Redis 高可用配置及持久化:从原理到实战,打造永不宕机的缓存架构

Redis 高可用配置及持久化:从原理到实战,打造永不宕机的缓存架构

果酱带你啃java
发布于 2026-04-14 13:21:02
发布于 2026-04-14 13:21:02
引言:为什么 Redis 高可用如此重要?
在当今的互联网架构中,Redis 作为高性能的内存数据库,被广泛应用于缓存、会话存储、消息队列等场景。根据 Redis 官方统计,全球有超过 50% 的 Fortune 500 公司在使用 Redis。然而,随着业务规模的扩大和对系统可用性要求的提高,单节点 Redis 的局限性日益凸显:
- 单点故障风险:单个 Redis 实例一旦宕机,将导致依赖它的所有服务不可用
- 性能瓶颈:单节点处理能力有限,难以应对高并发场景
- 数据安全:内存数据易丢失,缺乏有效的持久化策略可能导致数据灾难
本文将深入剖析 Redis 高可用的核心技术,包括主从复制、哨兵模式、集群部署以及持久化机制,并通过大量实战示例,帮助你构建一个稳定、高效、安全的 Redis 架构。
一、Redis 高可用核心概念解析
1.1 什么是 Redis 高可用?
Redis 高可用(High Availability)是指通过一系列技术手段,确保 Redis 服务在面对各种异常情况时,仍然能够保持持续可用的状态。高可用通常包含以下几个维度:
- 服务可用性:尽量减少服务中断时间,通常用 N 个 9 来衡量(如 99.99% 表示每年 downtime 不超过 52.56 分钟)
- 数据可靠性:确保数据不丢失或仅丢失少量数据
- 性能稳定性:在高并发场景下仍能保持稳定的响应速度
- 可扩展性:能够根据业务需求灵活扩展集群规模
1.2 Redis 高可用解决方案全景图
Redis 提供了多种机制来实现高可用,这些机制通常需要组合使用以达到最佳效果:
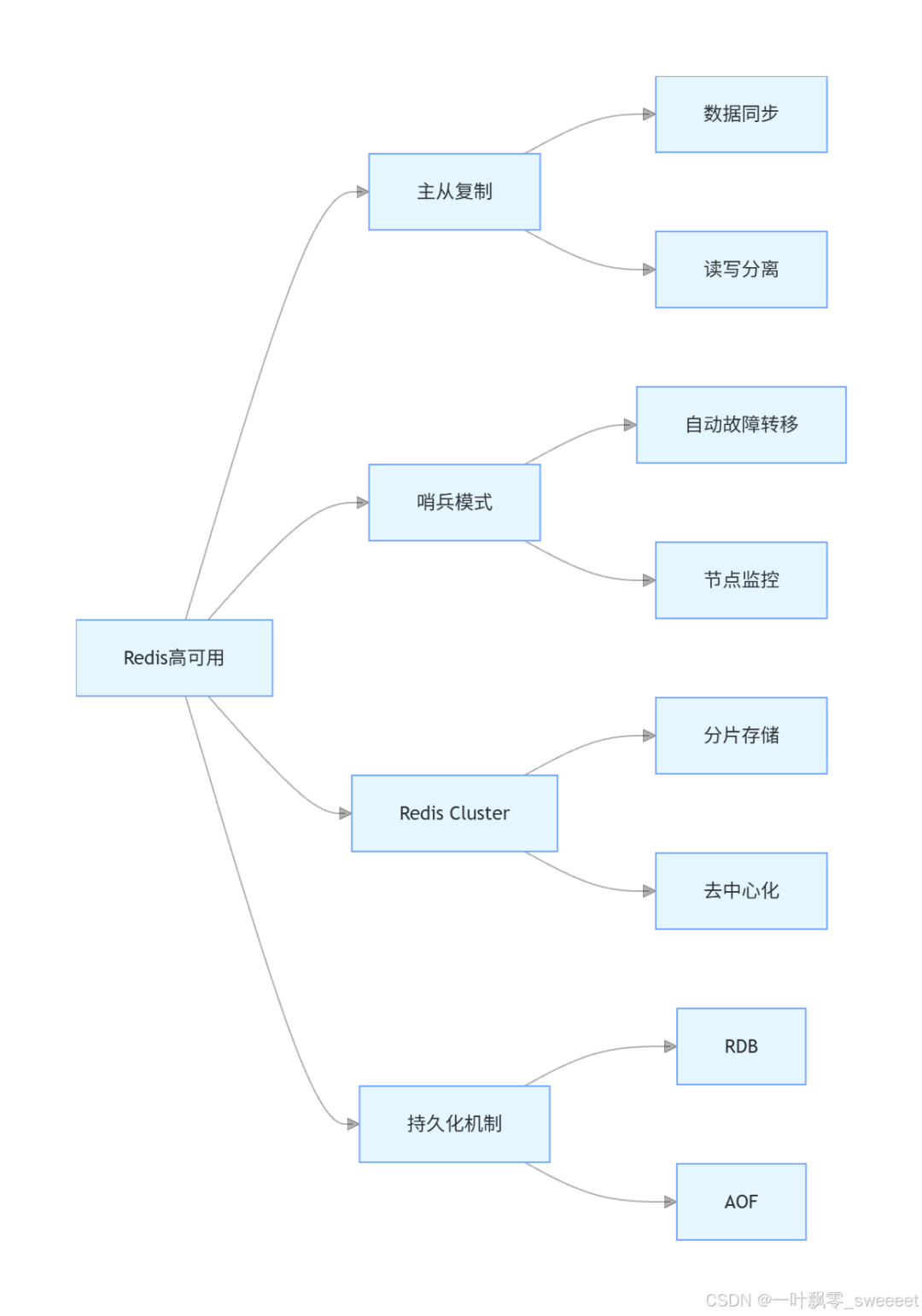
二、Redis 持久化机制:数据安全的最后一道防线
持久化是 Redis 高可用的基础,它确保 Redis 在重启后能够恢复数据。Redis 提供了两种持久化方式:RDB(Redis Database)和 AOF(Append Only File)。
2.1 RDB 持久化:快照式数据备份
RDB 是 Redis 默认的持久化方式,它通过创建数据的时间点快照来实现持久化。
2.1.1 RDB 工作原理
RDB 的工作流程如下:
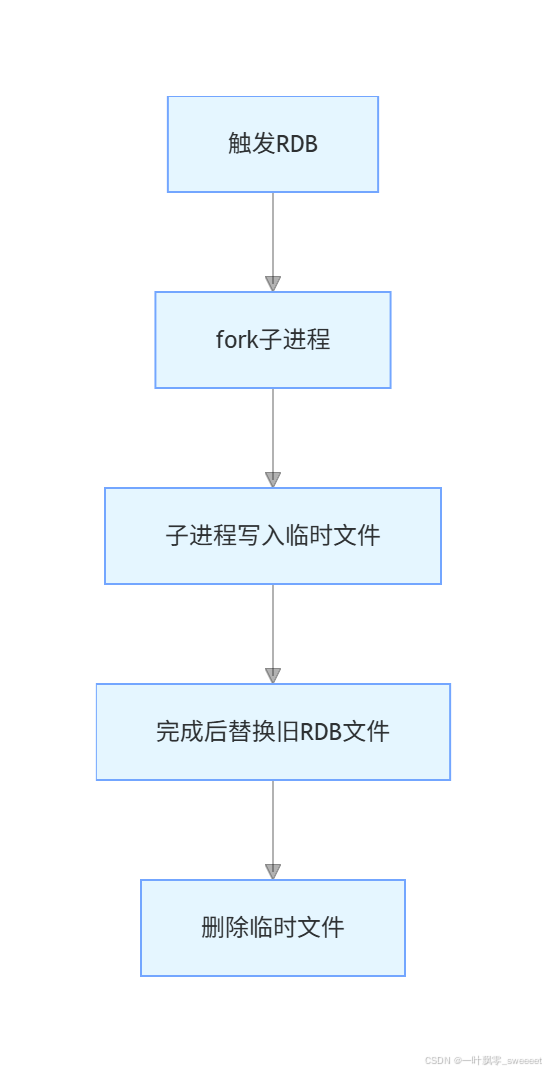
- Redis 会创建一个子进程来处理 RDB 文件的生成
- 子进程遍历内存中的数据并写入到临时文件
- 写入完成后,用临时文件替换原来的 RDB 文件
- 整个过程中,主进程仍然可以处理客户端请求
2.1.2 RDB 配置示例
# 配置RDB文件名
dbfilename dump.rdb
# 配置RDB文件存储路径
dir /var/lib/redis
# 配置自动触发RDB的条件
# 900秒内有至少1个键被修改
save 900 1
# 300秒内有至少10个键被修改
save 300 10
# 60秒内有至少10000个键被修改
save 60 10000
# 当RDB持久化出现错误时,是否停止接受写入操作
stop-writes-on-bgsave-error yes
# 是否对RDB文件进行压缩
rdbcompression yes
# 是否对RDB文件进行校验
rdbchecksum yes
2.1.3 手动触发 RDB
可以通过 Redis 命令手动触发 RDB 持久化:
# 同步方式,会阻塞Redis服务直到RDB完成
SAVE
# 异步方式,后台执行,不阻塞服务
BGSAVE
2.1.4 RDB 的优缺点分析
优点:
- RDB 文件是紧凑的二进制文件,适合备份和灾难恢复
- 恢复大数据集时,RDB 比 AOF 速度快
- 生成 RDB 文件时,主进程不需要进行 IO 操作
缺点:
- 无法实现实时或近实时的持久化,存在数据丢失风险
- fork 子进程可能会导致短暂的服务停顿,数据集越大停顿时间越长
2.2 AOF 持久化:日志式数据备份
AOF(Append Only File)通过记录所有写操作命令来实现持久化,重启时通过重新执行这些命令来恢复数据。
2.2.1 AOF 工作原理
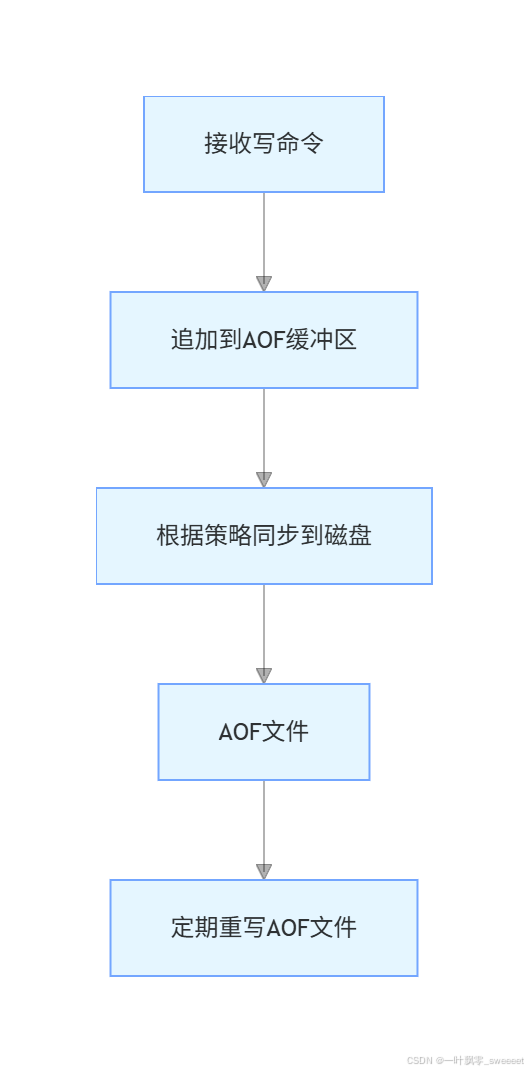
- Redis 执行完写命令后,会将命令追加到 AOF 缓冲区
- 根据配置的同步策略,将缓冲区内容同步到磁盘上的 AOF 文件
- 为了防止 AOF 文件过大,Redis 会定期对 AOF 文件进行重写
2.2.2 AOF 配置示例
# 开启AOF持久化
appendonly yes
# AOF文件名
appendfilename "appendonly.aof"
# AOF文件存储路径,与RDB共用
dir /var/lib/redis
# AOF同步策略
# appendfsync always # 每次写操作都同步,最安全但性能最差
appendfsync everysec # 每秒同步一次,平衡安全性和性能
# appendfsync no # 由操作系统决定何时同步,性能最好但安全性最差
# AOF重写期间是否不进行同步
no-appendfsync-on-rewrite no
# AOF文件重写触发条件
auto-aof-rewrite-percentage 100 # 当前AOF文件比上次重写后的文件大100%时触发
auto-aof-rewrite-min-size 64mb # AOF文件最小尺寸,小于此值不触发重写
# AOF文件损坏时的处理方式
aof-load-truncated yes # 加载时忽略最后可能损坏的命令
# 混合持久化(Redis 4.0+)
aof-use-rdb-preamble yes # 开启RDB-AOF混合持久化
2.2.3 AOF 重写机制
AOF 重写是为了减小 AOF 文件体积,它会创建一个新的 AOF 文件,包含重建当前数据集所需的最少命令。
手动触发 AOF 重写:
# 异步执行AOF重写
BGREWRITEAOF
2.2.4 AOF 的优缺点分析
优点:
- 更高的数据安全性,可配置不同的同步策略
- AOF 文件是文本文件,易于理解和修改
- 重写机制保证了 AOF 文件不会过大
缺点:
- 相同数据集下,AOF 文件通常比 RDB 文件大
- 在某些情况下,AOF 恢复速度比 RDB 慢
- 某些命令可能导致 AOF 文件体积膨胀
2.3 RDB 与 AOF 的选择与组合
在实际应用中,我们需要根据业务需求选择合适的持久化策略:
场景 | 推荐策略 | 理由 |
|---|---|---|
数据安全性要求高,可容忍一定性能损耗 | AOF(everysec) | 每秒同步一次,最多丢失 1 秒数据 |
追求高性能,数据可容忍一定丢失 | RDB | 对性能影响小,但可能丢失较多数据 |
既要求性能又要求数据安全 | RDB+AOF | Redis 4.0 + 支持混合持久化,结合两者优点 |
2.3.1 混合持久化详解
Redis 4.0 引入了混合持久化机制,当开启后,AOF 重写时会将当前数据以 RDB 格式写入 AOF 文件开头,然后将重写后的命令以 AOF 格式追加到后面。
混合持久化的优势:
- 兼具 RDB 的快速恢复能力和 AOF 的高数据安全性
- 减小 AOF 文件体积,加快重写和恢复速度
2.4 数据恢复实战
当 Redis 重启时,会根据配置加载持久化文件恢复数据:
- 如果只开启了 RDB,加载 dump.rdb 文件
- 如果只开启了 AOF,加载 appendonly.aof 文件
- 如果同时开启了 RDB 和 AOF,优先加载 AOF 文件
2.4.1 手动恢复数据
# 1. 停止Redis服务
systemctl stop redis
# 2. 备份现有持久化文件(如有)
cp /var/lib/redis/dump.rdb /var/lib/redis/dump.rdb.bak
cp /var/lib/redis/appendonly.aof /var/lib/redis/appendonly.aof.bak
