一条SQL看透两种数据库存储哲学


在信创项目中做数据库国产化改造时,你是否有过这样的疑惑:同样是SELECT id FROM tb1 WHERE c1 = 'a',为什么在MySQL里跑飞快,到Oracle类的数据库里就偶尔卡顿?明明都是建索引,不同数据库的执行逻辑却天差地别?
答案藏在索引组织表(IOT)和堆表(Heap Table)的底层差异里。这不是简单的语法区别,而是MySQL、Oracle、SQL Server三种数据库存储哲学的根本分野。
读完这篇文章,你将理解:
- 索引组织表(IOT)和堆表(Heap Table)的核心差异是什么
- SELECT id FROM tb1 WHERE c1 = 'a' 在两种架构下分别如何执行
- 索引应该怎么建、为什么这样建
一、先搞懂:堆表vs索引组织表,到底是什么?
1. 堆表(Heap Table):数据“随手扔”的存储方式
堆表是最直观的存储逻辑是数据页之间没有预设顺序,新插入的行可能被放在任何有空闲空间的数据页里,像把文件随意堆在抽屉里,毫无规律。

代表数据库:
- Oracle:默认所有普通表都是堆表
- SQL Server:建表不指定聚集索引时,默认是堆表
- MySQL MyISAM:也是堆表结构
核心特点:
- 数据行没有固定顺序,全表扫描要读所有数据页
- 访问单行数据通常需要额外索引
- 主键只是约束,数据存储和主键无关
2. 索引组织表(IOT):数据即索引,索引即数据
索引组织表里,数据行严格按主键顺序存在主键B+Tree的叶子节点中。没有独立的“数据区域”,主键索引的叶子节点直接存完整数据行,数据和索引合二为一。
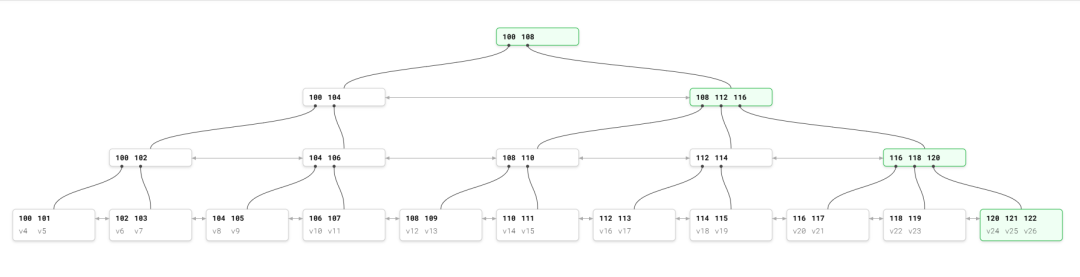
相关历史文章中有索引的介绍可以参考:
模糊搜索c1 like '%a%'真的都不能走索引么
代表数据库:
- MySQL InnoDB:默认所有表都是IOT(这是关键!);
- Oracle:需通过ORGANIZATION INDEX子句手动创建IOT。
核心特点:
- 表数据完全靠主键顺序组织
- 主键既是查询入口,也是数据存储载体
- Oracle要求IOT必须有主键,InnoDB无显式主键时会自动生成隐藏主键(6字节ROWID)
二、核心差异:一张表看清IOT和堆表的区别
维度 | 索引组织表(IOT) | 堆表(Heap) |
|---|---|---|
数据存储顺序 | 按主键B+Tree叶子节点顺序存储 | 无顺序,按插入顺序散布在任意数据页 |
主键角色 | 主键=数据的组织维度,数据存储在主键索引中 | 主键仅是约束,数据可以独立于主键存储 |
辅助索引叶子节点 | 存储主键值(而非ROWID/物理地址) | 存储ROWID/物理指针(页号+槽号) |
聚集索引 | 主键本身即聚集索引,无需单独创建 | 需显式创建聚集索引来指定数据顺序 |
没有主键时 | 自动选择第一个非空唯一索引作为主键 | 堆表无主键时,数据以堆形式存在 |
范围查询(主键) | 高效,直接顺序扫描叶子节点 | 需通过聚集索引快速定位 |
插入速度 | 可能受B+Tree维护开销影响 | 通常更快(仅追加到空闲页) |
随机插入 | 可能引发B+Tree叶子节点分裂 | 可直接写到任意空闲页 |
空间利用 | B+Tree结构有少量内部开销 | 可能有页面空闲空间碎片 |
三、SELECT id FROM tb1 WHERE c1='a' 到底怎么执行?
这是最核心的问题,也是最能体现底层差异的场景,我们分两种架构拆解。
1. MySQL InnoDB(IOT)执行逻辑
先看表结构:
CREATE TABLE tb1 (
id INT PRIMARY KEY, -- 主键
c1 VARCHAR(10),
c2 INT
);
CREATE INDEX idx_c1 ON tb1(c1); -- c1 上建辅助索引辅助索引idx_c1的叶子节点存储「c1值+主键id」,所以执行SELECT id FROM tb1 WHERE c1 = 'a'时:
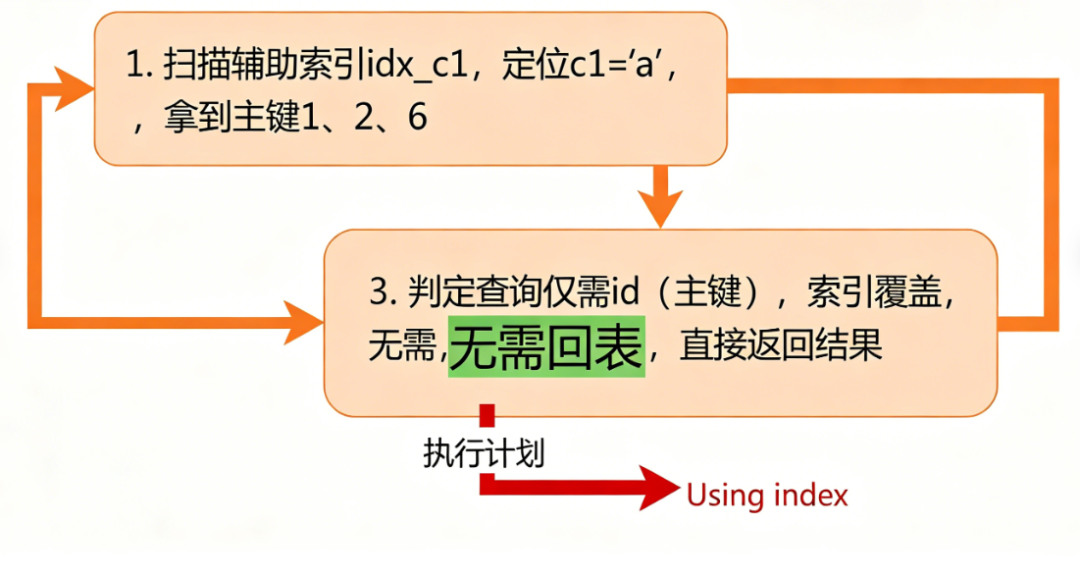
执行步骤:
- 扫描辅助索引idx_c1的B+Tree,定位到c1='a'的叶子节点,提取对应的主键值(比如1、2、6);
- 由于查询只需要id(主键),辅助索引已包含该信息,直接返回结果(索引覆盖,无需回表)。

