图论底层揭秘:邻接矩阵/表存储原理与DFS/BFS时间复杂度深度推导

图论底层揭秘:邻接矩阵/表存储原理与DFS/BFS时间复杂度深度推导

果酱带你啃java
发布于 2026-04-14 14:41:08
发布于 2026-04-14 14:41:08
一、图的基本概念与存储模型的底层逻辑
图(Graph)作为离散数学的核心结构,是描述实体间关系的抽象模型,其本质由顶点(Vertex)集合V和边(Edge)集合E组成,记为G=(V,E)。根据边的方向性,图可分为无向图(边无方向)和有向图(边有方向);根据边的权重属性,又可分为无权图和有权图。
1.1 邻接矩阵(Adjacency Matrix)的存储原理
邻接矩阵采用二维数组表示顶点间的邻接关系,其核心思想是用矩阵的行列索引对应顶点编号,矩阵元素值表示边的存在性或权重。对于包含n个顶点的图,邻接矩阵是n×n的方阵:
- 无权图:若顶点i到j有边,矩阵元素matrix[i][j]=1,否则为0;无向图的邻接矩阵是对称矩阵(matrix[i][j]=matrix[j][i])。
- 有权图:矩阵元素值直接存储边的权重,无边时通常用∞(或0,需根据场景约定)表示。
实例:无向无权图的邻接矩阵实现
package com.jam.demo.graph;
import lombok.extern.slf4j.Slf4j;
import org.springframework.util.ObjectUtils;
/**
* 邻接矩阵实现的无向无权图
* @author ken
*/
@Slf4j
publicclass UndirectedUnweightedGraphMatrix {
privatefinalint[][] matrix; // 邻接矩阵
privatefinalint vertexCount; // 顶点数量
/**
* 初始化图
* @param vertexCount 顶点数量
*/
public UndirectedUnweightedGraphMatrix(int vertexCount) {
this.vertexCount = vertexCount;
this.matrix = newint[vertexCount][vertexCount];
}
/**
* 添加边
* @param v1 顶点1(索引从0开始)
* @param v2 顶点2
* @throws IllegalArgumentException 顶点索引越界时抛出
*/
public void addEdge(int v1, int v2) {
if (v1 < 0 || v1 >= vertexCount || v2 < 0 || v2 >= vertexCount) {
thrownew IllegalArgumentException("顶点索引超出范围");
}
// 无向图双向赋值
matrix[v1][v2] = 1;
matrix[v2][v1] = 1;
log.info("添加边 ({}, {}) 成功", v1, v2);
}
/**
* 获取顶点的邻接顶点列表
* @param vertex 顶点索引
* @return 邻接顶点数组
*/
publicint[] getAdjacentVertices(int vertex) {
if (vertex < 0 || vertex >= vertexCount) {
thrownew IllegalArgumentException("顶点索引超出范围");
}
int[] adjVertices = newint[vertexCount];
int index = 0;
for (int i = 0; i < vertexCount; i++) {
if (matrix[vertex][i] == 1) {
adjVertices[index++] = i;
}
}
// 截取有效元素
return java.util.Arrays.copyOf(adjVertices, index);
}
/**
* 打印邻接矩阵
*/
public void printMatrix() {
log.info("邻接矩阵:");
for (int i = 0; i < vertexCount; i++) {
for (int j = 0; j < vertexCount; j++) {
System.out.print(matrix[i][j] + " ");
}
System.out.println();
}
}
public static void main(String[] args) {
