开源大模型在卷什么?原来都在干同一件事!?

开源大模型在卷什么?原来都在干同一件事!?

烟雨平生
发布于 2026-04-14 19:11:10
发布于 2026-04-14 19:11:10
最近看到一张图,上面列了多个开源大模型的架构对比。
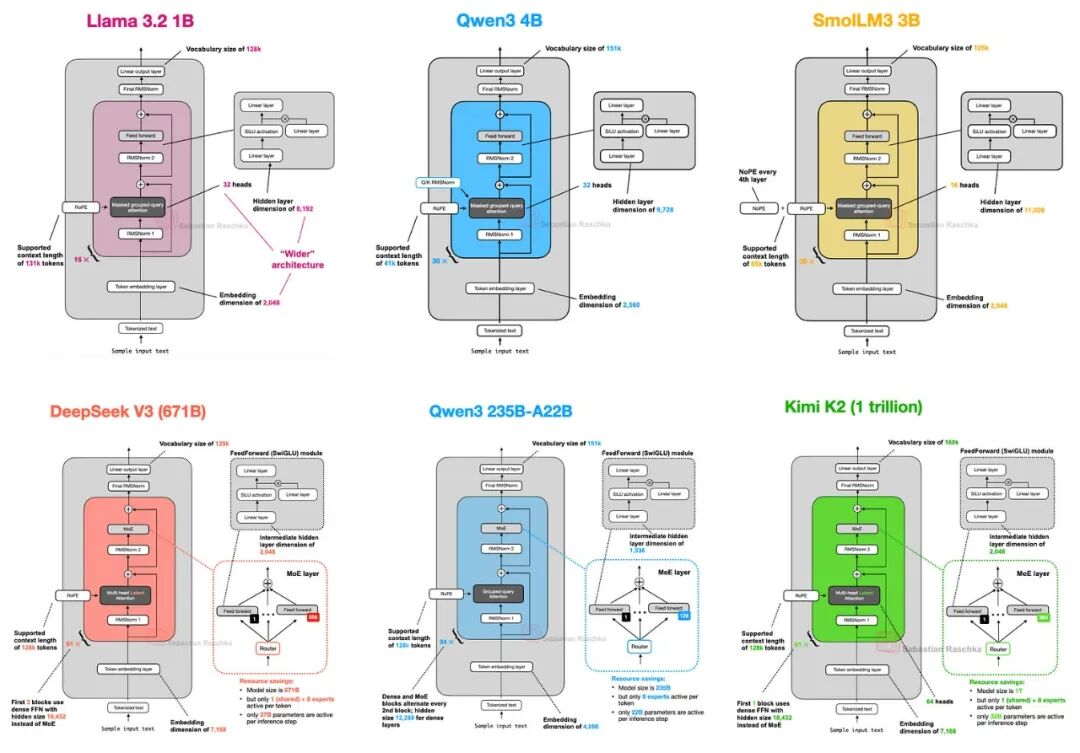
LLaMA、Qwen、Mistral、DeepSeek、Baichuan……名字一大堆,眼花缭乱。
你是不是也有这种感觉:知道这些模型都很厉害,但不知道它们到底在干什么?
今天我来帮你梳理一下。
40个开源大模型,几乎都在做同一件事:
想办法让注意力机制便宜。
什么是注意力机制?
“注意力机制”,简单来说就是AI判断“哪个字和当前字最相关”的过程,本质是一种数据驱动、自适应、全局的动态信息加权聚合方法。它的核心目标,是让模型在处理序列数据时,自动学习输入中不同元素之间的关联程度,给关键信息分配更高的权重,无关信息分配更低的权重,最终通过加权求和,聚焦并聚合对当前任务有用的信息。
为什么我还是无法理解Transformer?Attention的本质是什么?为什么向量之间乘一乘就能得到Token之间的相似度了?
