Transformer编码器的详细解析


编码器是什么
1. 宏观角色:从序列到表示
编码器的作用 :接收一个输入序列(如一句话的token序列),输出同样长度的、但蕴含了丰富上下文信息的表示向量序列。
通俗理解 :编码器就像是一个“深度阅读器”。它读入每个词,通过层层处理,让每个词的最终表示都“融合”了整个句子的上下文信息。输出的不是答案,而是 理解后的表示 ,供后续任务(分类、解码器生成等)使用。
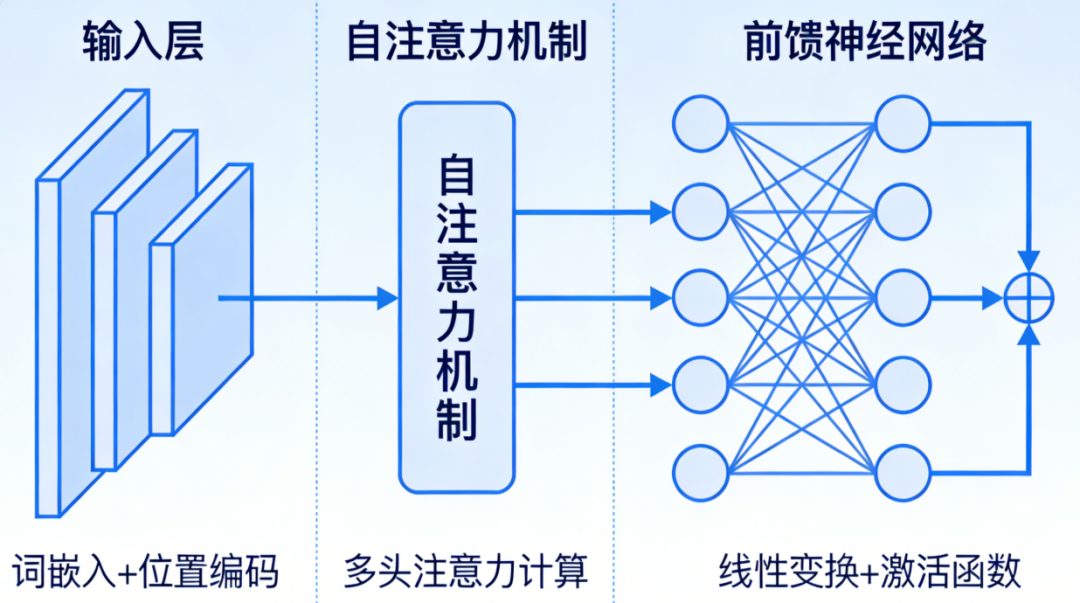
2. 为什么需要编码器?
在Transformer架构中,编码器的主要价值在于:
- 双向上下文建模 :与解码器不同,编码器在理解一个词时,可以同时利用它 左边和右边 的所有词。这是BERT等模型能够深度理解文本的关键。
- 特征提取 :将原始输入(词向量)转化为富含语义的、高维的特征表示。
- 作为独立模型 :可以只使用编码器部分(如BERT),完成分类、序列标注等任务。
3. 输入与输出
环节 | 说明 |
|---|---|
输入 | 词嵌入(Word Embedding)+ 位置编码(Positional Encoding) |
输出 | 与输入等长的向量序列,每个向量融合了全局上下文信息 |
输入输出尺寸 | 相同,均为 (batch_size, seq_len, d_model) |
2
编码器的核心模块
一个标准的Transformer编码器层由两个子层组成,每个子层都配有 残差连接 和 层归一化 。多个这样的层堆叠起来,就构成了完整的编码器。
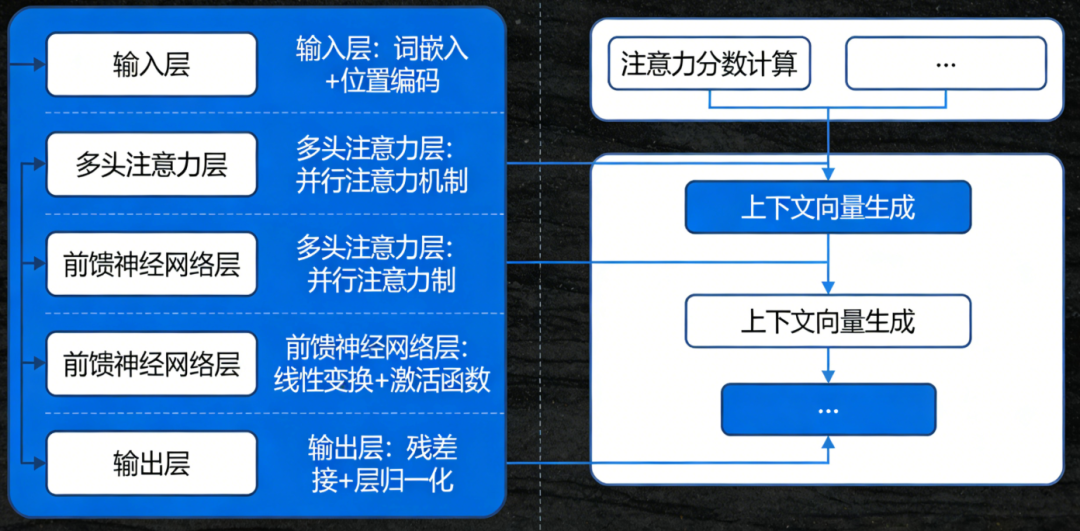
模块 | 作用 | 关键特性 |
|---|---|---|
多头自注意力 | 捕获序列内部的依赖关系 | 每个词都能看到所有词(双向) |
前馈网络 | 对每个位置独立进行非线性变换 | 增加模型容量,提取更高层特征 |
残差连接 | 让梯度直接流动,缓解梯度消失 | x + Sublayer(x) |
层归一化 | 稳定训练,加速收敛 | 在特征维度上标准化 |
1. 多头自注意力
这是编码器的核心,负责让序列中每个词与其他所有词“交流”。
工作原理 :对于输入序列的每个位置,通过Q、K、V机制计算该位置与其他所有位置的关联度,然后根据关联度聚合信息。
双向性 :与解码器不同,编码器的自注意力 没有掩码 ,每个位置都可以看到所有位置(包括后面的词)。这是“双向上下文”的技术实现。
多头机制 :多个注意力头并行计算,每个头关注不同类型的关系(语法、语义、指代等),最后将各头的结果拼接起来。
2. 前馈网络(Feed-Forward Network,FFN)
注意力层之后,每个位置的表示会独立通过一个前馈网络。
结构 :通常是一个两层的全连接网络,中间层维度通常是输入维度的4倍。公式为:
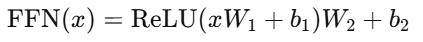
$ FFN(x)=ReLU(xW1+b1)W2+b2 $
作用 :对注意力层输出的信息进行“深加工”和“非线性变换”。研究表明,FFN在存储事实性知识方面起着重要作用。
位置独立 :FFN对每个位置独立操作,不同位置之间不共享信息(除了共享的参数)。
3. 残差连接与层归一化
每个子层(自注意力、FFN)周围都包裹着 残差连接 和 层归一化 ,这是训练深层网络的关键。
残差连接 :为梯度提供“高速公路”,让模型能轻松堆叠几十层。
x + Sublayer(x)
层归一化 :在特征维度上标准化,稳定训练。现代模型(如GPT、BERT)更倾向于 Pre-LN 结构(先归一化再进入子层),训练更稳定。
4. 堆叠多层
单个编码器层的能力有限,通过堆叠多个相同的层(如BERT-base有12层),模型可以逐步提取从浅层(语法)到深层(语义)的层次化特征。
3
编码器的工作流程
以一个完整的编码器层(Pre-LN结构)为例,其数据流向如下:
输入 x (来自上一层或嵌入层)
↓
层归一化(LayerNorm)
↓
多头自注意力(Multi-Head Self-Attention)
↓
残差连接:x + 自注意力输出
↓
层归一化(LayerNorm)
↓
前馈网络(FFN)
↓
残差连接:上一步输出 + FFN输出
↓
输出到下一层(或最终输出)在实际的BERT等模型中,这种结构会重复多次(如12次、24次),形成深层网络。
4
编码器 vs 解码器:关键区别
对比维度 | 编码器 | 解码器 |
|---|---|---|
自注意力 | 双向:每个位置能看到所有位置(无掩码) | 单向:每个位置只能看到前面位置(因果掩码) |
额外注意力 | 无 | 有编码器-解码器注意力,从编码器获取信息 |
典型应用 | BERT(纯理解)、ViT(图像分类) | GPT(纯生成)、机器翻译(与编码器配合) |
任务类型 | 理解任务(分类、抽取、相似度) | 生成任务(文本生成、翻译、摘要) |
5
编码器应用
应用 | 说明 | 示例 |
|---|---|---|
指令理解 | 将复杂的自然语言指令转化为机器可理解的表示 | “先走到A点,再拿起红色方块” → 向量表示 |
场景理解 | 结合视觉编码器(如ViT),理解机器人看到的环境 | 图像 → 编码器 → 场景语义特征 |
多模态融合 | 融合语言、视觉、传感器信息 | 文本编码器 + 视觉编码器 → 统一表示 |
对话状态跟踪 | 理解多轮对话历史,跟踪用户意图 | 编码器处理对话上下文,输出当前状态 |
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号