# 3. 将需要恢复的文件复制到Redis数据目录
cp /path/to/backup/dump.rdb /var/lib/redis/
# 或
cp /path/to/backup/appendonly.aof /var/lib/redis/
# 4. 启动Redis服务
systemctl start redis
2.4.2 修复损坏的 AOF 文件
如果 AOF 文件损坏,可以使用 Redis 提供的工具进行修复:
# 使用redis-check-aof工具修复AOF文件
redis-check-aof --fix /var/lib/redis/appendonly.aof
三、主从复制:读写分离与数据备份
主从复制(Master-Slave Replication)是 Redis 实现高可用的基础,它允许将一个 Redis 服务器(主节点)的数据复制到多个 Redis 服务器(从节点)。
3.1 主从复制的核心作用
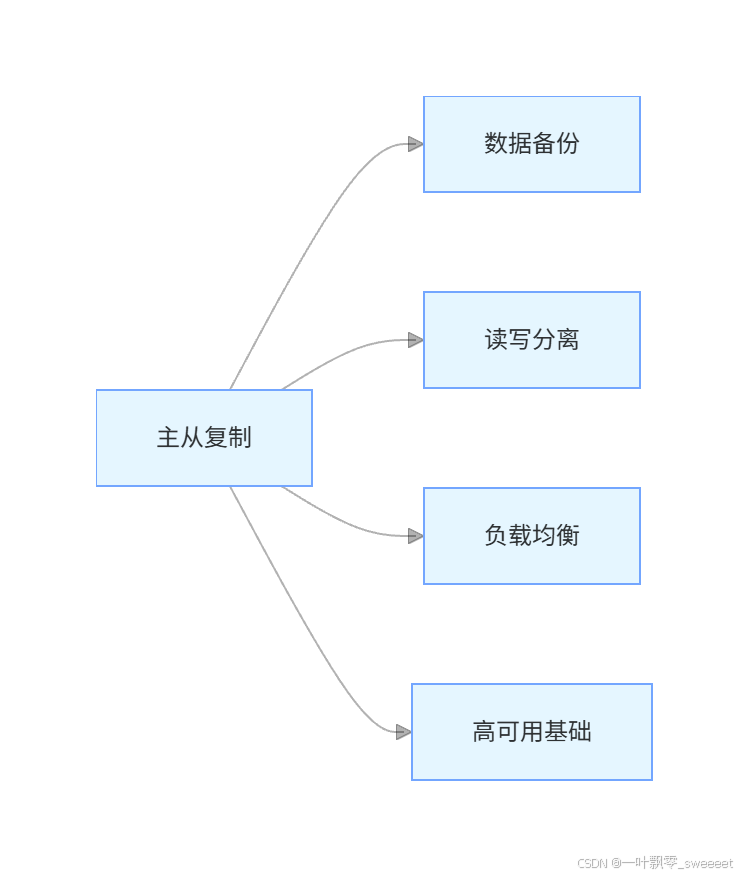
- 数据备份:从节点是主节点的备份,避免单点数据丢失风险
- 读写分离:主节点负责写操作,从节点负责读操作,提高系统吞吐量
- 负载均衡:多个从节点可以分担读请求,减轻主节点压力
- 高可用基础:为主节点故障时的故障转移提供支持
3.2 主从复制工作原理
主从复制的工作流程可以分为三个阶段:
- 建立连接阶段:从节点通过配置或命令连接到主节点,并发送 SYNC 命令
- 数据同步阶段:主节点收到 SYNC 命令后,执行 BGSAVE 生成 RDB 文件,同时记录此期间的写命令。RDB 文件生成后发送给从节点,从节点加载 RDB 文件,然后主节点发送期间记录的写命令
- 命令传播阶段:数据同步完成后,主节点会将后续的写命令实时发送给从节点,保证主从数据一致
3.3 主从复制配置实战
3.3.1 环境准备
我们将配置一个一主两从的 Redis 架构:
- 主节点:192.168.1.100:6379
- 从节点 1:192.168.1.101:6379
- 从节点 2:192.168.1.102:6379
3.3.2 主节点配置(redis.conf)
# 绑定IP,允许远程连接
bind 0.0.0.0
# 端口号
port 6379
# 保护模式关闭(生产环境建议开启并配置密码)
protected-mode no
# 日志文件
logfile "/var/log/redis/redis-server.log"
# 数据目录
dir /var/lib/redis
# 开启RDB
save 900 1
save 300 10
save 60 10000
# 开启AOF
appendonly yes
appendfsync everysec
3.3.3 从节点配置(redis.conf)
从节点 1(192.168.1.101)配置:
# 绑定IP
bind 0.0.0.0
# 端口号
port 6379
# 保护模式关闭
protected-mode no
# 日志文件
logfile "/var/log/redis/redis-server.log"
# 数据目录
dir /var/lib/redis
# 配置主节点地址和端口
replicaof 192.168.1.100 6379
# 如果主节点有密码,需要配置
# masterauth <master-password>
# 从节点只读(默认开启)
replica-read-only yes
从节点 2(192.168.1.102)配置与从节点 1 相同。
3.3.4 启动并验证主从架构
# 启动主节点
redis-server /etc/redis/redis.conf
# 启动从节点1
redis-server /etc/redis/redis.conf
# 启动从节点2
redis-server /etc/redis/redis.conf
# 连接主节点,查看信息
redis-cli -h 192.168.1.100 info replication
正常情况下,主节点信息应显示有 2 个从节点:
# Replication
role:master
connected_slaves:2
slave0:ip=192.168.1.101,port=6379,state=online,offset=12345,lag=1
slave1:ip=192.168.1.102,port=6379,state=online,offset=12345,lag=1
master_replid:xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:12345
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:12345
3.3.5 动态配置主从关系
除了在配置文件中设置,还可以通过命令动态配置主从关系:
# 在从节点上执行
redis-cli -h 192.168.1.101
192.168.1.101:6379> slaveof 192.168.1.100 6379
# 取消从节点身份(使其成为主节点)
192.168.1.101:6379> slaveof no one
3.4 主从复制进阶配置
3.4.1 从节点只读
默认情况下,从节点是只读的,可以通过配置修改:
# 从节点只读(默认yes)
replica-read-only yes
在生产环境中,建议保持从节点只读,防止误写操作。
3.4.2 复制积压缓冲区
复制积压缓冲区是主节点上的一个环形缓冲区,用于存储最近传播的命令,当从节点断线重连时,可以只同步断线期间的命令,而不需要全量同步。
# 复制积压缓冲区大小,默认1MB
repl-backlog-size 1mb
# 如果一段时间内没有从节点连接,释放复制积压缓冲区
repl-backlog-ttl 3600
对于写操作频繁的场景,建议增大复制积压缓冲区的大小。
3.4.3 从节点优先级
当主节点故障时,哨兵会根据从节点的优先级选择新的主节点,优先级越低越有可能被选中。
# 从节点优先级,默认100
replica-priority 100
可以为性能更好的从节点设置更低的优先级。
3.4.4 最小从节点数量
主节点可以配置必须有至少 N 个从节点连接,否则停止接受写操作,确保数据能被复制到足够的从节点。
# 最少需要多少个从节点连接
min-replicas-to-write 1
# 从节点的最大延迟时间
min-replicas-max-lag 10
上述配置表示:主节点至少需要 1 个从节点,且该从节点的延迟不超过 10 秒,否则主节点停止接受写操作。
3.5 Java 操作主从架构示例
下面是一个使用 Java 操作 Redis 主从架构的示例,展示如何实现读写分离:
3.5.1 Maven 依赖
<dependencies>
<!-- Redis客户端 -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>5.1.0</version>
</dependency>
<!-- Lombok -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.30</version>
<scope>provided</scope>
</dependency>
<!-- Slf4j API -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>2.0.9</version>
</dependency>
<!-- Slf4j Simple绑定 -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>2.0.9</version>
</dependency>
<!-- Spring Utils -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-core</artifactId>
<version>6.1.2</version>
</dependency>
<!-- FastJSON2 -->
<dependency>
