Exp. Mol. Med. | 综述: 大语言模型驱动的生物与化学研究

Exp. Mol. Med. | 综述: 大语言模型驱动的生物与化学研究

DrugAI
发布于 2026-04-13 15:50:25
发布于 2026-04-13 15:50:25
DRUGONE
人工智能正在通过提供适应生物系统复杂性的可扩展计算框架,重塑生物医学研究。在这一变革中,生物/化学语言模型,尤其是大语言模型,正在将分子结构重新定义为一种可以被计算处理的“语言”。研究人员系统梳理了这些模型在生物与化学领域中的发展,从分子表示到分子生成与优化的演进路径。
本文综述了生物大分子与小分子化合物的关键表示方式,包括蛋白质和核酸序列、单细胞数据、基于字符串的化学表示、图结构编码以及三维点云表示,并分析了它们在人工智能中的优势与局限。同时,研究人员还讨论了核心模型架构,如类似BERT的编码器、类似GPT的解码器以及编码器–解码器结构,并介绍了自监督学习、多任务学习和检索增强生成等预训练策略。
在应用层面,文章涵盖蛋白质结构与功能预测、蛋白设计、基因组分析、小分子性质预测、分子生成、反应预测与逆合成等方向。最后,研究人员展望了基于智能体的交互式AI系统在自动化科研中的潜力,并讨论了未来发展中的技术、伦理与监管问题。

大语言模型基于深度神经网络架构,并在海量文本语料上训练,在语言理解、生成和推理方面取得了突破性进展。尽管最初应用于自然语言,这些模型的核心思想同样适用于科学领域中的符号数据建模,因此在生物和化学领域引起了广泛关注。
科学研究依赖于对物理与生物系统结构和行为的形式化表达。然而,这些表达方式往往与语言模型的统计结构并不一致。因此,如何让语言模型更好地适配科学数据表示,成为关键问题。
大语言模型之所以表现出色,并非源于对单个符号的理解,而在于其对符号组合统计规律的建模能力。在科学领域,模型是否能够正确推断性质,很大程度上取决于输入表示是否有效编码了底层结构。因此,表示方式并非附属因素,而是决定模型能力的核心。
此外,模型规模与数据规模同样决定了模型的性能与涌现能力。科学领域中的语言模型,其成功依赖于模型架构、数据规模以及表示方式之间的协同作用。