对应的执行计划(关键字段):
- type = ref(索引范围扫描)
- key = idx_c1(使用c1索引)
- Extra = Using index(索引覆盖,无回表)
如果查询 SELECT *(全字段),则需要用主键值回表查主键B+Tree
2. Oracle堆表执行逻辑
表结构:
CREATE TABLE tb1 (
id NUMBER PRIMARY KEY,
c1 VARCHAR2(10),
c2 NUMBER
);
CREATE INDEX idx_c1 ON tb1(c1); -- c1 上建辅助索引Oracle辅助索引叶子节点存储「c1值+ROWID」(物理地址:文件号+块号+槽号),执行SELECT id FROM tb1 WHERE c1 = 'a'时:
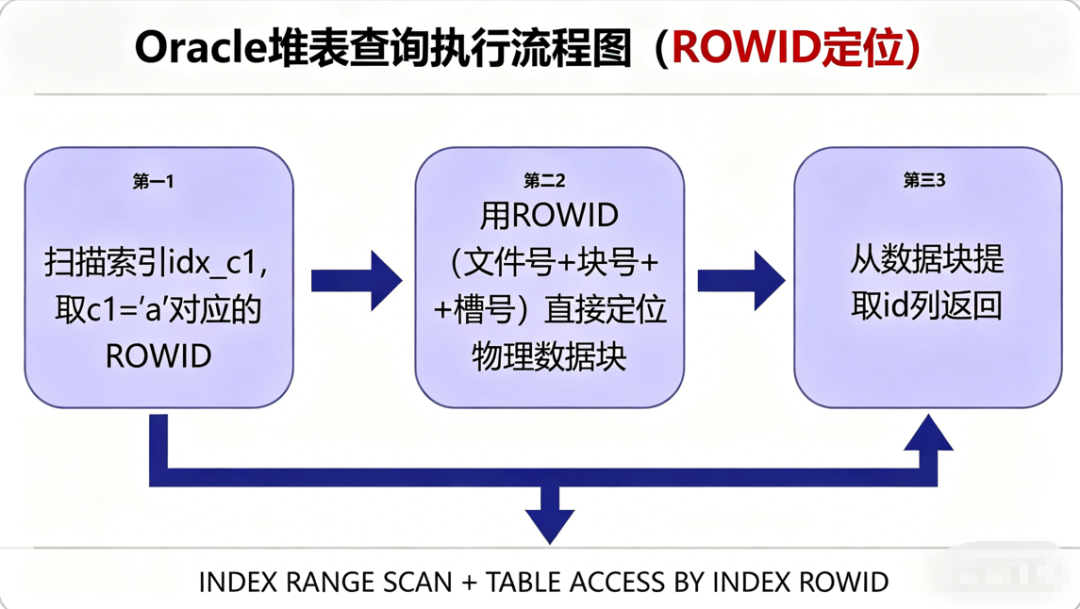
执行步骤:
- 扫描索引idx_c1,找到c1='a'对应的所有ROWID(比如(1,100,1)、(1,105,1))
- 通过ROWID直接定位数据行的物理位置
- 从数据行中提取id列,返回结果