<groupId>com.alibaba.fastjson2</groupId>
<artifactId>fastjson2</artifactId>
<version>2.0.32</version>
</dependency>
<!-- Guava -->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>32.1.3-jre</version>
</dependency>
</dependencies>
3.5.2 Redis 读写分离工具类
package com.example.redis;
import com.google.common.collect.Lists;
import lombok.extern.slf4j.Slf4j;
import org.springframework.util.CollectionUtils;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
import java.util.List;
import java.util.Random;
/**
* Redis工具类,实现读写分离
*
* @author ken
*/
@Slf4j
public class Redis读写分离工具 {
/**
* 主节点连接池
*/
private final JedisPool masterPool;
/**
* 从节点连接池列表
*/
private final List<JedisPool> slavePools;
/**
* 随机数生成器,用于从节点负载均衡
*/
private final Random random = new Random();
/**
* 构造方法
*
* @param masterHost 主节点主机地址
* @param masterPort 主节点端口
* @param slaveHosts 从节点主机地址列表
* @param slavePort 从节点端口
*/
public Redis读写分离工具(String masterHost, int masterPort, List<String> slaveHosts, int slavePort) {
// 配置连接池
JedisPoolConfig poolConfig = createPoolConfig();
// 初始化主节点连接池
this.masterPool = new JedisPool(poolConfig, masterHost, masterPort);
// 初始化从节点连接池
this.slavePools = Lists.newArrayList();
if (!CollectionUtils.isEmpty(slaveHosts)) {
for (String slaveHost : slaveHosts) {
this.slavePools.add(new JedisPool(poolConfig, slaveHost, slavePort));
}
}
log.info("Redis读写分离工具初始化完成,主节点: {}:{},从节点数量: {}",
masterHost, masterPort, slavePools.size());
}
/**
* 创建连接池配置
*
* @return JedisPoolConfig
*/
private JedisPoolConfig createPoolConfig() {
JedisPoolConfig config = new JedisPoolConfig();
// 最大连接数
config.setMaxTotal(100);
// 最大空闲连接数
config.setMaxIdle(20);
// 最小空闲连接数
config.setMinIdle(5);
// 获取连接时的最大等待毫秒数
config.setMaxWaitMillis(3000);
// 连接空闲时间
config.setMinEvictableIdleTimeMillis(60000);
// 测试连接是否可用
config.setTestOnBorrow(true);
return config;
}
/**
* 执行写操作(使用主节点)
*
* @param operation 操作接口
* @param <T> 返回值类型
* @return 操作结果
*/
public <T> T executeWrite(RedisOperation<T> operation) {
try (Jedis jedis = masterPool.getResource()) {
return operation.execute(jedis);
} catch (Exception e) {
log.error("Redis写操作异常", e);
throw new RuntimeException("Redis写操作失败", e);
}
}
/**
* 执行读操作(使用从节点)
*
* @param operation 操作接口
* @param <T> 返回值类型
* @return 操作结果
*/
public <T> T executeRead(RedisOperation<T> operation) {
// 如果没有从节点,使用主节点
if (CollectionUtils.isEmpty(slavePools)) {
log.warn("没有可用的从节点,使用主节点执行读操作");
return executeWrite(operation);
}
// 随机选择一个从节点
int index = random.nextInt(slavePools.size());
JedisPool slavePool = slavePools.get(index);
try (Jedis jedis = slavePool.getResource()) {
return operation.execute(jedis);
} catch (Exception e) {
log.error("Redis读操作异常,从节点索引: {}", index, e);
throw new RuntimeException("Redis读操作失败", e);
}
}
/**
* Redis操作接口
*
* @param <T> 返回值类型
*/
@FunctionalInterface
public interface RedisOperation<T> {
T execute(Jedis jedis);
}
/**
* 关闭连接池
*/
public void close() {
masterPool.close();
for (JedisPool slavePool : slavePools) {
slavePool.close();
}
log.info("Redis连接池已关闭");
}
}
3.5.3 使用示例
package com.example.redis;
import com.google.common.collect.Lists;
import redis.clients.jedis.Jedis;
/**
* Redis读写分离示例
*
* @author ken
*/
public class Redis读写分离示例 {
public static void main(String[] args) {
// 主节点配置
String masterHost = "192.168.1.100";
int masterPort = 6379;
// 从节点配置
List<String> slaveHosts = Lists.newArrayList("192.168.1.101", "192.168.1.102");
int slavePort = 6379;
// 创建Redis工具类实例
Redis读写分离工具 redisUtil = new Redis读写分离工具(masterHost, masterPort, slaveHosts, slavePort);
try {
// 执行写操作(存入数据)
String key = "user:1001";
String value = "{\"id\":1001,\"name\":\"张三\",\"age\":30}";