随着领域特定数据集的增长,如蛋白质数据库与化学数据库,语言模型在生物与化学中的应用得到了快速发展。然而,目前研究仍较为分散,跨领域系统比较仍然不足。本文的核心目标在于系统梳理这些方法,并分析其发展现状与未来挑战。
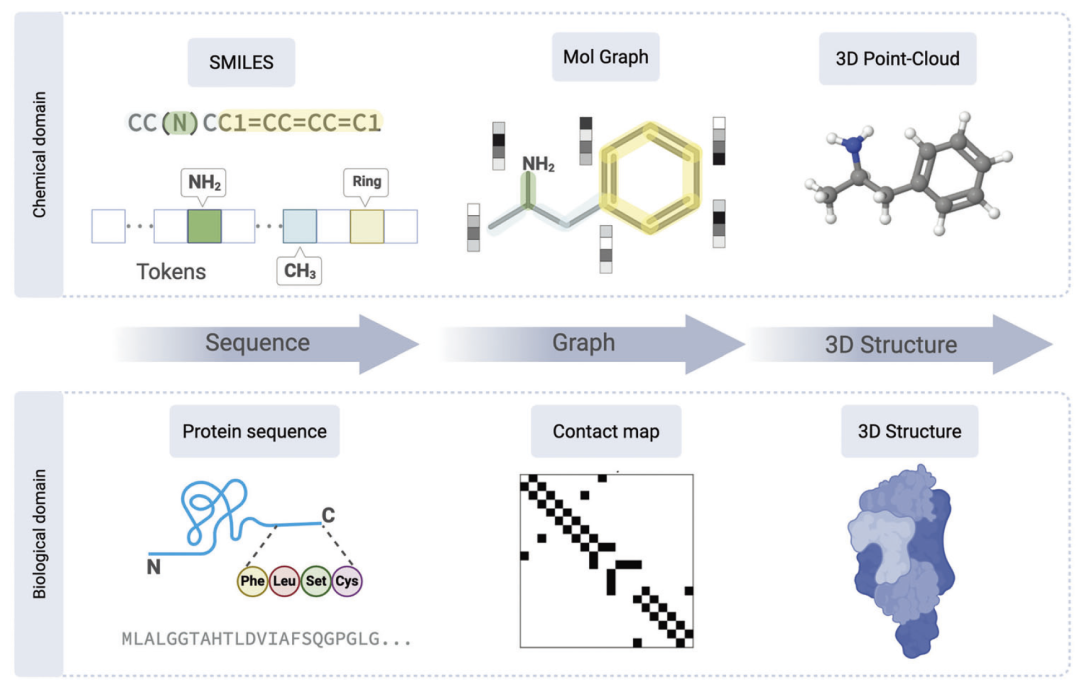
图1:分子表示方式比较。
生物语言模型
大语言模型的成功为生物数据分析提供了全新范式。在生物领域,各类数据如蛋白质序列、结构、核酸序列以及物种信息,都被用于语言模型建模。
蛋白质语言模型
蛋白质的序列特性使其天然适合语言建模。早期模型如ProtBERT、MSA Transformer和ProtTrans,借鉴自然语言处理方法,探索不同输入形式与模型结构。
随后,ESMFold在不依赖多序列比对的情况下实现了接近AlphaFold2的结构预测精度,展示了语言模型捕捉进化信息的能力。ProtMamba则进一步表明,蛋白语言建模可以摆脱注意力机制,通过状态空间模型处理长序列。
在蛋白设计方面,生成模型发挥了重要作用。例如ProGen通过条件标签控制序列生成,而后续模型进一步提升了结构与功能的协同建模能力。近年来,扩散模型也被引入蛋白结构生成,如RFdiffusion通过引入空间对称性约束,提高了生成结构的物理合理性。
蛋白质结构模型
蛋白质结构预测传统依赖实验方法,但成本高且速度慢。序列数量远超结构数据,导致结构预测需求迫切。
AlphaFold与AlphaFold2通过引入Evoformer模块,实现了对MSA和残基关系的高效建模。该模块本质上是一种生物特化的Transformer结构,能够捕捉进化信息。
结构模块则实现从序列到三维结构的端到端预测,使预测精度接近实验结果。这一突破标志着AI在结构生物学中的重大进展。
此外,ColabFold与Phyre2等平台提升了模型的可访问性,使高精度预测更加普及。
核酸语言模型
DNA仅由四种碱基组成,相比蛋白质信息密度更低,使建模更加困难。
早期方法使用CNN或RNN,但难以捕捉长程依赖。DNABERT引入基于Transformer的k-mer建模方法,提高了表示能力。后续模型采用BPE等分词方法,进一步优化性能。
