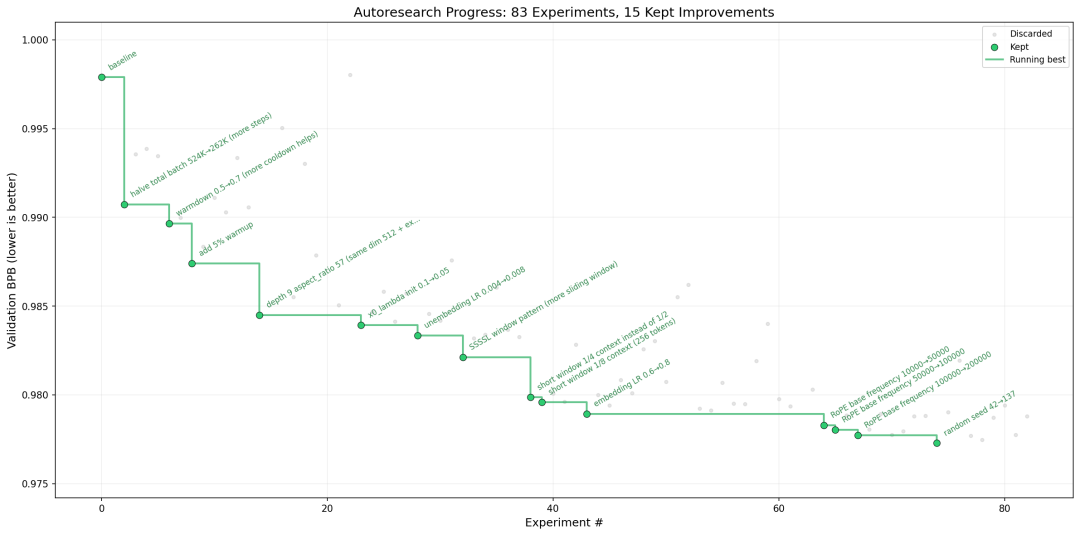
Karpathy autoresearch 实验进展图
Karpathy autoresearch 实验进展图
核心玩法是什么?
整个项目只有三个关键文件:
文件 | 作用 | 谁来改? |
|---|---|---|
prepare.py | 数据准备、评估函数、dataloader | ❌ 不能动 |
train.py | 模型架构、优化器、训练循环 | 🤖 AI 改这个 |
program.md | AI Agent 的行为指令 | 👨💻 人类改这个 |
这个设计太妙了——你不再写 Python,你写 Markdown
program.md 就是你的"研究组织代码",定义 AI Agent 的行为模式:怎么实验、怎么评估、怎么决定保留还是回滚
实验循环长这样:
永远循环:
1. 看当前 git 状态
2. 改 train.py,尝试一个想法
3. git commit
4. 跑实验(5分钟固定时长)
5. 读取结果:val_bpb 有没有降低?
6. 降了 → 保留,推进分支
7. 没降 → git reset 回滚
8. 记录到 results.tsv
9. 继续下一个实验
每次实验固定跑 5 分钟,一个小时跑大约 12 个实验。你睡 8 小时,AI 就给你跑了将近 100 个实验。每个实验的指标、内存、状态全部记录在 TSV 里
program.md 里有一条非常霸气的规则:
NEVER STOP: 一旦实验循环开始,不要暂停问人要不要继续。人类可能在睡觉。你是自主的。如果没想法了,想得更深一些。循环持续到人类手动打断为止
快速上手:
# 安装 uv 包管理器
curl -LsSf https://astral.sh/uv/install.sh | sh
# 安装依赖
uv sync
# 下载数据和训练 tokenizer
uv run prepare.py
# 手动跑一次训练(验证环境正常)
uv run train.py
然后开启你的 Claude Code 或者 Codex,对它说一句话就行:
Hi have a look at program.md and let's kick off a new experiment!
