手把手带你入门机器学习!从零训练一个可以在CPU上跑的3.37M中文GPT小模型,有详细步骤,有github源码,请各位老师检查作业

手把手带你入门机器学习!从零训练一个可以在CPU上跑的3.37M中文GPT小模型,有详细步骤,有github源码,请各位老师检查作业

烟雨平生
发布于 2026-04-14 19:13:36
发布于 2026-04-14 19:13:36
写给在知乎上问"非机器学习背景,想入门机器学习,该怎么做?"的你。 我的观点:因为看到,所以相信。 先训练一个模型,看到它跑通了、能回答问题了,然后再去理解背后的原理。就像神农尝百草——神农找到能吃的食物,靠的是先咬一口尝尝,而不是先搞清楚每种植物的每个部位包含了哪些化学物质,再研究这些化学物质对人体是否有益,最后才决定要不要吃一口。 本手册带你一步步跑通一个3.37M中文 GPT小模型 的完整流程:从pull代码到训练模型,从验收测试到生产部署。 全程只需一台普通笔记本电脑,不需要 GPU,大约 20 分钟即可完成训练。

这个项目能做什么
这个项目能让你在自己的电脑上,从零训练一个能回答中文问题的 GPT 小模型。
训练完成后,你可以向模型提问,它会生成中文回答。比如:
你问:什么是注意力机制?
模型回答:注意力通过分配权重让模型重点参考关键位置,提升对序列关系的理解。你问:解释蒸馏水与纯水区别?
模型回答:蒸馏水是通过蒸馏获得的水,去除了大部分杂质;
这不是调用人家的 API,不是下载人家的预训练模型——而是你自己从头训练出来的模型。
用了什么技术
不用被下面的名词吓到,先混个眼熟就好。你只需要知道:这些技术都是为了让一个"小模型"也能给出"可用的回答"。
技术 | 一句话说明 |
|---|---|
GPT(Decoder-only Transformer) | 模型的基本架构,也是 ChatGPT 用的架构 |
RMSNorm | 归一化方法,让训练更稳定 |
RoPE 位置编码 | 告诉模型"每个词在第几个位置" |
SiLU 激活函数 | 让模型学到非线性关系 |
权重共享 | 输入层和输出层共用一套参数,减少参数量 |
ByteLevel BPE 分词器 | 把中文句子切成小片段(token),让模型能"读"中文 |
AdamW 优化器 | 更新模型参数的方法 |
动态量化(INT8) | 把模型"压缩",让推理更快 |
模型规模:3.37M 参数(3.37 百万),4 层、4 个注意力头、256 维嵌入、128 最大序列长度。作为对比,GPT-3 有 1750 亿参数——我们的小模型只有它的五万分之一,但足以完成教学演示。
训练模型的主要流程
clone代码 → 训练分词器Tokenizer → 训练模型 → 验收测试 → 生产部署 → 生产验证具体来说:
- 克隆代码:把训练项目拉到本地
- 训练分词器Tokenizer:分词器负责把中文文本切成模型能理解的数字序列,训练和推理都依赖它
- 训练模型:让模型从训练数据中学习"问题→回答"的模式
- 验收测试:用测试集验证模型是否学到了有用的知识
- 生产部署:把模型导出为适合部署的格式
- 生产验证:验证部署后的效果和性能
下面一步步来。
第一步:克隆项目
训练模型需要代码和数据,所以第一步是把项目拉取到本地。
# 克隆项目
git clone https://github.com/helloworldtang/GPT_teacher-3.37M-cn.git
cd GPT_teacher-3.37M-cn
安装依赖
项目使用 Python 3.10 ~ 3.12(推荐 3.11.10)。推荐使用 uv 安装依赖,速度更快:
# 安装 uv(如果还没有的话)
curl -LsSf https://astral.sh/uv/install.sh | sh
# 创建虚拟环境并安装依赖
uv venv
source .venv/bin/activate # macOS/Linux
# .venv\Scripts\activate # Windows
uv pip install -e .如果不想用 uv,也可以用 pip:
python -m pip install -r requirements.txt安装完成后,验证一下:
python -c "import torch; print(torch.__version__)"
能输出版本号(如 2.11.0)就说明依赖安装成功。
第二步:训练分词器Tokenizer
什么是分词器,为什么需要它
模型不能直接读中文文字,它只能处理数字。分词器的作用就是把中文文本转换成数字序列。分词器(Tokenizer)是大模型与人类语言之间的“翻译官”,负责将连续的文本拆解并转化为模型能够理解的数字序列。
举个例子:
原文: "什么是注意力机制?"