新一代模型如Caduceus与HyenaDNA通过改进架构,支持长序列建模,并在调控区域预测等任务中表现优异。
单细胞语言模型
单细胞数据并非天然序列数据,因此需要对基因进行排序或嵌入建模。
scBERT与Geneformer通过对基因表达排序,实现了细胞类型识别。scGPT进一步实现基因与细胞层级的联合建模,在多任务中达到最优性能。
同时,通用LLM也被用于生物知识注入,例如GPT-4可以通过文本描述完成细胞类型注释。这类方法结合了知识驱动与数据驱动的优势。
生物分子表示与分词策略
生物分子可以通过序列、结构、图结构及功能注释等多种方式表示。不同表示方式决定模型可学习的信息类型。
分词策略同样关键,从k-mer到结构感知tokenization的发展,显著提升了模型性能。
生物语言模型的应用
在分子细胞生物学中,模型逐渐从单一模态向多模态发展。例如ESM3同时建模序列、结构与功能,体现了统一建模趋势。
多模态模型如BiomedGPT和Tx-LLM,可以整合文本、结构与序列数据,支持跨模态推理与医学问答。
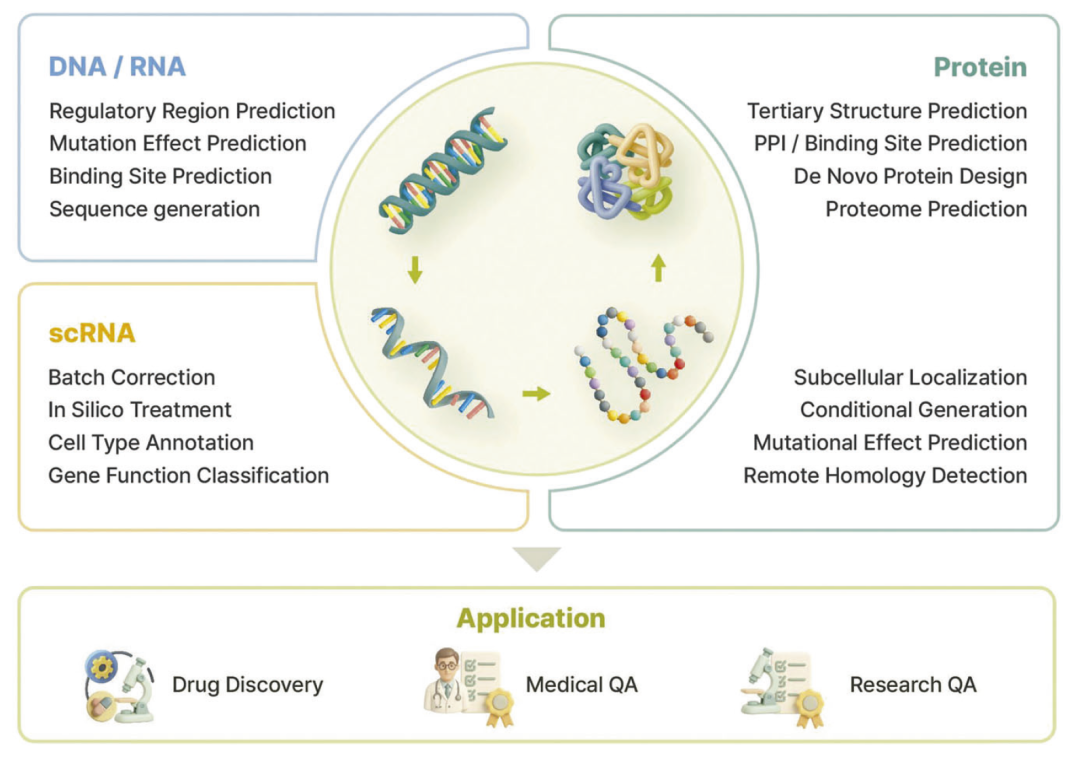
图2:BLM下游任务。
化学语言模型
化学语言模型通过SMILES等表示学习小分子的结构–性质关系,是药物发现的重要工具。
模型类型
化学语言模型主要分为编码器、解码器以及编码器–解码器结构。
编码器模型用于分子表示与性质预测,例如ChemBERTa。
解码器模型用于分子生成,如MolGPT。
编码器–解码器模型则适用于反应预测与逆合成。
此外,多模态模型正在整合图结构、文本与3D信息,实现更全面的分子建模。
多模态模型
化学信息具有天然多模态特性,包括文本、图结构与三维结构。模型如Mol-LLaMA与GIT-Mol通过融合多模态表示,实现跨模态推理。
预训练与微调策略
自监督学习是基础方法,如掩码语言建模。
多任务学习通过共享知识提高泛化能力。
检索增强生成通过引入外部知识减少幻觉。
参数高效微调方法(如LoRA)提升了模型适应能力。
分子表示
SMILES是最常用表示,但存在非唯一性与缺乏空间信息的问题。
图表示提供拓扑结构信息。
3D点云表示则能够捕捉空间几何特征,是当前重要发展方向。
分词策略
