一文讲清如何做好Workflow、RAG、Agent、Agentic RAG的技术选型!干货满满,不要错过

一文讲清如何做好Workflow、RAG、Agent、Agentic RAG的技术选型!干货满满,不要错过

烟雨平生
发布于 2026-04-14 18:45:17
发布于 2026-04-14 18:45:17
书接上文:“AI大佬”:未来是Agent的,Workflow和影刀RPA是垃圾
上周我们强调了Workflow的重要性,私下又有很多粉丝找过来,一定让我聊聊Workflow、RAG与Agent之间的关系,这一下就把我难住了,一个是这东西有撒好解释的?另一方面他们之间貌似没什么绝对的关系...
但是细细一想就会发现问题,也体现了一个AI现状:我们这些经常接触AI项目的,认为很简单的东西,其实多余数人是不清楚的,这个信息差比想象的大了很多!
比如,我天天发AI文章,我老婆一定是视而不见、甚至觉得有点烦的,所以我们觉得理所当然的知识,其他人可能真的不清楚,所以我们这里有必要再次好好解释一番:
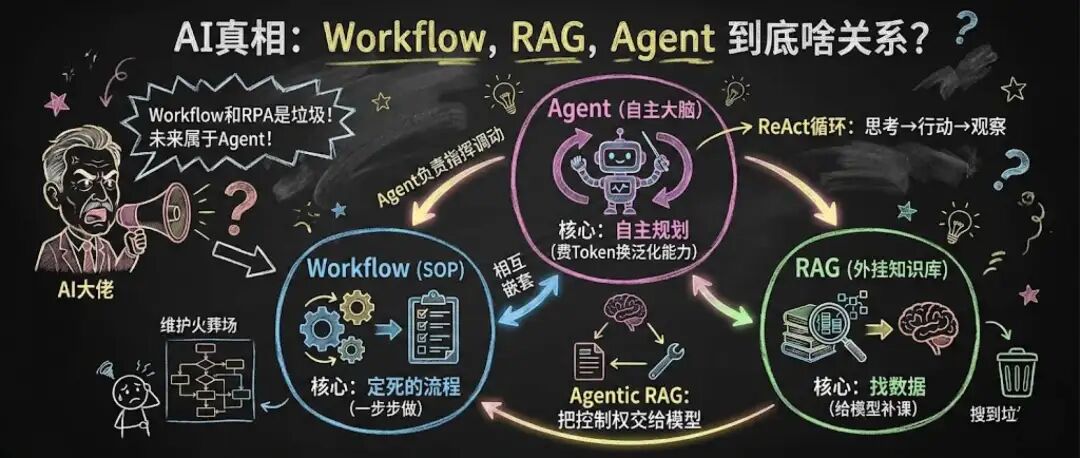
unsetunset三支柱unsetunset
不严格来说Workflow、RAG、Agent属于AI项目的三大支柱,他们分别对应不同的业务场景,比如:
- Workflow:HR提效(简历筛选、身份证录入);
- RAG:AI客服;
- Agent:复杂任务(根据问题自动搜索网址后生成材料如PPT、博客);
大家应该就看出来了,他们其实是三种技术路径,并且彼此之间并不是互斥的,比如RAG系统里面大概率有Workflow;Agent很可能既包含Workflow、又包含RAG。
按照我之前的定义,他们依次对应着算法、数据与泛化能力,说人话的话是:
- Workflow解决布置问题,让任务可控、步骤一步步执行;
- RAG让模型拿到需要的数据;
- Agent让系统复杂度降低,具备部分自主能力,能够组装合适的Workflow和找到合适的数据;
接下来我们做详细展开:
unsetunsetWorkflow → SOPunsetunset
Workflow又称为工作流,解决的是怎么一步步把这件事做完的问题,然后大家普遍认为Workflow是简单流程,难以表达业务的复杂性,所以大家用得更多的其实是SOP这个词,然后老板们从感受上也会觉得高级不少:

SOP对应我们常说的行业KnowHow,是我们要将这件事做好,应该具有什么样的流程,他是一套可以被设计的策略,将我们日常的动作翻译为技术语言,也就是我们常说的算法实现或者业务系统化。
Workflow的核心是整理,其背后对应着各种管理问题,包括沟通、设计等,这个是非常耗能力的。但如果只是Workflow + LLM的具体用法的话,最常见的是两种变形:
一、关键词提取
还是来看最经典的案例:
请问北京明天的天气情况如何?
