ModelEngine思想落地指南:用“智能体 + 插件”构建可复用AI应用.76
原创
ModelEngine思想落地指南:用“智能体 + 插件”构建可复用AI应用.76
原创
未闻花名
发布于 2026-04-14 06:52:49
发布于 2026-04-14 06:52:49
一、引言
在AI应用开发过程中,我们常面临“重复造轮子”、“流程碎片化”、“技术门槛高”三大绊脚难题,不同场景需重新编写数据处理、工具调用逻辑,非专业人员难以参与,复杂流程维护成本高。而基于ModelEngine 的核心思想,正是通过角色化智能体分工、插件化工具集成、双模式开发适配,打通 AI 应用从设计到落地的全链路,让开发效率倍增。
这种思想并非依赖ModelEngine官方框架,而是一套可复现的设计范式:将复杂任务拆分为“专业智能体”,通过标准化插件对接外部工具,同时支持低代码拖拽和代码扩展,兼顾易用性与灵活性。今天我们深入了解ModelEngine的核心思想,并通过“智能合同审查助手” 实践示例,细化分解此思想的核心体现。

二、ModelEngine思想拆解
1. 角色化智能体
让任务专职专责、专人专岗,打破传统单体代码逻辑,将应用拆分为多个有明确角色的智能体,每个智能体只负责单一核心任务,通过数据传递实现协作。
- 优势:解耦复杂逻辑,便于单独调试、迭代和复用,如“数据清洗智能体”可跨数据分析、办公自动化场景复用;
- 核心原则:一个智能体对应一个业务能力,输入输出格式标准化。
2. 插件化工具集成
对接资源无需重复开发,定义标准化插件接口,将 Excel、PDF、大模型、邮件等外部工具封装为插件,智能体通过调用插件完成具体操作,无需关注工具底层实现。
- 优势:插件可跨智能体、跨项目复用,新增工具仅需开发新插件,不改动核心逻辑;
- 核心原则:插件只负责工具调用,业务逻辑沉淀在智能体中。
3. 双模式开发
适配不同技术能力,兼顾非技术人员和开发者需求,支持两种开发模式:
- 低代码模式:通过可视化画布拖拽智能体、插件,配置参数即可搭建流程,适合运营、产品等非技术人员;
- 代码模式:通过编写代码定义智能体和插件,适配复杂业务逻辑,适合开发者。
三、智能体:智能合同审查助手
基于ModelEngine思想,我们构建一款“智能合同审查助手”,实现:上传 PDF/Word 合同→自动解析文本→审查合规风险(如违约责任、争议解决条款)→生成审查报告。示例PyPDF2、python-docx插件库,同时已经本地大模型进行审查和分析。

风险范围释义:
- 违约责任条款:审查赔偿范围、违约金合理性
- 争议解决条款:审查管辖法院、仲裁机构、法律适用
- 其他合规风险点:知识产权、保密条款、不可抗力等
1. 需求拆解与架构设计
1.1 核心需求
- 1. 支持 PDF/Word 合同上传,自动提取文本内容;
- 2. 审查 3 类核心风险:是否缺失违约责任条款、争议解决方式是否明确、付款期限是否清晰;
- 3. 生成结构化审查报告(风险点、修改建议、无风险项),支持 Word 导出。
1.2 架构设计(智能体 + 插件)
组件类型 | 具体组件 | 核心功能 | 依赖插件 |
|---|---|---|---|
智能体 | 文档解析智能体 | 读取 PDF/Word 文本,去除格式干扰 | PDF 插件、Word 插件 |
智能体 | 合规审查智能体 | 识别风险点,生成修改建议 | 大模型插件 |
智能体 | 报告生成智能体 | 整合审查结果,生成标准化 Word 报告 | Word 插件 |
插件 | PDFPlugin | 解析 PDF 文件文本 | PyPDF2 库 |