醒来看 results.tsv
设计哲学上有几点我觉得特别精彩:
- 固定时间预算:所有实验都是 5 分钟,不管你怎么改架构改参数,都是公平比较
- 简洁性原则:同等效果下更简单的代码优先。删代码能保持效果?那就是赢
- 单一指标:只看
val_bpb(验证集 bits per byte),越低越好 - Git 即记忆:所有实验都 commit,成功推进分支,失败就 reset
不过这个项目目前只支持 NVIDIA GPU(在 H100 上测试),对 Mac 或 CPU 用户不太友好。好在社区已经有了 MacOS、Windows、AMD 的 fork 版本。
Codex Autoresearch:把自主研究推广到一切有指标的场景
项目地址:https://github.com/leo-lilinxiao/codex-autoresearch

Codex Autoresearch Banner
Codex Autoresearch Banner
Karpathy 的 autoresearch 只做 ML 训练,而 codex-autoresearch 把这套逻辑泛化到了所有软件工程场景。
它是一个 OpenAI Codex 的 Skill(技能插件),核心理念:只要你有一个可以衡量的数字指标,它就能帮你自动优化。
你只需用一句话描述目标,Codex 会自动分析项目、确认指标、然后进入自主迭代循环。
看几个实际场景:
你说的话 | Codex 做什么 |
|---|---|
"提高测试覆盖率" | 扫描项目,提出指标,自动写测试直到达标 |
"修复 12 个失败的测试" | 逐个检测修复,直到全部通过 |
"为什么 API 返回 503?" | 用科学方法排查根因,给出可证伪的假设 |
"这段代码安全吗?" | STRIDE + OWASP 审计,每个发现都有代码证据 |
架构上有个很聪明的设计——支持前台和后台两种运行模式。
你可以盯着它跑,也可以让它后台无人值守地跑一整夜。
实验循环跟 Karpathy 的一脉相承:
共享循环核心(永远循环或 N 次):
1. 审查当前状态 + git 历史 + 结果日志
2. 选一个假设
3. 做一个原子改动
4. git commit
5. 跑验证 + 安全护栏
6. 改进了 → 保留。变差了 → 回滚。崩了 → 修复或跳过
7. 记录结果
8. 健康检查
9. 连续 3 次丢弃 → 调整策略;5 次 → 转向;2 次转向 → 搜索网络
10. 重复
它还有一个跨运行学习的机制——每次成功或失败的经验都会被提取成"教训",注入到下一轮实验的决策中。
安装也很简单:
git clone https://github.com/leo-lilinxiao/codex-autoresearch.git
cp -r codex-autoresearch your-project/.agents/skills/codex-autoresearch
然后在 Codex 里说:
$codex-autoresearch
I want to get rid of all the `any` types in my TypeScript code
走开,回来看结果。
Claude Autoresearch:9 个命令覆盖全场景
项目地址:https://github.com/uditgoenka/autoresearch
这个是面向 Claude Code 的版本,口号很直白:
"设定目标 → Claude 跑循环 → 你醒来看结果"
跟 Codex 版本类似,也是泛化的自主迭代框架,但这个项目在命令体系上做得更完整,提供了 9 个开箱即用的命令:
命令 | 功能 |
|---|---|
/autoresearch | 核心自主迭代循环 |
/autoresearch:plan | 交互式配置向导 |
/autoresearch:security | STRIDE + OWASP 安全审计 |
/autoresearch:ship | 发布前检查工作流 |
/autoresearch:debug | 科学方法自主排 bug |
/autoresearch:fix | 自动修复所有错误 |
/autoresearch:scenario | 场景驱动测试生成 |
/autoresearch:predict | 多角色预分析 |
/autoresearch:learn | 自动生成/更新文档 |
它定义了 8 条核心规则,这也是整个 autoresearch 范式的精髓:
- 循环到底——无限循环或 N 次循环后总结
- 先读后写——理解上下文再动手
- 一次一改——原子性修改,坏了知道是哪步
- 机械验证——不要主观的"看起来行",要指标
- 自动回滚——失败立刻撤回
- 简单为王——同样效果,代码越少越好
- Git 即记忆——所有实验都进 git 历史
- 卡住了就想更深——没思路的时候重新审视、组合近似成功的实验、尝试激进改变