// 初始化包含5个顶点的无向图
UndirectedUnweightedGraphMatrix graph = new UndirectedUnweightedGraphMatrix(5);
// 添加边:0-1, 0-2, 1-3, 2-4, 3-4
graph.addEdge(0, 1);
graph.addEdge(0, 2);
graph.addEdge(1, 3);
graph.addEdge(2, 4);
graph.addEdge(3, 4);
graph.printMatrix();
// 获取顶点3的邻接顶点
int[] adjVertices = graph.getAdjacentVertices(3);
log.info("顶点3的邻接顶点:{}", java.util.Arrays.toString(adjVertices));
}
}
邻接矩阵的优缺点分析
优点:
- 边的存在性判断时间复杂度为O(1),直接通过矩阵索引访问;
- 实现简单,适合稠密图(边数量接近n²);
- 矩阵操作可利用线性代数工具(如矩阵乘法求路径数)。
缺点:
- 空间复杂度为O(n²),即使是稀疏图(边数量远小于n²)也需占用n²空间,空间利用率低;
- 遍历顶点的邻接顶点时需遍历整行,时间复杂度为O(n),效率低于邻接表。
1.2 邻接表(Adjacency List)的存储原理
邻接表采用“数组+链表(或动态数组)”的结构存储图:数组的每个元素对应一个顶点,数组元素指向的链表(或动态数组)存储该顶点的所有邻接顶点及边的权重(有权图)。
对于包含n个顶点的图:
- 数组长度为n,索引对应顶点编号;
- 每个数组元素是一个集合(如List),存储该顶点的邻接顶点信息(无权图存储顶点编号,有权图存储<邻接顶点编号, 权重>对)。
实例:有向有权图的邻接表实现
package com.jam.demo.graph;
import com.google.common.collect.Lists;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.extern.slf4j.Slf4j;
import org.springframework.util.CollectionUtils;
import java.util.List;
/**
* 邻接表实现的有向有权图
* @author ken
*/
@Slf4j
publicclass DirectedWeightedGraphList {
/**
* 边的实体类(存储邻接顶点和权重)
*/
@Data
@AllArgsConstructor
publicstaticclass Edge {
privateint targetVertex; // 邻接顶点编号
privateint weight; // 边的权重
}
privatefinal List<List<Edge>> adjList; // 邻接表
privatefinalint vertexCount; // 顶点数量
/**
* 初始化图
* @param vertexCount 顶点数量
*/
public DirectedWeightedGraphList(int vertexCount) {
this.vertexCount = vertexCount;
this.adjList = Lists.newArrayListWithCapacity(vertexCount);
// 初始化每个顶点的邻接列表
for (int i = 0; i < vertexCount; i++) {
adjList.add(Lists.newArrayList());
}
}
/**
* 添加有向边
* @param source 源顶点
* @param target 目标顶点
* @param weight 边的权重
* @throws IllegalArgumentException 顶点索引越界时抛出
*/
public void addEdge(int source, int target, int weight) {
if (source < 0 || source >= vertexCount || target < 0 || target >= vertexCount) {
thrownew IllegalArgumentException("顶点索引超出范围");
}
adjList.get(source).add(new Edge(target, weight));