添加了组合索引后
CREATE INDEX idx_c1_id ON tb1(c1,id);执行计划如下(走索引覆盖)

四、索引该怎么建?
1. MySQL InnoDB索引设计原则
原则1:善用覆盖索引,避免回表
InnoDB辅助索引天然包含主键,查询主键列时无需额外设计,但查其他列需建复合索引:
-- 经常查 c1='a' 的 id + c2 → 建复合覆盖索引
CREATE INDEX idx_c1_covered ON tb1(c1, c2);
-- 查询时 Extra = Using index,完全无回表
SELECT id, c2 FROM tb1 WHERE c1 = 'a';原则2:主键越小越好
主键会存在所有辅助索引中,避免用UUID/长字符串:
-- 推荐:自增整数主键(8字节)
CREATE TABLE orders (id BIGINT AUTO_INCREMENT PRIMARY KEY);
-- 慎用:UUID 主键(36字节,每个索引都要存)
CREATE TABLE orders (id VARCHAR(36) PRIMARY KEY);原则3:遵循最左前缀原则
复合索引(a,b,c),优先把等值查询列放前面:
-- 高效:等值+等值+范围
WHERE a = 'x' AND b = 'y' AND c > 10
-- 低效:范围列在中间,后面的索引失效
WHERE a = 'x' AND b > 'y' AND c = 'z'2. Oracle/SQL Server堆表索引设计原则
原则1:Oracle 用复合索引实现覆盖,减少ROWID访问
-- 建 (c1, id) 复合索引,查询时仅扫描索引
CREATE INDEX idx_c1_id ON tb1(c1, id);
SELECT id FROM tb1 WHERE c1 = 'a';原则2:SQL Server巧用INCLUDE子句
堆表建非聚集索引时,用INCLUDE存额外列(不参与排序,减小索引体积):
CREATE INDEX idx_c1 ON tb1(c1) INCLUDE (id);原则3:Oracle慎用IOT,SQL Server合理选聚集索引
- Oracle:仅对“主键查询占比极高”的表建IOT(ORGANIZATION INDEX);
- SQL Server:聚集索引选“唯一、稳定、常做范围查询”的列(如订单时间),避免选性别、状态等低基数列。
五、IOT和堆表该怎么选?
架构 | 适用场景 | 典型案例 |
|---|---|---|
索引组织表(IOT) | 大量主键点查询、高并发顺序写入、读多写少、主键范围查询、需事务(ACID) | 电商订单表、用户表、CMS 文章表 |
堆表(Heap) | 大量随机插入、ETL批量加载、宽表少索引、临时表/中间表、日志归档 | ETL 临时表、日志收集表、历史数据归档表 |
六、总结
- IOT(MySQL InnoDB):数据按主键排序,索引即数据,主键是数据的 “唯一标识”;
- 堆表(Oracle/SQL Server):数据无序存储,索引是路标,物理地址(ROWID)是数据的 “最终归宿”。
没有绝对的优劣,只有适合的场景。 懂底层,才能写出高效SQL,做出正确的架构决策。
💬 互动时间:你在信创项目工作中遇到过因数据库存储结构导致的性能问题吗?留言区聊聊你的解决方案~
如果觉得这篇内容有用,记得点赞 + 收藏,转发给身边的研发小伙伴!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-11,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号