工作流程序会执行两个操作:关键信息提取 + 流程执行。
对应这里的操作很简单,拿到明天到底是什么日期,拿到北京这个地点,时间地点提取成功后就调用天气查询接口。
这也是我们最初使用模型最最常用的功能,也是提升AI产品稳定性的核心,专业名称是:实体提取 或 槽位填充,我自己更喜欢用关键词提取这个词。
除了关键词提取外,第二个就是意图识别了:
二、意图识别
依旧是请问北京明天的天气情况如何?这个案例,为什么我们是要调用天气接口,而不是调用其他接口,这里的背后就是LLM最主要的能力,自然语言理解,其背后对应着意图识别。
大家可以看到,其实Agent的基石,Function Calling Tools调用的准确性也是在此。
什么时候要调天气接口、什么时候要调旅游规划接口、什么时候要...
这是我们提前规划好的,提前设计清晰的,如果是模型识别不准那么我们针对性处理即可,可以是微调、也可以是提示词注入,这里大家也一定意识到了:
我们常说的模型的可观测性,其实更多的就在这里
为什么Workflow还不够
到这里问题也就出来了,按理说Workflow这种模式很稳定,各个企业应该很喜欢啊,毕竟现阶段大模型最让人诟病的就是不稳定。
这里的答案是:对的,各个企业确实都喜欢Workflow,并且实际跑在生产环境的80%都是Workflow,真正不喜欢Workflow的是两种人:
- 第一,做Agent的那批人,尤其是需要融资和卖课的;
- 第二,研发人员;
那么为什么研发人员不喜欢Workflow呢?答案是太复杂了,维护起来全是泪,这是一个工程问题,比如下图是维护了3年的Workflow:
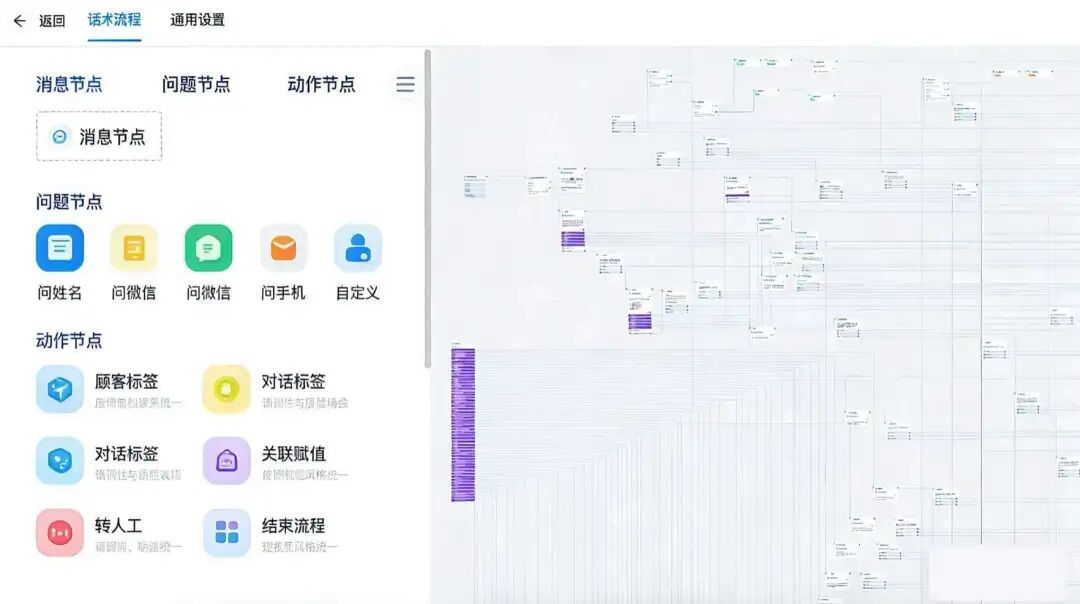
Workflow的挑战不在技术难度而是维护难度,需要面对的是:
- 不断新增的意图;
- 不断变化的策略(需求);
- 用户千奇百怪的表达;
- ...