插件 | WordPlugin | 读取 / 生成 Word 文件 | python-docx 库 |
插件 | LLMPlugin | 调用大模型完成合规审查 | 本地Qwen大模型 |
2. 整体执行流程
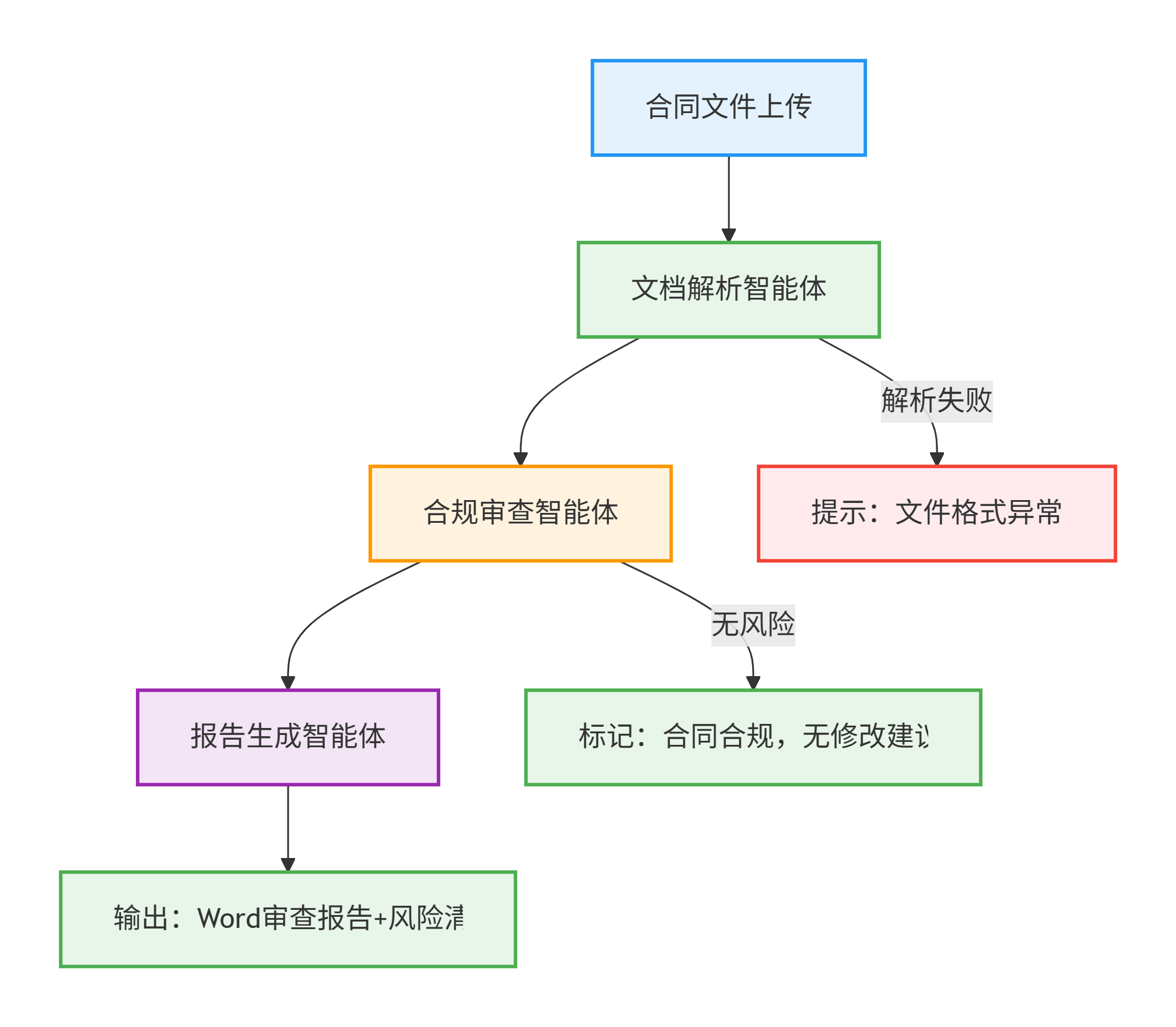
步骤说明:
- 1. 合同文件上传:用户上传PDF/Word合同文件,系统接收并验证文件格式与完整性,支持批量上传和加密传输。
- 2. 文档解析智能体:自动提取文本内容,识别合同结构,分割条款段落,处理扫描件OCR识别,生成结构化数据。
- 3. 合规审查智能体:分析条款合规性,检查违约责任、争议解决等风险点,比对法律数据库,评估风险等级并提供修改建议。
- 4. 报告生成智能体:整合审查结果,生成结构化报告,包含风险摘要、条款分析、修改建议,并自动生成Word格式文档。
- 5. 输出结果:最终提供可下载的Word审查报告和Excel风险清单,支持后续编辑和归档,确保审查过程可追溯。
- 6. 异常处理:如文件解析失败则提示格式异常,无风险则标记合同合规,系统自动处理各种边缘情况。
3. 项目整体实践
3.1 结构预览
contract_review/ ├─ core/ (ModelEngine核心模块) │ ├─ __init__.py │ ├─ agent.py (智能体基类) │ └─ plugin.py (插件基类+具体插件) ├─ agents/ (自定义智能体) │ ├─ __init__.py │ ├─ parse_agent.py (文档解析智能体) │ ├─ review_agent.py (合规审查智能体) │ └─ report_agent.py (报告生成智能体) └─ main.py (主流程入口)
3.2 实现核心模块(core/)
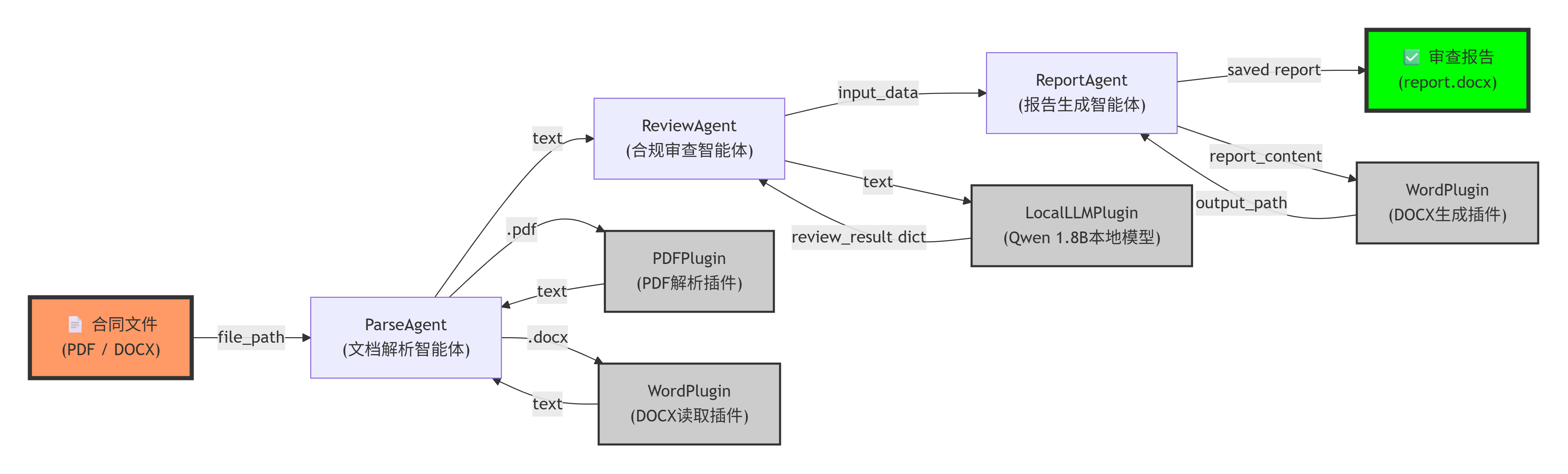
三个核心智能体和多个插件模块的交互流程:
- 系统接收PDF或DOCX格式的合同文件,通过文档解析智能体提取文本内容,合规审查智能体利用本地Qwen 1.8B模型进行风险分析,报告生成智能体最终输出结构化审查报告。
- 插件系统提供了可扩展的文件处理和报告生成能力。
3.2.1 core/agent.py(智能体基类,定义标准接口)
class BaseAgent:
"""智能体基类(模拟ModelEngine的BaseAgent)"""
agent_name = "default_agent"
agent_desc = "默认智能体,需子类重写业务逻辑"
def __init__(self, plugins=None):
self.plugins = plugins or {} # 关联插件,字典格式管理
def execute(self, input_data):
"""核心执行方法,必须由子类重写"""
raise NotImplementedError("请在子类中实现execute方法")3.2.2 core/plugin.py(插件基类 + 具体插件实现)
实现了基于插件架构的本地合同合规审查系统的核心,包括从PDF/Word 文件中提取合同文本,并利用本地部署的大语言模型(Qwen1.5-1.8B-Chat)进行合规分析,最后生成结构化 Word 审查报告的完整过程。
import os
from abc import abstractmethod
from PyPDF2 import PdfReader
from docx import Document
class BasePlugin:
"""插件基类(模拟ModelEngine的BasePlugin)"""
