vLLM v0.19.0 来了,适配 HuggingFace v5,多模态优化,CPU KV 缓存卸载

vLLM v0.19.0 来了,适配 HuggingFace v5,多模态优化,CPU KV 缓存卸载

Ai学习的老章
发布于 2026-04-13 12:23:01
发布于 2026-04-13 12:23:01
3 月份我连写了 vLLM 0.18 和 vLLM 三月四连发,假期发现 vllm v0.19.0 发了
我之所以一直追 vLLM 的每个版本,因为它确实是目前生产环境里用得最多的大模型推理引擎。
你在用 vLLM 部署模型,你必须知道新版本改了什么、哪些坑填了、哪些新坑挖了。
这次 v0.19.0 的更新量很大,我先把最重要的拎出来聊,然后再补充 vLLM 官方最近发的两篇技术博客,这两个都值得单独展开说。
先看全貌:v0.19.0 改了什么
关键更新 | 类型 | 一句话 |
|---|---|---|
Gemma 4 首日支持 | 模型 | Google 最强开源模型,发布当天就能在 vLLM 上跑 |
零气泡异步调度 + 推测解码 | 引擎 | 两大优化终于不打架了 |
Model Runner V2 成熟 | 引擎 | 从实验性到生产级,补齐了一大堆能力 |
ViT 全量 CUDA 图 | 性能 | 多模态模型的视觉编码器也有 CUDA 图加速了 |
通用 CPU KV 缓存卸载 | 显存 | 显存不够 CPU 来凑,支持自定义卸载策略 |
DBO 通用化 | 性能 | 微批次重叠优化,所有模型都能用了 |
NVIDIA B300/GB300 | 硬件 | 新一代硬件首日适配 |
Transformers v5 兼容 | 生态 | 大面积适配 HuggingFace v5 |
下面挨个拆
一、零气泡异步调度 × 推测解码:终于合体了
上次写 Model Runner V2 的时候我就提过,vLLM V1 有个很蛋疼的问题——异步调度和推测解码这两个最重要的优化,分别能跑,放一起就打架。
为什么打架?因为推测解码的拒绝采样(rejection sampling)结果需要从 GPU 同步回 CPU,CPU 拿到结果后才能准备下一步的输入。这个同步点一卡,异步调度"CPU 和 GPU 并行干活"的优势就被吃掉了。
v0.19.0 的解法:把输入准备也搬到 GPU 端。拒绝采样的结果直接在 GPU 上被下一步消费,CPU 和 GPU 之间的同步点彻底消除——所谓"零气泡",就是两边的流水线中间没有空转等待。
实际意义是什么?你现在可以同时享受异步调度的高吞吐和推测解码的低延迟。在此之前,这两个优化你只能二选一,或者忍受明显的性能折扣。
二、Model Runner V2:从实验品到生产级
上次 v0.18.0 里 MRV2 还打着"实验性"的标签,我也说过"LoRA、线性注意力、Eagle 之外的推测方法暂不支持"
这次大量短板被补齐了:
新增能力 | 说明 |
|---|---|
Pipeline Parallelism CUDA 图 | 流水线并行场景支持分段 CUDA 图捕获,多卡部署不再掉速 |
推测解码拒绝采样器 | Greedy 解码和 Logprobs 输出都支持了 |
多模态 + 推测解码 | 以前多模态模型没法用推测解码加速,现在可以了 |
Streaming Inputs | 输入流式处理,降低首 token 延迟 |
EPLB | 专家级并行负载均衡,跑 MoE 模型必备 |
FP32 draft logits + FP64 Gumbel 噪声 | 精度提升,减少推测解码时的数值漂移 |
对于纯推理场景(不挂 LoRA),MRV2 已经可以认真考虑在生产环境上了。启用方式还是一样:
export VLLM_USE_V2_MODEL_RUNNER=1
# 然后正常跑 vLLM,不用改任何代码
MRV2 的推进速度超出预期
