Transformer自注意力中,两个词向量的相关性为何能简单地用一个“标量”表示?

Transformer自注意力中,两个词向量的相关性为何能简单地用一个“标量”表示?

烟雨平生
发布于 2026-04-14 19:03:57
发布于 2026-04-14 19:03:57
先给答案:自注意力里的这个 “标量”,从来不是用来控制 “取哪一维” 的。
它只控制 “取多少”,不控制 “取什么”;它不是 “两个词整体有多像”,而是 “这个词对当前词有没有用”。
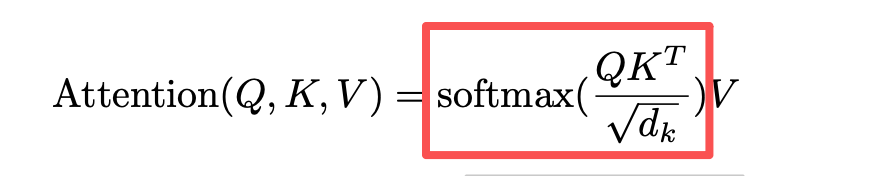
你看,图中框中的部分进行了归一化后得到一个标量。
虽然是标量,已经可以完成对V的“提纯”,即“这个词对当前词有没有用”、这个词对当前词是否相关。
两个词向量的相关性,为什么能用一个「标量」表示?
答案很简单:
不是因为 “语义相似度”,而是因为「当前这个Q,想从所有K里抓哪一类信息」。
你理解的 “相关性 = 语义近不近”,是人类直觉,不是注意力公式的真实含义。
真正的含义是:
- Q 是查询向量:代表 “我现在想要什么信息”
- K 是键向量:代表 “我这里有什么信息”
- Q・Kᵀ 点积并softmax算出来的标量 = 匹配分数= 「这个K里有没有Q想要的东西」
- V 不是原始词向量,是模型 “专门整理好、准备被别人拿走的信息”。
它不是 “两个词整体有多像”,而是 “这个词对当前词有没有用”。
标量再粗糙也没关系,因为V早就把 “不需要的信息” 删掉了。你加权加过来的,本来就只有你想要的那部分。
形容词和名词相关,但我不想要形容词的词性,只想拿它的 “修饰语义”,但注意力是把整个 V 向量加权加过来,这不就乱了吗?
你的直觉完全正确:单头注意力确实做不到 “只取一部分信息”。标量权重只能控制加多少,不能控制加哪一维。
1、不是词向量本身在交互,是 Q/K/V 三个投影后的向量在交互。
每个词进来,会经过三个线性层变成Q、K、V。
也就是说:V 不是原始词向量,是模型 “专门整理好、准备被别人拿走的信息”。
模型训练时会自动学会:
- 让名词的 V 里不含词性干扰
- 让形容词的 V 里只留修饰语义
所以你担心的 “词性污染”,在 V 里就已经被过滤掉了。
2、多头注意力 = 同时开很多个 “专用通道”
这是最关键的一点。
所以 Transformer 不用单个标量,而是用 8/12/16 个头。
每个头负责一种关系:
- 头 1:代词 → 先行词
- 头 2:形容词 → 名词(只取修饰)
- 头 3:动词 → 宾语
- 头 4:句法依赖
……
每个头只专注一小类语义关系。
单头粗糙,多头合起来就精细了。
你担心的 “只想要部分信息”,
不是靠一个权重,而是靠多头分工实现的。
3、输出还会再过一次线性层:信息重组
注意力加权求和之后,并不是直接用。
它会经过一个线性层 + 残差连接。
这一步的作用:
把多头拿到的信息,重新混合、过滤、压缩成有用的表示。
模型完全可以学会:
- 哪些维度是语义
- 哪些是词性
- 哪些是句法
- 哪些是上下文
然后只保留有用维度,压制干扰维度。
回到这个最本质的哲学问题:
难道模型可以找到人类无法理解的空间来减小偏差吗?是不是不能用比喻理解?
Transformer的自注意力不是在“理解句子”,不是在理解语义,是在做信息路由(information routing),它只做:谁该从谁那里拿多少信息。
人类用 “相关性、指代、修饰” 这些比喻去解释,
只是为了方便理解,不是模型真的这么思考。
模型真正做的是:高维空间里的大规模线性信息流动 + 非线性过滤。
它不需要 “理解词性”,它只需要学会:
词性信息在某些维度
语义信息在另一些维度
注意力只路由语义,不路由词性
你觉得“标量太粗糙、会带无关信息”,这个直觉完全正确。
Transformer 不是靠单个标量解决问题,而是靠:
- Q/K/V 投影过滤无用信息;
- 多头注意力分工处理不同关系;
- 输出层再做维度筛选与重组;
- 海量数据中学到哪些维度该留、哪些该压。
定义1. 标量(Scalar)
标量是单一、无维度、无结构的基础数据值,是数据的最小独立单元,仅包含「值本身」,不包含任何关联关系或维度信息。
核心特征:单值性、无维度、原子性(不可再拆分为更小的有意义数据单元)。
2. Embedding(嵌入向量)
Embedding 是将非结构化 / 结构化数据映射到低维连续数值空间的多维向量,本质是一组有序的浮点数数组,核心作用是用数值向量表达数据的「语义、特征或关联关系」。
核心特征:多维性、语义性、连续性(向量中每个维度的数值都有特定的特征含义)。
https://www.zhihu.com/question/3043464144/answer/2008281637125890410
Q与K^T点积——量化token间的关联相似度,这就是你疑惑的 “乘一乘”,它的本质不是简单的数值相乘,而是向量相似度的计算。从向量几何的角度理解点积:向量方向越接近,点积值越大,代表两个向量的相似度越高。 具体到注意力中:对每一个Query(当前元素的查询),和所有Key做点积;点积结果越大,说明当前元素和该元素的关联越强、越相关; 最终得到一个相似度矩阵,行是Query(当前元素),列是Key(所有元素),矩阵中的每一个值,代表 “两个元素的关联程度”。 总结:这里的乘法,是用数学方式,把“元素间的相关性”转化为可计算的数值,是注意力机制中“发现关联” 的核心手段,而非注意力本身。
不是点积运算 “创造” 了语义相似性,而是语义嵌入模型 “预设” 了语义相似性对应的向量方向特征,点积只是把这个预设的特征提取出来而已。 为什么点积可以把这个预设的特征提取出来?这是一个数学原理,如果两个高维向量越接近,它们的交乘数字就越可能更大,它们彼此之间对对方投入的「注意力」也就越大,在Attention这个地方就可以理解为两个Token越相关,语义越相似。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-11,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号