String setResult = redisUtil.executeWrite(jedis -> jedis.set(key, value));
System.out.println("写入结果: " + setResult);
// 执行读操作(获取数据)
String getResult = redisUtil.executeRead(jedis -> jedis.get(key));
System.out.println("读取结果: " + getResult);
// 执行另一个读操作,可能会使用不同的从节点
String ttlResult = redisUtil.executeRead(jedis -> String.valueOf(jedis.ttl(key)));
System.out.println("过期时间: " + ttlResult + "秒");
} finally {
// 关闭连接池
redisUtil.close();
}
}
}
四、哨兵模式:自动故障转移
虽然主从复制实现了数据备份和读写分离,但当主节点故障时,需要手动将一个从节点晋升为主节点,这显然无法满足高可用的要求。Redis 哨兵(Sentinel)机制解决了这个问题,它能够自动监控 Redis 节点,并在主节点故障时进行自动故障转移。
4.1 哨兵模式的核心功能
- 监控(Monitoring):不断检查主节点和从节点是否正常运行
- 通知(Notification):当某个节点出现问题时,向管理员或其他应用程序发送通知
- 自动故障转移(Automatic failover):当主节点不能正常工作时,自动将一个从节点升级为新的主节点,并让其他从节点指向新的主节点
- 配置管理(Configuration provider):客户端连接哨兵获取当前主节点的地址
4.2 哨兵工作原理
哨兵模式通常由多个哨兵节点组成,形成一个哨兵集群,这样可以避免单个哨兵节点的故障导致整个哨兵系统失效。
4.2.1 哨兵集群的工作流程
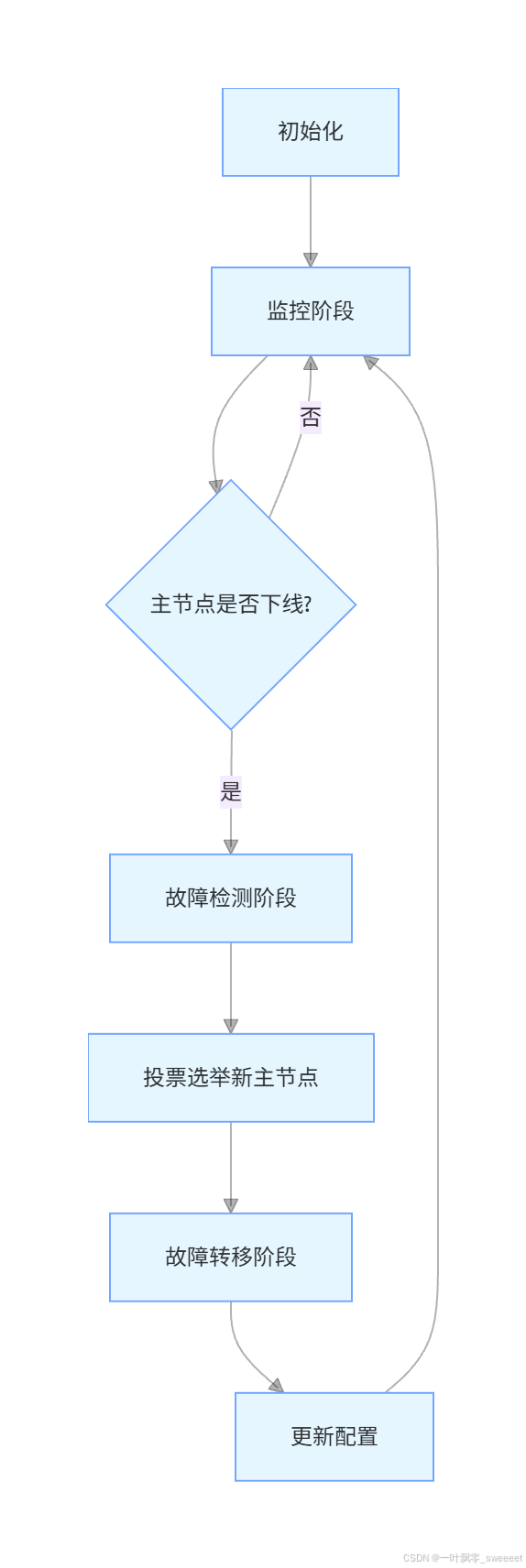
- 监控阶段:哨兵定期向主节点、从节点和其他哨兵发送 PING 命令,检查它们是否存活
- 故障检测阶段:当一个哨兵发现主节点没有在规定时间内响应,会标记主节点为 "主观下线"。如果多个哨兵都标记主节点为 "主观下线",则主节点被标记为 "客观下线"
- 投票选举阶段:哨兵集群通过投票机制,选举出一个哨兵作为领导者,负责执行故障转移
- 故障转移阶段:领导者哨兵选择一个从节点作为新的主节点,让其他从节点复制新的主节点,并更新相关配置
- 更新配置阶段:哨兵将新的主节点信息通知给客户端
4.2.2 主观下线与客观下线
- 主观下线(Subjectively Down, SDOWN):单个哨兵认为某个节点不可用
- 客观下线(Objectively Down, ODOWN):多个哨兵达成共识,认为主节点不可用
客观下线只适用于主节点,从节点和哨兵节点只有主观下线状态。
4.3 哨兵模式配置实战
我们将在之前的一主两从架构基础上,添加 3 个哨兵节点,形成完整的哨兵模式:
- 主节点:192.168.1.100:6379
- 从节点 1:192.168.1.101:6379
- 从节点 2:192.168.1.102:6379
- 哨兵 1:192.168.1.100:26379
- 哨兵 2:192.168.1.101:26379
- 哨兵 3:192.168.1.102:26379
4.3.1 哨兵配置文件(sentinel.conf)
所有哨兵节点的配置基本相同,只需保证bind地址正确:
# 绑定IP
bind 0.0.0.0
# 哨兵端口
port 26379
# 守护进程模式
daemonize yes
# 日志文件
logfile "/var/log/redis/redis-sentinel.log"
# 数据目录
dir "/var/lib/redis"
# 监控主节点
# 格式:sentinel monitor <master-name> <ip> <port> <quorum>
# quorum:判定主节点客观下线所需的最少哨兵数量
sentinel monitor mymaster 192.168.1.100 6379 2
# 主节点密码(如果主节点有密码)
# sentinel auth-pass mymaster <password>
# 主节点超时时间(毫秒),超过此时间未响应则标记为主观下线
sentinel down-after-milliseconds mymaster 30000
# 故障转移时,最多可以有多少个从节点同时对新主节点进行同步
sentinel parallel-syncs mymaster 1
# 故障转移超时时间(毫秒)
sentinel failover-timeout mymaster 180000
# 配置当主节点失效时,哪些从节点优先被选择为新主节点
# 数值越小优先级越高
sentinel replica-priority mymaster 100
4.3.2 启动哨兵节点
# 在三个节点上分别启动哨兵
redis-sentinel /etc/redis/sentinel.conf
# 或
redis-server /etc/redis/sentinel.conf --sentinel
4.3.3 验证哨兵配置
# 连接任意一个哨兵节点
redis-cli -h 192.168.1.100 -p 26379
# 查看哨兵信息
192.168.1.100:26379> info sentinel
正常情况下,输出应包含类似以下内容:
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=192.168.1.100:6379,slaves=2,sentinels=3
4.3.4 模拟主节点故障并测试故障转移
# 1. 获取主节点进程ID
ps -ef | grep redis-server | grep 6379
# 2. 杀死主节点进程(模拟故障)
kill -9 <主节点PID>
# 3. 观察哨兵日志
tail -f /var/log/redis/redis-sentinel.log
# 4. 检查新的主节点
redis-cli -h 192.168.1.101 info replication
redis-cli -h 192.168.1.102 info replication
故障转移完成后,其中一个从节点会成为新的主节点,另一个从节点会指向新的主节点。
当原来的主节点恢复后,它会自动成为新主节点的从节点,而不是恢复为主节点。
4.4 哨兵模式进阶配置
4.4.1 哨兵集群的自动发现
哨兵之间会通过主节点的__sentinel__:hello频道自动发现彼此,无需手动配置所有哨兵的地址。
4.4.2 配置重写
当发生故障转移后,哨兵会自动更新自己的配置文件,记录新的主节点信息,并通过发布订阅机制通知其他哨兵更新配置。
4.4.3 客户端重新配置
哨兵提供了SENTINEL get-master-addr-by-name命令,客户端可以通过该命令获取当前主节点的地址:
redis-cli -h 192.168.1.100 -p 26379 SENTINEL get-master-addr-by-name mymaster
输出示例:
1) "192.168.1.101"
2) "6379"
4.5 Java 连接哨兵模式示例
下面是一个使用 Java 连接 Redis 哨兵模式的示例:
package com.example.redis.sentinel;
import lombok.extern.slf4j.Slf4j;
import org.springframework.util.StringUtils;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisSentinelPool;
import redis.clients.jedis.Pool;
import redis.clients.jedis.exceptions.JedisConnectionException;