上次还在说"暂不支持推测解码的完整流程",这次就基本补齐了。异步调度 + 推测解码 + CUDA 图,这三板斧全到位之后,MRV2 的性能上限会比 V1 高一截
三、ViT 全量 CUDA 图捕获
这个更新对跑多模态模型的同学来说很实在
之前 vLLM 处理图片/视频请求时,视觉编码器(ViT)部分是"裸跑"的——每次都要重新 launch 一堆 CUDA kernel,小 batch 场景下这个开销特别明显
v0.19.0 让 ViT 也支持了 CUDA 图捕获。简单说就是把 ViT 的计算图"录像"下来,之后每次推理直接"回放",省掉了反复 launch kernel 的开销
如果你经常用 Gemma 4、Qwen-VL 这类多模态模型处理图片问答,这个优化带来的延迟降低是体感可知的
四、CPU KV 缓存卸载:显存不够 CPU 来凑
这是个很实用的功能
跑长序列时最头疼的就是 KV 缓存吃显存——一个 8K 上下文的请求,KV 缓存可能就要吃掉好几个 GB。之前显存满了,vLLM 只能丢弃请求或者降级处理
v0.19.0 引入了通用 CPU KV 缓存卸载机制:
- 可插拔的缓存策略(CachePolicy):自定义哪些 block 优先卸载到 CPU 内存
- Block 级别的抢占处理:细粒度控制,该卸哪块卸哪块
- 混合模型支持:SSM + Transformer 混合架构(比如 Mamba 系列)也能用
你可以理解为——KV 缓存有了"虚拟内存",显存放不下的部分自动溢出到 CPU 内存
五、DBO 通用化:所有模型都能享受微批次重叠
DBO(Dual-Batch Overlap)是 vLLM 之前引入的一个优化——把预填充和解码放在不同的微批次里交替执行,让 GPU 的计算和内存访问更好地重叠起来。
问题是之前只有特定模型架构能用,限制不少。这次通用化了——不管你跑什么模型,DBO 都能给你带来吞吐提升。
六、硬件支持更新
NVIDIA B300/GB300(SM 10.3):
- AllReduce 融合默认开启,调优过的 all-reduce 通信器
- Blackwell 架构的 CUTLASS FP8 GEMM 优化
- 修复了桌面级 Blackwell 上 NVFP4 的 NaN 问题
AMD ROCm:
- 升级到 ROCm 7.2.1 + PyTorch 2.10 + Triton 3.6
- DeepEP 作为 all2all 后端——EP 场景的 AMD 用户终于有像样的方案了
- AITER 的持久化 MLA kernel 和 FP8×FP8 注意力
- Nightly Docker 镜像和 wheel 发布,CI 终于跟上了
Intel XPU:MLA 模型支持 + W4A8 量化
CPU:tcmalloc 默认启用,池化模型吞吐提升 **48.9%**——纯 CPU 部署的用户别错过
七、API 和其他值得关注的更新
新端点:/v1/chat/completions/batch——批量推理终于有专门的 API 了,不用再自己写循环
thinking tokens 硬限制:推理模型(如 Qwen3-Coder)的思考长度现在可以设上限了,防止模型在简单问题上疯狂"内心戏"
-sc 简写:--speculative-config 太长了,现在用 -sc 就行
量化更新:
- 在线 MXFP8 量化,MoE 和 Dense 模型都支持
- QeRL:在线量化 + 量化重加载,专为 RLHF 训练场景设计
Transformers v5 兼容:大面积适配了 HuggingFace Transformers v5,升级后不用再担心各种奇怪的兼容性报错
到这里,v0.19.0 的核心更新就聊完了。
接下来补充两篇 vLLM 官方博客的内容——这两篇在 v0.18 和 v0.19 之间发布,跟这次版本更新紧密相关。
【博客一】隐藏状态提取:给推测解码的训练管道打通了
这篇博客详细介绍了一个从 v0.18.0 开始引入的新系统
标题听着学术,但实际解决的问题非常落地
痛点在哪?
