AI 设计多肽:生化研究工具的范式革命

AI 设计多肽:生化研究工具的范式革命

DrugIntel
发布于 2026-04-13 18:02:15
发布于 2026-04-13 18:02:15

文献来源: Hong L, Vincoff S, Chatterjee P. AI-Designed Peptides as Tools for Biochemistry. Biochemistry, 2026. DOI: 10.1021/acs.biochem.6c00138 作者单位: 宾夕法尼亚大学生物工程系 & 计算机与信息科学系(通讯作者:Pranam Chatterjee) 发表期刊: Biochemistry(ACS)
目录
- 1. 研究背景:多肽的独特生态位与历史局限
- 2. AI 设计多肽的方法论体系
- • 2.1 表征学习(Representation Learning)
- • 2.2 性质预测模型(Property Prediction)
- • 2.3 生成算法(Generative Algorithms)
- • 2.4 基于结构的设计范式
- • 2.5 基于序列的设计范式
- 3. 多肽作为生化工具的应用场景
- 4. 方法选择建议
- 5. 展望与挑战
1. 研究背景
1.1 抗体的统治与局限
抗体长期主导生化研究的亲和试剂市场,支撑着 Western blot、免疫沉淀(Co-IP)、流式细胞术等核心实验技术。然而其固有缺陷日益凸显:
问题维度 | 具体表现 |
|---|---|
批次稳定性 | 不同批次抗体性能差异显著,跨实验室重复困难 |
序列透明度 | 动物免疫来源的多克隆/单克隆抗体序列不公开,结合机制模糊 |
生产周期 | 从免疫到纯化通常需要 3–6 个月 |
应用局限 | 抗体无法穿透活细胞,访问胞内靶点需固定/透化处理 |
优化困难 | 同时优化亲和力、特异性和实验相容性极为耗时 |
重组替代品(scFv、纳米抗体、设计小蛋白)部分解决了上述问题,但仍依赖折叠蛋白骨架和复杂的表达系统。
1.2 多肽的独特生态位
多肽(通常 < 50 个残基)在分子量和功能上处于小分子与蛋白质/抗体之间,具有独特的实验优势:
相比小分子的优势:
- • 分子量更大,可识别蛋白延伸表面(extended protein surfaces)
- • 能与本征无序区域(IDR)和线性基序(linear motifs)结合
- • 可精确共价连接荧光基团、酶或降解元件
相比抗体的优势:
- • 化学合成简单,序列完全透明
- • 免疫原性风险低
- • 合成周期 3–7 天(vs 抗体 3–6 个月)
- • 可进入活细胞(结合细胞穿透肽技术)
- • 高通量合成与筛选成本低
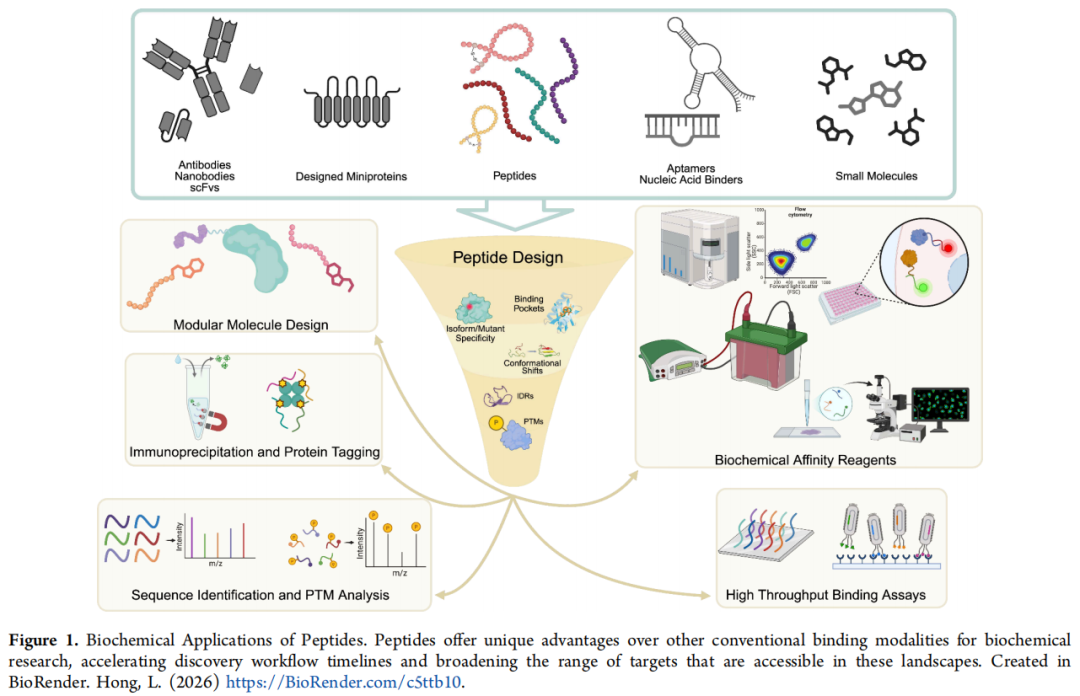