安装方式(推荐插件安装):
# 在 Claude Code 中运行
/plugin marketplace add uditgoenka/autoresearch
/plugin install autoresearch@autoresearch
或者手动复制:
git clone https://github.com/uditgoenka/autoresearch.git
cp -r autoresearch/claude-plugin/skills/autoresearch .claude/skills/autoresearch
cp -r autoresearch/claude-plugin/commands/autoresearch .claude/commands/autoresearch
然后试试:
/autoresearch
Goal: Increase test coverage from 72% to 90%
Scope: src/**/*.test.ts, src/**/*.ts
Metric: coverage % (higher is better)
Verify: npm test -- --coverage | grep "All files"
Guard: npm test
AutoResearchClaw:最激进的——直接帮你写论文
项目地址:https://github.com/aiming-lab/AutoResearchClaw

AutoResearchClaw Logo
AutoResearchClaw
前面几个还是在"优化代码/模型"的范畴,这货直接把目标拉到了全自主写论文
口号:"Chat an Idea. Get a Paper."——你说一个想法,它给你出一篇会议论文
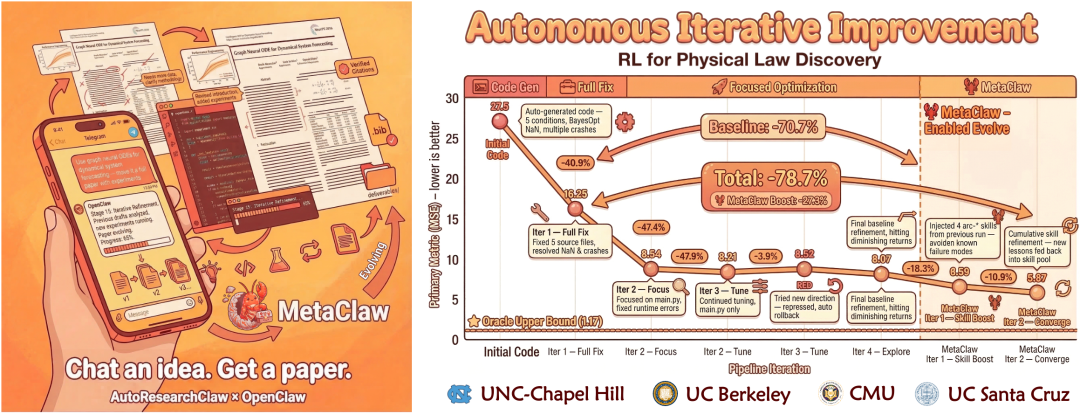
AutoResearchClaw 框架图
AutoResearchClaw 框架图
23 个阶段,8 个大的 Phase,全自动流水线:
Phase A: 研究范围界定 Phase E: 实验执行
1. 主题初始化 12. 实验运行
2. 问题分解 13. 迭代改进(自动修复)
Phase B: 文献发现 Phase F: 分析与决策
3. 搜索策略 14. 结果分析(多 Agent)
4. 文献收集(真实 API) 15. 研究决策(PIVOT/REFINE)
5. 文献筛选 [人工关口]
6. 知识提取 Phase G: 论文写作
16. 论文大纲
Phase C: 知识综合 17. 论文初稿
7. 综合 18. 同行评审(证据检查)
8. 假设生成(多角色辩论) 19. 论文修订
Phase D: 实验设计 Phase H: 最终化
9. 实验设计 [人工关口] 20. 质量关口 [检查]
10. 代码生成 21. 知识归档
11. 资源规划 22. 导出发布(LaTeX)
23. 引用验证
最终产出一整套交付物:
产出 | 说明 |
|---|---|
paper_draft.md | 完整论文(引言、相关工作、方法、实验、结论) |
paper.tex | 可编译的 LaTeX(NeurIPS/ICML/ICLR 模板) |
references.bib | 真实的 BibTeX 引用(来自 OpenAlex、Semantic Scholar、arXiv) |
experiment runs/ | 生成的实验代码 + 沙箱运行结果 |
charts/ | 自动生成的对比图表 |
reviews.md | 多 Agent 同行评审 |
几个让我印象深刻的设计:
- 引用不造假:文献通过 OpenAlex、Semantic Scholar 和 arXiv API 获取真实论文,还有 4 层引用验证。这一点非常关键,其他自动写论文的工具最大的问题就是瞎编引用
- 自愈机制:实验失败了会自动诊断修复;假设不成立会自动 PIVOT 换方向
- 多 Agent 辩论:假设生成和结果分析都用多视角辩论机制,不是单一 LLM 的"自说自话"
- 跨平台支持:通过 ACP(Agent Client Protocol),支持 Claude Code、Codex CLI、Copilot CLI、Gemini CLI、Kimi CLI 等任何兼容的 Agent 后端
- Sentinel 哨兵:后台质量监控——NaN/Inf 检测、论文证据一致性检查、引用相关性打分、反编造守卫
快速上手:
# 克隆安装
git clone https://github.com/aiming-lab/AutoResearchClaw.git
cd AutoResearchClaw
python3 -m venv .venv && source .venv/bin/activate
pip install -e .