也就是有限的Workflow需要面对无穷的用户意图(与表达),最终结果就是维护成本爆炸,到一定时间后谁改谁错。
至此,相信大家对什么是Workflow,包括Workflow有什么优缺点是比较清楚的了,我们接下来再说RAG:
unsetunsetRAGunsetunset
模型本身的知识是训练进去的语料,这东西肯定是不满足当前的信息流速的,为了获取更新、更专业、更隐私的知识,RAG技术应运而生。
RAG常用的数据源是本地结构化知识库 与 网络信息,但更多形式的也支持,包括PDF、Word、Excel、图片......
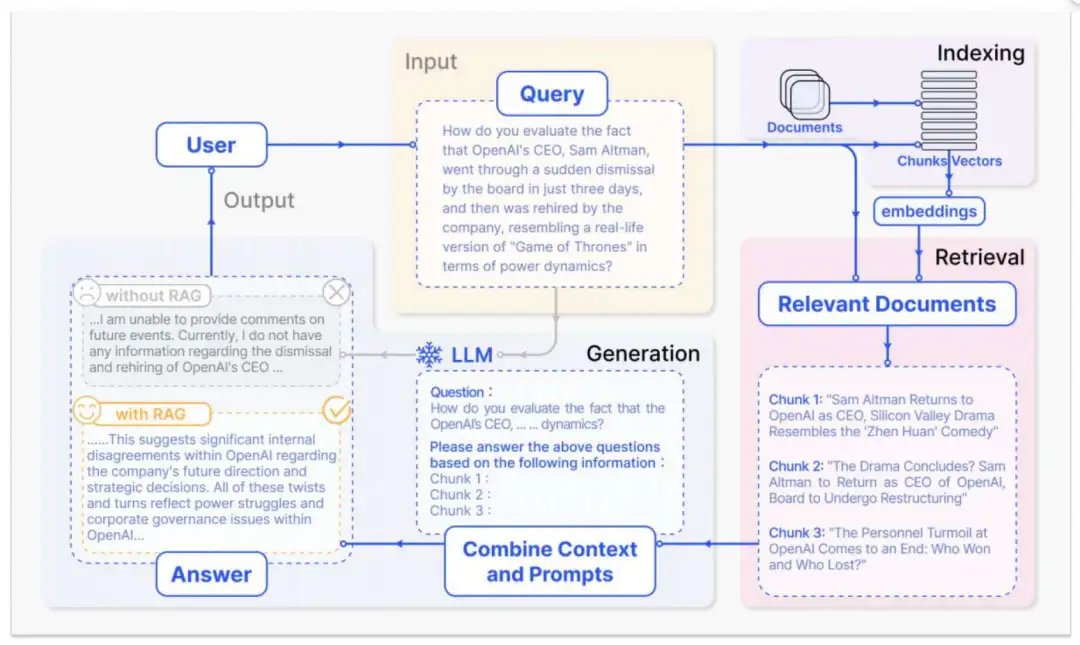
RAG难的核心表面上看是如何每次把用户需要的知识搜索出来,但背后真正难的是如何进行数据结构设计、如何清洗数据、如何处理用户问题......