log.info("添加有向边 ({}, {}),权重:{}", source, target, weight);
}
/**
* 获取顶点的邻接边列表
* @param vertex 顶点索引
* @return 邻接边列表
*/
public List<Edge> getAdjacentEdges(int vertex) {
if (vertex < 0 || vertex >= vertexCount) {
thrownew IllegalArgumentException("顶点索引超出范围");
}
return adjList.get(vertex);
}
/**
* 打印邻接表
*/
public void printAdjList() {
log.info("邻接表:");
for (int i = 0; i < vertexCount; i++) {
System.out.print("顶点" + i + ":");
List<Edge> edges = adjList.get(i);
if (CollectionUtils.isEmpty(edges)) {
System.out.println("无邻接顶点");
continue;
}
for (Edge edge : edges) {
System.out.print("(" + edge.getTargetVertex() + ", " + edge.getWeight() + ") ");
}
System.out.println();
}
}
public static void main(String[] args) {
// 初始化包含4个顶点的有向有权图
DirectedWeightedGraphList graph = new DirectedWeightedGraphList(4);
// 添加边:0→1(权重5)、0→2(权重3)、1→3(权重2)、2→3(权重7)
graph.addEdge(0, 1, 5);
graph.addEdge(0, 2, 3);
graph.addEdge(1, 3, 2);
graph.addEdge(2, 3, 7);
graph.printAdjList();
// 获取顶点0的邻接边
List<Edge> edges = graph.getAdjacentEdges(0);
log.info("顶点0的邻接边:{}", edges);
}
}
邻接表的优缺点分析
优点:
- 空间复杂度为O(n+e)(n为顶点数,e为边数),稀疏图下空间利用率远高于邻接矩阵;
- 遍历顶点的邻接顶点时只需遍历对应链表,时间复杂度为O(degree(v))(degree(v)为顶点v的度),效率更高。
缺点:
- 边的存在性判断需遍历对应顶点的邻接链表,时间复杂度为O(degree(v));
- 无向图中添加边需同时更新两个顶点的邻接列表,实现略复杂。
二、DFS与BFS遍历的底层逻辑与时间复杂度推导
图的遍历是从指定顶点出发,访问图中所有可达顶点的过程,核心目标是确保每个顶点仅被访问一次。深度优先搜索(DFS)和广度优先搜索(BFS)是两种最基础的遍历算法,其底层逻辑和效率差异源于对“下一个访问顶点”的选择策略不同。
2.1 深度优先搜索(DFS)的底层逻辑
DFS遵循“先深后广”的策略:从起始顶点出发,沿着一条路径尽可能深地访问顶点,直到无法继续(路径末端),再回溯到上一个顶点,选择未访问的分支继续深入。其核心依赖栈(递归调用栈或显式栈)实现回溯。
2.1.1 DFS的实现方式
DFS有两种实现方式:递归实现(利用方法调用栈)和非递归实现(显式使用栈结构)。
实例:基于邻接表的DFS递归实现
package com.jam.demo.traversal;
import com.jam.demo.graph.DirectedWeightedGraphList;
import com.jam.demo.graph.UndirectedUnweightedGraphMatrix;
import lombok.extern.slf4j.Slf4j;
import org.springframework.util.CollectionUtils;
import java.util.Arrays;
import java.util.List;
/**
* 基于邻接表的DFS遍历实现
* @author ken
*/
@Slf4j
publicclass DfsTraversal {
/**
* 递归实现DFS遍历(邻接表,无向无权图)
* @param adjList 邻接表
* @param currentVertex 当前访问的顶点
