十几个 Skill 不够智能?OpenClaw 的 Skill 运作机制了解一下

十几个 Skill 不够智能?OpenClaw 的 Skill 运作机制了解一下

臻成AI大模型
发布于 2026-04-14 18:22:17
发布于 2026-04-14 18:22:17

很多人装了十几个 skill,用起来却感觉 AI 还是不够智能,问题可能不在 skill 本身,而在于你根本不了解它的加载逻辑。

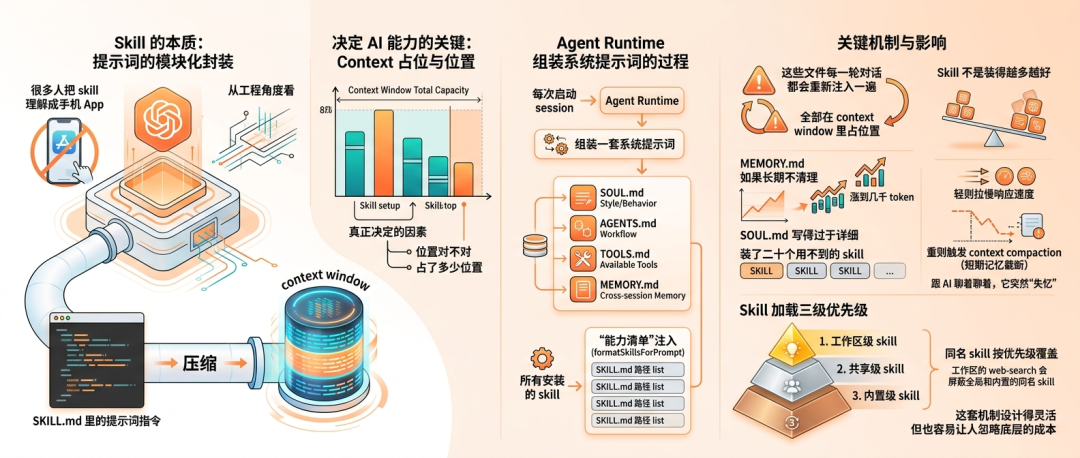
Skill 的本质:提示词的模块化封装
很多人把 OpenClaw 的 skill 理解成手机上的 App,装完就能用。
但从工程角度看,这套机制的本质是把 SKILL.md 里的提示词指令压缩进每一次 session 的 context window。
真正决定 AI 能力的,不是你装了哪些 skill,而是 skill 在 context 里占了多少位置、占的位置对不对。
OpenClaw 每次启动 session,Agent Runtime 会组装一套系统提示词。
这套提示词由多个文件构成:SOUL.md 定义行为风格,AGENTS.md 定义工作流规则,TOOLS.md 暴露可用工具,MEMORY.md 存储跨会话记忆。
所有你安装的 skill 都会通过 formatSkillsForPrompt 被转换成一张能力清单注入进去,告诉模型每个 skill 的 SKILL.md 在什么路径,用到的时候再去 read。
关键在于:这些文件每一轮对话都会重新注入一遍,全部在 context window 里占位置。
这个机制决定了 skill 不是装得越多越好。
MEMORY.md 如果长期不清理,很容易悄悄涨到几千 token;SOUL.md 写得过于详细也是常见问题;装了二十个用不到的 skill,最终都是 token 的负担。
轻则拉慢响应速度,重则触发 context compaction 把你的短期记忆截断——你跟 AI 聊着聊着,它突然失忆了,原因往往就在这儿。
OpenClaw 的 skill 加载采用三级优先级:工作区级 skill 最高,共享级 skill 其次,内置级 skill 最低。
同名 skill 按优先级覆盖,工作区的 web-search 会屏蔽全局和内置的同名 skill。
这套机制设计得灵活,但也容易让人忽略底层的成本。
记忆体系的结构性缺陷与解决方案
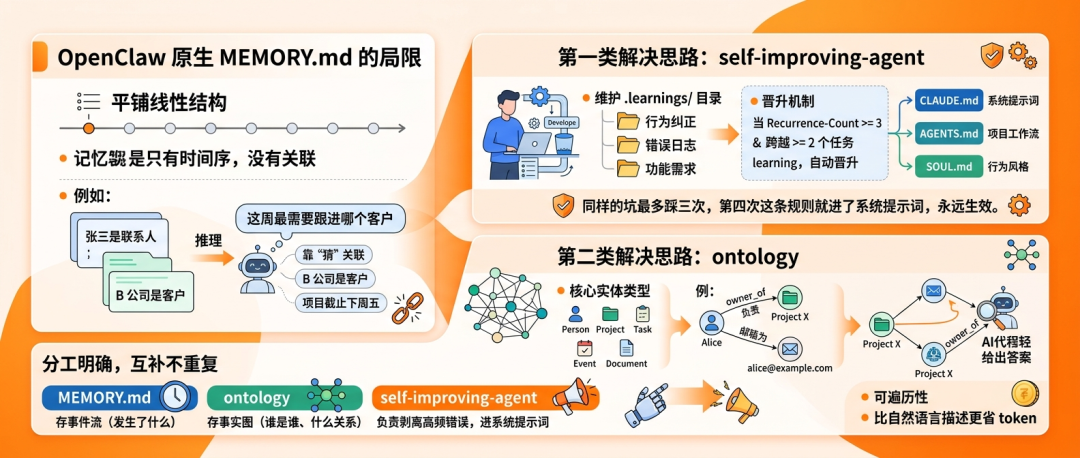
OpenClaw 原生的 MEMORY.md 是平铺线性结构,每条记忆之间没有关联,只有时间序。
你问"这周最需要跟进哪个客户",AI 能找到三条独立记忆:张三是联系人,B 公司是客户,项目截止下周五。但它不知道这三件事是连在一起的,需要靠生成时的推理去"猜"关联,而不是靠结构去"走"关联。
这个缺陷催生了两类解决思路。
第一类是 self-improving-agent(@pskoetta,星数 2.1k,下载 22 万)。