分词器:→ [53, 128, 67, 201, 89, 342, 156, 78] (一串数字)同时,分词器也能把数字"翻译"回中文:
数字: [53, 128, 67, 201, 89, 342, 156, 78]
分词器:→ "什么是注意力机制?"分词器是训练和推理的基础设施,必须先准备好。
训练分词器
python -m src.build_tokenizer执行后,程序会读取 data/train.jsonl 中的训练数据,学习中文文本的切分规律,生成词表大小为 4096 的分词器,保存到 tokenizer/tokenizer.json。
没有报错就说明成功了。 你可以确认一下文件是否存在:
ls -la tokenizer/tokenizer.json分词器的一些细节(可选了解)
- 使用的是 ByteLevel BPE(字节级字节对编码)算法,这是目前中文 NLP 中常用的分词方案
- 词表大小 4096,意味着分词器认识 4096 种不同的"片段"
- 包含 4 个特殊标记:
<bos>(开头)、<eos>(结尾)、<pad>(填充)、<unk>(未知)
第三步:训练模型
训练命令
python -m src.train就这么一行命令。程序会自动读取配置(config.yaml)、加载训练数据、开始训练。
训练过程中你会看到什么
训练开始后,终端会持续打印日志:
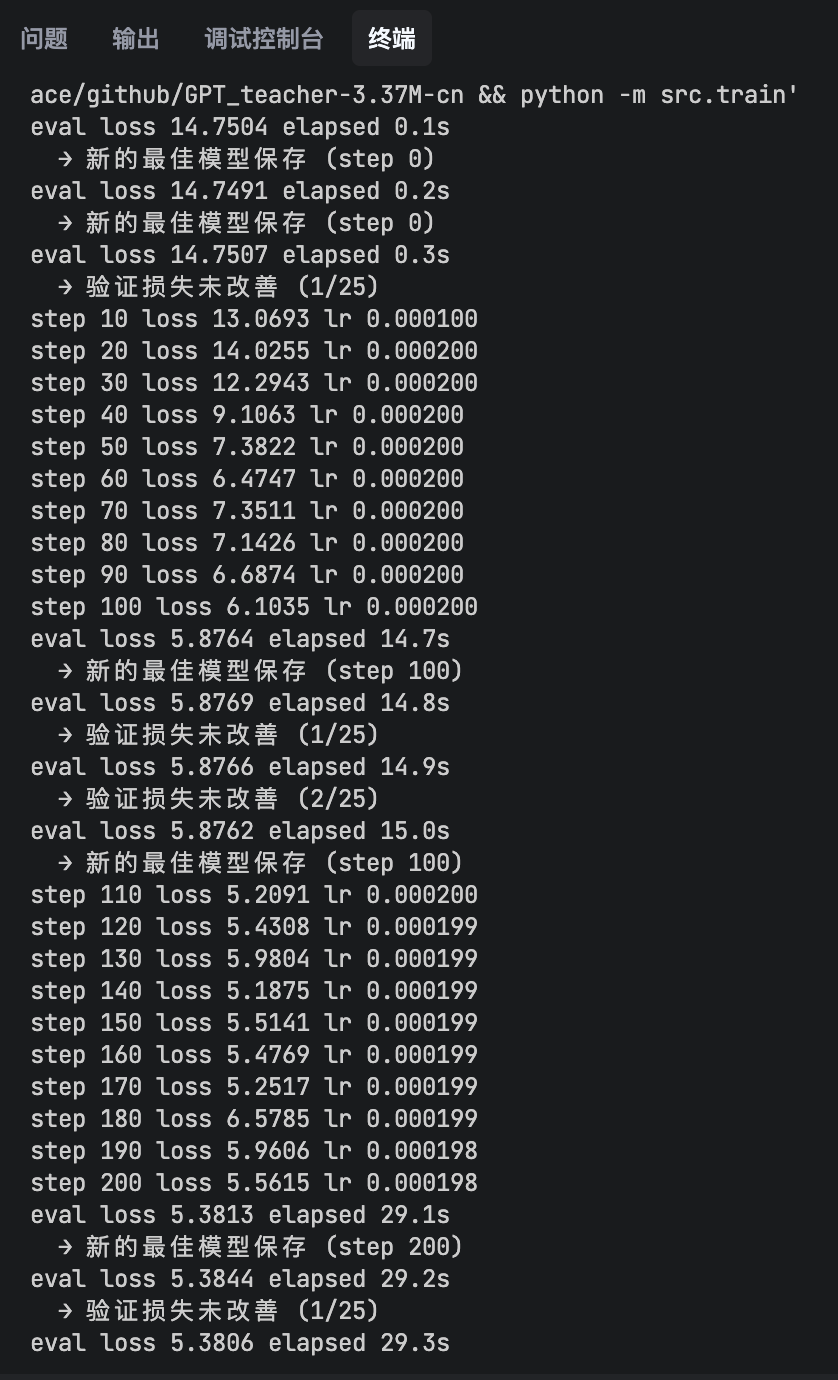
重点关注两个指标:
指标 | 含义 | 期望趋势 |
|---|---|---|
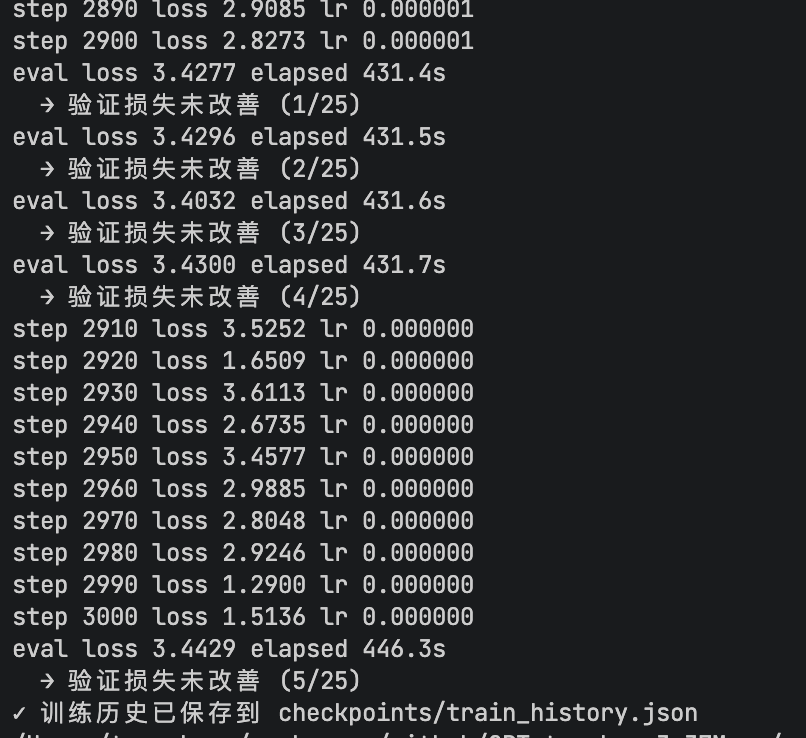
loss(训练损失) | 模型预测与正确答案的差距 | 越来越小 |
eval loss(验证损失) | 模型在未见数据上的表现 | 越来越小 |
正常情况下,loss 会从 78 逐步下降到 34 左右。 如果 loss 在下降,说明模型在学习。
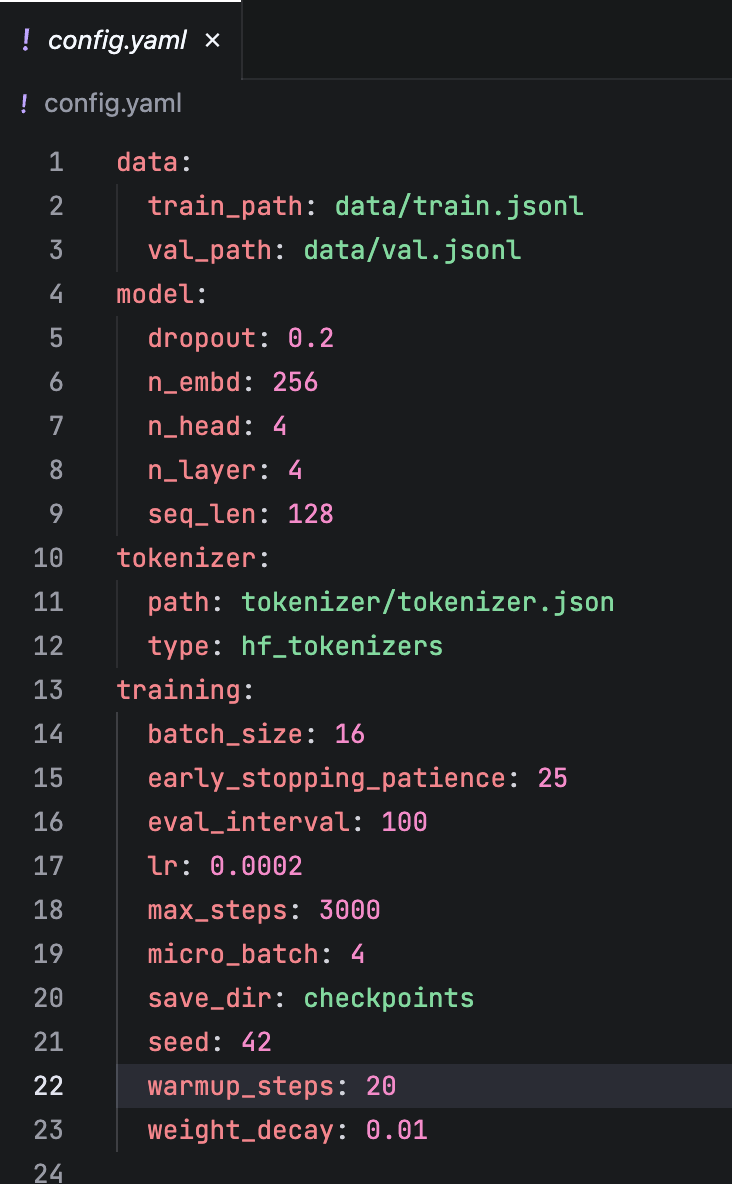
训练参数说明(config.yaml)
参数 | 当前值 | 含义 |
|---|---|---|
max_steps | 3000 | 训练步数上限 |
batch_size | 16 | 每步有效批大小 |
micro_batch | 4 | 每次实际处理的小批次 |
lr | 0.0002 | 学习率(参数更新的步幅) |