import java.util.HashSet;
import java.util.Set;
/**
* Redis哨兵模式工具类
*
* @author ken
*/
@Slf4j
public class Redis哨兵工具 {
/**
* 主节点名称
*/
private static final String MASTER_NAME = "mymaster";
/**
* 哨兵连接池
*/
private final Pool<Jedis> jedisPool;
/**
* 构造方法
*
* @param sentinelHosts 哨兵节点地址列表,格式为host:port
* @param password Redis密码,可为null
*/
public Redis哨兵工具(Set<String> sentinelHosts, String password) {
if (sentinelHosts == null || sentinelHosts.isEmpty()) {
throw new IllegalArgumentException("哨兵节点列表不能为空");
}
// 配置连接池
redis.clients.jedis.JedisPoolConfig poolConfig = new redis.clients.jedis.JedisPoolConfig();
poolConfig.setMaxTotal(100);
poolConfig.setMaxIdle(20);
poolConfig.setMinIdle(5);
poolConfig.setMaxWaitMillis(3000);
poolConfig.setTestOnBorrow(true);
// 创建哨兵连接池
if (StringUtils.hasText(password)) {
this.jedisPool = new JedisSentinelPool(MASTER_NAME, sentinelHosts, poolConfig, password);
} else {
this.jedisPool = new JedisSentinelPool(MASTER_NAME, sentinelHosts, poolConfig);
}
log.info("Redis哨兵工具初始化完成,哨兵节点数量: {}", sentinelHosts.size());
}
/**
* 执行Redis操作
*
* @param operation 操作接口
* @param <T> 返回值类型
* @return 操作结果
*/
public <T> T execute(RedisOperation<T> operation) {
if (operation == null) {
throw new IllegalArgumentException("Redis操作不能为空");
}
Jedis jedis = null;
try {
jedis = jedisPool.getResource();
return operation.execute(jedis);
} catch (JedisConnectionException e) {
log.error("Redis连接异常", e);
// 连接异常时尝试重新获取连接
if (jedis != null) {
jedis.close();
}
jedis = jedisPool.getResource();
return operation.execute(jedis);
} catch (Exception e) {
log.error("Redis操作异常", e);
throw new RuntimeException("Redis操作失败", e);
} finally {
if (jedis != null) {
jedis.close();
}
}
}
/**
* Redis操作接口
*
* @param <T> 返回值类型
*/
@FunctionalInterface
public interface RedisOperation<T> {
T execute(Jedis jedis);
}
/**
* 关闭连接池
*/
public void close() {
if (jedisPool != null) {
jedisPool.close();
log.info("Redis哨兵连接池已关闭");
}
}
/**
* 测试方法
*/
public static void main(String[] args) {
// 哨兵节点地址
Set<String> sentinelHosts = new HashSet<>();
sentinelHosts.add("192.168.1.100:26379");
sentinelHosts.add("192.168.1.101:26379");
sentinelHosts.add("192.168.1.102:26379");
// 创建Redis哨兵工具实例
Redis哨兵工具 redisUtil = new Redis哨兵工具(sentinelHosts, null);
try {
// 执行写操作
String key = "product:1001";
String value = "{\"id\":1001,\"name\":\"智能手机\",\"price\":2999}";
String setResult = redisUtil.execute(jedis -> jedis.set(key, value));
log.info("写入结果: {}", setResult);
// 执行读操作
String getResult = redisUtil.execute(jedis -> jedis.get(key));
log.info("读取结果: {}", getResult);
} finally {
// 关闭连接池
redisUtil.close();
}
}
}
五、Redis Cluster:分布式集群方案
对于数据量过大或并发量极高的场景,单主多从的架构可能仍然无法满足需求。Redis Cluster(Redis 集群)提供了数据分片(sharding)功能,将数据分布到多个节点,实现了 Redis 的水平扩展。
5.1 Redis Cluster 的核心特性
- 数据分片:将数据分散存储在多个节点上,每个节点负责一部分数据
- 高可用:每个主节点都可以有多个从节点,当主节点故障时,从节点可以晋升为主节点
- 去中心化:集群中的每个节点都可以与其他节点通信,没有中心节点
- 自动重平衡:当集群节点数量变化时,数据可以自动在节点间迁移,保持负载均衡
5.2 Redis Cluster 数据分片原理
Redis Cluster 采用哈希槽(hash slot)来分配数据,整个集群共有 16384 个哈希槽(0-16383)。
5.2.1 哈希槽分配
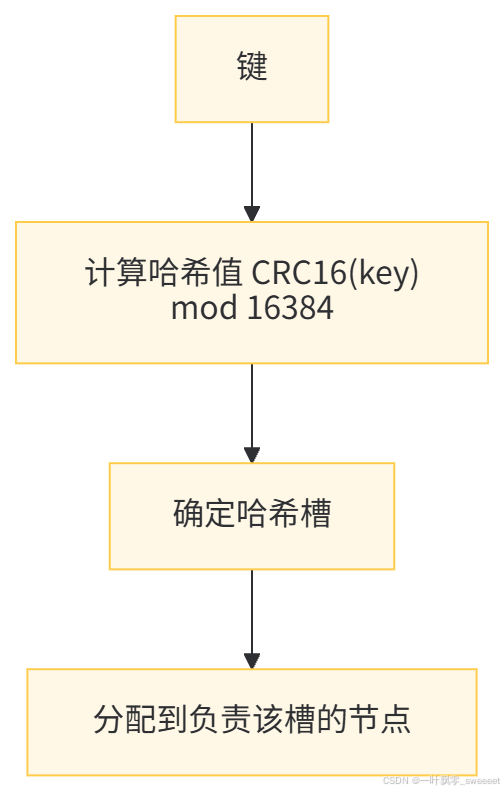
- 每个键通过 CRC16 算法计算哈希值,然后对 16384 取模,得到对应的哈希槽
- 每个节点负责一部分哈希槽,默认情况下,哈希槽平均分配给所有主节点
- 例如,3 个主节点的集群,每个节点负责约 5461 个哈希槽
5.2.2 数据迁移
当集群节点发生变化(如添加或移除节点)时,哈希槽会在节点间重新分配,数据也会相应地迁移。
5.3 Redis Cluster 架构与故障转移
Redis Cluster 的每个主节点都可以有一个或多个从节点,用于实现高可用:
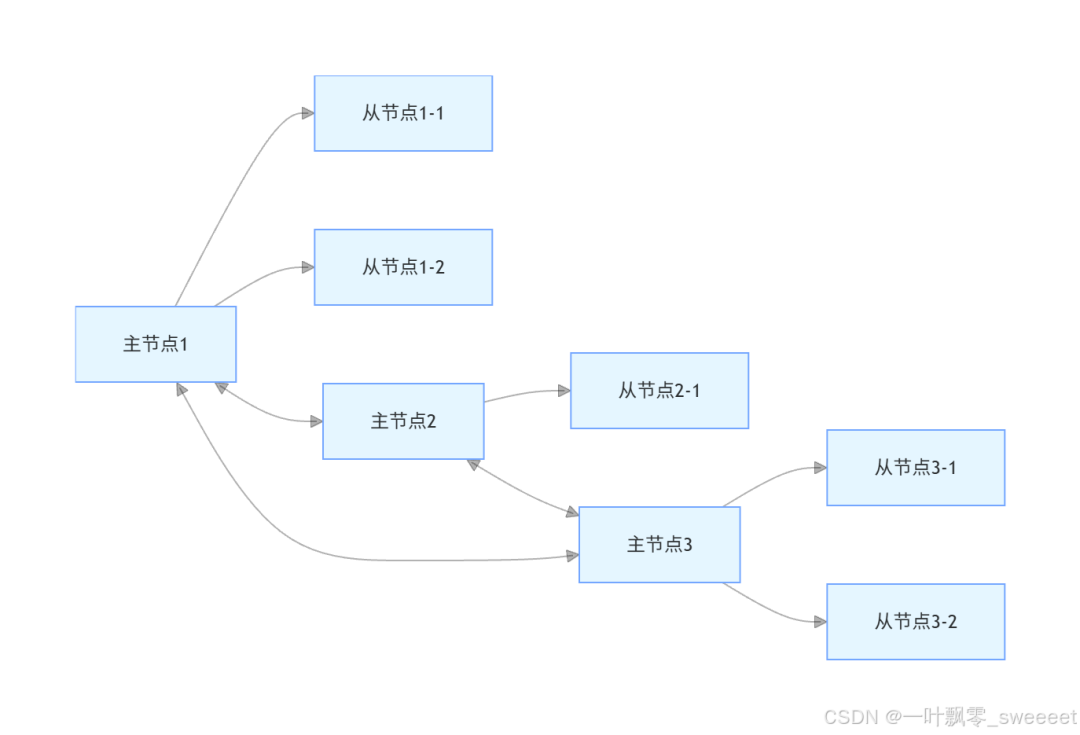
- 主节点负责处理槽和客户端请求
- 从节点复制主节点的数据,当主节点故障时,从节点可以被选举为新的主节点
- 所有节点之间相互通信,使用 Gossip 协议交换集群信息
5.4 Redis Cluster 配置实战
我们将配置一个包含 3 个主节点和 3 个从节点的 Redis Cluster:
- 主节点 1:192.168.1.100:6379
- 主节点 2:192.168.1.101:6379
- 主节点 3:192.168.1.102:6379
- 从节点 1(主节点 1 的从节点):192.168.1.100:6380
