Transformer到底是什么?为什么我还是无法理解Transformer?

Transformer到底是什么?为什么我还是无法理解Transformer?

烟雨平生
发布于 2026-04-14 19:12:43
发布于 2026-04-14 19:12:43
究其原因,是但凡讲到Transformer,铺天盖地的资料上来就直奔自注意力机制(Self-Attention)的Q、K、V细节,只钻枝叶、不谈全局,只见树林,不见森林。
现在我就来尝试使用一个新的视角来解读下Transformer,解决学了好久还是一团浆糊的问题!
Transformer到底是什么?
Transformer是一种深度神经网络架构,2017年由Google提出,核心是基于自注意力机制(Self-Attention)构建的序列建模架构,摒弃传统RNN与CNN,依托多头注意力(Multi-Head Attention)和位置编码(Positional Encoding)实现计算并行化,还能高效捕捉序列中的长距离依赖关系。这一创新的神经网络结构,有效解决了传统序列模型在计算与长距离依赖捕捉上的效率难题,大幅提升了前向传播与特征建模的效率,其实用性已被众多企业和研究机构验证,也由此掀起人工智能发展的全新浪潮。如今,Transformer 架构更是成为大模型时代无可争议的核心基石。
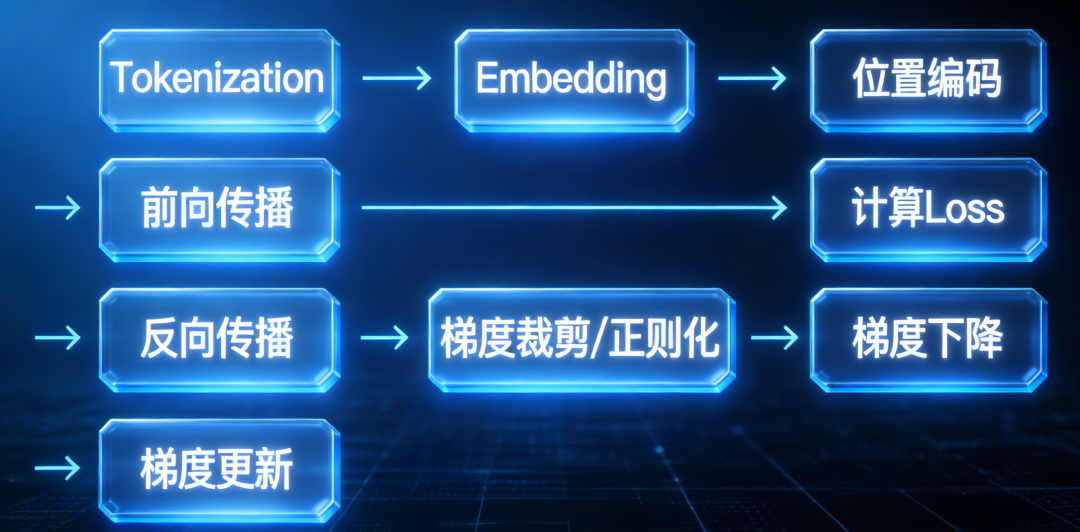
Transformer神经网络只是优化了模型训练和模型推理的一个环节,即前向传播部分。
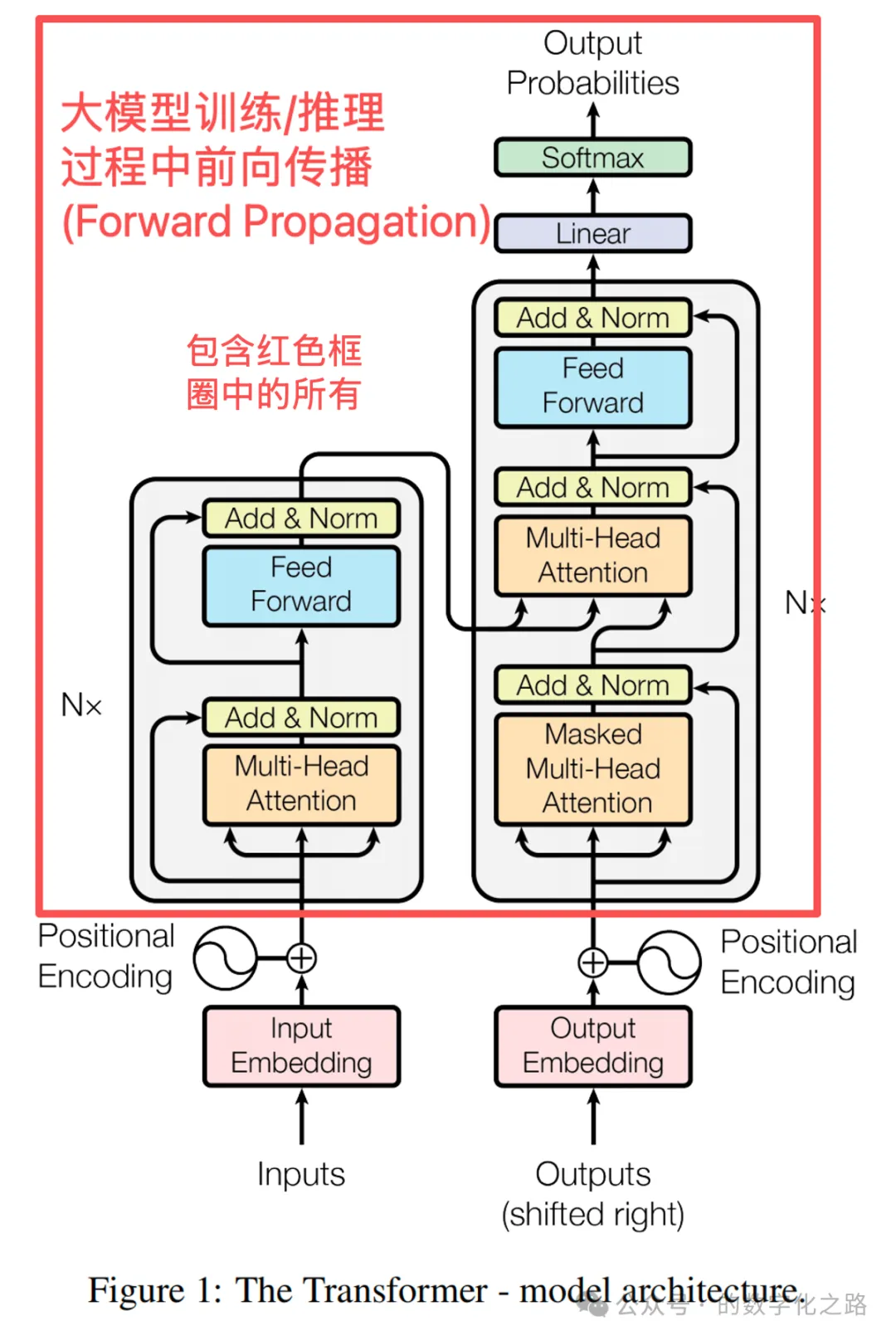
图片
完整的模型训练流程是这样的:
Transformer=位置编码+自注意力机制(Self-Attention)+前馈网络
结构分为两大块:
- Encoder(编码器):理解输入,擅长理解类任务(BERT就是纯 Encoder)
- Decoder(解码器):生成输出,擅长生成类任务(GPT就是纯 Decoder)
整体结构
标准 Transformer 是:
- N 层 Encoder
- N 层 Decoder
中间通过 Encoder-Decoder Attention 连接
