2026“金三”必看:写一个查询各学科成绩第二名的SQL

2026“金三”必看:写一个查询各学科成绩第二名的SQL

烟雨平生
发布于 2026-04-14 18:54:41
发布于 2026-04-14 18:54:41
如题:表score中有字段 id,stu_id,subject_id,score 写一个sql筛选出各学科成绩第二名的学生。
思考3秒,有想法了,再往下看。
参考SQL1:
SELECT
s1.subject_id,
s1.stu_id,
s1.score
FROM stu_score s1
WHERE
s1.score IS NOT NULL
AND 1 = (
SELECT COUNT(DISTINCT s2.score)
FROM stu_score s2
WHERE s2.subject_id = s1.subject_id AND s2.score > s1.score
)
GROUP BY s1.subject_id, s1.stu_id, s1.score;SQL执行结果:
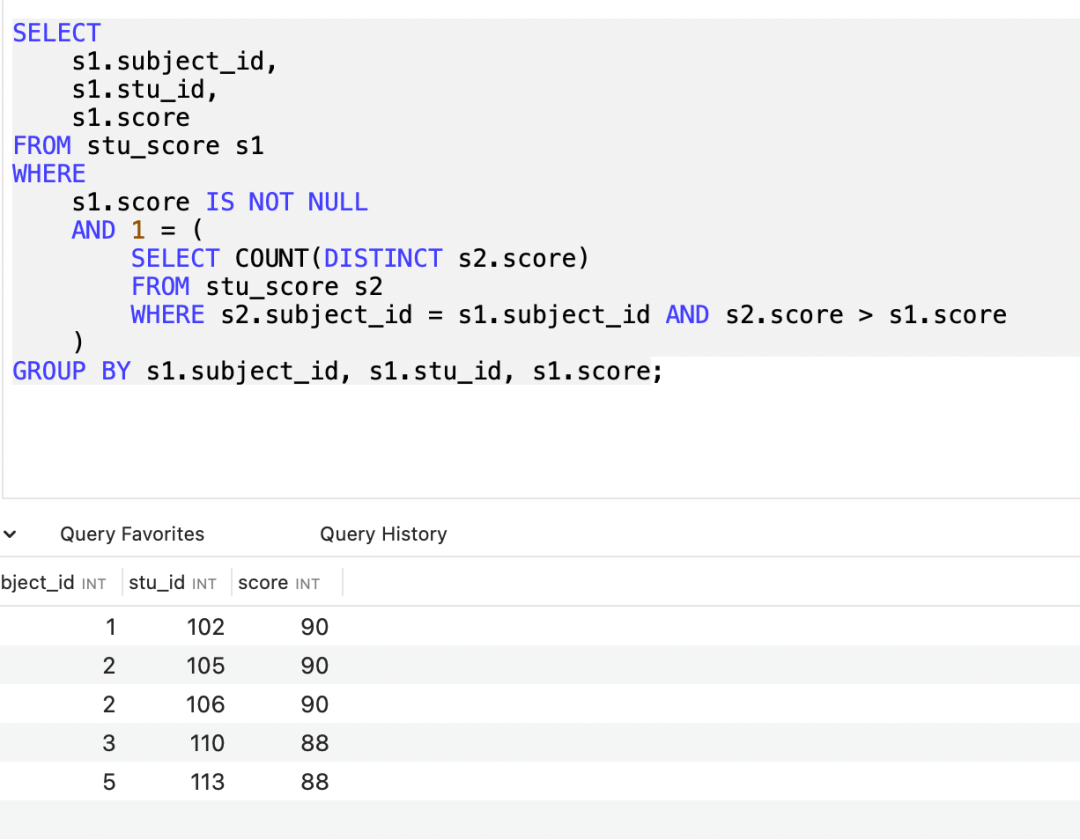
下面是表结构及测试数据:
-- 创建成绩表(score),字段与需求完全匹配
DROP TABLE IF EXISTS stu_score; -- 先删除已存在的表(可选,避免重复创建)
CREATE TABLE stu_score (
id INT PRIMARY KEY AUTO_INCREMENT COMMENT '主键ID,自增',
stu_id INT NOT NULL COMMENT '学生ID',
subject_id INT NOT NULL COMMENT '学科ID',
score INT COMMENT '成绩(允许NULL,模拟无成绩的情况)'
) COMMENT '学生成绩表';
ALTER TABLE stu_score
ADD INDEX idx_subject_score(subject_id, score);
-- 清空表数据(可选,确保测试数据纯净)
TRUNCATE TABLE stu_score;
-- 插入测试数据
INSERT INTO stu_score (stu_id, subject_id, score) VALUES
-- 学科1(subject_id=1):无并列,第二名仅1人
(101, 1, 95), -- 第1名
(102, 1, 90), -- 第2名
(103, 1, 85), -- 第3名
-- 学科2(subject_id=2):第二名2人并列
(104, 2, 98), -- 第1名
(105, 2, 90), -- 第2名(并列)
(106, 2, 90), -- 第2名(并列)
(107, 2, 88), -- 第3名
-- 学科3(subject_id=3):2人并列第1,无第二名(跳跃排名场景)
(108, 3, 95), -- 第1名(并列)
(109, 3, 95), -- 第1名(并列)
(110, 3, 88), -- 第3名(无第二名)
-- 学科4(subject_id=4):仅1条数据,无第二名
(111, 4, 80),
-- 学科5(subject_id=5):含NULL成绩(验证过滤逻辑)
(112, 5, 92), -- 第1名
(113, 5, 88), -- 第2名