- 从节点 2(主节点 2 的从节点):192.168.1.101:6380
- 从节点 3(主节点 3 的从节点):192.168.1.102:6380
5.4.1 节点配置文件
所有节点的配置类似,主要区别在于端口号和节点角色:
主节点 1 配置(redis-6379.conf):
# 绑定IP
bind 0.0.0.0
# 端口号
port 6379
# 开启集群模式
cluster-enabled yes
# 集群配置文件,由Redis自动生成和更新
cluster-config-file nodes-6379.conf
# 集群节点超时时间(毫秒)
cluster-node-timeout 15000
# 集群从节点迁移屏障,只有当主节点至少有N个正常工作的从节点时,其他从节点才能迁移
cluster-migration-barrier 1
# 保护模式关闭
protected-mode no
# 日志文件
logfile "/var/log/redis/redis-6379.log"
# 数据目录
dir /var/lib/redis/6379
# 开启持久化
appendonly yes
从节点 1 配置(redis-6380.conf)与主节点类似,只需修改端口号为 6380,日志文件和数据目录也相应调整。
其他节点的配置与上述类似,根据各自的端口号进行调整。
5.4.2 启动所有节点
# 启动主节点1
redis-server /etc/redis/redis-6379.conf
# 启动从节点1
redis-server /etc/redis/redis-6380.conf
# 启动主节点2
redis-server /etc/redis/redis-6379.conf # 在192.168.1.101上执行
# 启动从节点2
redis-server /etc/redis/redis-6380.conf # 在192.168.1.101上执行
# 启动主节点3
redis-server /etc/redis/redis-6379.conf # 在192.168.1.102上执行
# 启动从节点3
redis-server /etc/redis/redis-6380.conf # 在192.168.1.102上执行
5.4.3 创建集群
使用 redis-cli 创建集群:
# Redis 5.0+使用以下命令
redis-cli --cluster create \
192.168.1.100:6379 \
192.168.1.101:6379 \
192.168.1.102:6379 \
192.168.1.100:6380 \
192.168.1.101:6380 \
192.168.1.102:6380 \
--cluster-replicas 1
参数说明:
--cluster create:创建集群--cluster-replicas 1:每个主节点有 1 个从节点
执行命令后,Redis 会自动分配主从关系和哈希槽,确认配置后输入 "yes" 完成集群创建。
5.4.4 验证集群配置
# 连接任意节点
redis-cli -h 192.168.1.100 -p 6379 -c
# 查看集群信息
192.168.1.100:6379> cluster info
# 查看节点信息
192.168.1.100:6379> cluster nodes
cluster info命令输出示例:
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:6
cluster_my_epoch:1
cluster_stats_messages_ping_sent:123
cluster_stats_messages_pong_sent:118
cluster_stats_messages_sent:241
cluster_stats_messages_ping_received:113
cluster_stats_messages_pong_received:123
cluster_stats_messages_meet_received:5
cluster_stats_messages_received:241
5.4.5 测试数据分片
# 连接集群
redis-cli -h 192.168.1.100 -p 6379 -c
# 设置键值对
192.168.1.100:6379> set user:1001 "张三"
-> Redirected to slot [12182] located at 192.168.1.101:6379
OK
# 获取键值
192.168.1.101:6379> get user:1001
"张三"
# 设置另一个键值对
192.168.1.101:6379> set product:2001 "笔记本电脑"
-> Redirected to slot [9438] located at 192.168.1.100:6379
OK
可以看到,不同的键会被分配到不同的节点。
5.4.6 模拟主节点故障
# 1. 找到主节点1的进程ID
ps -ef | grep redis-server | grep 6379 | grep 192.168.1.100
# 2. 杀死主节点1的进程
kill -9 <主节点1 PID>
# 3. 等待约15秒(cluster-node-timeout),查看集群状态
redis-cli -h 192.168.1.101 -p 6379 -c cluster nodes
可以看到,原来的从节点 1(192.168.1.100:6380)会晋升为新的主节点。
当原来的主节点 1 恢复后,它会成为新主节点的从节点。
5.5 Redis Cluster 常用操作
5.5.1 添加新节点
# 1. 启动新节点(以从节点为例)
redis-server /etc/redis/redis-6381.conf
# 2. 将新节点加入集群
redis-cli --cluster add-node 192.168.1.100:6381 192.168.1.100:6379
# 3. 如果要将新节点设置为某个主节点的从节点
# 首先获取主节点ID
redis-cli -h 192.168.1.100 -p 6379 cluster nodes | grep master
# 然后在新节点上执行
redis-cli -h 192.168.1.100 -p 6381 cluster replicate <主节点ID>
5.5.2 重新分配哈希槽
# 启动哈希槽重分配工具
redis-cli --cluster reshard 192.168.1.100:6379
按照提示输入要移动的槽数量、目标节点 ID、源节点 ID 等信息。
5.5.3 移除节点
# 首先确保要移除的节点没有负责任何哈希槽(如果是主节点)
# 然后执行移除命令
redis-cli --cluster del-node 192.168.1.100:6379 <要移除的节点ID>
5.6 Java 连接 Redis Cluster 示例
package com.example.redis.cluster;
import com.alibaba.fastjson2.JSON;
import com.google.common.collect.Sets;
import lombok.extern.slf4j.Slf4j;
import org.springframework.util.CollectionUtils;
import org.springframework.util.StringUtils;
import redis.clients.jedis.HostAndPort;
import redis.clients.jedis.JedisCluster;
import redis.clients.jedis.JedisPoolConfig;
import java.util.HashSet;
import java.util.Map;
import java.util.Set;
/**
* Redis Cluster工具类
*
* @author ken
*/
@Slf4j
