为什么我还是无法理解Transformer?Transformer到底是什么?

为什么我还是无法理解Transformer?Transformer到底是什么?

烟雨平生
发布于 2026-04-14 18:53:22
发布于 2026-04-14 18:53:22
究其原因,是但凡讲到 Transformer,铺天盖地的资料上来就直奔自注意力机制(Self-Attention)的 Q、K、V 细节,只钻枝叶、不谈全局,只见树林,不见森林。
Transformer灵魂1问:如何理解Attention中的Q,K,V?你会了吗?一文讲清楚
为什么会这样?
自注意机制是Transformer的创新点,不讲清楚自注意力机制(Self-Attention),就不能掌握Transformer强大之处。训练大模型的pipeline已经很成熟了,只是与Transformer的架构相比,又慢效果又不好。而Q、K、V又是自注意机制核心结构。当然并不是一定要用Q、K、V,但目前看,这样的结构很好使。具体为什么,此处就不展开了,想深入了解的同学可以移步为什么我还是无法理解Transformer?Attention的本质是什么?为什么向量之间乘一乘就能得到Token之间的相似度了?
但对初学者而言,单搞懂自注意力机制的 Q、K、V,远远不够。
为什么?
学习 Transformer 的人,必然是带着实际需求来的 —— 它的设计初衷是什么?核心解决什么问题?落地能实现什么价值?自注意力机制的 Q、K、V,只讲清了 “是什么”,却没说透关键的 “能做什么”。
大家学习 Transformer,绝非只为调用现成的 API(毕竟这无需深究底层),核心诉求其实是弄懂如何训练一个大模型。
接下来我们看看训练大模型的标准流程,大家不妨思考:Transformer 架构,究竟在哪个环节发挥核心作用?
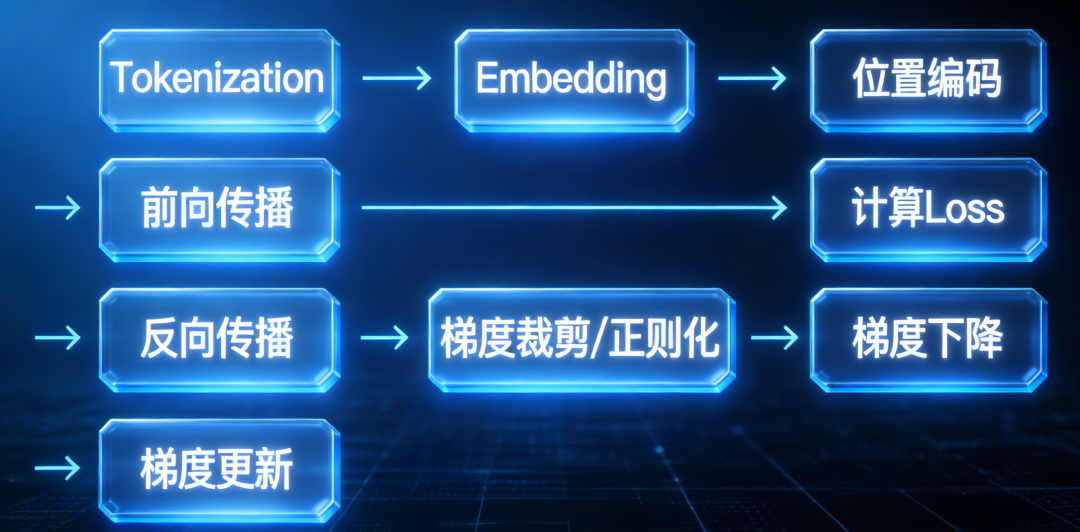
是“前向传播”。
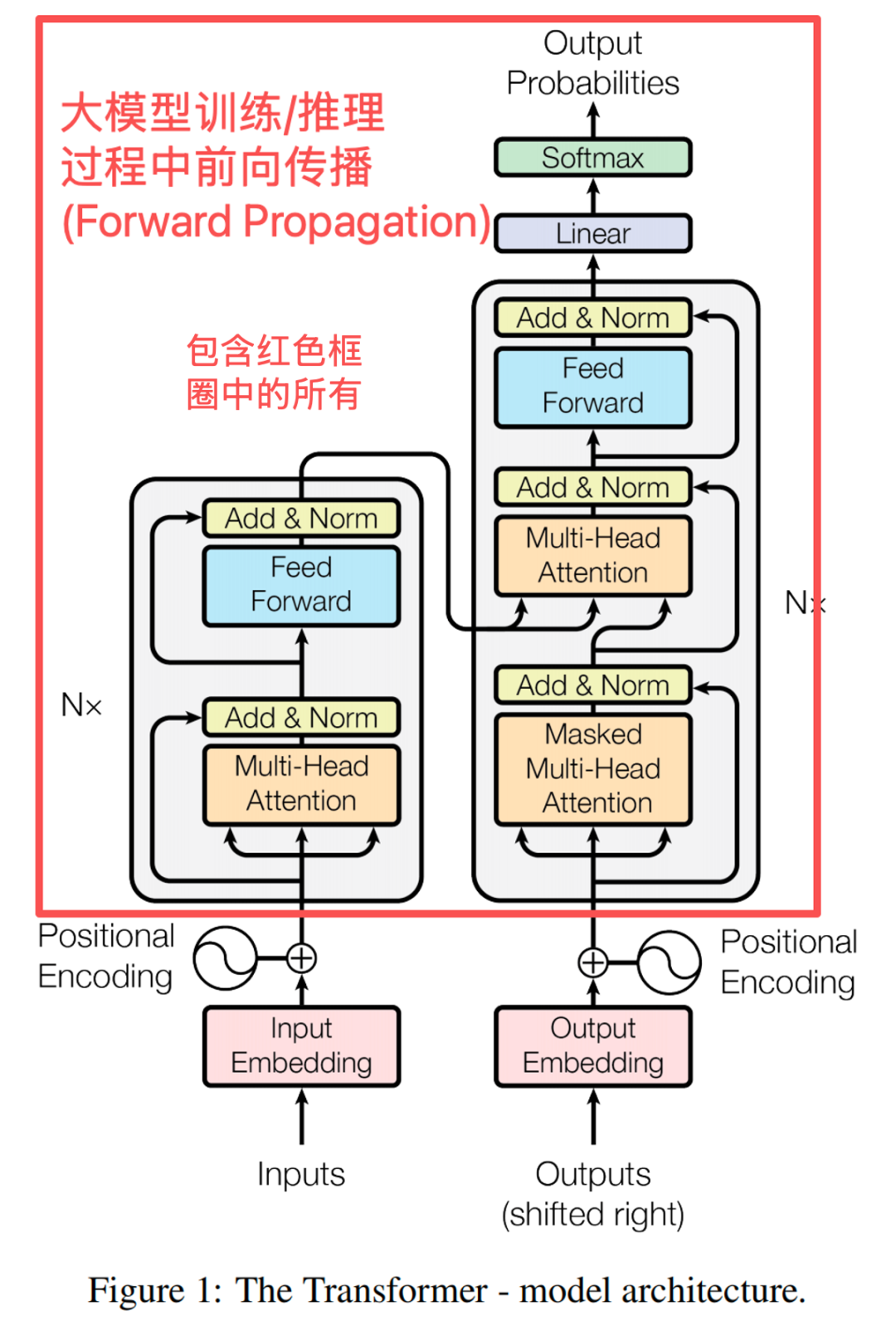
如果把一次大模型训练过程称为森林的话,Transformer架构只是其中的树林,一个很重要的树林。
看了上面了两个图,是不是有点感觉了。有点有面,有局部有全局。
Transformer架构现在已经统治了大模型时代。
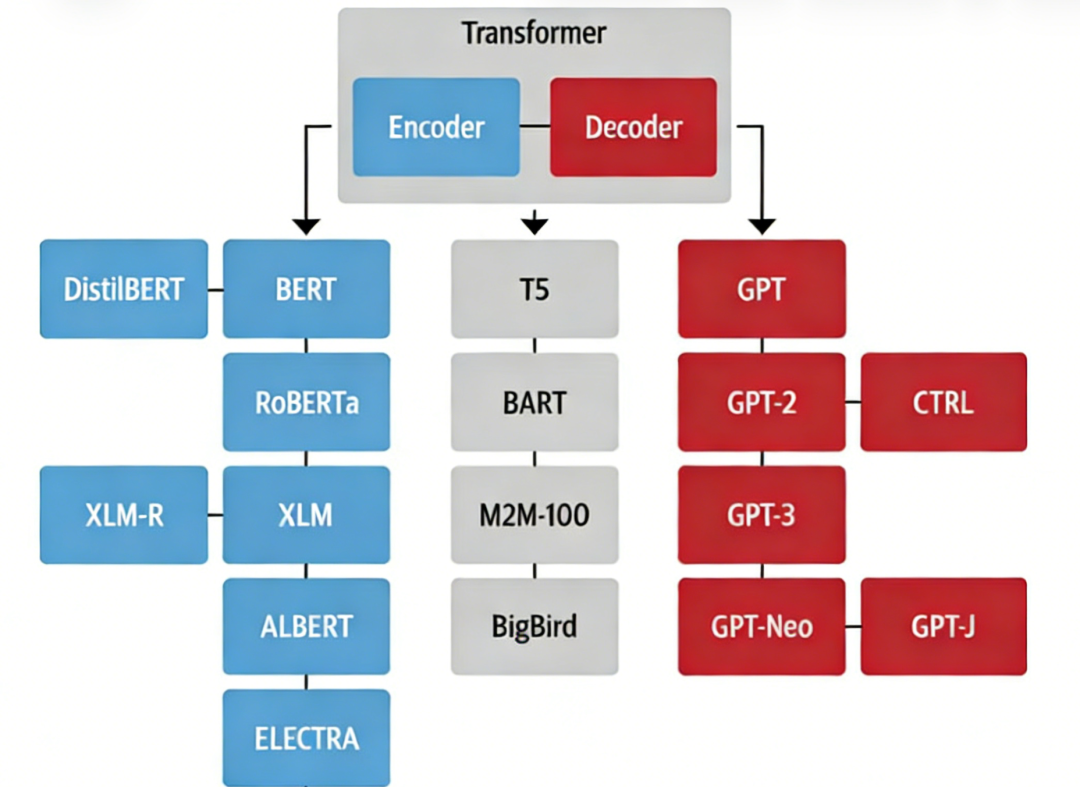
那Transformer架构究竟是什么?它是一种神经网络结构,是一种经众多企业与研究机构验证、具备极高实用价值的神经网络结构。
Transformer 由 Ashish Vaswani 等人在 2017 年的经典论文《Attention Is All You Need》中首次提出,该架构创新性引入自注意力(Self-Attention)机制,彻底摒弃了传统的循环神经网络(RNN)与卷积神经网络(CNN)结构,不仅大幅提升了模型的训练效率,还显著增强了长序列的处理能力,也因此成为后续各类先进大模型的核心基础架构。
上面讲的有点学术,再总结一下:
Transformer架构开创性地以自注意力机制(Self-Attention)为核心,摒弃传统循环与卷积结构,依托多头注意力(Multi-Head Attention)和位置编码(Positional Encoding)实现计算并行化,还能高效捕捉序列中的长距离依赖关系。这一创新的神经网络结构,有效解决了传统序列模型在计算与长距离依赖捕捉上的效率难题,大幅提升了前向传播与特征建模的效率,其实用性已被众多企业和研究机构验证,也由此掀起人工智能发展的全新浪潮。如今,Transformer 架构更是成为大模型时代无可争议的核心基石。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-06,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号