Nat. Methods | 蛋白表征不确定性的跨模型与跨任务量化

Nat. Methods | 蛋白表征不确定性的跨模型与跨任务量化

DrugAI
发布于 2026-04-13 15:42:41
发布于 2026-04-13 15:42:41
DRUGONE
蛋白语言模型产生的嵌入表示已成为连接序列与结构、功能等生物学任务的重要桥梁,但这些表示本身的可靠性长期未被系统评估。研究人员提出一种模型无关的方法,用于量化蛋白嵌入的不确定性,即通过计算嵌入空间中随机(非生物)序列在邻域中的占比,来评估其生物学有效性。研究发现,低质量嵌入往往无法捕获真实生物学信号,其向量特性甚至与随机序列难以区分。该方法能够在下游分析前对嵌入进行筛选,从而显著提升预测可靠性,并为蛋白语言模型的应用提供统一的质量控制框架。

随着语言模型从自然语言处理扩展至生物序列建模,蛋白嵌入逐渐成为理解分子功能与结构的重要表示方式。这些嵌入能够在低维空间中编码蛋白序列信息,并广泛应用于相似性搜索、功能注释及性质预测等任务。然而,与传统机器学习预测不同,嵌入本身通常缺乏显式的不确定性或置信度评估。
研究人员指出,这一缺陷可能带来严重后果:如果嵌入本身未能正确表达生物学信息,其误差将被放大并传播至所有下游任务。相比之下,传统基于序列比对的方法能够通过进化保守性提供可靠性评估,而蛋白语言模型缺乏类似机制。此外,由于训练数据覆盖不完整以及模型优化目标的限制,嵌入空间本身存在多种可能映射方式,每个蛋白在该空间中的位置都不可避免地包含不确定性。
因此,建立一种与模型结构和任务无关的嵌入质量评估方法,对于提升蛋白语言模型的可信度和可解释性具有关键意义。