* @param visited 访问标记数组(true表示已访问)
*/
public static void dfsRecursive(List<List<Integer>> adjList, int currentVertex, boolean[] visited) {
// 标记当前顶点为已访问
visited[currentVertex] = true;
log.info("访问顶点:{}", currentVertex);
// 遍历当前顶点的所有邻接顶点
List<Integer> adjacentVertices = adjList.get(currentVertex);
if (CollectionUtils.isEmpty(adjacentVertices)) {
return;
}
for (int vertex : adjacentVertices) {
if (!visited[vertex]) {
// 递归访问未访问的邻接顶点
dfsRecursive(adjList, vertex, visited);
}
}
}
/**
* 基于邻接矩阵的DFS非递归实现
* @param matrix 邻接矩阵
* @param startVertex 起始顶点
* @param vertexCount 顶点数量
*/
public static void dfsNonRecursive(int[][] matrix, int startVertex, int vertexCount) {
boolean[] visited = newboolean[vertexCount];
// 显式栈存储待访问的顶点
java.util.Stack<Integer> stack = new java.util.Stack<>();
// 起始顶点入栈
stack.push(startVertex);
while (!stack.isEmpty()) {
int current = stack.pop();
if (!visited[current]) {
visited[current] = true;
log.info("访问顶点:{}", current);
// 逆序入栈邻接顶点(保证遍历顺序与递归一致)
for (int i = vertexCount - 1; i >= 0; i--) {
if (matrix[current][i] == 1 && !visited[i]) {
stack.push(i);
}
}
}
}
}
public static void main(String[] args) {
// 1. 邻接表DFS递归测试(无向无权图)
List<List<Integer>> adjList = Arrays.asList(
Arrays.asList(1, 2), // 顶点0的邻接顶点
Arrays.asList(0, 3), // 顶点1的邻接顶点
Arrays.asList(0, 4), // 顶点2的邻接顶点
Arrays.asList(1, 4), // 顶点3的邻接顶点
Arrays.asList(2, 3) // 顶点4的邻接顶点
);
boolean[] visited = newboolean[5];
log.info("邻接表DFS递归遍历结果:");
dfsRecursive(adjList, 0, visited);
// 2. 邻接矩阵DFS非递归测试
UndirectedUnweightedGraphMatrix graphMatrix = new UndirectedUnweightedGraphMatrix(5);
graphMatrix.addEdge(0, 1);
graphMatrix.addEdge(0, 2);
graphMatrix.addEdge(1, 3);
graphMatrix.addEdge(2, 4);
graphMatrix.addEdge(3, 4);
log.info("\n邻接矩阵DFS非递归遍历结果:");
dfsNonRecursive(graphMatrix.getMatrix(), 0, 5);
}
}
2.1.2 DFS的时间复杂度推导
DFS的时间复杂度取决于图的存储结构:
- 邻接矩阵存储:遍历每个顶点时,需检查该顶点对应的矩阵行(共n个元素),判断是否存在边。总操作次数为n×n = n²,因此时间复杂度为O(n²)。
- 邻接表存储:遍历每个顶点时,仅需访问其邻接链表中的顶点。每个顶点被访问一次(O(n)),每条边被处理一次(O(e)),总操作次数为n+e,因此时间复杂度为O(n+e)。