(114, 5, NULL); -- 无成绩,应被过滤参考答案解析:
1. SELECT
2. s1.subject_id,
3. s1.stu_id,
4. s1.score
5. FROM stu_score s1 -- 外层表别名s1,代表“当前待判断的成绩记录”
6. WHERE
7. s1.score IS NOT NULL -- 过滤条件1:排除无成绩(score为NULL)的记录
8. AND 1 = ( -- 过滤条件2:核心逻辑——当前记录是“第二名”
9. -- 子查询:统计同一学科中,比当前记录成绩更高的“唯一分数”个数
10. SELECT COUNT(DISTINCT s2.score)
11. FROM stu_score s2 -- 内层表别名s2,用于和s1对比成绩
12. WHERE
13. s2.subject_id = s1.subject_id -- 限定:只对比同一学科的成绩
14. AND s2.score > s1.score -- 限定:只统计比当前成绩高的分数
15. )
16. GROUP BY s1.subject_id, s1.stu_id, s1.score; -- 分组去重,避免重复记录1. 外层查询(第 1-5 行)
FROM stu_score s1:把score表别名为s1,s1可以理解为 “当前正在检查的那条成绩记录”(比如检查学生 102 的学科 1 成绩 90)。
SELECT s1.subject_id, s1.stu_id, s1.score:最终要输出的字段 —— 学科 ID、学生 ID、成绩。
2. 过滤条件 1(第 7 行):s1.score IS NOT NULL
作用:排除没有成绩的记录(比如测试数据中学科 5 的学生 114,score 为 NULL),避免无意义的计算。
如果不加这个条件,NULL 值会导致子查询的COUNT结果异常(NULL 无法和任何值比较大小)。
3. 核心过滤条件2(第 8-15 行):1 = (子查询)
这是整个 SQL 的核心,我们用测试数据中的例子(学生 102,学科 1,成绩 90)来拆解子查询的执行逻辑:
子查询的作用:统计 “学科 1 中,比 90 分更高的唯一分数有多少个”;
每一条外层记录都要执行一次子查询。
执行过程:
s2.subject_id = s1.subject_id
只查学科 1 的记录;s2.score > s1.score只查分数 > 90 的记录(学科 1 中只有学生 101 的 95
COUNT(DISTINCT s2.score)统计这些高分的 “唯一值个数”(95 是唯一值,结果 = 1);
外层条件1 = 1成立,所以学生 102 的这条记录会被选中(是第二名)。
再举一个并列第二名的例子(学生 105,学科 2,成绩 90):
子查询统计 “学科 2 中> 90 分的唯一分数”:只有 98 分,COUNT 结果 = 1 → 条件成立,选中;
学生 106(学科 2,成绩 90)的子查询结果同样 = 1 → 也会被选中,实现 “并列第二名都查出”。
再举一个无第二名的例子(学生 110,学科 3,成绩 88):
子查询统计 “学科 3 中> 88 分的唯一分数”:只有 95 分,COUNT 结果 = 1?不 —— 学科 3 中 95 分是并列第一,DISTINCT后还是 1 个,但是为什么 RANK () 的 SQL 中它是第三名?