warmup_steps | 20 | 预热步数(学习率从 0 渐增) |
eval_interval | 100 | 每 100 步评估一次 |
early_stopping_patience | 25 | 连续 25 次评估没改善就停止 |
训练完成后的产物
训练结束后,checkpoints/ 目录下会生成以下文件:
文件 | 说明 |
|---|---|
last.pt | 最后一步的模型权重 |
best.pt | 验证损失最低的模型权重 |
quantized.pt | 量化后的模型(体积更小、推理更快) |
train_history.json | 训练历史(每步 loss) |
train_time.txt | 训练耗时统计 |
可选参数
# 强制使用 CPU 训练
python -m src.train --device cpu
# 自动选择(有 GPU 用 GPU,没有用 CPU)
python -m src.train --device auto # 默认行为
# 禁用 Flash Attention
python -m src.train --no-flash训练需要多长时间
在一台普通 CPU 笔记本上(如 M1/M2 Mac),训练 3000 步大约 15~25 分钟。如果有 GPU,会更快。
第四步:验收测试
模型训练完了,但它到底学到了什么?我们需要验收。
4.1 训练集内测试(验证逻辑自洽能力)
python -m src.test_acceptance --ckpt checkpoints/last.pt --device auto --mode training这个命令会用 data/test_acceptance.jsonl 中的 10 个问题测试模型,每个问题计算生成答案与期望答案的关键词匹配度。
通过标准:至少 8 个问题的匹配度 ≥ 80%。
4.2 验收数据集测试(验证泛化能力)
python -m src.test_acceptance --ckpt checkpoints/last.pt --device auto --mode acceptance这个命令会用 data/val_acceptance.jsonl 中的 10 个通用知识问题测试模型。这些问题不包含在训练集中,测试的是模型的泛化能力。
通过标准:至少 7 个问题的匹配度 ≥ 80%。
4.3 单个问题测试
如果你想手动问模型一个问题:
python -m src.infer --prompt "什么是注意力机制?" --ckpt checkpoints/last.pt --temperature 0.0 --show_label --device auto输出:
回答:注意力通过分配权重让模型重点参考关键位置,提升对序列关系的理解。4.4 验收命令参数详解
test_acceptance 参数
python -m src.test_acceptance [参数]参数 | 默认值 | 说明 |
|---|---|---|
--ckpt | checkpoints/last.pt | 模型权重文件路径 |
--device | auto | 设备选择:auto(自动)或 cpu |
--test_file | data/test_acceptance.jsonl | 测试数据文件路径(--mode training 时使用) |
--temperature | 0.0 | 生成温度,0 表示确定性输出 |
--top_p | 0.9 | nucleus 采样阈值 |
--mode | training | 测试模式:training(训练集内)或 acceptance(泛化验收) |
参数解释:
--ckpt:指定用哪个模型。训练后会生成last.pt(最后一步)和best.pt(最优一步)。通常用last.pt即可;如果验证损失在训练后期有上升,可以用best.pt。--device auto:程序会自动检测,有 GPU 就用 GPU,没有就用 CPU。如果你的电脑没有 GPU,写cpu也行。--temperature 0.0:温度为 0 时,模型每次给出相同的回答(确定性输出),便于复现和对比。温度越高,回答越"有创意"但也越不可控。--top_p 0.9:控制采样范围,只从概率累积前 90% 的候选词中选择。越小越保守。--mode training:用训练集相关的问题测试,验证模型是否记住了学过的内容。--mode acceptance:用独立验收集测试,验证模型是否具有泛化能力。
infer 参数
python -m src.infer --prompt "你的问题" [参数]参数 | 默认值 | 说明 |
|---|---|---|
--prompt | (必填) | 你想问模型的问题 |
--ckpt | checkpoints/last.pt | 模型权重文件路径 |