1.3 传统多肽发现的瓶颈
传统的多肽发现流程(噬菌体展示、组合文库筛选、天然结合基序的迭代突变)存在以下根本性局限:
- 1. 劳动密集:每轮筛选需要大量手工工作
- 2. 多目标优化困难:难以同时兼顾亲和力、特异性、溶解性、稳定性
- 3. 靶标受限:难以针对无序区域或缺乏结构信息的靶标
- 4. 物理化学性质差:未经优化的多肽常具有溶解性低、蛋白酶敏感、非特异性结合等问题
AI 的介入正系统性地解决上述瓶颈,推动多肽发现从"筛选驱动"走向"设计驱动"。
2. AI 设计多肽的方法论体系
作者将 AI 多肽设计工具系统划分为三大类核心模型——表征模型、预测模型和生成模型——并在此基础上按设计范式区分为"基于序列"与"基于结构"两大路线。
2.1 表征学习
表征模型通过自监督学习(masked language modeling, MLM)从海量序列数据中学习多肽的物理化学和结构特征,输出高维数值嵌入向量,为下游预测与生成任务奠定基础。
蛋白质语言模型(pLM)
以 ESM-2、ProtT5、ProteinBERT 为代表,在全长蛋白数据集上训练,可自然延伸至由 20 种标准氨基酸组成的多肽。ESM-2 凭借其优秀的结构预测(ESMFold)和序列特征提取能力,成为众多下游工具的骨干编码器。

化学语言模型(CLM)
ChemBERTa、Chemformer 等基于 SMILES 字符串训练,天然支持非标准氨基酸(NCAA)、化学修饰和环状拓扑结构,适用于肽模拟物(peptidomimetics)设计。
多肽专用语言模型(pepLM)
通过微调现有模型或从零训练,专门针对多肽数据优化:
模型 | 词汇表 | 拓扑 | 核心能力 |
|---|---|---|---|
PeptideBERT | 标准氨基酸 | 线性 | 溶解性、溶血性、非污染性预测 |
PepDoRA | SMILES | 线性/环状 | 膜通透性、溶血性、PPI 预测 |
PepLand | SMILES(图神经网络) | 线性/环状 | 细胞穿透、溶解性、结合亲和力 |
HELM-BERT | HELM | 线性/环状 | 膜通透性(环状)、PPI 预测 |
PeptideCLM | SMILES | 线性/环状 | 环状多肽膜扩散预测 |
技术要点: Transformer 的自注意力机制使 pepLM 能建模残基间的长程依赖关系;PepLand 采用图神经网络,将多肽视为二维分子图,是另一条有吸引力的技术路线。预训练表征模型对下游预测和生成任务均有显著的迁移学习效果。
2.2 性质预测模型
性质预测模型是表征学习能力的重要验证手段,也是多目标生成框架中的关键组件(作为奖励函数或推断时采样的引导信号)。
蛋白-多肽相互作用位点预测
- • DELPHI、MEG-PPIs、EGRET:预测靶蛋白上的蛋白-蛋白相互作用位点