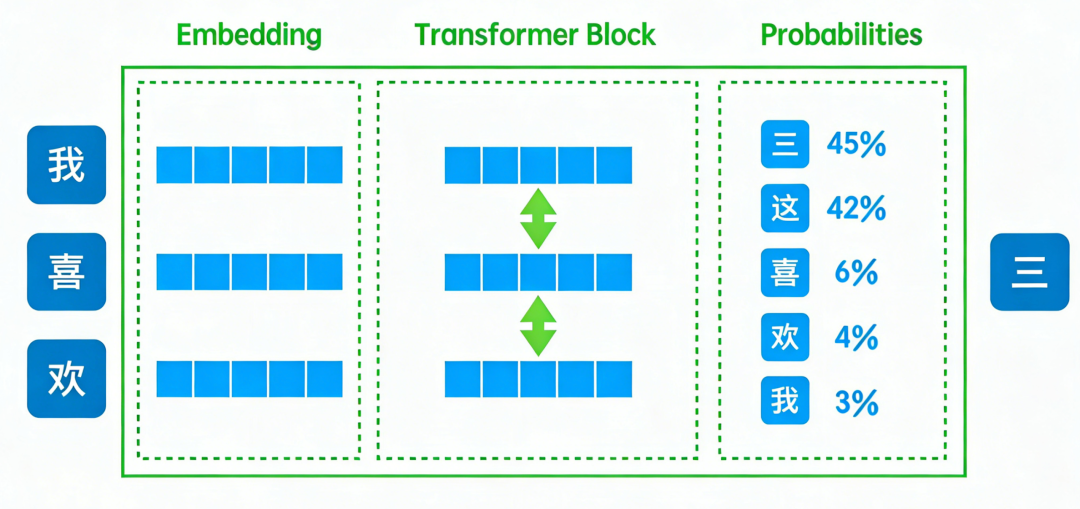
为什么要想办法让注意力机制便宜?
因为Transformer的注意力机制太贵了——计算复杂度是O(n²),n是序列长度。
当序列长度超过4096时,计算量会爆炸式增长。
所以这些模型的核心目标,就是:降低注意力机制的计算成本。
怎么做到的?三条路。
路径1:修改注意力机制
1. 稀疏注意力
代表模型: Sparse Transformer、Longformer、BigBird
核心思想:不是所有token都需要attend所有token。
举个例子,你在读这篇文章时,不会逐字逐字地回顾所有内容,而是关注附近的词。
稀疏注意力就是模拟这种"局部注意力"——只关注附近的token,或者全局的几个关键token。
结果:计算复杂度从O(n²)降到O(n√n),甚至O(n)。
代价:模型精度会下降,需要更长的训练时间。
2. 滑动窗口注意力(Sliding Window Attention)
代表模型:Mistral
系列核心思想:只关注当前 token 附近固定窗口内的内容,超出窗口不计算。兼顾效果与速度,是当前小模型标配。
3. GQA/MQA 分组查询注意力
代表模型:LLaMA 3、Qwen、Mistral 8x7B
这是最被低估但最实用的优化:
- MQA(Multi-Query Attention,多查询注意力):所有头共享一组 KV,速度最快,但效果下降明显
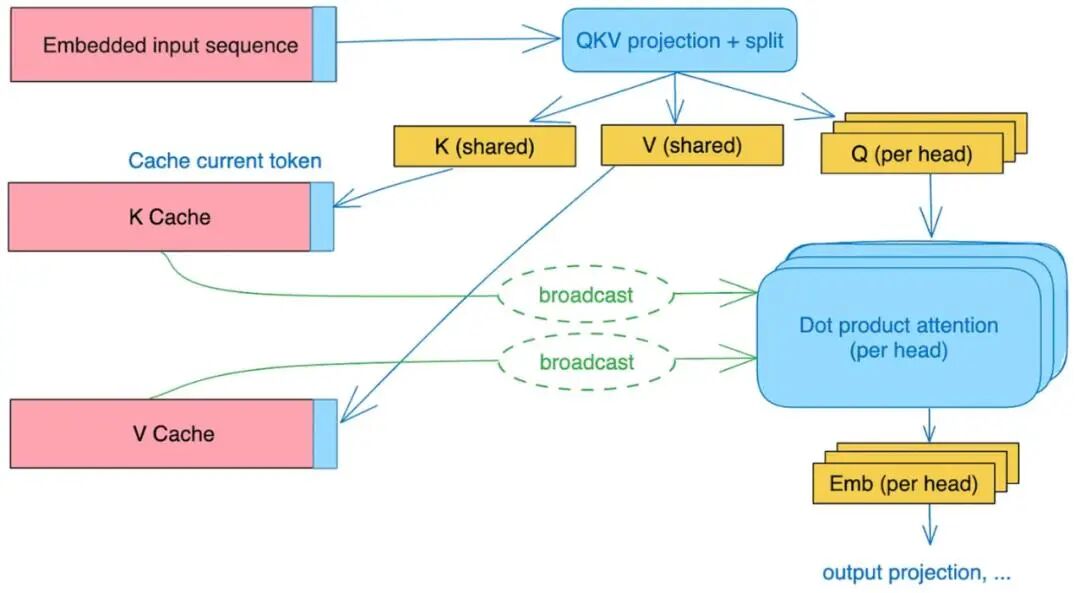
previewImag
- GQA(Grouped-Query Attention,分组查询注意力):分成若干组共享 KV,效果接近原生 MHA,速度接近 MQA现在新模型几乎默认 GQA,平衡效果与推理速度。
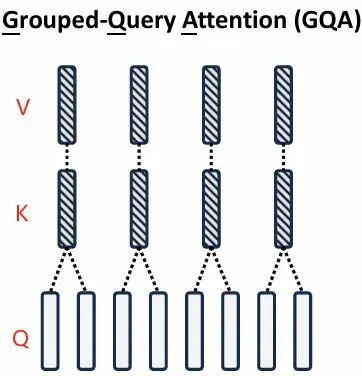
previewImag
路径2:优化内存和计算
1. FlashAttention 系列
代表模型: FlashAttention、FlashAttention-2、FlashAttention-3
核心思想:减少显存访问次数,因为显存访问比计算慢。
举个例子,你从硬盘读数据,比CPU计算慢得多。Flash Attention就是优化这个——减少显存访问次数。
结果:计算速度快2-4倍,显存占用减少一半。
代价:需要特殊的GPU硬件支持。
2. KV Cache 与 PagedAttention
Transformer 生成时,前面 token 的 KV 会反复计算。KV Cache 就是把已计算的 Key、Value 缓存起来,只增量计算新 token。
在此基础上:
PagedAttention(vLLM 核心):把 KV 分成 “页”,像操作系统内存管理一样高效利用显存
Continuous Batching:动态批处理 + KV 复用,大幅提升并发
KV 量化:INT8/INT4 存储 KV,显存再砍半
路径3:混合专家模型(MoE)
代表模型: Switch Transformer、GLaM、Mixtral
核心思想:不是所有参数都用,每次推理只激活一部分参数。
举个例子,你有100个专家,每次只选4个专家来处理。这样计算量就减少了25倍。
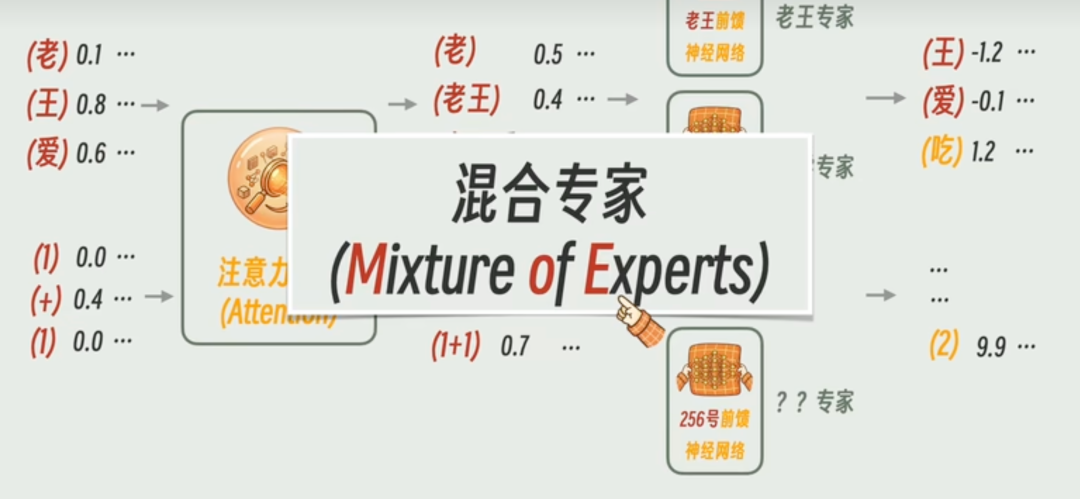