--max_new_tokens | 64 | 最多生成多少个 token |
--temperature | 0.0 | 生成温度(0=确定性,越高越随机) |
--top_k | 0 | top-k 采样(0=不限制) |
--top_p | 0.9 | nucleus 采样阈值 |
--repetition_penalty | 1.0 | 重复惩罚(>1 减少重复) |
--stop_strings | 。 ; \n | 遇到这些字符就停止生成 |
--show_label | 关闭 | 加上此参数会在输出前加"回答:"前缀 |
--device | auto | 设备选择 |
参数解释:
--temperature:0.0:每次回答一样,适合测试验收0.5:稍微有些变化,适合日常使用1.0:比较随机,可能产生不同回答
--max_new_tokens 64:控制回答的最大长度。一个问题回答大概 20~40 个 token,64 已经足够。如果想让模型多说一些,可以调大到 128。--repetition_penalty:如果发现模型重复说同一句话,可以把这个值调到1.2或1.5,模型就会尽量避免重复。--stop_strings:模型生成到句号、分号或换行时自动停止。这是为了让回答更简洁,不会一直生成下去。
4.5 验收输出解读
运行验收测试后,你会看到类似这样的输出:
开始验收测试,共10个问题...
================================================================================
问题 1/10
Q: 解释RoPE的作用
A(期望): RoPE把相对位置信息注入注意力,保留位序关系且高效。
A(生成): RoPE把相对位置信息注入注意力,保留位序关系且高效。
匹配度: 100.0%
--------------------------------------------------------------------------------
问题 2/10
Q: 解释蒸馏水与纯水区别?
A(期望): 蒸馏水是通过蒸馏获得的水,去除了大部分杂质...
A(生成): 蒸馏水是通过蒸馏获得的水,去除了大部分杂质...
匹配度: 95.0%
--------------------------------------------------------------------------------
...