public class RedisCluster工具 {
/**
* Redis集群客户端
*/
private final JedisCluster jedisCluster;
/**
* 构造方法
*
* @param nodes 集群节点列表,格式为host:port
* @param password 密码,可为null
*/
public RedisCluster工具(Set<String> nodes, String password) {
if (CollectionUtils.isEmpty(nodes)) {
throw new IllegalArgumentException("集群节点列表不能为空");
}
// 转换节点格式
Set<HostAndPort> clusterNodes = new HashSet<>();
for (String node : nodes) {
String[] parts = node.split(":");
if (parts.length != 2) {
throw new IllegalArgumentException("无效的节点格式: " + node + ",正确格式应为host:port");
}
clusterNodes.add(new HostAndPort(parts[0], Integer.parseInt(parts[1])));
}
// 配置连接池
JedisPoolConfig poolConfig = new JedisPoolConfig();
poolConfig.setMaxTotal(100);
poolConfig.setMaxIdle(20);
poolConfig.setMinIdle(5);
poolConfig.setMaxWaitMillis(3000);
poolConfig.setTestOnBorrow(true);
// 创建集群客户端
int connectionTimeout = 5000;
int soTimeout = 3000;
int maxAttempts = 5;
if (StringUtils.hasText(password)) {
this.jedisCluster = new JedisCluster(clusterNodes, connectionTimeout, soTimeout,
maxAttempts, password, poolConfig);
} else {
this.jedisCluster = new JedisCluster(clusterNodes, connectionTimeout, soTimeout,
maxAttempts, poolConfig);
}
log.info("Redis Cluster工具初始化完成,节点数量: {}", nodes.size());
}
/**
* 设置键值对
*
* @param key 键
* @param value 值
* @return 操作结果
*/
public String set(String key, String value) {
try {
return jedisCluster.set(key, value);
} catch (Exception e) {
log.error("Redis Cluster set操作异常,key: {}", key, e);
throw new RuntimeException("Redis Cluster set操作失败", e);
}
}
/**
* 获取键值
*
* @param key 键
* @return 值
*/
public String get(String key) {
try {
return jedisCluster.get(key);
} catch (Exception e) {
log.error("Redis Cluster get操作异常,key: {}", key, e);
throw new RuntimeException("Redis Cluster get操作失败", e);
}
}
/**
* 设置带过期时间的键值对
*
* @param key 键
* @param value 值
* @param seconds 过期时间(秒)
* @return 操作结果
*/
public String setex(String key, String value, int seconds) {
try {
return jedisCluster.setex(key, seconds, value);
} catch (Exception e) {
log.error("Redis Cluster setex操作异常,key: {}", key, e);
throw new RuntimeException("Redis Cluster setex操作失败", e);
}
}
/**
* 删除键
*
* @param key 键
* @return 受影响的键数量
*/
public Long del(String key) {
try {
return jedisCluster.del(key);
} catch (Exception e) {
log.error("Redis Cluster del操作异常,key: {}", key, e);
throw new RuntimeException("Redis Cluster del操作失败", e);
}
}
/**
* 设置对象(自动序列化为JSON)
*
* @param key 键
* @param obj 对象
* @return 操作结果
*/
public String setObject(String key, Object obj) {
try {
String json = JSON.toJSONString(obj);
return jedisCluster.set(key, json);
} catch (Exception e) {
log.error("Redis Cluster setObject操作异常,key: {}", key, e);
throw new RuntimeException("Redis Cluster setObject操作失败", e);
}
}
/**
* 获取对象(自动从JSON反序列化)
*
* @param key 键
* @param clazz 对象类型
* @param <T> 对象类型
* @return 对象
*/
public <T> T getObject(String key, Class<T> clazz) {
try {
String json = jedisCluster.get(key);
if (StringUtils.hasText(json)) {
return JSON.parseObject(json, clazz);
}
return null;
} catch (Exception e) {
log.error("Redis Cluster getObject操作异常,key: {}", key, e);
throw new RuntimeException("Redis Cluster getObject操作失败", e);
}
}
/**
* 关闭集群客户端
*/
public void close() {
if (jedisCluster != null) {
try {
jedisCluster.close();
log.info("Redis Cluster客户端已关闭");
} catch (Exception e) {
log.error("关闭Redis Cluster客户端异常", e);
}
}
}
/**
* 测试方法
*/
public static void main(String[] args) {
// 集群节点
Set<String> nodes = Sets.newHashSet(
"192.168.1.100:6379",
"192.168.1.101:6379",
"192.168.1.102:6379",
"192.168.1.100:6380",
"192.168.1.101:6380",