这里要注意:这段 SQL 的逻辑是 “比当前成绩高的唯一分数有 1 个 → 就是第二名”,而 RANK () 的逻辑是 “有 2 个并列第一,所以 88 分是第三名”—— 这也是这段 SQL 等价于 DENSE_RANK () 的原因。
4. GROUP BY(第 16 行):分组去重
作用:避免同一学生、同一学科有重复的成绩记录(比如某学生同一学科被录入两次 90 分),导致结果中出现重复行。
分组字段subject_id, stu_id, score:这三个字段组合能唯一标识 “某学生某学科的某个成绩”,确保结果无重复。
关键细节补充
为什么子查询要用COUNT(DISTINCT s2.score)而不是COUNT(s2.score)?
如果不用DISTINCT,统计的是 “比当前成绩高的记录数”,而非 “高分的唯一值个数”。
比如学科 3 中,学生 108 和 109 都是 95 分,若用COUNT(s2.score),学生 110(88 分)的子查询结果 = 2 → 外层条件1=2不成立,符合 RANK () 的逻辑;而用DISTINCT后结果 = 1 → 符合 DENSE_RANK () 的逻辑。
这是 “是否允许并列第二名” 的核心控制。
这个SQL的执行效率?
缺点:属于 “相关子查询”(子查询依赖外层的 s1),每一条外层记录都要执行一次子查询,数据量大时效率较低;