推导依据:DFS的核心操作是“访问顶点”和“遍历邻接顶点”,邻接矩阵中每个顶点的邻接检查需遍历n个元素,而邻接表中仅需遍历实际存在的边。根据《算法导论》(第3版),图的遍历算法时间复杂度由存储结构决定,邻接表下为O(n+e),邻接矩阵下为O(n²)。
2.2 广度优先搜索(BFS)的底层逻辑
BFS遵循“先广后深”的策略:从起始顶点出发,先访问其所有邻接顶点(第一层),再依次访问每个邻接顶点的邻接顶点(第二层),以此类推。其核心依赖队列实现“层序访问”。
2.2.1 BFS的实现方式
BFS通常采用非递归实现,显式使用队列存储待访问的顶点。
实例:基于邻接表的BFS实现
package com.jam.demo.traversal;
import com.google.common.collect.Lists;
import com.jam.demo.graph.UndirectedUnweightedGraphMatrix;
import lombok.extern.slf4j.Slf4j;
import org.springframework.util.CollectionUtils;
import java.util.List;
import java.util.Queue;
import java.util.concurrent.LinkedBlockingQueue;
/**
* 基于邻接表的BFS遍历实现
* @author ken
*/
@Slf4j
publicclass BfsTraversal {
/**
* 基于邻接表的BFS遍历(无向无权图)
* @param adjList 邻接表
* @param startVertex 起始顶点
* @param vertexCount 顶点数量
*/
public static void bfs(List<List<Integer>> adjList, int startVertex, int vertexCount) {
boolean[] visited = newboolean[vertexCount];
// 队列存储待访问的顶点
Queue<Integer> queue = new LinkedBlockingQueue<>();
// 起始顶点入队并标记为已访问
visited[startVertex] = true;
queue.offer(startVertex);
log.info("BFS遍历结果:");
while (!queue.isEmpty()) {
int current = queue.poll();
log.info("访问顶点:{}", current);
// 遍历当前顶点的邻接顶点
List<Integer> adjacentVertices = adjList.get(current);
if (CollectionUtils.isEmpty(adjacentVertices)) {
continue;
}
for (int vertex : adjacentVertices) {
if (!visited[vertex]) {
visited[vertex] = true;
queue.offer(vertex);
}
}
}
}
/**
* 基于邻接矩阵的BFS遍历
* @param matrix 邻接矩阵
* @param startVertex 起始顶点
* @param vertexCount 顶点数量
*/
public static void bfsMatrix(int[][] matrix, int startVertex, int vertexCount) {
boolean[] visited = newboolean[vertexCount];
Queue<Integer> queue = new LinkedBlockingQueue<>();
visited[startVertex] = true;
queue.offer(startVertex);
log.info("\n邻接矩阵BFS遍历结果:");
while (!queue.isEmpty()) {
int current = queue.poll();
log.info("访问顶点:{}", current);
// 遍历当前顶点的所有邻接顶点(矩阵行)
for (int i = 0; i < vertexCount; i++) {
if (matrix[current][i] == 1 && !visited[i]) {
visited[i] = true;
queue.offer(i);