方法
研究人员提出随机邻居评分(RNS),通过统计某一蛋白嵌入在其k个最近邻中属于随机序列的比例来量化不确定性。为此,构建随机序列数据集作为“非生物对照”,并将其嵌入同一潜在空间中。随后,通过计算每个蛋白在该空间中与随机序列的邻近程度,评估其嵌入是否具有生物学意义。该方法无需依赖具体模型结构或下游任务,可适用于不同蛋白语言模型。
结果
嵌入质量与结构预测性能密切相关
研究人员首先分析了嵌入不确定性与结构预测质量之间的关系。结果显示,高质量结构预测对应的嵌入与随机序列明显区分,而低质量预测的嵌入则更接近随机空间,表现出较弱的生物学信息表达能力。
从图1可以看到,随着结构预测质量下降,嵌入与随机序列的相似性显著增加,并在潜在空间中逐渐重叠,这表明低质量嵌入趋向于“随机化”。
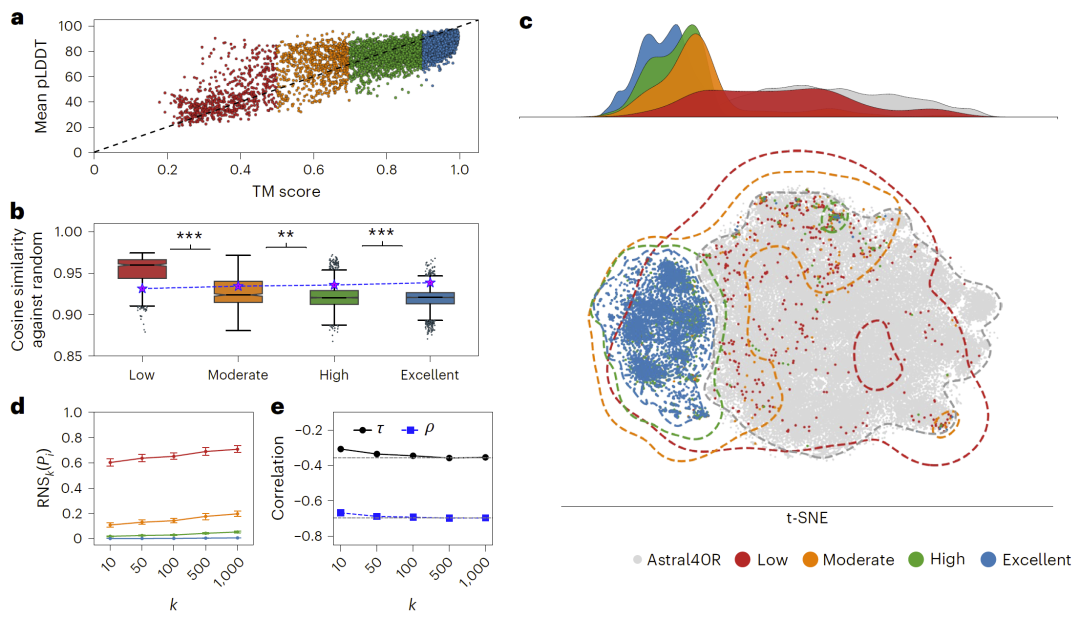
图1: 蛋白结构预测质量与嵌入确定性之间的关系。
存在“嵌入垃圾空间”现象
通过降维可视化,研究人员发现蛋白嵌入空间中存在类似“垃圾区”的区域,随机序列及低质量嵌入往往集中于此。这一现象说明,当模型未能充分学习序列信息时,其嵌入会退化为缺乏生物意义的表示。
基于这一观察,研究人员提出RNS作为衡量嵌入质量的核心指标,并验证其能够有效区分高质量与低质量嵌入。
RNS与模型置信度及结构指标相关
进一步分析表明,RNS与结构相似性指标呈负相关关系,即不确定性越高,结构预测质量越低。此外,RNS与模型内部置信度指标存在一定关联,但不依赖于具体模型输出,因此具有更强的通用性。