优点:兼容无开窗函数的老版本 MySQL,逻辑易懂。
总结
核心逻辑:通过子查询统计 “同一学科中比当前成绩高的唯一分数个数 = 1”,判定该成绩为第二名(含并列);
DISTINCT是关键:确保统计的是 “唯一高分值”,而非 “高分记录数”,实现并列第二名的查询;
GROUP BY用于去重:避免同一学生同一学科的重复成绩导致结果冗余。
这段 SQL 是老版本 MySQL 中替代开窗函数的经典写法,核心是用 “计数高分值个数” 来模拟排名逻辑。
看看理解的对不对?还没有完全理解?那我们从SQL查询的执行顺序来拆解一下。
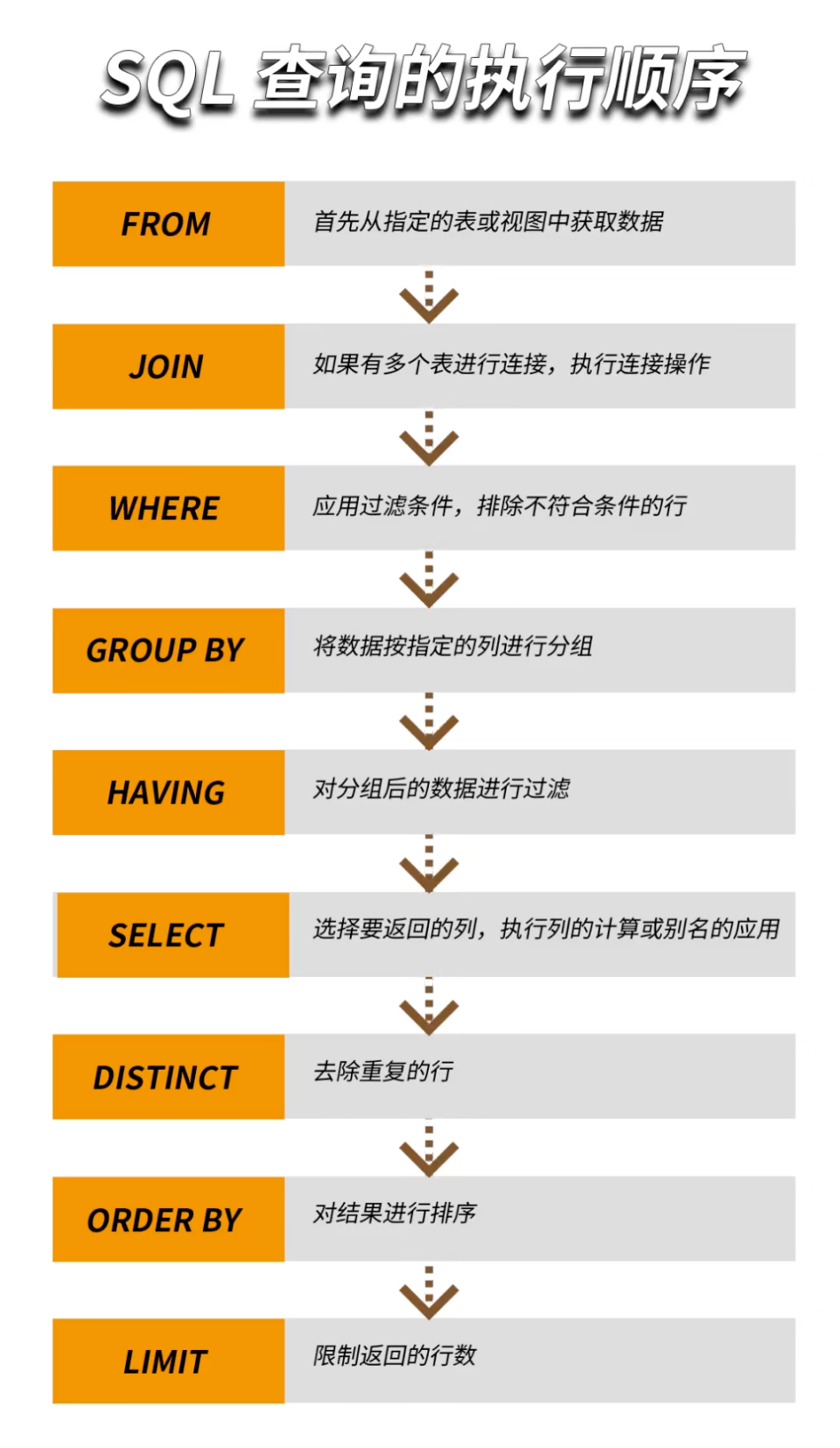
SQL查询执行顺序全解析:从声明到结果
🔸SQL作为声明式语言:SQL允许我们声明所需结果,而不必指定如何得到这些结果。这为开发者提供了抽象层,专注于“什么”而非“如何”。
🔸查询编写与执行顺序:编写SQL时,我们按照SELECT、FROM、WHERE等顺序编写,但数据库执行时,执行顺序:FROM → WHERE → GROUP BY → HAVING → SELECT → ORDER BY → LIMIT
看完后,是不是有点感觉了。
另外,这个需求只有这一种写法吗?
有的,但需要MySQL版本>5.7
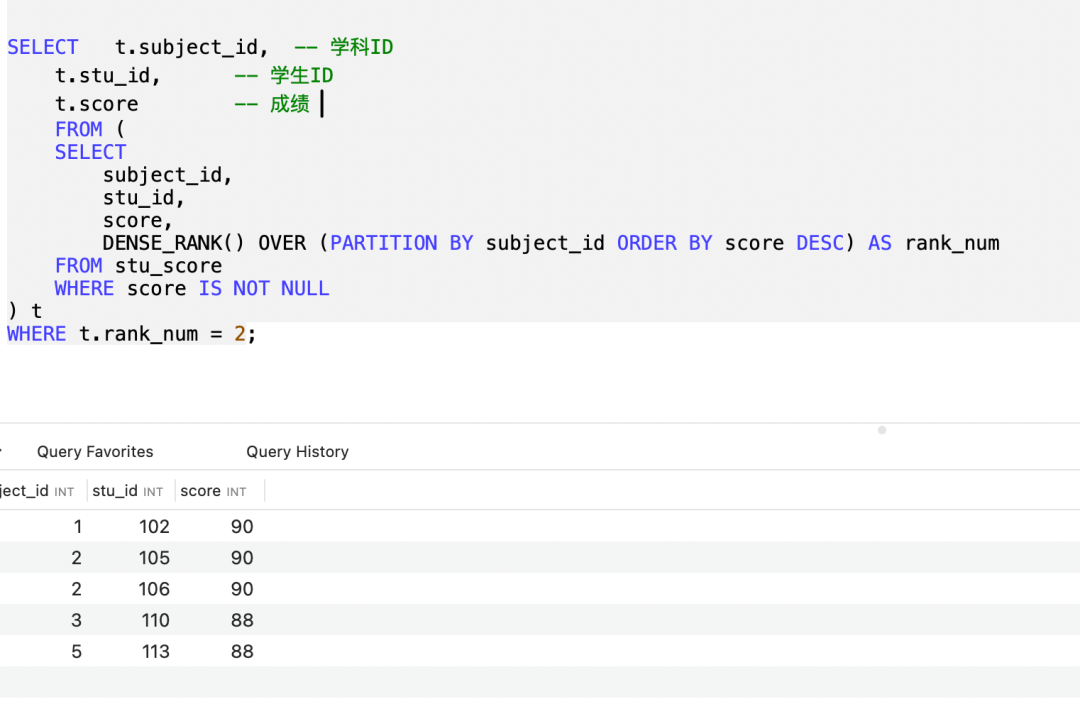