# 交互式配置
researchclaw setup
researchclaw init
# 一条命令跑起来
export OPENAI_API_KEY="sk-..."
researchclaw run --config config.arc.yaml --topic "Your research idea" --auto-approve
它已经 showcase 了 8 个领域(数学、统计、生物、计算、NLP、RL、视觉、鲁棒性)的全自主生成论文
横向对比:四个项目怎么选?
特性 | Karpathy autoresearch | Codex Autoresearch | Claude Autoresearch | AutoResearchClaw |
|---|---|---|---|---|
核心场景 | ML 模型训练优化 | 通用代码质量 | 通用代码质量 | 全自主写论文 |
Agent 平台 | 任意 | OpenAI Codex | Claude Code | 多平台 ACP |
自主程度 | 高(永不停止) | 高(后台模式) | 高(无限循环) | 极高(23 阶段流水线) |
迭代粒度 | 改 train.py | 任意代码改动 | 任意代码改动 | 文献→实验→论文 |
评估方式 | val_bpb | 自定义指标 | 自定义指标 | 多维质量评审 |
GPU 要求 | 需要 NVIDIA GPU | 不需要 | 不需要 | 按任务而定 |
适合谁 | ML 研究者 | 工程师/开发者 | 工程师/开发者 | 科研工作者 |
老章说两句
这一波 autoresearch 生态的爆发,本质上是三个趋势交汇:
第一,Agent 能力到位了。 Claude Code、Codex CLI 这些编程 Agent 已经能够稳定地修改代码、运行测试、读取结果。不再是"玩具级"了。
第二,范式足够简洁。 Karpathy 的核心洞察是——你只需要一个指标 + 一个约束 + 一个循环。这个模式简单到任何人都能理解、任何场景都能套用。
第三,Git 是天然的 Agent 记忆。 每次实验 commit,失败就 revert,成功就推进。这比任何复杂的状态管理系统都优雅。
说白了,这就是把 AI 从"一次性问答"变成"持续迭代"的范式转变。以前你让 AI 改代码,改完就改完了。现在是让它进入一个无限循环:改、测、评、保留或回滚、再来。跟人类科研的流程一模一样——提出假设、做实验、分析结果、决定下一步——只不过它不需要睡觉。
我觉得 AutoResearchClaw 是最值得关注的一个。
虽然全自主写论文的质量还没法跟顶级研究者比,但作为科研辅助工具——帮你快速做文献调研、跑初步实验、生成论文初稿——已经能省掉大量重复劳动了。
当然,这些项目也有很明显的局限:
- 只能优化能量化的东西。"让代码更优雅"这种目标它搞不定
- API 成本不低。跑一夜的实验,token 费用可能不便宜
- 创造性有限。它擅长的是在已知空间内暴力搜索,真正颠覆性的创新还是得靠人类
但方向是对的。
当 Agent 能力继续提升、成本继续下降,"你定义方向,AI 做苦力"可能真的会成为科研和工程的常态。
制作不易,如果这篇文章觉得对你有用,可否点个关注。给我个三连击:点赞、转发和在看。若可以再给我加个🌟,谢谢你看我的文章,我们下篇再见!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-28,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号