- • PepCNN、PepBCL:预测靶蛋白上的通用多肽结合区域
- • PepNN:提供序列(PepNN-Seq)和结构(PepNN-Struct)两种预测途径,可针对特定多肽配体进行靶标相互作用热点预测
物理化学与药学性质预测
PeptiVerse 是该领域的集成平台,可预测多种治疗和实验相关性质:
溶解性 · 溶血性 · 细胞穿透性 · 膜通透性 · 可合成性 · 非污染性 · 结合亲和力 · 半衰期 · 毒性
2.3 生成算法
生成模型是 AI 多肽设计的核心引擎,负责从学习到的分布中采样生成满足约束条件的新序列。
自回归模型(早期方法)
基于 GPT 架构,逐词元生成序列。已成功应用于蛋白和多肽设计(ProGen、ProGen2 等),但从左到右的单向生成限制了全局序列性质的约束施加,难以同时优化多个下游实验指标。
离散扩散模型(Discrete Diffusion)
将序列生成建模为逐步去噪过程的反转:训练时随机掩盖或替换词元(token),推断时从被破坏的序列逐步还原为真实序列。
核心优势:
- • 天然适配离散字母表(氨基酸序列、SMILES)
- • 支持双向上下文,利于全局性质的引导采样
- • 可与强化学习、蒙特卡洛树搜索(MCTS)结合,实现多目标优化
代表工作:PepTune(基于 PepMDLM,结合 MCTS 进行多目标引导采样)、TR2-D2(通过强化学习对扩散分布进行指数倾斜)
流匹配(Flow Matching)
学习从简单基础分布到目标数据分布的时间依赖向量场,实现更快速、更全局协调的序列更新。
- • MOG-DFM:学习多目标 Pareto 前沿的离散流匹配,是 moPPIt 的生成骨架
- • AReUReDi:引入整流更新(rectified updates),在残基级别直接向 Pareto 前沿移动
- • Gumbel-FM:Gumbel-Softmax 与流匹配的结合,适用于目标蛋白序列条件化生成
关键洞见: 离散扩散与流匹配框架均将"学习宽泛的多肽先验"与"将采样引导至任务特定区域"解耦,这一设计原则对于同时优化结合、选择性和物理化学行为的多肽设计尤为有效。
2.4 基于结构的设计范式
基于结构的方法将蛋白质三维空间信息作为设计的核心约束,是最早受益于现代 AI 的多肽设计路线之一。

结构预测与构象采样
折叠算法为结构设计提供原子级分辨率模板:
工具 | 适用场景 |
|---|---|
AlphaFold2 / AlphaFold3 | 单体和多聚体结构预测 |
AlphaFold-Multimer | 蛋白复合物预测 |
RoseTTAFold All-Atom | 支持非标准分子的广义生物分子建模 |
构象集成与动力学模拟:
- • PepFlow:通过超网络条件化扩散模型,直接从多肽能量图景采样构象集合
- • BioEmu:利用生成式深度学习对蛋白平衡系综进行可扩展模拟,提供结合几何的动态视角
三维多肽设计
新一代 AI 方法可直接在三维空间中输出原子坐标与序列:
一般多肽设计(无需靶标输入):
- • HelixDiff:基于评分函数的扩散模型,生成全原子 α 螺旋结构;热点填补模块可引入 D 型氨基酸以提升稳定性
- • AfCycDesign:结合 AlphaFold2 进行环状多肽从头设计与结构条件化重设计;与基序嫁接(motif grafting)工具联用可实现靶向结合
多肽结合物设计(明确以靶标为条件):
工具 | 拓扑 | 核心特性 | 实验验证 |
|---|---|---|---|
RFdiffusion | 线性 | 靶标结构 + 结合位点引导 | 生物物理、结构 |
RFpeptides | 环状 | RFdiffusion 扩展至环状多肽 | 生物物理、结构 |
EvoBind2 | 线性/环状 | 仅需靶标序列(无结构) | 生物物理 |
BindCraft | 线性 | 一步设计功能性蛋白结合物 | 生物物理、细胞、结构 |
BoltzGen | 线性/环状 | 支持共价键、残基约束 | 生物物理、细胞 |
HelixFlow | 线性(L/D) | SE(3)等变全原子流匹配 | 生物物理、细胞 |
CpSDE | 环状 | 谐波 SDE + 原子-键建模 | — |
CP-Composer | 环状 | 几何约束(二硫键等) | — |
CYC_BUILDER | 环状 | 种子片段 + 强化学习 | 生物物理、细胞 |
PXDesign | 线性 | 快速、模块化、高精度 | 生物物理 |
结构化方法的适用条件与局限:
- • ✅ 高质量结构信息可用、靶点有明确结合界面时表现优异
- • ✅ 可加速高亲和力结合物的设计,适用于 pulldown、体外结合测定
- • ❌ 固有局限于结构空间可描述的靶标;对无序区域和缺乏晶体结构的靶点支持有限
2.5 基于序列的设计范式
序列方法在氨基酸序列空间中直接建模结合、结构和物理化学行为,覆盖更广泛的靶标类型和相互作用模式。

蛋白质语言模型驱动的结合物发现
- • SaLT&PepPr:利用 ESM-2 表征,从已知相互作用蛋白中识别并复用线性结合片段,已在 β-连环蛋白等靶标上获得体内验证
- • PepMLM:基于跨度掩码语言模型(span MLM)目标,直接以靶标蛋白序列为条件生成结合多肽;已在亨廷顿突变蛋白、转录因子、病毒磷蛋白、致癌融合蛋白等高难度靶标上完成实验验证
- • PepPrCLIP:借鉴 OpenAI CLIP 框架,实现对 pLM 采样多肽文库的虚拟筛选
特异性约束序列设计
单纯的亲和力对许多生化应用仍不够,需在生成阶段直接编码生物特异性:
- • moPPIt:整合 PepNN-Seq 启发的结合位点预测器,将生成偏向用户定义的靶标表位区域,实现表位特异性多肽的从头生成,可同时用作抑制剂和细胞治疗的结合模块
- • SOAPIA:在训练时显式纳入脱靶蛋白序列,在无结构数据条件下降低交叉反应性,实现异构体/旁系同源物水平的选择性辨别
- • Metalorian:潜在扩散方法,生成选择性结合特定金属离子(如 Cu)的多肽,展示了序列框架对非蛋白结合化学的编码能力
多目标多肽生成
当结合灵活化学语言(SMILES、HELM、CHUCKLES)时,序列设计获得显著增强,可同时优化结合亲和力与多种物理化学性质:
工具 | 词汇表 | 多目标策略 | 核心性质 |
|---|---|---|---|
HELM-GPT | HELM | 强化学习 | 膜通透性 + KRAS 亲和力 |
PepThink-R1 | SMILES | CoT + RL(LLM推理) | LogD、MRT、SIF |
PepINVENT | CHUCKLES | Transformer RL | 溶解性、通透性(含 NCAA) |
PepTune | SMILES | MCTS + 离散扩散 | 亲和力、通透性、溶解性、溶血性 |
TR2-D2 | SMILES | 指数倾斜扩散 | 亲和力、通透性、溶解性、溶血性 |
MOG-DFM | 标准氨基酸 | 离散流匹配(Pareto前沿) | 亲和力、半衰期、溶解性、溶血性 |
moPPIt | 标准氨基酸 | MOG-DFM + 位点预测 | 亲和力、位点特异性、半衰期、溶解性 |
AReUReDi | 标准/SMILES | 整流离散流匹配 | 亲和力、半衰期、溶解性、溶血性 |
SOAPIA | 标准氨基酸 | Siamese 引导生成 | 亲和力 + 脱靶规避 |
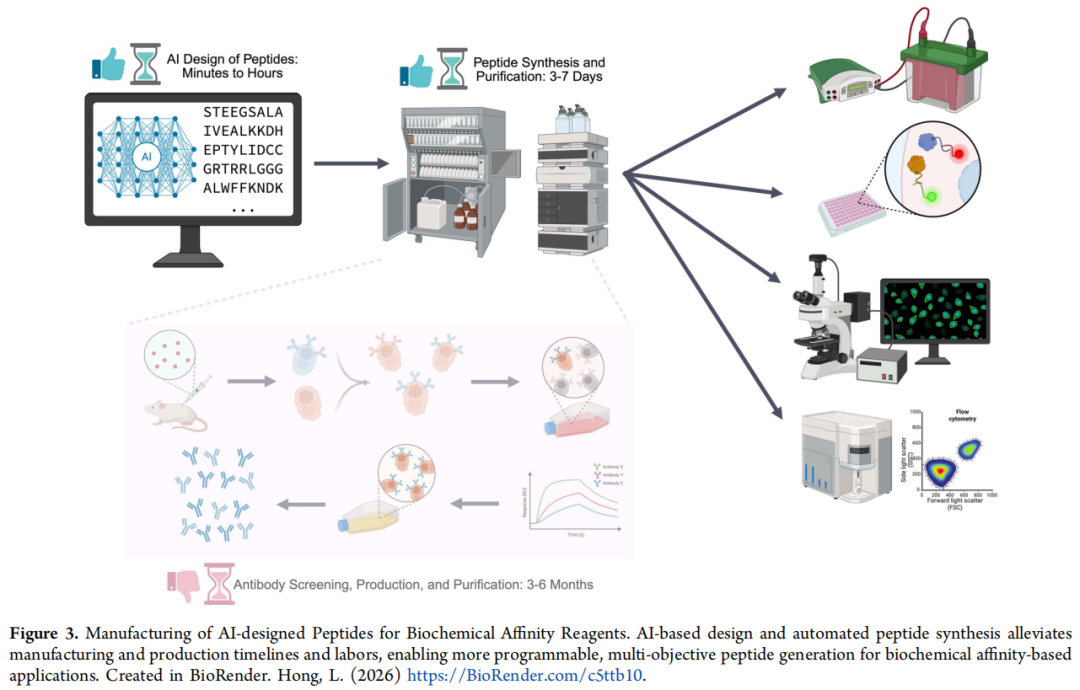
3. 多肽作为生化工具的应用场景
3.1 实验适配亲和试剂
多肽作为亲和试剂的核心优势在于:可在设计阶段即指定实验条件,从而针对特定检测格式生成"开箱即用"的专用试剂。
不同检测格式的设计逻辑
检测格式 | 靶标状态 | 多肽设计要求 |
|---|---|---|
Western blot | 变性蛋白 | 靶向变性后仍暴露的线性表位序列 |
免疫沉淀(Co-IP) | 天然构象(含洗涤剂) | 靶向天然结合界面或亲和标签(HaloTag、6×His、HiBiT) |
流式细胞术 | 天然胞外域 | 控制电荷与疏水性,限制非特异性膜吸附 |
高通量结合测定 | 多种格式 | 需结合 AI 多目标优化,兼顾亲和力与物理化学性质 |
相比抗体的工程优势
由于序列完全已知且化学合成,多肽试剂的结合强度、背景信号和标记化学均可在实验表现不佳时直接调整修改,无需重新筛选新的试剂来源。