到这里大家应该就看明白了:RAG是一定离不开Workflow的,因为数据如何清洗、如何存储、用户问题又如何重写、最终检索的内容如何排序等全部都是一个个小Workflow。
并且,整体RAG框架看起来简单,用起来非常难,很多同学掌握Workflow很快,到让他做个简单AI客服,一下就懵逼了,这里我们也描述下简单RAG项目怎么做,这里只说策略不举例,一次完整的RAG流程是:
用户提问 → 检索操作 → 返回结果
很多同学这里最大的问题是:检索返回的都是不相关的垃圾信息。于是整个流程就宣告失败;如果返回了想要的内容,但是其中垃圾信息较多,也不能算成功。
搜索成功的核心有二:
- 第一是用户输入,这东西是不可控的,所以问题或者说拿去检索的关键词一定会被转写和优化;
- 第二是一定要保证在输入(用去搜索那个关键词)没问题的情况下一定要能得到正确的结果,这一块就要求最初的数据处理了;
改写用户查询,会慢及最烦躁的数据入库处理:
一、查询改写
这块也不只是RAG需要面临的问题,对于Agent的Tools调用,也会遭遇相同的问题:用户语言太模糊,他具有多意图,泛化能力要求极高,这东西只有模型能够解决。
还是那句话:用户无限的意图需要被有限的工具所收敛、对应着用户的无限问题需要被知识库做边界。
比如用户一句话可能有多个问题,但我们需要处理的只能是知识库里面有的问题,如果没有那么就无需处理。
综上,重写查询,相当于在检索前做一轮语义收束(Convergence / Narrowing down),会大大提升检索精确度,当前常见的策略是查询分解,偶尔会用到HyDE(Hypothetical Document Embeddings,假设文档嵌入):
查询分解的核心思维是分而治之,将复杂或多意图查询拆分为独立的原子子问题;
HyDE (假设文档嵌入)属于先脑补,后检索,让LLM基于问题生成一份“假设答案”,用其丰富语义去检索;
这里具体如何做查询分解和HyDE我们就不展开了...
二、查询效果评估
查询改写后就开始真正的查询,问题就变成了如何评价每次查询的质量,这个是非常经典的面试题,常见的评估指标有:
- 检索召回率(Recall@k):改写后的查询,能否在 top-k 个检索结果中命中正确答案的文档;
- 查询意图保持度:人工抽样检查,改写是否歪曲了用户原意;
- 下游任务准确率提升:最终答案的准确率是否因改写而显著提升;
也有通俗一点的说法:
- 没召回(入库/切分/索引问题)
- 召回了没选对(重排问题)
- 选对了答歪(提示词/生成约束问题)
- 本来就不该答(范围外问题/需要工具调用/需要人工)
但是每次我以为说清楚了,都还是有同学没明白,所以这里还需要进一步说细点:
首先,评估查询质量要细化到每个链条,这里依次是:
- 路由正确 - 问题是否分到对的意图模块;
- 召回可靠 - 关键证据有没有被找到;
- 排序合理 - 正确证据是否排在前列;
- 回答可证 - 答案是否严格基于证据;
- 边界清晰 - 不该答的是否恰当处理;
然后接下来就是具体的标准,这东西还不能一蹴而就,是个逐渐加强的过程,具体细节这里也不展开,给个简单案例表,大家体验下就行:
错误类型 | 常见现象 | 修复 |
|---|---|---|