plugin_name = "default_plugin"
plugin_version = "1.0.0"
@abstractmethod
def run(self, *args, **kwargs):
"""插件核心执行方法,子类重写"""
pass
# ---------------------- 插件实现(基于本地模型,包含PDF/Word/本地大模型) ----------------------
class PDFPlugin(BasePlugin):
"""PDF解析插件:提取PDF文本内容"""
plugin_name = "pdf_plugin"
def run(self, file_path):
if not os.path.exists(file_path):
raise FileNotFoundError(f"PDF文件不存在:{file_path}")
if not file_path.endswith(".pdf"):
raise ValueError("仅支持后缀为.pdf的文件")
# 读取PDF文本
reader = PdfReader(file_path)
text_content = ""
for page in reader.pages:
page_text = page.extract_text() or ""
text_content += page_text + "\n"
return text_content.strip()
class WordPlugin(BasePlugin):
"""Word插件:读取docx文本 + 生成审查报告Word"""
plugin_name = "word_plugin"
def run(self, action, file_path, content=None):
if not os.path.exists(os.path.dirname(file_path)) and os.path.dirname(file_path):
os.makedirs(os.path.dirname(file_path), exist_ok=True)
# 动作1:读取docx文件文本
if action == "read":
if not file_path.endswith(".docx"):
raise ValueError("仅支持后缀为.docx的文件")
doc = Document(file_path)
text_content = "\n".join([para.text for para in doc.paragraphs])
return text_content.strip()
# 动作2:生成合规审查报告Word
elif action == "generate":
if not content:
raise ValueError("生成Word报告需要传入content字典参数")
doc = Document()
# 填充报告内容(企业标准格式)
doc.add_heading("合同合规审查报告", 0)
doc.add_paragraph(f"审查合同:{os.path.basename(content['file_path'])}")
doc.add_paragraph(f"审查时间:{content['review_time']}")
doc.add_paragraph(f"审查模型:Qwen1.5-1.8B-Chat(本地运行)")
# 风险点汇总
doc.add_heading("一、核心风险点汇总", level=1)