"192.168.1.102:6380"
);
// 创建Redis Cluster工具实例
RedisCluster工具 redisCluster = new RedisCluster工具(nodes, null);
try {
// 测试字符串操作
String strKey = "cluster:test:string";
redisCluster.set(strKey, "Redis Cluster 测试");
String strValue = redisCluster.get(strKey);
log.info("字符串值: {}", strValue);
// 测试对象操作
String objKey = "cluster:test:object";
User user = new User(1001, "张三", 30);
redisCluster.setObject(objKey, user);
User savedUser = redisCluster.getObject(objKey, User.class);
log.info("对象值: {}", savedUser);
// 测试过期时间
String exKey = "cluster:test:expire";
redisCluster.setex(exKey, "5秒后过期", 5);
log.info("过期键值: {}", redisCluster.get(exKey));
} finally {
// 关闭客户端
redisCluster.close();
}
}
/**
* 用户实体类
*/
public static class User {
private int id;
private String name;
private int age;
public User(int id, String name, int age) {
this.id = id;
this.name = name;
this.age = age;
}
// getter和setter
public int getId() { return id; }
public void setId(int id) { this.id = id; }
public String getName() { return name; }
public void setName(String name) { this.name = name; }
public int getAge() { return age; }
public void setAge(int age) { this.age = age; }
@Override
public String toString() {
return "User{id=" + id + ", name='" + name + "', age=" + age + "}";
}
}
}
六、Redis 高可用最佳实践
6.1 不同场景下的高可用方案选择
场景 | 推荐方案 | 优点 | 缺点 |
|---|---|---|---|
小型应用,低并发 | 单节点 + RDB/AOF | 部署简单,资源消耗低 | 无高可用,故障时服务中断 |
中型应用,中等并发 | 主从复制 + 哨兵 | 高可用,自动故障转移 | 无法水平扩展,所有数据存储在单个主节点 |
大型应用,高并发,大数据量 | Redis Cluster | 高可用,水平扩展,数据分片 | 部署和维护复杂,需要更多资源 |
6.2 持久化策略最佳实践
- 生产环境建议同时开启 RDB 和 AOF:
- RDB 适合用于备份和灾难恢复
- AOF 提供更高的数据安全性
- 混合持久化(AOF 使用 RDB 前缀)可以兼顾两者优点
- 合理配置 RDB 触发条件:
- 根据业务数据更新频率调整 save 参数
- 重要数据建议增加备份频率
- AOF 同步策略选择:
- 对数据安全性要求极高的场景使用
appendfsync always - 大多数场景推荐使用
appendfsync everysec,平衡安全性和性能 - 对性能要求极高且可以容忍数据丢失的场景使用
appendfsync no
- 对数据安全性要求极高的场景使用
- 定期备份持久化文件:
- 定期将 RDB 和 AOF 文件备份到其他存储介质
- 测试备份文件的恢复能力
6.3 主从复制最佳实践
- 从节点数量:
- 一般建议每个主节点配置 1-3 个从节点
- 过多的从节点会增加主节点的负担和网络带宽消耗
- 复制拓扑结构:
- 小规模集群可以使用星型结构(一个主节点多个从节点)
- 大规模集群可以使用树型结构(从节点下面再挂从节点)
- 网络优化:
- 主从节点尽量部署在同一局域网内
- 避免主从节点之间的网络延迟过大(建议 < 10ms)
- 数据同步优化:
- 适当增大
repl-backlog-size,减少全量同步的概率 - 配置
repl-diskless-sync yes启用无盘复制,减少磁盘 IO
- 适当增大
6.4 哨兵模式最佳实践
- 哨兵数量:
- 建议配置 3-5 个哨兵节点
- 哨兵数量应为奇数,便于投票选举
- 哨兵节点部署:
- 哨兵节点应部署在不同的物理机或虚拟机上
- 避免哨兵节点与 Redis 节点部署在同一台机器上,防止单点故障
- 配置参数优化:
down-after-milliseconds:根据业务容忍度设置,建议 30000ms(30 秒)parallel-syncs:根据从节点数量设置,建议 1-2failover-timeout:建议 180000ms(3 分钟)
- 监控与告警:
- 监控哨兵日志,及时发现异常
- 配置告警机制,当发生故障转移时及时通知管理员
6.5 Redis Cluster 最佳实践
- 节点数量:
- 建议至少 3 个主节点,每个主节点至少 1 个从节点
- 总节点数量建议为 6 个(3 主 3 从)
- 哈希槽分配:
- 尽量让哈希槽在主节点间平均分配
- 避免单个节点负责过多的哈希槽
- 内存配置:
- 每个节点的内存不宜过大,建议不超过 10GB
- 根据节点数量和内存大小规划总数据量
- 故障转移优化:
- 合理设置
cluster-node-timeout,建议 15000ms(15 秒) - 配置
cluster-migration-barrier,防止从节点过度迁移
- 合理设置
- 扩容策略:
- 提前规划扩容方案,避免在业务高峰期扩容
- 扩容时逐步迁移哈希槽,避免影响业务
6.6 监控与运维
- 关键监控指标:
- 内存使用情况:used_memory, used_memory_rss
- 命中率:keyspace_hits / (keyspace_hits + keyspace_misses)
- 连接数:connected_clients, client_longest_output_list
- 持久化状态:rdb_last_save_time, aof_last_rewrite_time_sec
- 主从同步状态:master_link_status, slave_repl_offset
- 推荐监控工具:
- Redis CLI:基础监控命令
- Redis Insight:Redis 官方图形化工具
- Prometheus + Grafana:全面监控和可视化
- ELK Stack:日志收集和分析
- 定期维护任务:
- 检查持久化文件完整性
- 测试故障转移功能
- 清理过期键和大键
- 升级 Redis 版本
七、总结与展望
Redis 高可用是构建稳定可靠的分布式系统的关键环节。本文详细介绍了 Redis 的持久化机制、主从复制、哨兵模式和集群方案,从原理到实战,全面覆盖了 Redis 高可用的核心技术。
通过合理配置 Redis 的持久化策略,可以确保数据安全;利用主从复制实现读写分离,提高系统吞吐量;借助哨兵模式实现自动故障转移,提升系统可用性;采用 Redis Cluster 实现数据分片和水平扩展,应对大规模应用场景。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-09-16,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号