路由错(去哪搜错了) | 意图漏标/多标;多意图未拆;路由到错误模块导致检索空间不对 | 调整意图体系与描述;补训练样本/难例;阈值与多标签策略;增加澄清追问;路由后做“兜底检索” |
搜不到(召回缺失) | top-k 完全无证据;同义词/别名命不中;长文被切碎导致证据散落 | chunk策略(大小/重叠/结构化切分);标题/摘要/条款号入库;元数据过滤;混合检索(BM25+向量);同义词与别名表 |
搜到但没排上来(排序问题) | 正确证据在 top-k 但不在 top-3;冲突条款被旧版本压住;相似chunk重复占位 | 重排模型/规则重排;版本优先级与适用范围加权;去重与聚合;top-k扩展+二次检索 |
证据对但回答错(生成失真) | 引用到了但结论算错/漏答;把多个chunk拼错;冲突条款未声明冲突 | “只基于证据”生成约束;逐条引用/引用-断言绑定;冲突处理模板(列差异+请求确认);计算/规则类走结构化解析或工具化 |
边界处理错(该不该答) | 不该答还答;该答却拒/追问过度;缺关键槽位不追问直接编 | 边界定义与范围外策略;缺槽追问模板;拒答阈值;转人工条件;对“可答但缺信息”设置最小追问集 |
RAG问题太过复杂,我们这里稍微点一下就好,应该足够清晰描述他与Workflow的关系了,最后就是Agent了:
unsetunsetAgentunsetunset
前面我们说了用户无穷的意图难以被有限的Workflow、知识表述,否则无论Workflow还是RAG(Data)的维护成本都会奇高,最终AI项目就会夭折。
在这个基础下Agent应运而生,虽然这东西从描述上似乎“牛逼轰轰”的:具有自主规划并具有执行能力,能最终交互结果的系统;
但其实很简单:就是为了解决Workflow泛化能力不足的问题,其本质是用循环增加Token消耗,去换取生成的Workflow更合理的架构,最终解决的Workflow工程维护问题;
对应着的Agentic RAG是一样的,常规的RAG其实也是写死了的Workflow,因为Workflow固定也因为数据格式的固定,所以这里稍微有点需求变化就要上硬代码,但Agent也同步解决了这个问题。
只不过,暂时Agent解决Workflow的效果还不错,但是Agentic RAG做得一般
还是之前最常见的问题:请问明天成都天气怎么样,我明天飞机到成都,要去旅游。
这里用户的意图是很多的:
- 清晰的天气查询;
- 模糊的接送机、酒店预定、旅游计划制定;
这就是Agent了:开放、模糊、需求不确定、步骤不确定。然后Agent的ReAct架构就会使用大模型的能力自己生成Workflow:
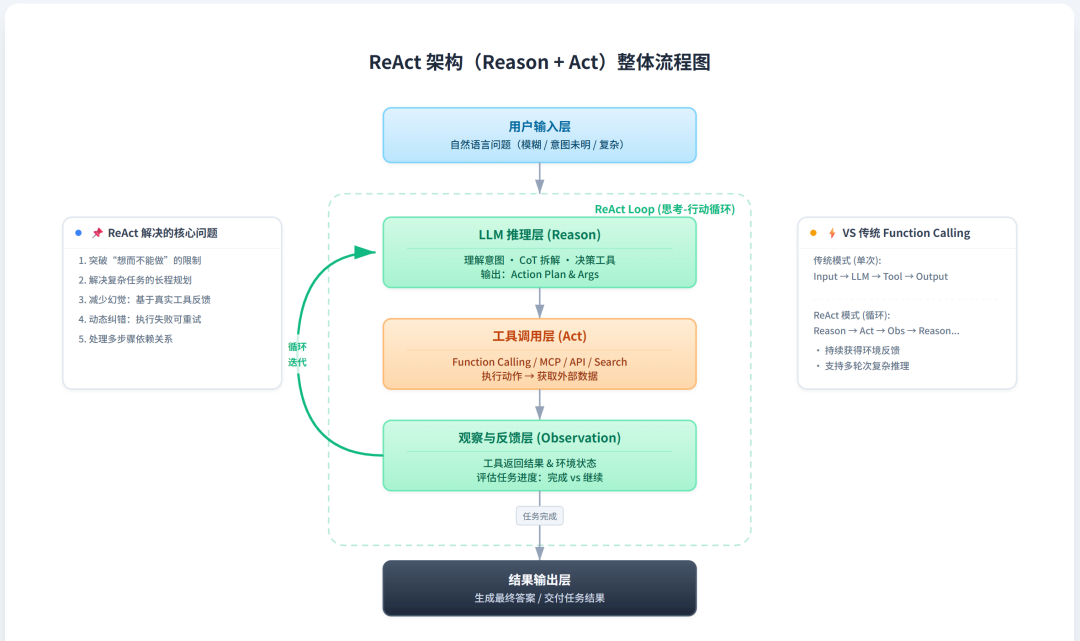
对于初学者,可以粗暴的认为ReAct框架就是Agent:
ReAct
从模型演进角度看,LLM长期存在一个硬伤:只能想、只能说,不能做。
Function Calling/Tool Calling的出现,本质是把“外部能力”挂到模型上,但在真实场景中很快就暴露问题:工具一多、问题一模糊,模型就开始乱调、错调,整体稳定性很差。
这里一方面是模型理解能力不足,另一方面是生成的Workflow不好,于是乎ReAct架构就来了,他的价值不是让模型更聪明,而是通过一个固定循环,把“思考”和“行动”强行绑在一起:
推理(Thought)→ 行动(Action)→ 观察(Observation)→ 再推理
模型是一次性生成答案,Agent是边想边做、看结果再决定下一步。复杂问题被拆成多个可验证的小步骤,每一步都有明确的输入、输出和反馈。
例如“2018 年世界杯冠军国家的总统是谁”,Agent 会先确认冠军国家,再查询该国总统信息,两轮“思考 → 行动 → 观察”后得到最终答案。
这种方式的意义不在步骤多,而在于错误不会一次性放大,这也是 ReAct 能显著降低幻觉的根本原因。
但需要清醒地认识到:ReAct并不是银弹。
它本质上是用更多 Token、更多状态管理、更多工程复杂度,去换取 Workflow 的泛化能力。每一轮循环都是成本,每一次决策错误都会被放大,状态设计、上下文管理、工具选择,都会成为新的工程难点。
很有可能的情况是:2次循环做不好的,10次也做不好,所以需要做很多工程优化。我们最后说下Agent 与 RAG 的关系:
Agentic RAG
传统的RAG在使用过程中,大家慢慢发现一些问题:
- 先查向量库;
- 再 Top-K;
- 然后塞 Prompt;
- 最后生成;
流程非常清楚,但问题也很明显:一旦问题变复杂,流程就不够用了。
与之前Workflow一样,Agentic RAG出现了,他把这件事交给模型:
- 现在该不该继续查?
- 是查正文,还是查附录?
- 是换关键词,还是换数据源?
- 证据够不够,能不能回答?
这些“判断”,过去都藏在 if-else/Workflow 里,靠经验硬编码;现在是通过 ReAct,把决策权前移给模型,但执行权仍然在工程侧。所以你会发现一个非常重要的分工变化:
Agent 不“干活”,Agent 负责“指挥谁干活”。
很多人开始以为Agentic RAG是一种“新的RAG形态”,但你仔细拆就会发现:
- 数据怎么存?没变
- 数据要不要处理?还得清洗
- 表格怎么处理?还是工程
- 引用怎么校验?依旧规则
- ......
所以,什么都没有变,唯一变化的,是控制流。Agentic RAG 是:人设计能力边界 → 模型在边界内调度流程。
这意味着什么?它有效解决了传统RAG在应对复杂、多跳查询时,因流程僵化而导致的信息割裂、证据不全等顽疾。
例如在法律、医疗等专业领域,Agentic RAG能模拟专家的工作流,从海量文档中精准定位并交叉验证信息,输出可追溯、可审计的结论。
但要注意,这种强大的灵活性以更高的工程复杂度和推理成本为代价。它并非替代了数据处理等基础工作,而是对数据质量和系统架构提出了更高要求。
未来,Agentic RAG的发展方向将是框架化、组件化,通过提供更成熟的“技能”(Skills)库和调度框架,降低其应用门槛,让开发者能更聚焦于业务逻辑而非底层实现。
unsetunset结语unsetunset
以上就是Workflow、RAG、Agent之间的关系,如大家看到的,他们直接其实没什么必然的关系...
最后,文章求分享,感谢!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-01-19,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号