if content["risks"]:
for i, risk in enumerate(content["risks"], 1):
doc.add_paragraph(f"{i}. {risk['item']}", style="List Number")
doc.add_paragraph(f" 整改建议:{risk['suggestion']}", style="List Bullet")
else:
doc.add_paragraph("✅ 无核心风险点,合同条款符合企业合规要求。")
# 审查结论
doc.add_heading("二、审查最终结论", level=1)
doc.add_paragraph(content["conclusion"])
# 保存Word文件
doc.save(file_path)
return file_path
class LocalLLMPlugin(BasePlugin):
"""本地大模型插件:基于Qwen1.5-1.8B-Chat执行合同合规审查"""
plugin_name = "local_llm_plugin"
def __init__(self, model_name="qwen/Qwen1.5-1.8B-Chat", cache_dir="D:\\modelscope\\hub"):
super().__init__()
self.model_name = model_name
self.cache_dir = cache_dir
self.tokenizer = None
self.model = None
self._load_local_model() # 初始化时自动下载/加载本地模型
def _load_local_model(self):
"""下载(首次)并加载本地Qwen1.5-1.8B-Chat模型"""
print("="*50)
print(f"正在下载/校验模型:{self.model_name}")
print(f"模型缓存目录:{self.cache_dir}")
print("提示:首次下载需要约4GB磁盘空间,后续运行直接加载缓存,无需重复下载")
print("="*50)
# 步骤1:通过modelscope下载模型到本地缓存
try:
local_model_path = snapshot_download(
self.model_name,
cache_dir=self.cache_dir
)
except Exception as e:
raise Exception(f"模型下载失败:{e}")
# 步骤2:通过transformers加载tokenizer和模型
try:
self.tokenizer = AutoTokenizer.from_pretrained(
local_model_path,
trust_remote_code=True,
padding_side="right" # 优化生成效果
)
self.model = AutoModelForCausalLM.from_pretrained(
local_model_path,
trust_remote_code=True,
device_map="cpu" # 自动适配CPU/GPU(有GPU则自动加载,无GPU则用CPU)
)
# 模型推理优化(CPU/GPU通用)
self.model.eval()
except Exception as e:
raise Exception(f"模型加载失败:{e}")
print("="*50)
print("模型下载/加载完成,可开始合同审查!")