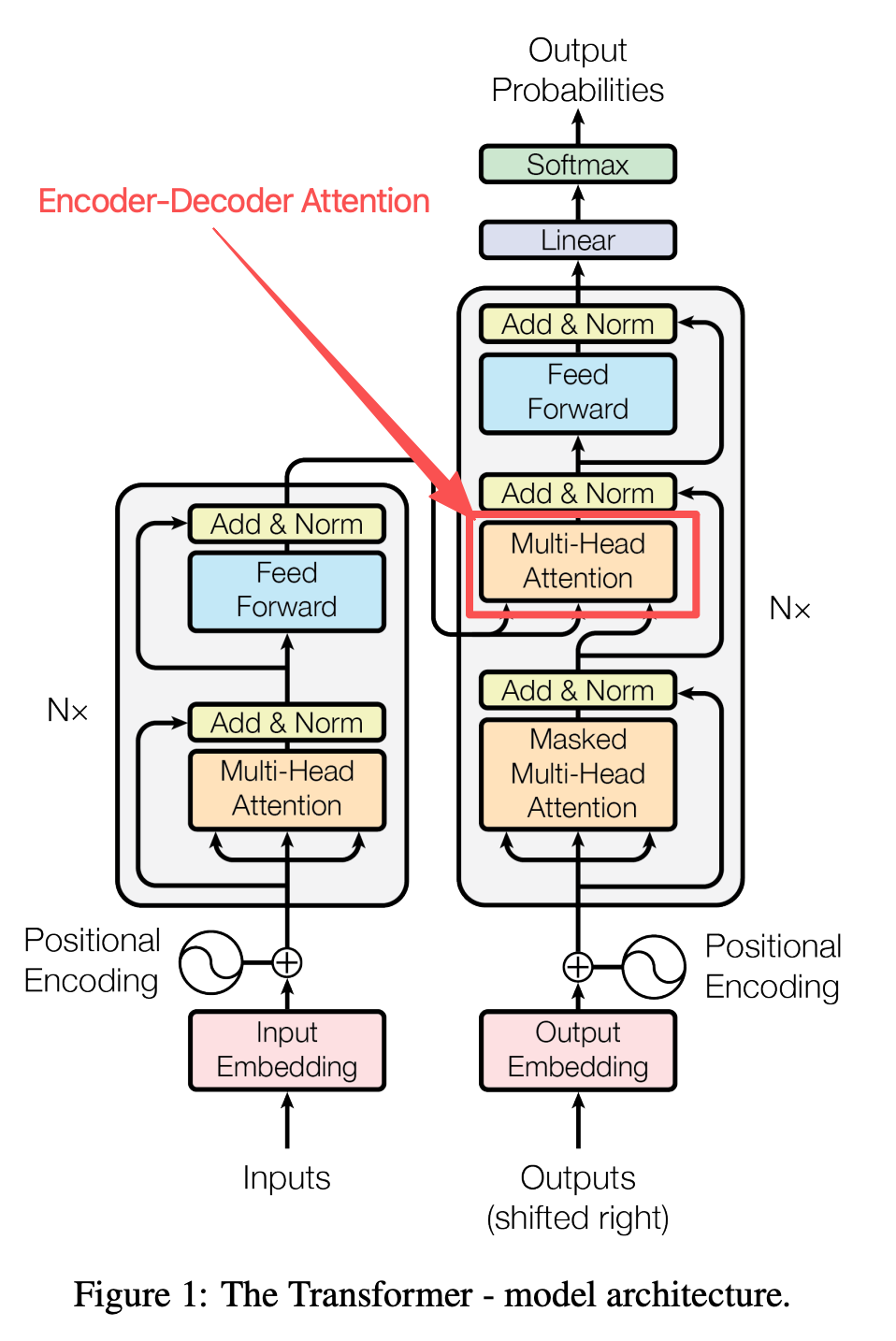
关键模块详解
1. 自注意力机制Self-Attention
Transformer中的注意力机制,本质是一种数据驱动、自适应、全局的动态信息加权聚合方法,本质是通过动态权重分配实现信息选择性聚焦,其核心在于模拟人类认知系统对复杂输入的差异化处理能力。这种机制通过可学习的方式赋予输入特征不同的重要性权重,使模型能够自主决定 “看哪里” 和 “如何看”。
一句话:注意力机制让每个词都能看到句子里所有词,并算出它们的关联程度。
步骤:
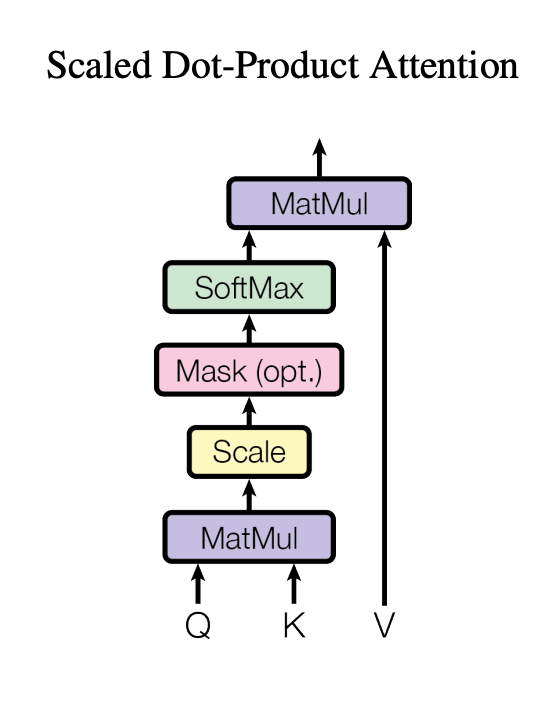
1、对每个token生成三个向量:
- Q(Query 查询)
- K(Key 键)
- V(Value 值)
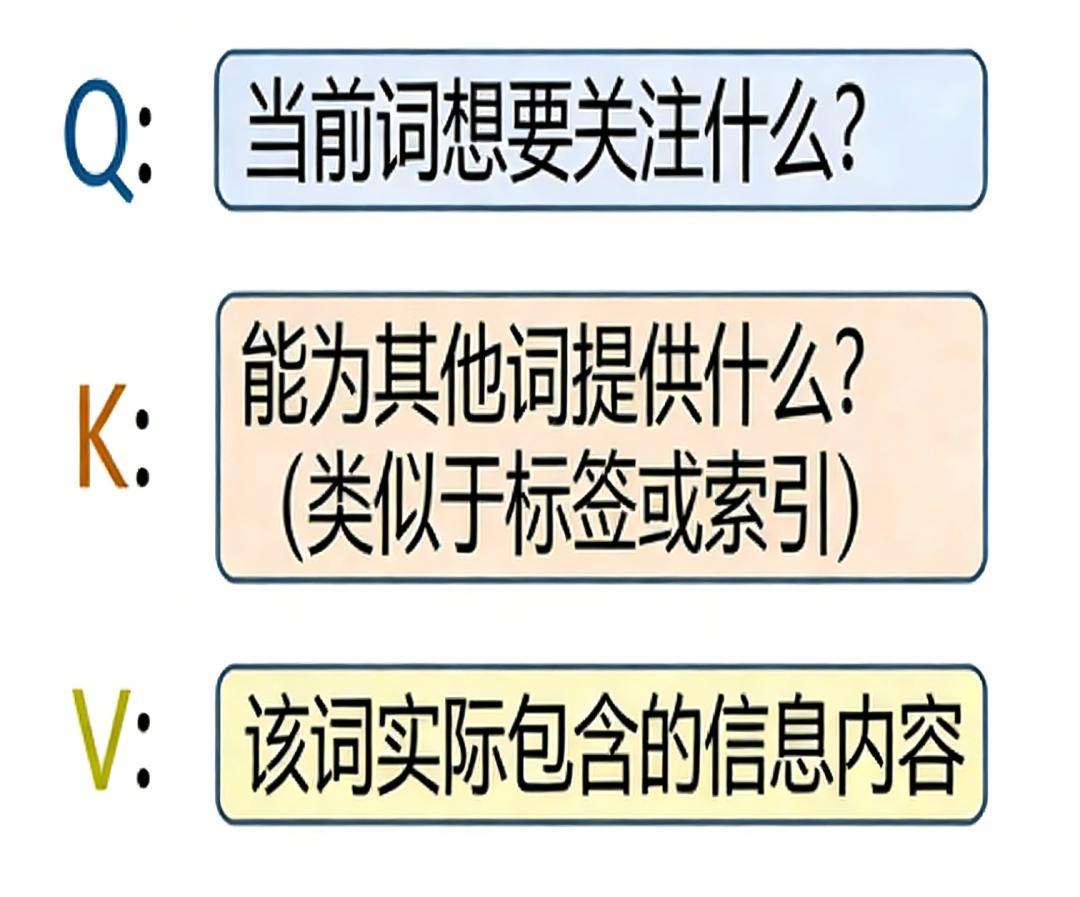
2、计算Q・K^T,得到注意力分数
3、除以根号 d_k 缩放,避免数值爆炸
4、Softmax归一化,得到权重
5、权重×V来提取特征,得到最终输出