================================================================================
验收测试总结
================================================================================
逻辑自洽能力: 92.0% (目标: ≥90%)
总体匹配度: 92.0%
通过≥80%标准的问题数: 10/10 (目标: ≥8)
✓ 训练集内测试通过!关键看两个数字:
- 总体匹配度:所有问题的平均匹配率,90% 以上说明学得很好
- 通过数量:匹配度 ≥ 80% 的问题数量,≥ 8 个即通过
第五步:生产环境部署
验收通过后,就可以把模型部署到生产环境了。
5.1 导出安全格式(safetensors)
训练产生的 .pt 文件使用 Python pickle 格式,存在安全风险。生产环境推荐使用 safetensors 格式:
python -m src.export_safetensors --ckpt checkpoints/last.pt --output checkpoints/model.safetensors --include_config执行后生成两个文件:
checkpoints/model.safetensors:模型权重(安全格式)checkpoints/model.json:模型配置
5.2 使用量化模型
训练过程会自动生成量化模型 checkpoints/quantized.pt。量化(INT8)是把模型参数从 32 位浮点数压缩为 8 位整数,体积缩小约 4 倍,推理速度提升 2~3 倍,精度损失很小。
推理时,程序会自动检测模型是否为量化格式:
# 使用量化模型推理
python -m src.infer --prompt "什么是注意力机制?" --ckpt checkpoints/quantized.pt --temperature 0.0 --show_label5.3 部署方式
方式一:直接使用推理脚本
最简单的方式,适合演示和小规模使用:
python -m src.infer --prompt "你的问题" --ckpt checkpoints/quantized.pt --temperature 0.0 --show_label --device cpu方式二:封装为 API 服务
可以基于推理脚本封装一个简单的 HTTP API:
from src.model import GPT
from src.infer import load_checkpoint, generate
from src.data import load_tokenizer
# 启动时加载模型(只加载一次)
obj = load_checkpoint("checkpoints/quantized.pt")
cfg = obj["cfg"]
tok = load_tokenizer(cfg["tokenizer"]["type"], cfg["tokenizer"]["path"])
model = GPT(
vocab_size=tok.vocab_size,
n_layer=cfg["model"]["n_layer"],
n_head=cfg["model"]["n_head"],
n_embd=cfg["model"]["n_embd"],
seq_len=cfg["model"]["seq_len"],
dropout=cfg["model"]["dropout"],
use_flash=False,
)
model.load_state_dict(obj["model"])
# 推理时调用
def ask(question: str) -> str:
return generate(model, tok, question, max_new_tokens=64,
temperature=0.0, top_p=0.9, device="cpu")注意:以上是示意代码,实际部署时可结合 Flask / FastAPI 等框架提供 HTTP 接口。
第六步:生产环境验证
部署完成后,需要从效果和性能两个维度验证。
6.1 效果验证
运行验收测试,确认部署后的模型效果没有退化:
# 训练集内验收
python -m src.test_acceptance --ckpt checkpoints/quantized.pt --device cpu --mode training
# 泛化验收
python -m src.test_acceptance --ckpt checkpoints/quantized.pt --device cpu --mode acceptance用 quantized.pt 跑一遍,确认通过标准与 last.pt 一致。
6.2 首 Token 耗时测量
"首 Token 耗时"(Time To First Token, TTFT)是衡量推理响应速度的关键指标。用户提问后,多久能看到第一个字?