print("="*50)重点说明:
- 模块化设计:通过 BasePlugin 抽象基类定义统一接口,支持扩展不同功能插件(PDF 解析、Word 处理、大模型推理)。
- 多格式文档支持:
- PDFPlugin:读取 .pdf 文件并提取纯文本。
- WordPlugin:既可读取 .docx 文本,也可生成标准化的合规审查报告,含风险点、建议、结论。
- 本地大模型集成:LocalLLMPlugin 封装了 Qwen1.5-1.8B-Chat 模型的下载、加载与推理流程,确保数据不出内网,满足安全要求。
- 自动化审查流程:用户只需提供合同文件路径,系统即可自动完成:文件解析 → 模型分析 → 报告生成,无需人工干预。
3.3 实现自定义智能体(agents/)
3.3.1 agents/parse_agent.py(文档解析智能体)
定义文档解析智能体,核心作用是根据输入的文件路径,自动识别合同文件格式(PDF 或 Word),并调用对应的插件提取其中的纯文本内容。
from core.agent import BaseAgent
class ParseAgent(BaseAgent):
"""文档解析智能体:解析PDF/Word合同文本"""
agent_name = "parse_agent"
agent_desc = "解析PDF/Word格式合同,提取纯文本内容"
def execute(self, input_data):
file_path = input_data["file_path"]
if not os.path.exists(file_path):
raise FileNotFoundError(f"合同文件不存在:{file_path}")
# 根据文件后缀选择对应插件
if file_path.endswith(".pdf"):
pdf_plugin = self.plugins.get("pdf_plugin")
return pdf_plugin.run(file_path)
elif file_path.endswith(".docx"):
word_plugin = self.plugins.get("word_plugin")
return word_plugin.run(action="read", file_path=file_path, content=None)
else:
raise ValueError("不支持的文件格式,仅支持.pdf和.docx")重要说明:
- 统一入口解析多格式文档:对外提供一致的 execute() 接口,内部根据文件扩展名分发到 PDF 或 Word 解析插件。
- 插件化架构:通过 self.plugins.get(...) 动态调用已注册的 pdf_plugin 或 word_plugin,实现解耦和可扩展性。
- 输入校验:检查文件是否存在、格式是否支持,避免无效操作。
3.3.2 agents/review_agent.py(合规审查智能体)
定义合规审查智能体,核心作用是作为合同合规审查任务的协调者,接收合同文本,调用已注册的本地大模型插件(local_llm_plugin)进行风险分析,并返回审查结果。
from core.agent import BaseAgent
class ReviewAgent(BaseAgent):
"""合规审查智能体:调用本地模型审查合同风险"""
agent_name = "review_agent"
agent_desc = "基于本地大模型,审查合同合规风险并生成修改建议"
def execute(self, input_data):
contract_text = input_data
if not contract_text:
raise ValueError("合同文本为空,无法进行审查")
# 调用本地大模型插件执行审查
llm_plugin = self.plugins.get("local_llm_plugin")
return llm_plugin.run(contract_text)重点说明:
- 插件化调用:不直接依赖模型实现,而是通过 self.plugins.get("local_llm_plugin") 动态获取已注册的插件,实现逻辑与执行分离,便于替换或升级底层模型。
- 输入校验:对传入的合同文本进行非空检查,防止无效请求导致后续错误。
- 统一接口:通过 execute(input_data) 方法提供标准化入口,便于上层调度系统(如工作流引擎、API 服务)调用。
3.3.3 agents/report_agent.py(报告生成智能体)
定义报告生成智能体,核心作用是将合同审查结果(风险点、结论等)与原始文件信息整合,调用 Word 插件生成符合企业标准格式的 Word 审查报告,并保存到指定目录。