公式:
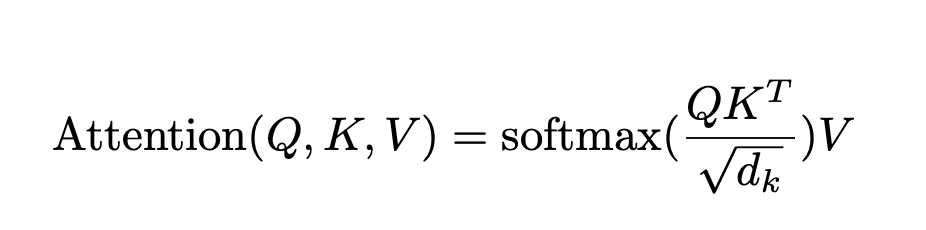
2.多头注意力Multi-Head Attention
把Q/K/V分成多组,并行计算多个注意力:
- 每个头关注不同类型的关联
- 最后拼接起来
让模型能同时捕捉:语法、语义、指代、长距离依赖等。
3. 位置编码 Positional Encoding
Transformer 没有时序结构,不知道词的顺序,所以手动加入位置信息:
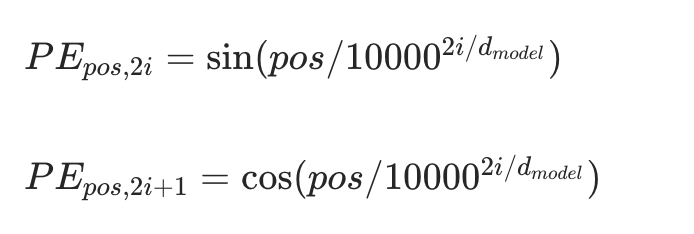
4. 残差连接+层归一化
每个子层外面都套:
LayerNorm(x + SubLayer(x))
作用:
- 防止梯度消失
- 让深层网络能训练
四、Encoder 内部结构
每层 Encoder 包含:
- 多头自注意力(可以看到全部输入)
- 残差 + 层归一化
- 前馈网络 FFN
- 残差 + 层归一化
五、Decoder 内部结构
每层 Decoder 包含:
- 掩码多头自注意力(Masked) 只能看到当前及之前的 token,防止偷看未来
- 残差 + 层归一化
- Encoder-Decoder注意力 用Encoder 的信息做翻译 / 生成
- 残差 + 层归一化
- 前馈网络FFN
- 残差 + 层归一化
为什么Transformer 这么强并行计算
- 并行计算 RNN 必须一个词一个词算,Transformer 可以一次算完长距离依赖强
- 长距离依赖 强注意力直接连接任意两个 token,不受距离影响
- 表达能力强 多头注意力能建模复杂语义关系
- 易扩展到超大规模 GPT、LLaMA、BERT 全是它的变体
常见变种
- BERT:只使用 Encoder,双向注意力,擅长理解
- GPT:Decoder-only,单向掩码注意力,擅长生成
- T5、BART:完整 Encoder-Decoder,擅长翻译、摘要
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-29,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号