化学分词需要考虑原子与键的语义。传统字符级方法存在问题,因此提出了Atom-level等改进方法。
应用
化学语言模型广泛应用于药物发现,包括性质预测、分子生成、反应预测与毒性评估。
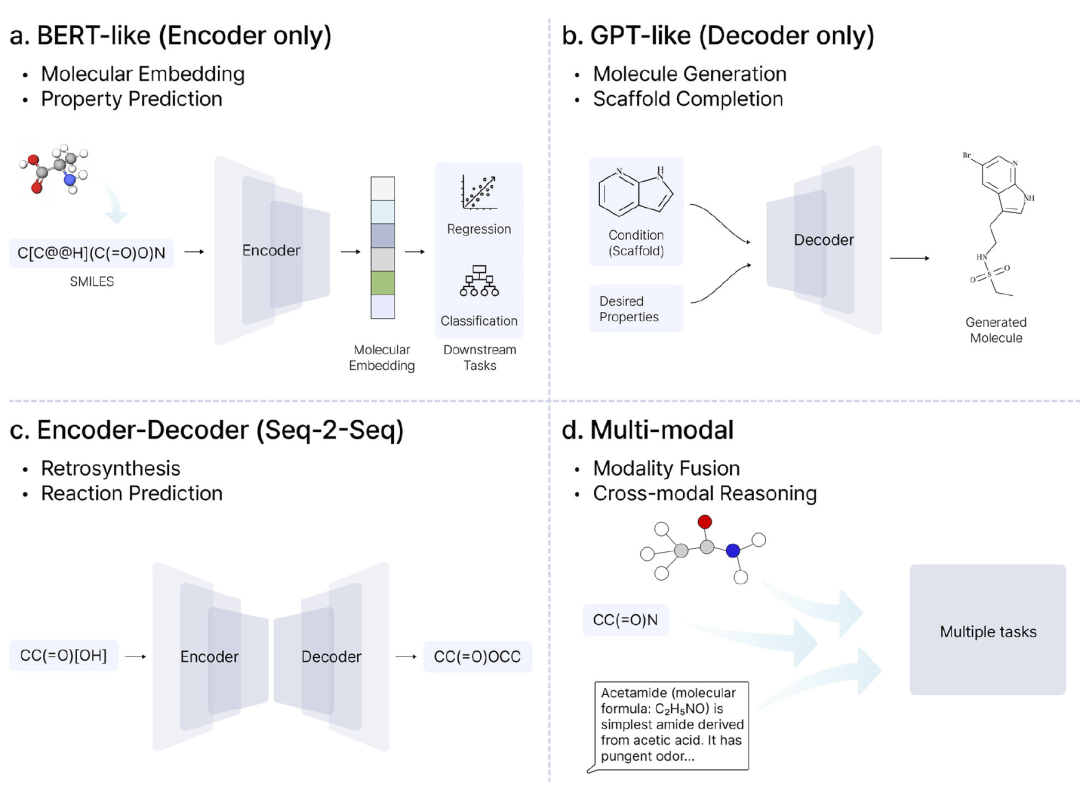
图3:CLM模型架构。
数据集与基准
模型性能高度依赖数据质量。常用数据包括:
- 化学数据库(如ZINC、ChEMBL)
- 反应数据(如USPTO)
- 生物医学语料(如PubMed)
- 医学QA数据集
这些数据支撑了从分子预测到临床问答的多种任务。
LLM在生物与化学中的应用方式
提示工程是最简单的应用方式,可用于SMILES转换与反应预测,但存在不稳定性。微调方法通过引入领域数据,提高模型性能。
更进一步,LLM与智能体系统结合,实现自动化科研。例如ChemCrow与Chemputer等系统,能够执行多步骤实验流程。
结论
大语言模型正在推动分子科学进入新的研究范式,将生物与化学系统统一为可计算的“语言”。
这一进展的核心在于表示学习,即如何将复杂的分子信息转化为模型可理解的形式。
未来的发展方向包括:
- 多模态统一模型
- 更强的生物化学知识融合
- 更标准化的评估体系
- 更高的可解释性
同时,基于智能体的系统将推动科研自动化,使AI成为假设生成与实验设计的重要工具。
总体而言,生物与化学语言模型有望成为分子科学的基础平台,显著加速“设计–构建–测试–学习”循环。
整理 | DrugOne团队
参考资料
Ashyrmamatov, I., Gwak, S.J., Jin, SY. et al. A survey on large language models in biology and chemistry. Exp Mol Med (2026).
https://doi.org/10.1038/s12276-025-01583-1

内容为【DrugOne】公众号原创|转载请注明来源
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-12,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号