结果:模型参数量很大(比如Mixtral 8x7B有467B参数),但推理成本和7B模型差不多。
代价:训练更难,显存占用更大。
路径 4:彻底抛弃注意力:线性架构(Mamba / RetNet)
近年最颠覆性路线:
RetNet:用循环结构替代注意力,实现 O (n) 复杂度,并行训练 + 线性推理
Mamba/SSM 状态空间模型:彻底去掉显式注意力,长文本性能碾压 Transformer代表:Mamba、Jamba、Qwen-Mamba
特点:
天然线性复杂度,越长文本越快
不需要复杂注意力优化
正在成为下一代架构主流
路径 5:上下文长度扩展(不用重训扩到 128K)
想处理长文档,但不想训大模型?靠这些技巧:
- NTK-RoPE(Neural Tangent Kernel - Rotary Position Embedding,神经切核旋转位置编码)
- YaRN(Yet another RoPE Extrapolation method,新型 RoPE 外推方法)
- ALiBi(Attention with Linear Biases,带线性偏置的注意力机制)
不用重新预训练,直接把 4K 上下文扩展到 32K/64K/128K,是长文本应用的低成本方案。
路径 6:模型量化
量化让小显卡也能跑大模型,是落地最关键技术通过降低数值精度,大幅减少显存占用:
- INT8/INT4/NF4
- GPTQ(Generalized Post-Training Quantization,广义后训练量化)
- AWQ(Activation-Aware Weight Quantization,激活感知权重量化)
- GGUF(GGML Universal Format,GGML 通用格式)
- EXL2
效果:
- 7B 模型 4G 显存可跑
- 70B 模型单卡可推理
- 速度提升,成本暴跌
选择模型时,看这三个指标
你不需要知道所有模型的技术细节,但你需要知道这三个指标:
1. 参数量
参数量越大,理论上模型越强,但推理成本越高。
- 小模型(<10B):适合本地部署,资源消耗低。
- 中模型(10B-70B):适合中小企业,性能和成本平衡。
- 大模型(>70B):适合大公司,性能最强,但成本很高。
2. 上下文长度
上下文长度越长,能处理的内容越多,但推理成本越高。
- 短上下文(<4K):适合简单问答。
- 中上下文(4K-32K):适合对话、文档摘要。
- 长上下文(>32K):适合代码分析、长文本理解。
3. 训练数据质量
训练数据质量越高,模型效果越好,但不容易量化。
你可以通过以下方式判断:
- 看模型的开源社区的活跃度(star数、issue数)。
- 看模型的技术报告和论文质量。
- 看模型在排行榜上的表现。
常见开源大模型速查
模型 | 参数量 | 上下文长度 | 核心特点 |
|---|---|---|---|
LLaMA 2 | 7B/13B/34B/70B | 4K | Meta开源,质量高 |
LLaMA 3 | 8B/70B | 8K | 最新的Meta模型 |
Qwen | 7B/14B/72B | 32K | 阿里开源,中文好 |
Mistral | 7B | 32K | 小模型强,开源友好 |
DeepSeek | 7B/67B | 4K | 深度求索,代码强 |