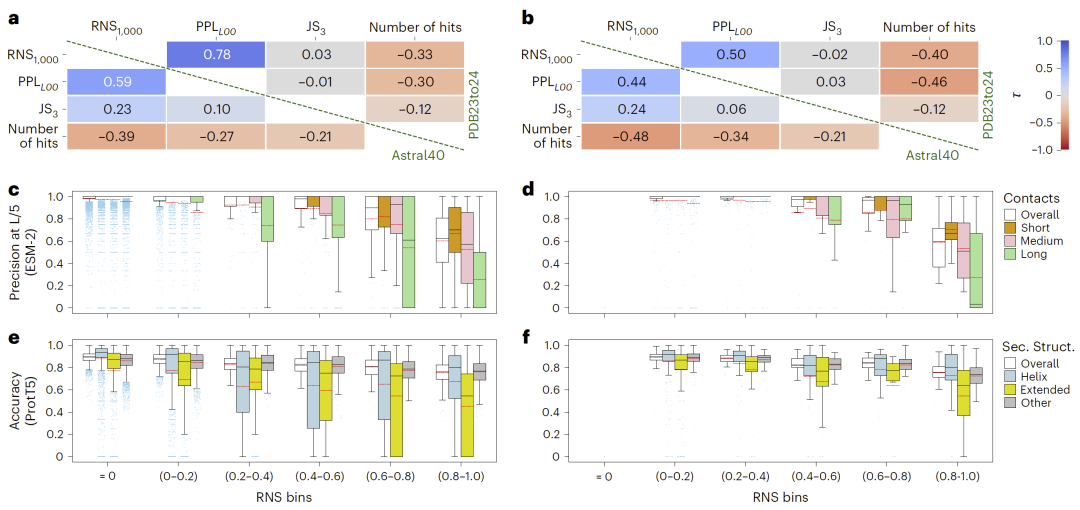
图2: 较高的RNS对应更大的不确定性及更低的下游预测准确性。
嵌入不确定性影响下游预测性能
研究人员评估了嵌入不确定性对多种下游任务的影响,包括残基接触预测和二级结构预测。结果显示,随着RNS增加,模型预测性能显著下降。
例如,在接触预测任务中,高不确定性嵌入对应的预测精度显著降低,尤其是在长距离相互作用预测中影响更为明显;在二级结构预测中,虽然影响较弱,但仍呈现一致趋势。
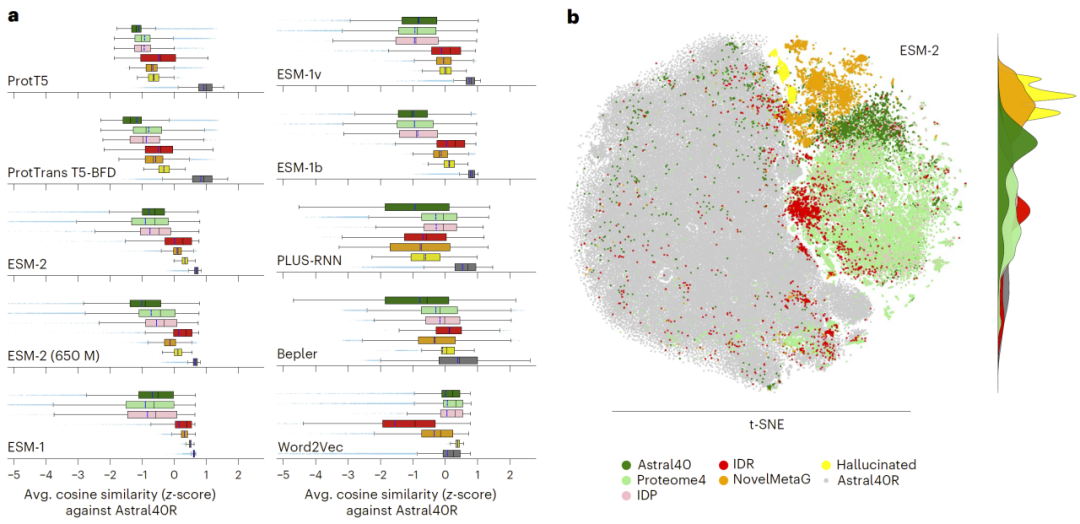
图3: 蛋白语言模型潜在表示中的不确定性在不同蛋白数据集间的差异。
不同模型与数据集中的不确定性差异
研究人员在多种蛋白语言模型和不同数据集上评估RNS,发现不同模型在不同类型序列上的表现存在显著差异。例如,结构化蛋白通常具有较低不确定性,而无序区域(IDR)则更难被准确表示,表现出更高RNS值。
此外,对于新颖序列(如宏基因组数据或生成序列),部分模型仍能保持较低不确定性,说明其具备一定泛化能力。
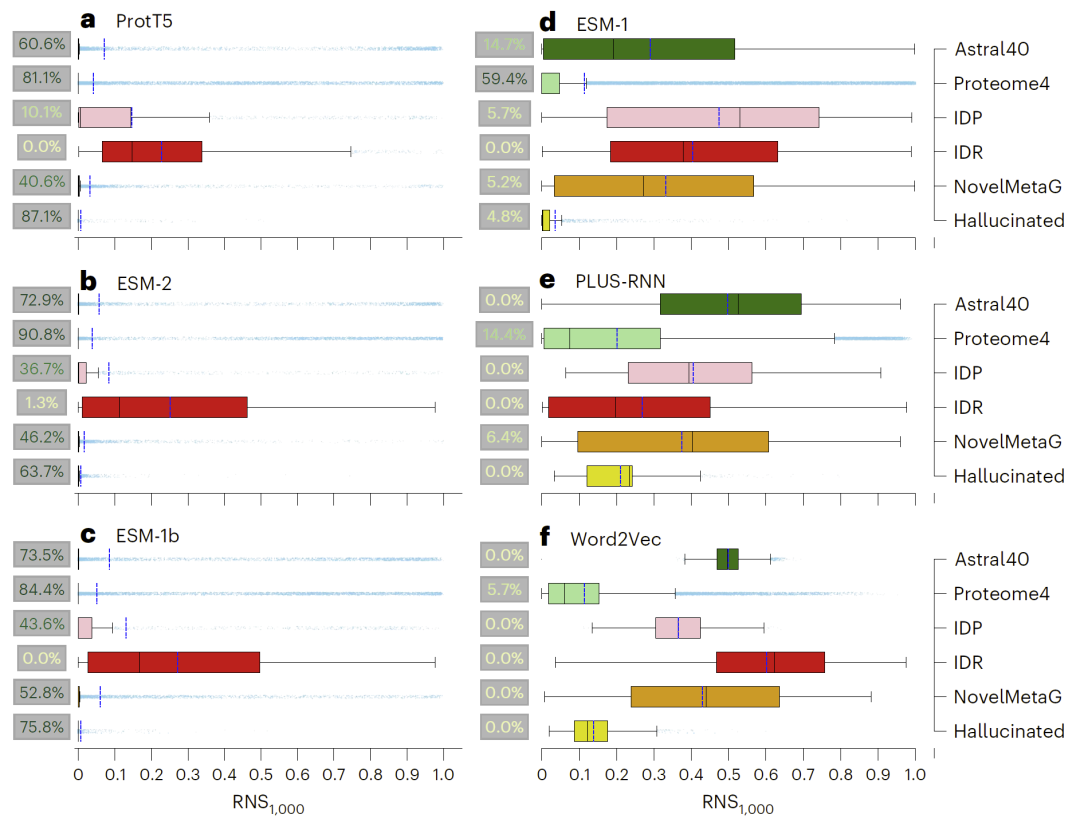
图4: RNS在不同蛋白数据集与蛋白语言模型中的嵌入不确定性评估。
人类蛋白组中的未充分学习区域
研究进一步发现,即使在人类蛋白组中,仍有相当比例的蛋白嵌入处于高不确定性状态。这些区域对应模型未充分学习的序列空间,也限制了下游任务的预测能力。
在变异效应预测任务中,仅当蛋白嵌入具有较低不确定性时,模型才能准确区分致病与非致病突变;而高不确定性区域的预测性能接近随机水平。这一结果强调了嵌入筛选的重要性。