}
}
}
}
public static void main(String[] args) {
// 1. 邻接表BFS测试
List<List<Integer>> adjList = Lists.newArrayList();
adjList.add(Lists.newArrayList(1, 2)); // 顶点0
adjList.add(Lists.newArrayList(0, 3)); // 顶点1
adjList.add(Lists.newArrayList(0, 4)); // 顶点2
adjList.add(Lists.newArrayList(1, 4)); // 顶点3
adjList.add(Lists.newArrayList(2, 3)); // 顶点4
bfs(adjList, 0, 5);
// 2. 邻接矩阵BFS测试
UndirectedUnweightedGraphMatrix graphMatrix = new UndirectedUnweightedGraphMatrix(5);
graphMatrix.addEdge(0, 1);
graphMatrix.addEdge(0, 2);
graphMatrix.addEdge(1, 3);
graphMatrix.addEdge(2, 4);
graphMatrix.addEdge(3, 4);
bfsMatrix(graphMatrix.getMatrix(), 0, 5);
}
}
2.2.2 BFS的时间复杂度推导
BFS的时间复杂度与DFS一致,同样由存储结构决定:
- 邻接矩阵存储:每个顶点出队时,需遍历矩阵的一行(n个元素)判断邻接关系,总操作次数为n×n = n²,时间复杂度为O(n²)。
- 邻接表存储:每个顶点入队并处理一次(O(n)),每条边被访问一次(O(e)),总操作次数为n+e,时间复杂度为O(n+e)。
推导依据:BFS的核心是“顶点入队-出队-处理邻接顶点”,邻接矩阵下处理每个顶点的邻接关系需O(n)时间,邻接表下仅需O(degree(v))时间。根据《数据结构与算法分析》(Java语言版),BFS的时间复杂度与DFS相同,邻接表下为线性时间O(n+e),邻接矩阵下为平方时间O(n²)。
2.3 DFS与BFS的核心差异
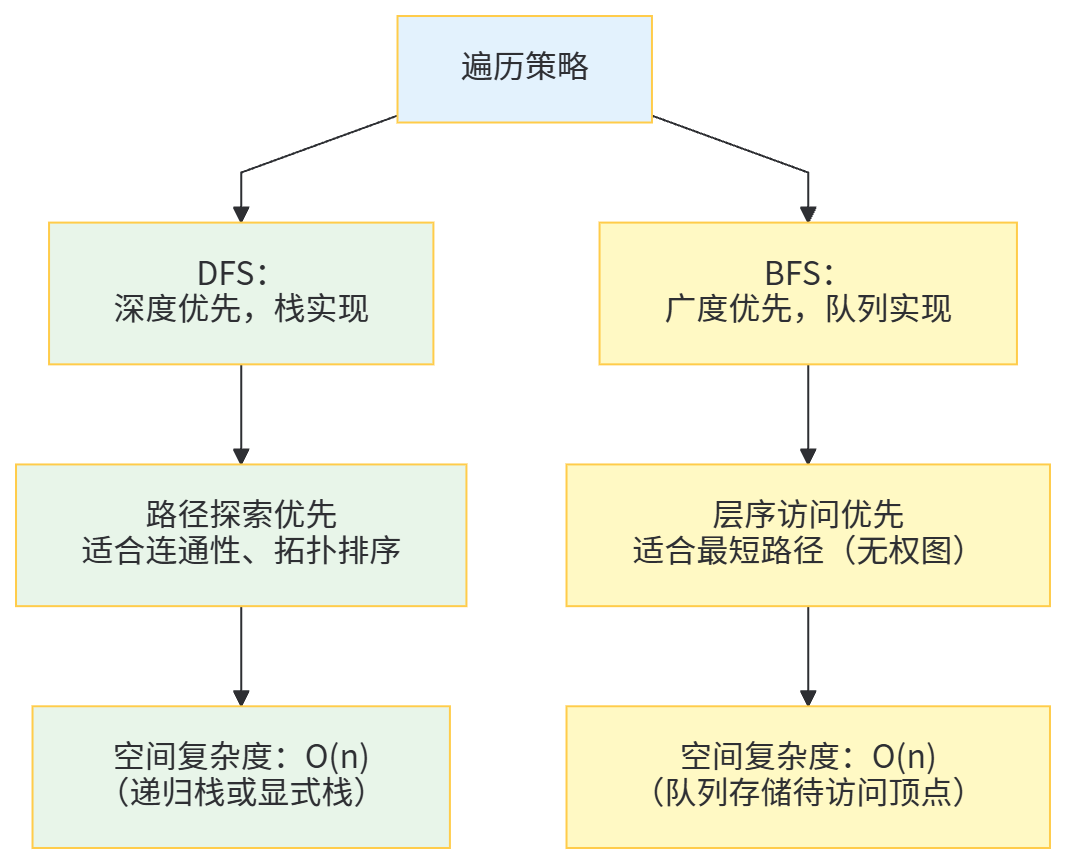
三、存储模型与遍历算法的选型实践
3.1 存储模型的选型依据
场景 | 推荐存储模型 | 原因 |
|---|---|---|
稠密图(e≈n²) | 邻接矩阵 | 空间利用率高,边操作时间复杂度O(1) |
稀疏图(e≪n²) | 邻接表 | 空间复杂度O(n+e),遍历邻接顶点效率更高 |
频繁判断边的存在性 | 邻接矩阵 | 判断操作O(1),优于邻接表的O(degree(v)) |
频繁遍历邻接顶点 | 邻接表 | 遍历时间与邻接顶点数量成正比,效率更高 |
有权图 | 邻接表或邻接矩阵 | 邻接表存储<顶点,权重>对,邻接矩阵直接存储权重,按需选择 |
3.2 遍历算法的选型依据
需求场景 | 推荐算法 | 原因 |
|---|---|---|
寻找无权图的最短路径 | BFS | 层序遍历保证首次访问顶点时路径最短 |
拓扑排序(有向无环图) | DFS | 递归回溯时记录顶点完成时间,逆序即为拓扑序 |
检测图中的环 | DFS | 递归过程中检测回边(指向递归栈中顶点的边),效率更高 |
连通分量查找 | DFS/BFS | 两者均可,DFS实现更简洁(递归),BFS适合层序展示连通分量 |
四、总结
图的存储模型(邻接矩阵/邻接表)和遍历算法(DFS/BFS)是图论的基础,其底层逻辑直接决定了算法效率和适用场景。邻接矩阵以空间换时间,适合稠密图和频繁边判断的场景;邻接表以时间换空间,适合稀疏图和频繁遍历邻接顶点的场景。DFS和BFS的时间复杂度均由存储结构决定:邻接矩阵下为O(n²),邻接表下为O(n+e),两者的核心差异在于遍历策略(栈vs队列)和适用场景。
理解这些底层逻辑不仅能帮助开发者选择合适的数据结构和算法,更能为后续学习最短路径(Dijkstra、Floyd)、最小生成树(Prim、Kruskal)等高级图算法奠定基础。在实际开发中,需结合业务场景的顶点/边数量、操作频率等因素,选择最优的存储模型和遍历算法,以平衡时间和空间效率。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-15,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号