from core.agent import BaseAgent
import datetime
class ReportAgent(BaseAgent):
"""报告生成智能体:生成标准化Word审查报告"""
agent_name = "report_agent"
agent_desc = "整合审查结果,生成企业标准格式Word审查报告"
def execute(self, input_data):
review_result = input_data["review_result"]
file_path = input_data["file_path"]
# 构造报告内容
report_content = {
"file_path": file_path,
"review_time": datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
"risks": review_result["risks"],
"conclusion": review_result["conclusion"]
}
# 调用Word插件生成报告
word_plugin = self.plugins.get("word_plugin")
output_file_name = f"合同审查报告_{os.path.basename(file_path).replace('.', '_')}.docx"
output_file_path = os.path.join("contract_reports", output_file_name)
return word_plugin.run(
action="generate",
file_path=output_file_path,
content=report_content
)重要说明:
- 结构化报告生成:将来自ReviewAgent的审查结果封装为标准化字典,供报告模板使用。
- 自动化命名与存储:根据原始合同文件名自动生成带时间语义的报告文件名,并统一存入 contract_reports/ 目录。
- 插件驱动输出:通过 word_plugin 的 "generate" 动作实现报告渲染,保持逻辑与格式解耦。
3.4 主流程入口(main.py)
import os
from core.plugin import PDFPlugin, WordPlugin, LLMPlugin
from agents.parse_agent import ParseAgent
from agents.review_agent import ReviewAgent
from agents.report_agent import ReportAgent
def main(contract_file_path):
"""
主流程:合同文件 → 解析 → 审查 → 生成报告
:param contract_file_path: 合同文件路径(.pdf或.docx)
"""
# 步骤1:初始化插件(包含本地大模型插件)
plugins = {
"pdf_plugin": PDFPlugin(),
"word_plugin": WordPlugin(),
"local_llm_plugin": LocalLLMPlugin(
model_name="qwen/Qwen1.5-1.8B-Chat",
cache_dir="D:\\modelscope\\hub"
)
}
# 步骤2:初始化智能体并关联插件
parse_agent = ParseAgent(plugins=plugins)
review_agent = ReviewAgent(plugins=plugins)
report_agent = ReportAgent(plugins=plugins)
# 步骤3:执行全流程
try:
print("\n【步骤1/3】正在解析合同文件...")
contract_text = parse_agent.execute({"file_path": contract_file_path})
print("\n【步骤2/3】正在进行合规审查(本地模型推理中,稍等)...")
review_result = review_agent.execute(contract_text)
print(f"===review_result===:{review_result}")
print("\n【步骤3/3】正在生成Word审查报告...")
report_file_path = report_agent.execute({
"review_result": review_result,
"file_path": contract_file_path
})
# 步骤4:输出结果
print("\n" + "="*60)
print("合同审查全流程完成!")