可以用下面的方法简单测量:
# 测量推理总耗时(近似首 token 耗时,因为本模型输出很短)
time python -m src.infer --prompt "什么是注意力机制?" --ckpt checkpoints/quantized.pt --temperature 0.0 --device cpu在普通 CPU 笔记本上,预期结果:
模型 | 首 Token 耗时 | 总推理耗时(64 token) |
|---|---|---|
last.pt(FP32) | 约 50~100ms | 约 1~2s |
quantized.pt(INT8) | 约 20~50ms | 约 0.5~1s |
model.safetensors | 约 50~100ms | 约 1~2s |
以上数据为参考值,实际取决于 CPU 性能。
6.3 优化方向
如果觉得推理速度不够快,可以考虑以下优化方向:
优化方向 | 说明 | 预期提升 |
|---|---|---|
动态量化 | 已实现(quantized.pt) | 速度提升 2~3 倍 |
KV Cache | 缓存注意力计算结果,避免重复计算 | 推理速度提升 30~50% |
ONNX 导出 | 将模型转为 ONNX 格式,利用 ONNX Runtime 加速 | 速度提升 2~4 倍 |
增大模型 | 增加层数和维度,提升回答质量 | 效果提升,但推理变慢 |
增加训练数据 | 更多高质量的问答数据 | 效果显著提升 |
增大词表 | 从 4096 增大到 8192 或更大 | 中文处理更精细 |
第七步:小结及迭代方向
小结
到这里,你已经完成了:
- ✅ 克隆了一个 中文GPT 小模型的训练项目
- ✅ 训练了一个中文分词器
- ✅ 在 CPU 上训练了一个 3.37M 参数的中文 GPT 模型
- ✅ 通过验收测试验证了模型效果
- ✅ 导出了生产部署所需的模型格式
- ✅ 在生产环境验证了效果和性能
你刚刚从零完成了一个机器学习模型的完整生命周期。 虽然模型很小,但流程和 ChatGPT 等大模型的训练流程本质相同——只是规模不同。
迭代方向
如果你想继续深入,这里有几个方向:
方向一:提升模型能力
- 增加训练数据(当前 265 条,可以扩展到数千条)
- 增大模型规模(如
n_layer=6, n_embd=512) - 增大词表(如
vocab_size=8192) - 增加训练步数
方向二:提升工程质量
- 添加 KV Cache 加速推理
- 添加 ONNX 导出支持
- 实现模型服务化(REST API / gRPC)
- 添加监控和日志
方向三:学习更多原理
- 理解 Transformer 注意力机制
- 学习反向传播和梯度下降
- 了解学习率调度策略
- 研究 BPE 分词算法
第八步:项目工程介绍
这一节带你了解项目的代码结构,为进一步学习做个铺垫。
目录结构
GPT_teacher-3.37M-cn/
├── config.yaml # 全局配置文件
├── pyproject.toml # 项目依赖定义
├── data/ # 训练数据
│ ├── train.jsonl # 训练集(265 条问答)
│ ├── val.jsonl # 验证集(13 条)
│ ├── test_acceptance.jsonl # 训练集内测试集(10 条)
│ └── val_acceptance.jsonl # 泛化验收集(10 条)
├── tokenizer/
│ └── tokenizer.json # 分词器文件(训练分词器后生成)
├── checkpoints/ # 模型权重(训练后生成)
│ ├── last.pt # 最后一步权重
│ ├── best.pt # 最优权重
│ ├── quantized.pt # 量化权重
│ └── model.safetensors # 安全格式权重
└── src/ # 源代码
├── build_tokenizer.py # 训练分词器
├── data.py # 数据加载和处理
├── model.py # GPT 模型定义
├── train.py # 训练主循环
├── infer.py # 推理(生成回答)
├── test_acceptance.py # 验收测试
├── tokenizer.py # 分词器加载
├── export_safetensors.py # 导出安全格式
└── utils.py # 工具函数数据格式
所有数据文件使用 JSONL 格式(每行一个 JSON 对象):
{"prompt": "什么是注意力机制?", "completion": "注意力通过分配权重让模型重点参考关键位置..."}prompt:问题completion:期望的回答
如果你想用自己的数据训练,只需按照这个格式准备 JSONL 文件即可。
配置文件(config.yaml)
所有超参数集中在 config.yaml 中管理:
data:
train_path: data/train.jsonl # 训练数据路径
val_path: data/val.jsonl # 验证数据路径
model:
n_layer: 4 # Transformer 层数
n_head: 4 # 注意力头数
n_embd: 256 # 嵌入维度
seq_len: 128 # 最大序列长度
dropout: 0.2 # Dropout 比率
tokenizer:
type: hf_tokenizers # 分词器类型