3.2 活细胞靶点参与与实时测量
多肽的小分子量使其具备抗体无法比拟的胞内访问能力:
抗体的胞内检测局限:
- • 通常需要固定和透化处理
- • 上述步骤破坏蛋白亚细胞定位信息
- • 无法捕捉瞬时蛋白相互作用
多肽的解决方案:
- • 结合细胞穿透肽(CPP)技术,设计可进入活细胞并稳定保留足够时间以完成靶标结合的多肽
- • 荧光标记的多肽结合物可直接用于胞内流式和成像读数
- • 未标记多肽可用于竞争置换实验,结合标准生化分析评估靶标结合
- • 实现在接近生理状态的条件下测定靶标结合、结合位点占用或竞争性置换
3.3 多肽探针与报告分子
精密设计的多肽底物/探针是众多生化测定的基础,AI 驱动的设计可显著提升选择性和解释性:
酶活性测定:
- • 蛋白酶测定:荧光生成型(fluorogenic)多肽底物,荧光团-猝灭剂 FRET 对
- • 激酶/磷酸酶测定:多肽底物或对接基序,精确设计实现酶家族内的单一成员选择性
修饰型报告分子:
多肽可共价连接各种功能模块,形成追踪多种生物事件的分子报告系统:
- • 荧光团:追踪结合和定位
- • 猝灭剂 / FRET 对:报告蛋白酶裂解、构象变化
- • 光交联剂(photo-crosslinker):捕捉瞬时相互作用
- • 邻近标记手柄:如 HiBiT 标签,实现蛋白丰度的精确定量
关键认识: 在所有上述应用中,序列背景决定了背景信号、动态范围和脱靶效应,多肽设计是保障测定质量的核心变量。
3.4 可编程蛋白质组编辑:诱导邻近策略
这是全文最具远景性的部分,作者将多肽引导的蛋白质组编辑与 CRISPR 对基因组的影响相提并论:
概念框架
CRISPR 成功的核心在于将靶向(gRNA)与执行(Cas9 核酸酶)解耦,使基因组操控变得简单、可编程、广泛适用。多肽引导的诱导邻近策略正在将这一逻辑移植到蛋白质组层面:
用户指定引导多肽 → 融合至效应酶催化结构域 → 招募酶活性至特定靶蛋白 → 实现定向功能调控
无需改动底层 DNA 序列。
代表性实现
蛋白降解系统:
- • uAbs(泛素抗体):引导多肽融合至 E3 泛素连接酶催化结构域(CHIP 等),指导泛素化和降解;SaLT&PepPr、PepMLM、PepPrCLIP 设计的多肽均已用于 uAb 引导
- • PepTACs:多肽-PROTAC 杂合降解分子
蛋白稳定化系统:
- • duAbs(去泛素化酶抗体):引导多肽融合至 OTUB1 去泛素化酶结构域,实现蛋白丰度的稳定化调控;已在体内选择性敲低致病性 β-连环蛋白亚群中验证
其他修饰系统:
- • DUBTACs:去泛素化酶靶向嵌合体,稳定肿瘤抑制因子
- • DEPTACs:靶向磷酸化调控(tau 蛋白磷酸化)