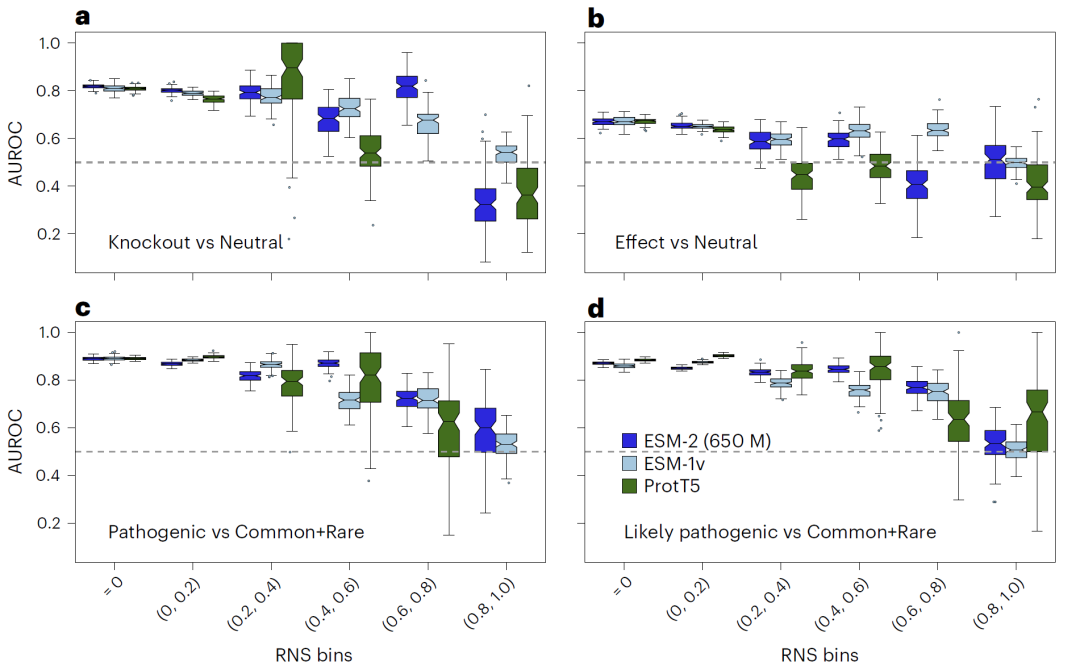
图5: 基于RNS筛选可提升变异分类任务的性能。
讨论
研究人员系统性地揭示了蛋白嵌入中普遍存在的不确定性问题,并提出RNS作为一种通用、模型无关的量化方法。研究结果表明,嵌入质量直接决定了下游任务的性能上限,因此在使用蛋白语言模型之前进行嵌入评估具有重要意义。
该方法不仅能够识别模型未充分学习的序列区域,还可用于指导数据筛选、模型选择及下游任务优化。此外,研究还表明,不同模型在不同数据分布上的表现差异显著,强调了“没有最优模型,只有最适合任务的模型”。
总体而言,该工作为蛋白语言模型的可靠应用提供了关键工具,并提出在科学领域中推广嵌入质量评估的重要性,为未来基础模型的发展提供了新的方向。
整理 | DrugOne团队
参考资料
Prabakaran, R., Bromberg, Y. Quantifying uncertainty in protein representations across models and tasks. Nat Methods (2026).
https://doi.org/10.1038/s41592-026-03028-7

内容为【DrugOne】公众号原创|转载请注明来源
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-03,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号