print(f"审查报告保存路径:{os.path.abspath(report_file_path)}")
print(f"风险点数量:{len(review_result['risks'])}")
for i, risk in enumerate(review_result['risks'], 1):
print(f" {i}. 风险点:{risk['item']}")
print(f" 建议:{risk['suggestion']}")
print("="*60)
except Exception as e:
print(f"\n流程执行失败:{e}")
# ---------------------- 运行入口(直接执行此文件即可) ----------------------
if __name__ == "__main__":
# 替换为你的合同文件路径(支持.pdf或.docx)
TEST_CONTRACT_PATH = "测试合同.pdf" # 可修改为:"测试合同.docx"
# 运行主流程
main(TEST_CONTRACT_PATH)输出结果:
================================================== 正在下载/校验模型:qwen/Qwen1.5-1.8B-Chat 模型缓存目录:D:\modelscope\hub 提示:首次下载需要约4GB磁盘空间,后续运行直接加载缓存,无需重复下载 ================================================== Downloading Model from modelscope to directory: D:\modelscope\hub\qwen\Qwen1.5-1.8B-Chat 2026-02-04 14:13:42,563 - modelscope - INFO - Creating symbolic link [D:\modelscope\hub\qwen\Qwen1.5-1.8B-Chat]. 2026-02-04 14:13:42,572 - modelscope - WARNING - Failed to create symbolic link D:\modelscope\hub\qwen\Qwen1.5-1.8B-Chat for D:\modelscope\hub\qwen\Qwen1___5-1___8B-Chat. Loading weights: 100%|███████████████████████| 291/291 [00:00<00:00, 956.43it/s, Materializing param=model.norm.weight] ================================================== 模型下载/加载完成,可开始合同审查! ================================================== 【步骤1/3】正在解析合同文件... 【步骤2/3】正在进行合规审查(本地模型推理中,稍等)... 模型原始返回内容: { "risks": [ { "item": "违约责任条款", "suggestion": "在系统开发过程中,如果乙方未能按照约定的时间节点完成任务,甲方有权要求乙方支付违约金,具体金额根据逾期天数和总费用的比例计算。同时,如果乙方未能按照约定的方式和时间提交系统,甲方有权解除合同,并要求乙方退还已收款项并赔偿相应的经济损失。对于乙方违反保密义务的行为,甲方有权要求乙方赔偿实际经济损失。" }, { "item": "风险点", "suggestion": "在第 1 条中,关于乙方的培训时间限制可能需要调整为 2-3 次,每次时长不少于 3 小时,以满足甲方的需求。此外,可以增加一个风险点,即乙方在试运行期间应对可能出现的技术问题进行快速响应,如系统崩溃、数据丢失等,以保障系统的稳定运行。" } ], "conclusion": "本合同中,甲方有以下违约责任条款:在系统开发过程中,如乙方未能按照约定的时间节点完成任务,甲方有权要求乙方支付违约金,具体金额根据逾期天数和总费用的比例计算。同时,如果乙方未能按照约定的方式和时间提交系统,甲方有权解除合同,并要求乙方退还已收款项并赔偿相应的经济损失。对于乙方违反保密义务的行为,甲方有权要求乙方赔偿实际经济损失。同时培训时间限制可能需要调整为 2-3 次,每次时长不少于 3 小时,以满足甲方的需求。此外,可以增加一个风险点,即乙方在试运行期间应对可能出现的技术问题进行快速响应,如系统崩溃、数据丢失等,以保障系统的稳定运行。" } 【步骤3/3】正在生成Word审查报告... ============================================================ 合同审查全流程完成! 审查报告保存路径:D:\AIWorld\test\contract_reports\合同审查报告_测试合同_pdf.docx 风险点数量:2 1. 风险点:违约责任条款 建议:在系统开发过程中,如果乙方未能按照约定的时间节点完成任务,甲方有权要求乙方支付违约金,具体金额根据逾期天数和总费用的比例计算。同时,如果乙方未能按照约定的方式和时间提交系统,甲方有权解除合同,并要求乙方退还已收款项并赔偿相应的经济损失。对于乙方违反保密义务的行为,甲方有权要求乙方赔偿实际经济损失。 2. 风险点:风险点 建议:在第 1 条中,关于乙方的培训时间限制可能需要调整为 2-3 次,每次时长不少于 3 小时,以满足甲方的需求。此外,可以增加一个风险点,即乙方在试运行期间应对可能出现的技术问题进行快速响应,如系统崩溃、数据丢失等,以保障系统的稳定运行。 ============================================================
四、总结
ModelEngine的核心价值,并非某一个框架或工具,而是“模块化拆分、标准化集成、全场景适配”的设计思想。打破了传统 AI 应用开发都是从头到尾手写代码的固化模式,把复杂系统拆解成一个个可独立运作、可自由组合的智能体和插件。通过智能体的角色化分工,将复杂逻辑解耦,每个智能体只专注一件事,既方便单独调试优化,又能跨项目复用;
通过插件化集成外部工具,不管是 Excel、PDF 处理,还是本地大模型、云端 API,都能按统一标准接入,不用反复适配底层逻辑;再加上全场景适配的特性,都能基于这套思想快速搭建专属AI应用。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号