-- 核心功能:查询各学科成绩第二名的学生(连续排名规则:并列第一后下一个分数即为第二名)
SELECT
t.subject_id, -- 输出字段:学科ID
t.stu_id, -- 输出字段:学生ID
t.score -- 输出字段:该学生对应学科的成绩
-- 外层查询的数据来源:子查询(别名t),子查询先完成各学科成绩的连续排名
FROM (
-- 子查询:为每个学科的学生成绩生成连续排名
SELECT
subject_id, -- 基础字段:学科ID(用于按学科分区)
stu_id, -- 基础字段:学生ID(关联具体学生)
score, -- 基础字段:成绩(排名的核心依据)
-- 核心函数:生成连续排名(同分并列、后续排名不跳跃)
DENSE_RANK() OVER (
PARTITION BY subject_id -- 分区规则:按学科ID分组,排名仅在同个学科内生效
ORDER BY score DESC -- 排序规则:同科内按成绩降序排列,高分排名靠前
) AS rank_num -- 排名结果别名,用于外层筛选第二名
FROM stu_score -- 数据来源:学生成绩表
WHERE score IS NOT NULL -- 过滤条件:排除无成绩(score为NULL)的记录,避免干扰排名
) t -- 子查询结果集别名t,供外层查询引用
WHERE t.rank_num = 2; -- 筛选条件:只保留排名为2的记录(即各学科的第二名)上面这个SQL,唯一需要再拆解下就是这个DENSE_RANK函数。
核心函数:DENSE_RANK(),MySQL最小版本8.0
这是「连续排名函数」,是区别于RANK()(跳跃排名)的关键,核心规则:
同分并列
相同分数的记录,排名编号完全一致;
排名连续
并列之后的排名不跳跃,直接接下一个数字(而非跳过并列的数量)。
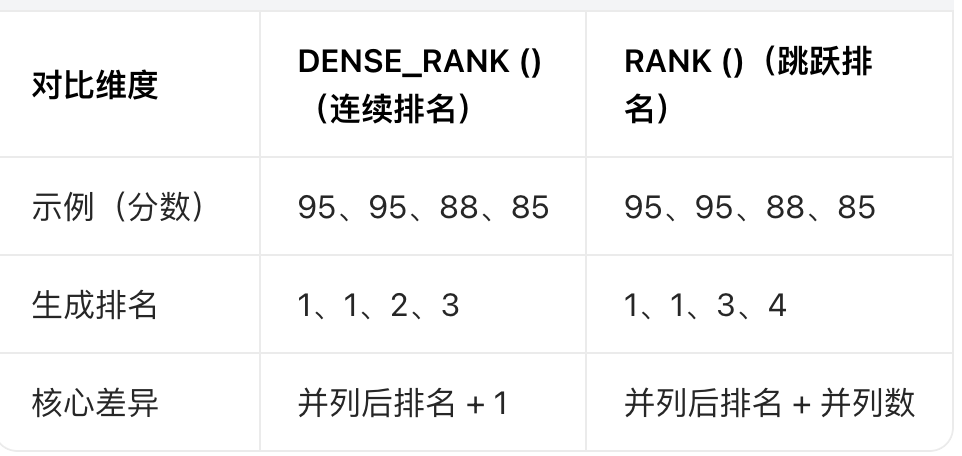
通俗理解:DENSE_RANK()只看 “分数梯队”—— 第一梯队(最高)排 1,第二梯队排 2,第三梯队排 3,不管每个梯队有多少人。
2. 窗口规则:OVER (PARTITION BY subject_id ORDER BY score DESC)
OVER()是窗口函数的 “作用域定义”,告诉数据库:DENSE_RANK()该在哪个范围、按什么规则生成排名。
(1)PARTITION BY subject_id:按学科 “分区 / 分组”
作用:把整张表的数据,按subject_id(学科 ID)拆分成多个独立的 “小数据集”(窗口),排名只在同一个学科的小数据集内进行,不同学科的排名互不干扰。
举例:
(2)ORDER BY score DESC:按成绩 “降序排序”