推测解码大家应该不陌生了——上次三月四连发里我详细聊过 P-EAGLE
核心思路就是用一个小的草稿模型快速猜 token,再用大模型并行验证
关键在于,目前最好的推测解码方法(Eagle-3、P-EAGLE、DFlash),草稿模型需要大模型的中间层隐藏状态作为输入。你要训练这种草稿模型,就得先生成海量的隐藏状态数据
以前要做这件事,两条路都很痛苦:
路线一:用 transformers 跑。 能跑,但慢得要死——vLLM 的所有性能优化(分布式推理、前缀缓存、自动批处理、分块预填充)全丢了。而且 transformers 和 vLLM 的隐藏状态可能有微妙差异,训出来的草稿头到 vLLM 上一跑就不对。
路线二:魔改 vLLM 内部。 直接调内部 API,手动组装各种组件。能跑,但维护成本爆炸——vLLM 一升级你的 patch 就废了。之前 Speculators 库 v0.5.0 之前就是这么干的。
vLLM 的解法:在现有管道上做文章
vLLM 团队想到了一个很巧妙的方案。他们注意到三件事:
- vLLM 跑 Eagle-3 推测解码时,已经有从大模型向草稿模型传递隐藏状态的管道
- vLLM 有 KV Connector API,本来用于 Prefill/Decode 分离场景的数据传输,支持写磁盘、共享内存、Nixl 传输等多种方式
- 隐藏状态和 KV 缓存的内存管理方式本质上是一样的——每个 token 对应一个值,可以复用分页内存管理
把这三个现有能力一组合:创建一个"假的"草稿模型,它不做推理,只负责接收大模型传过来的隐藏状态,存到自己的 KV 缓存里,再通过 KV Connector 导出。
下图是这套系统的整体设计——通过复用 Eagle-3 的隐藏状态管道和 KV Connector API,实现了零侵入的隐藏状态提取:
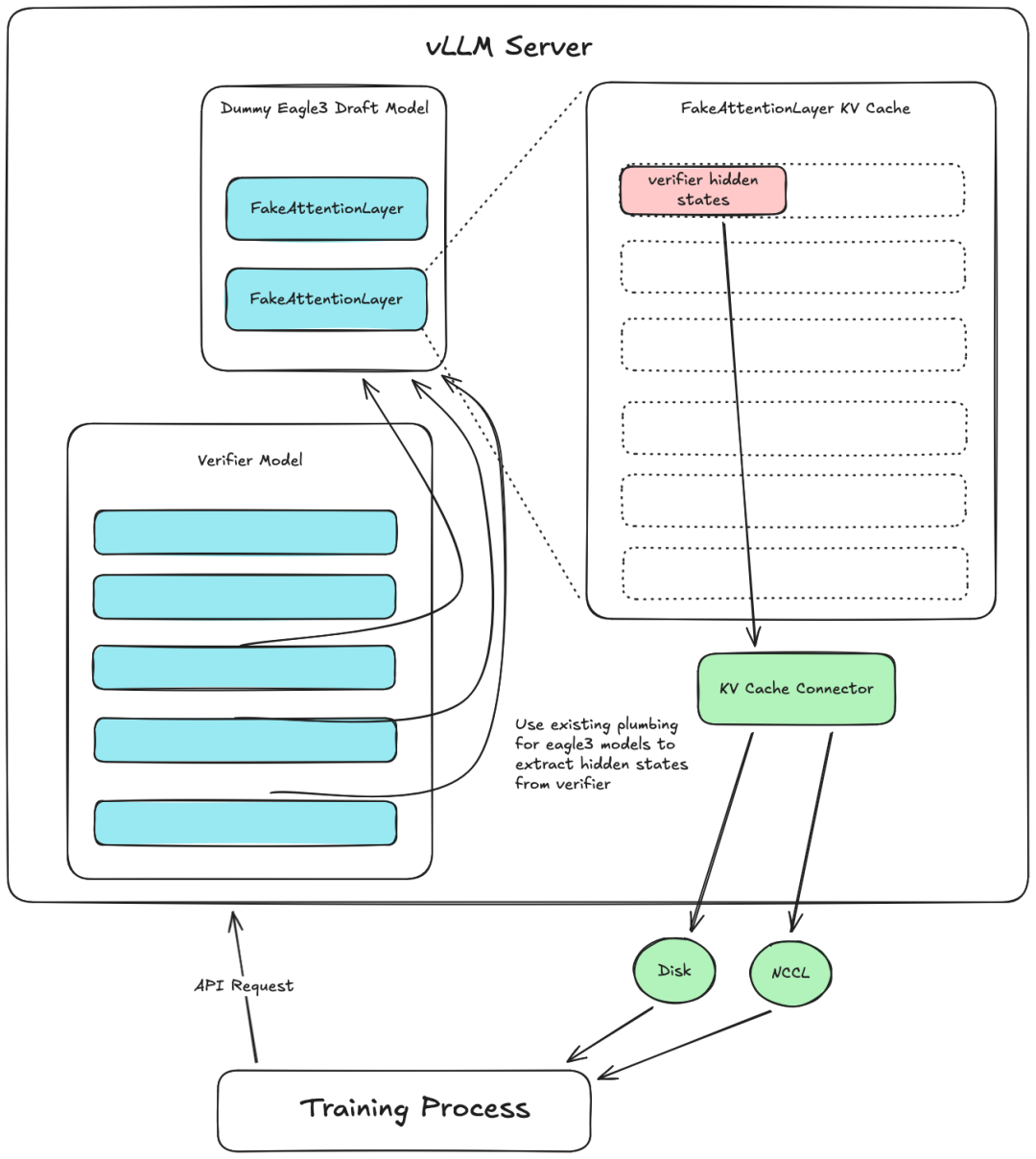
隐藏状态提取系统设计
隐藏状态提取系统设计
这套设计的好处很明显:
- 零侵入:不改 vLLM 核心代码,复用现有管道
- 全功能:前缀缓存、分块预填充、自动批处理全能用
- 灵活:通过 KV Connector API 扩展导出方式(写磁盘、GPU 直传、跨节点传输)
怎么用?
启动方式一条命令搞定:
vllm serve Qwen/Qwen3-8B --speculative_config '{
"method": "extract_hidden_states",
"num_speculative_tokens": 1,
"draft_model_config": {
"hf_config": {
"eagle_aux_hidden_state_layer_ids": [3, 18, 33, 36]
}
}
}' --kv_transfer_config '{
"kv_connector": "ExampleHiddenStatesConnector",
"kv_role": "kv_producer",
"kv_connector_extra_config": {