当前技术状态: 大多数实现依赖融合蛋白而非全合成双功能多肽,但随着具有明确亲和力、特异性和胞内相容性的多肽设计变得更为常规,全合成版本有望实现。
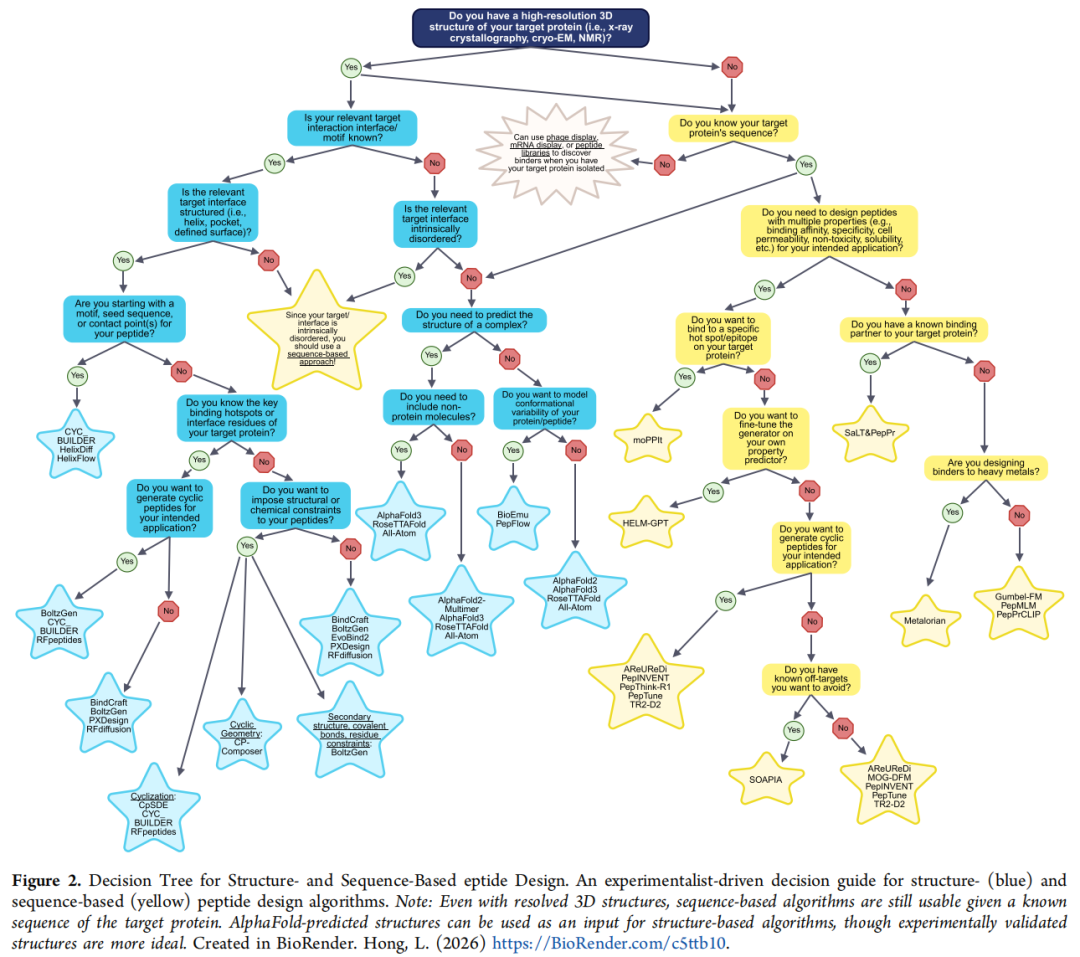
4.方法选择建议
方法选择决策框架
作者在文章图 2 中提供了一棵实验者导向的决策树,核心逻辑如下:
是否有高分辨率三维结构?
├─ 是
│ ├─ 相关界面是否已知且结构化?
│ │ ├─ 是 → 基于结构的结合物设计(RFdiffusion/BindCraft/BoltzGen 等)
│ │ └─ 否 → 界面是否无序?
│ │ ├─ 是 → 序列方法(moPPIt/PepMLM)
│ │ └─ 否 → 考虑预测复合物(AlphaFold-Multimer)
└─ 否
├─ 知道靶标序列?
│ ├─ 需要多目标优化?
│ │ ├─ 是 → 多目标序列方法(moPPIt/PepTune/TR2-D2)
│ │ └─ 否 → 单目标序列方法(PepMLM/PepPrCLIP)
│ └─ 有已知结合热点?→ moPPIt(位点引导生成)
└─ 不知道序列 → 先通过噬菌体展示等发现结合伴侣关键注意事项: 即使有已解析三维结构,序列方法通常仍可使用,且在处理无序靶标时往往表现更优;AlphaFold 预测结构可作为结构方法输入,但实验验证结构更为理想。
5. 展望与挑战
5.1 近期机遇
多目标"实验即用"试剂的规模化生成是当前最直接的贡献方向:
- • 取代对已有抗体的依赖,尤其是在特异性不稳定的应用场景
- • 将多肽发现从序贯试错转变为工程化工作流
治疗级应用的延伸: 相同设计原则将从靶标结合扩展至功能性扰动和细胞环境操控。耦合分子处理与下游生化或细胞状态效应的涌现模型,预示着多肽不仅能作为靶向结合物,还能作为诱导特定生化结果(降解、稳定化、通路调控)的执行器。
5.2 技术挑战
精准预测模型的数据需求: 多目标控制的有效性严重依赖于高精度预训练性质预测器,这些预测器反过来需要高质量、实验产生的生化和物理化学训练数据。实验生物学家与计算团队的紧密合作是突破瓶颈的关键。
非标准氨基酸的扩展: 专门针对翻译后修饰蛋白或特定蛋白家族的表征模型(如 PTM-Mamba、FusOn-pLM)将进一步扩展可访问的选择性相互作用范围。
闭环实验-计算流水线: AI 设计与自动化多肽合成、高通量筛选以及闭环实验反馈的深度整合,将实现多肽试剂的按需生成、筛选与迭代优化。
5.3 远期愿景
在这一范式下,多肽将超越简单的亲和工具,成为将序列设计直接与生化功能和细胞行为挂钩的可编程分子试剂。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-11,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号