path: tokenizer/tokenizer.json # 分词器路径
training:
batch_size: 16 # 有效批大小
micro_batch: 4 # 微批次大小(梯度累积)
max_steps: 3000 # 最大训练步数
lr: 0.0002 # 学习率
warmup_steps: 20 # 预热步数
eval_interval: 100 # 评估间隔
early_stopping_patience: 25 # 早停耐心值
save_dir: checkpoints # 保存目录
seed: 42 # 随机种子
weight_decay: 0.01 # 权重衰减核心源码导读
下面简要介绍每个源文件的作用和核心逻辑,帮助你找到进一步学习的切入点。
src/model.py — GPT 模型定义
这是整个项目的核心,定义了 GPT 模型的结构。
- RMSNorm:归一化层,比 LayerNorm 更简洁高效
- rope():RoPE 位置编码函数,给每个 token 注入位置信息
- SelfAttention:自注意力层,模型"看上下文"的能力来源
- MLP:前馈网络层,模型"理解语义"的能力来源
- Block:一个 Transformer 块 = 注意力 + 前馈 + 残差连接
- GPT:完整模型 = 嵌入层 + N 个 Block + 输出层
关键设计:权重共享——self.head.weight = self.tok_emb.weight,输入嵌入和输出层共用一套参数,既减少参数量,又让语义表示更一致。
src/data.py — 数据处理
负责把 JSONL 数据转换成模型能吃的张量。
核心逻辑是 Teacher Forcing(教师强制):
- 把问题和答案拼成一段文本:
"用户:问题\n助手:答案" - 输入是这段文本,目标是向后偏移一位
- 关键:只对答案部分计算损失,问题部分的标签设为
-100(忽略)
这样模型只学习"给定问题和答案开头,预测答案的下一个词"。
src/train.py — 训练主循环
训练的核心流程:前向传播 → 计算损失 → 反向传播 → 更新参数,循环往复。
关键特性:
- 梯度累积:
micro_batch=4,每 4 个小批次才更新一次参数,等效于 batch_size=16 - 学习率调度:前 20 步线性预热,之后余弦退火
- 早停:连续 25 次评估验证损失没有改善就停止训练
- 自动量化:训练结束后自动导出 INT8 量化模型
src/infer.py — 推理引擎
让训练好的模型生成回答。
推理流程:
- 把用户问题格式化为
"用户:问题\n助手:" - 逐个 token 生成回答
- 每生成一个 token 时,通过温度、top-k、top-p 控制随机性
- 遇到停止词(句号、分号、换行)或 EOS 标记时停止
src/build_tokenizer.py — 分词器训练
从训练数据中学习中文文本的切分规则。
使用 HuggingFace 的 tokenizers 库,训练一个 ByteLevel BPE 分词器:
- 把所有中文文本先转为字节序列
- 通过 BPE 算法找出最常见的字节组合
- 生成 4096 个"片段"作为词表
src/test_acceptance.py — 验收测试
自动化测试模型的回答质量。
核心指标是关键词匹配度:把期望答案按词拆分,看生成答案包含了多少个期望词。例如期望答案有 10 个词,生成了 8 个,匹配度就是 80%。
模型训练的完整数据流
原始数据 (JSONL)
↓ build_tokenizer.py
分词器 (tokenizer.json)
↓ data.py
数字序列 + 标签
↓ train.py
模型权重 (.pt / .safetensors)
↓ infer.py
中文回答这就是从数据到回答的完整链路。每一步都对应上面的一个源文件。
常见问题
Q:训练报错 "No module named 'src'"?
确保在项目根目录下运行命令,并且虚拟环境已激活。
Q:训练 loss 不下降?
检查 data/train.jsonl 是否存在且不为空。运行 wc -l data/train.jsonl 确认数据行数。
Q:模型回答乱码?
重新训练分词器:python -m src.build_tokenizer,然后重新训练模型。
Q:Mac 上量化报错?
部分 Mac 平台不支持 PyTorch 动态量化。这不影响使用,直接用 last.pt 即可。
Q:想用自己的数据训练?
按 JSONL 格式准备数据文件,每行格式为 {"prompt": "问题", "completion": "回答"},然后修改 config.yaml 中的数据路径。
现在,打开终端,从第一步开始,亲手训练一个属于你自己的 中文GPT 小模型吧。
如何从0到1在CPU上训练一个可演示的中文GPT?用TRAE,一个Prompt搞定!
从0到1手搓484行代码,用普通CPU训练一个3.37M中文GPT模型,耗时不到20分钟,回答的效果很不错,欢迎各位老师检查作业
项目源码:
https://github.com/helloworldtang/GPT_teacher-3.37M-cn
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-30,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号