"shared_storage_path": "/tmp/hidden_states"
}
}'
eagle_aux_hidden_state_layer_ids 指定要提取哪几层的隐藏状态,shared_storage_path 指定输出目录。每个请求处理完后,你在指定目录下能找到 safetensors 文件:
# /tmp/hidden_states/{req_id}.safetensors
{
"token_ids": [prompt_seq_len], # prompt 的 token id
"hidden_states": [prompt_seq_len, num_layers, hidden_size] # 对应的多层隐藏状态
}
几个注意事项:
- 支持
--tensor-parallel-size和--data-parallel-size多卡部署 - 只提取 prompt token 的隐藏状态,建议调
v1/completions接口并设max_tokens=1 - 目前只有写磁盘的
ExampleHiddenStatesConnector,后续会加 GPU 直传等更高效的方式
这套系统已经和 vLLM 的 Speculators 库整合(PR #353),speculators v0.5.0 将支持草稿模型的在线训练——边推理边生成训练数据边训练,整个流程闭环了。
这个功能看起来是给研究者用的,但它解决的问题很根本。推测解码是公认的最有效推理加速手段,但"怎么训一个好的草稿模型"一直是个高门槛的事。以前你要么用 transformers 慢慢跑数据(还可能跑出来的数据跟 vLLM 不一致),要么大改 vLLM 源码。现在一条命令搞定。推测解码从"通用方案"走向"为你的模型定制专属草稿头",这条路被打通了。
【博客二】Gemma 4 落地 vLLM:Day 0 四平台支持
之前写过 Gemma 4 全系列本地部署指南,这次 vLLM 官方博客详细介绍了 Gemma 4 在 vLLM 上的支持情况,有些细节值得补充。
Day 0 全平台,这个含金量不低
vLLM 对 Gemma 4 做到了发布当天四个硬件平台同时可用:
- NVIDIA GPU:A100、H100、B200 都能跑
- Google TPU:Trillium 和 Ironwood 都有适配
- AMD GPU:ROCm 平台支持
- Intel XPU:也加入了首日阵营
TPU 支持是这次的亮点
之前开源推理引擎在 TPU 上的支持普遍很弱,vLLM 这次算是补上了这块短板。对于用 Google Cloud 的团队来说,终于不用在 TPU 和开源模型之间二选一了。
下图是 Gemma 4 在 Arena.ai 聊天排名上的性能对比——同等模型尺寸下,参数效率遥遥领先:
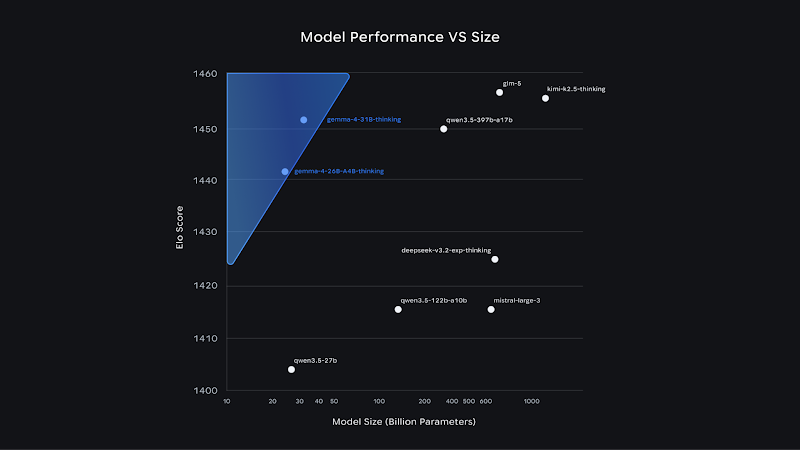
Gemma 4 性能对比
Gemma 4 性能对比
Gemma 4 在 vLLM 上能做什么
Gemma 4 家族有四个尺寸:E2B、E4B、26B MoE、31B Dense。在 vLLM 上的核心能力:
- 多模态:图片和视频原生处理,边缘模型(E2B/E4B)还支持语音输入
- 工具调用:原生 function-calling + 结构化 JSON 输出,vLLM 专门做了 Gemma 4 tool parser
- 长上下文:边缘模型 128K,大模型 256K
- 推理能力:复杂多步推理,数学和逻辑任务有显著突破
- 140+ 语言原生支持
- Apache 2.0 协议:商用零障碍
快速上手,官方推荐用预构建 Docker 镜像省心省力:
# 最省事的方式
docker run --gpus all vllm/vllm-openai:gemma4
或者手动启动(需要 transformers>=5.5.0):
pip install vllm==0.19.0
vllm serve google/gemma-4-31b-it \
--tensor-parallel-size 2 \
--trust-remote-code
更多部署细节可以参考官方 recipes:https://docs.vllm.ai/projects/recipes/en/latest/Google/Gemma4.html
Gemma 4 对 vLLM 的意义,不只是"又多支持一个模型"。Day 0 覆盖四大硬件平台,说明 vLLM 的多后端抽象层已经足够成熟——加一个新模型不再需要每个硬件后端各搞一套适配了。Google 把 Gemma 4 全系列换成 Apache 2.0,再加上 vLLM 的生产级推理性能,对于想在自有基础设施上跑开源模型的团队来说,这个组合很有吸引力。
总结
把 v0.19.0 的版本更新和两篇博客放在一起看,vLLM 最近这一波动作的主线很清晰:
从推理引擎到推理平台。
- 底层引擎:MRV2 成熟 + 零气泡异步调度,推理性能的天花板在抬高
- 加速方向:隐藏状态提取打通训练管道,推测解码从"拿来就用"进化到"定制优化"
- 模型生态:Gemma 4 首日四平台支持,新模型接入速度肉眼可见地在加快
- 硬件覆盖:B300/GB300 首日适配、ROCm 持续完善、TPU/XPU 补强
对于我们用 vLLM 的人来说,最直接的建议:
- 如果你在用推测解码,v0.19.0 必升——零气泡异步调度合体后,吞吐提升是白捡的
- 如果你在跑多模态模型,ViT CUDA 图 + MRV2 多模态推测解码,延迟会有可感知的改善
- 如果你被显存困扰,试试 CPU KV 缓存卸载——长上下文场景下这是个救命功能
- MRV2 该提上日程了,虽然 LoRA 还没支持,但纯推理场景已经生产就绪
#vLLM #大模型推理 #Gemma4 #推测解码 #ModelRunnerV2
制作不易,如果这篇文章觉得对你有用,可否点个关注。给我个三连击:点赞、转发和在看。若可以再给我加个🌟,谢谢你看我的文章,我们下篇再见!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-07,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号