作用:在每个学科的小数据集内,按score(成绩)从高到低排序,这是生成排名的 “依据”—— 分数越高,排名编号越小(1 是最高分,2 是次高分)。
补充:如果写ASC(升序),则分数越低排名越靠前,和业务需求相反,所以必须用DESC。
REFERENCE:
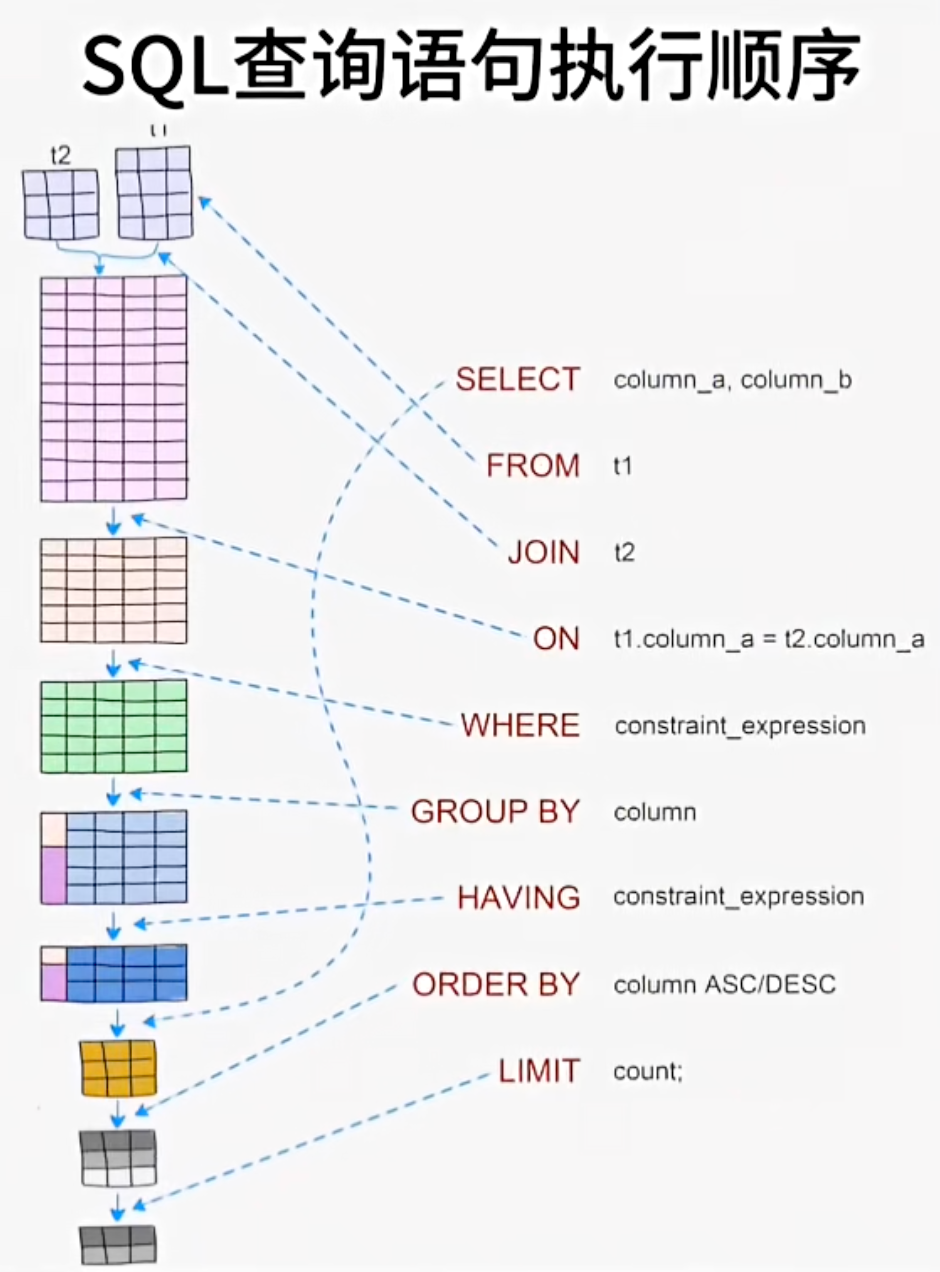
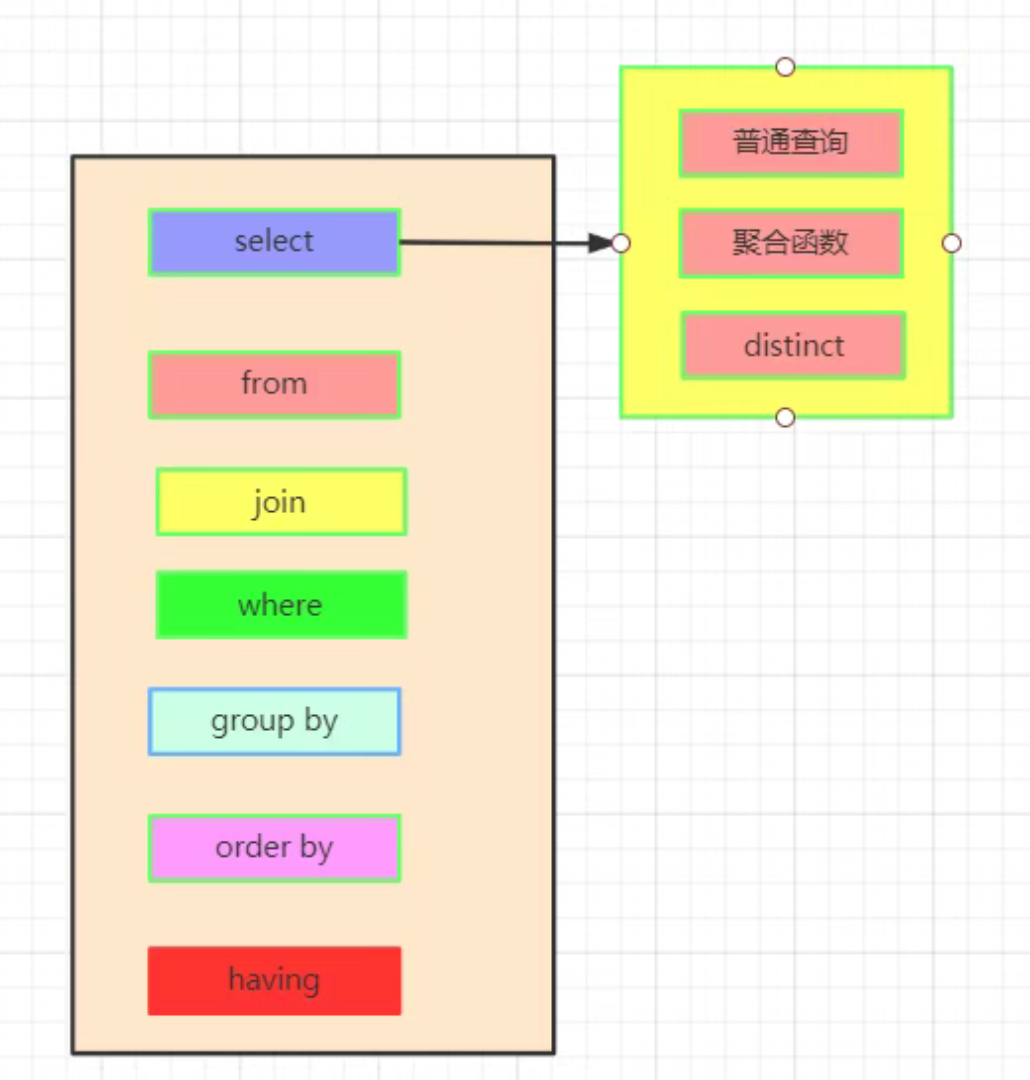
这是我们实际上SQL执行顺序: 1、确定数据源。先执行from,join来确定表之间的连接关系,得到初步的数据 2、过滤行。where对数据进行普通的初步的筛选 3、group by 分组 4、各组分别执行having中的普通筛选或者聚合函数筛选。 5、然后把再根据我们要的数据进行select,可以是普通字段查询也可以是获取聚合函数的查询结果,如果是集合函数,select的查询结果会新增一条字段 6、将查询结果去重distinct 7、最后合并各组的查询结果,按照order by的条件进行排序 8、执行limit限制返回的行数
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-08,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号