Baichuan | 7B/13B | 4K | 百川智能,中文好 |
Mixtral | 8x7B | 32K | MoE模型,性价比高 |
怎么选模型?
看你的业务场景:
1. 聊天机器人
- 推荐:LLaMA 2、Qwen、Mistral
- 原因:质量高,开源友好,支持长上下文。
2. 代码生成
- 推荐:DeepSeek、CodeLLaMA、StarCoder
- 原因:代码训练数据多,生成质量高。
3. 文档摘要
- 推荐:Qwen、Mistral、Mixtral
- 原因:支持长上下文,摘要质量高。
4. 本地部署
- 推荐:LLaMA 2 7B、Mistral 7B、Qwen 7B
- 原因:小模型,资源消耗低。
模型训练的技术趋势
除了注意力机制,还有几个技术趋势值得关注:
1. 从单一模态到多模态
以前的模型只处理文本,现在的模型可以处理图像、音频、视频。
代表模型:CLIP、GPT-4V、LLaVA。
2. 从单一架构到混合架构
以前的模型只用Transformer,现在的模型混合了CNN、RNN、Transformer。
代表模型:Perceiver IO、ViViT。
3. 从预训练到微调
以前的模型直接用预训练模型,现在的模型针对特定任务微调。
代表模型:ChatGLM、Baichuan-Chat、Qwen-Chat。
4. 从密集模型到 MoE 稀疏模型
大参数低成本成为主流,推理成本不再随参数量线性增长。
给你的建议
如果你是AI工程师:
- 不要追新,要追实用。 新模型不一定适合你的场景,选最合适的。
- 关注GQA、KV Cache、量化、vLLM,这四个是落地核心。
- 关注开源社区。 模型的质量不仅仅看论文,还要看开源社区的活跃度。
- 自己测试。 别人的评测不一定适合你的场景,自己测试最可靠。
如果你是产品经理:
- 理解模型的能力边界。 模型不是万能的,知道它擅长什么,不擅长什么。
- 关注成本。 大模型很贵,小模型不一定差,选性价比高的。
- 关注延迟。 聊天机器人需要实时响应,长文本生成可以延迟稍高。
总结
40个开源大模型,几乎都在做同一件事:让注意力机制便宜。
完整优化路线一共 6 条:
- 稀疏 / 窗口 / GQA 注意力优化
- FlashAttention + KV Cache/PagedAttention
- MoE 混合专家
- Mamba/RetNet 线性架构
- NTK/YaRN 上下文扩展
- INT4/INT8 模型量化
选择模型时,看三个指标:参数量、上下文长度、训练数据质量。
“没有最好的模型,只有最适合的模型。”
MoE为什么这么快 —— 从小学数学到MoE 大模型进化史
https://www.bilibili.com/video/BV1CgZABxEcy/
为什么我还是无法理解Transformer?Attention的本质是什么?为什么向量之间乘一乘就能得到Token之间的相似度了?
互动时间
你平时用哪些开源大模型?有没有踩过坑?
评论区聊聊,大家一起避坑。
觉得有用的话,点个赞,转发给需要的小伙伴。
关注不迷路,每天分享AI底层原理、工程实践、bug排查。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-26,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号