它维护一个 .learnings/ 目录,里面有三个文件记录行为纠正、错误日志和功能需求。真正有价值的是它的晋升机制:当一条 learning 被标记为 Recurrence-Count 大于等于 3,且跨越至少 2 个不同任务,它会自动晋升到 CLAUDE.md、AGENTS.md 或 SOUL.md,变成每次 session 启动时必定注入的永久规则。
同样的坑最多踩三次,第四次这条规则就进了系统提示词,永远生效。它本质上是在做记忆的优先级排序和持久化分流——高频规则进 CLAUDE.md,项目工作流进 AGENTS.md,行为风格进 SOUL.md。
第二类是 ontology(@oswalpalash)。
它引入了显式的知识图层,定义了 Person、Project、Task、Event、Document 等核心实体类型。当 AI 需要记住"Alice 是 Project X 的负责人,邮箱是 alice@example.com"时,它创建的是三个相互关联的节点,而不是一段平铺文本。
这种结构带来的最大好处是可遍历性。
你问"Project X 现在谁在负责",AI 沿着 owner_of 这条边走一步就能给出答案。更重要的是,结构化节点本身比同等信息的自然语言描述更省 token。
这两个 skill 的分工很明确:MEMORY.md 存事件流(发生了什么、什么时候说了什么),ontology 存事实图(谁是谁、什么关系、什么属性),self-improving-agent 负责把高频错误从 MEMORY.md 里剥离出来进系统提示词。
三个机制互补,不重复。
结语
skill 装得再多,如果不懂 context 预算管理,效果会大打折扣。
装 skill 之前先跑一遍 /context detail,看清楚你的 context 预算现在被哪些文件占了多少。
MEMORY.md 长期不清理很容易涨到几千 token,SOUL.md 写得过于详细也是常见问题。
ClawHub 的 skill 注入逻辑是只有 enabled: true 且平台满足 requires.bins 的 skill 才会出现在能力清单里。这意味着可以"装而不激活",先安装,需要的时候再开。
十个以内的活跃 skill 对 context 的影响在可接受范围内,但如果窗口配置本身比较紧,建议只先开 self-improving-agent,其他按需激活。
本质上,每个 skill 解决的是 OpenClaw 本身没有填好的坑——记忆的持久化、知识的结构化、行为的自我校正、外部知识库接入、多模态扩展。
ClawHub 上确实有 16000+ skill,但绝大多数不值得装。
挑 skill 的时候,先想清楚你要解决的是什么问题,再决定要不要占那个槽位。
上下文预算有限,精准占位比多多益善更重要。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-07,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号