2026 RAG 全景:从大模型基座到 Agent 记忆中枢——万字长文吃透全栈落地

2026 RAG 全景:从大模型基座到 Agent 记忆中枢——万字长文吃透全栈落地

烟雨平生
发布于 2026-04-14 19:19:29
发布于 2026-04-14 19:19:29
这不是一篇给你讲概念的文章。
这是一份让你看完就能动手,少走半年弯路的实战指南。
为什么你必须搞懂 RAG
2023 年是大模型“百模大战”年,所有人都在刷榜单、比参数。2024 年起,战场转移了——谁能把大模型真正用起来,谁才有价值。
而检索增强生成(RAG,Retrieval-Augmented Generation),就是这场“应用落地战”里最核心的武器。RAG能让大模型在生产环境真正用起来!!!
不夸张地说:没有 RAG 打底,一切 AI 应用都是 PPT。
你可能在无数地方见过 RAG 这个词,但很多讲解要么只停在“向量检索+大模型生成”这层皮,要么铺天盖地的英文论文让人望而却步。这篇文章的目标只有一个:让你真正搞懂 RAG,并且能落地。
文章结构如下:
- RAG 是什么,为什么需要它
- RAG 技术的发展迭代历程
- 落地时如何做技术选型
- 业界当前的经典实践
- RAG 未来的发展方向
- 从零到一的 RAG 实战落地路径
全文约 12000 字,干货优先,代码和图表穿插,一次读完,够用一年。
第一章:RAG 是什么,为什么需要它?
1.1 从一个真实的痛点说起
你公司买了 GPT-4 API 权限,花了两周做了一个“企业智能客服”——把公司所有产品文档喂进去,用户提问,AI 作答。
演示很完美。上线第一天,用户来问:
“你们最新出的 Pro 版本,和去年的 Basic 版本相比,具体差在哪里?”
AI 答得头头是道。可你看完之后发现——它在瞎说。
因为 GPT-4 根本不知道你们公司存在,更不知道你们有什么产品。 它给出的答案完全是根据训练数据“编”出来的。
这就是 大模型的两大致命缺陷:
① 知识截止(Knowledge Cutoff)
所有大模型都有训练截止日期。GPT-4 的训练数据截止到某个时间点,之后发生的事情它一概不知。你公司上个月发布的新产品,它当然不知道。
② 幻觉(Hallucination)
幻觉就是大模型生成看似合理但实际是错误的回答,是大模型在 “一本正经地胡说八道”。大模型是在海量数据上训练出来的玩“文字接龙”的概率预测机器,大模型没有思想,只是在做极致的数学计算。当它被问到不知道的事情时,它不会说“我不知道”,而是会“合情合理地编造”一个听起来像真的答案。这个问题在专业领域里会造成严重后果。
那能不能把知识喂进去训练?
理论上可以,但:
- 重新微调一个大模型,费用从几万到几百万不等;
- 你的文档每天都在更新,不可能每次更新都去重训;
- 训练完的知识“固化”在权重里,之后依然存在知识截止问题。
RAG 就是来解决这两个问题的。
1.2 RAG 的核心思路
RAG 的核心思路极其简单,用一句话概括:
在让大模型作答之前,先去外部知识库找到相关信息,然后把这些信息连同问题一起交给大模型。
用生活化的比喻来说:
你去参加一场开卷考试,不需要把所有知识背进脑子里——你只需要知道去哪里找,以及如何把找到的内容用在答案上。
RAG 里的大模型就是那个能看懂资料、组织语言作答的“学生”,而外部知识库就是那本“参考书”。
RAG 全称 Retrieval-Augmented Generation,直译是“检索增强生成”,三个词对应三个步骤:
用户提问
│
▼
[Retrieval 检索] → 去知识库里找相关文档片段
│
▼
[Augmentation 增强] → 把找到的内容拼到 Prompt 里
│
▼
[Generation 生成] → 大模型根据上下文生成答案1.3 RAG 解决了什么,没解决什么
RAG 解决的问题:
- ✅ 知识时效性:外部知识库随时可更新,不需要重训模型
- ✅ 幻觉抑制:答案有“依据”可查,减少无依据编造
- ✅ 私有知识接入:企业内部文档、专有数据可安全接入
- ✅ 可追溯性:答案可以附上来源链接,用户可自行核实
- ✅ 成本可控:无需重训大模型,只需维护知识库
RAG 没有解决的问题:
- ❌ 复杂推理:需要多步逻辑推导的问题,基础 RAG 依然力不从心
- ❌ 极致实时性:入库、索引构建存在一定延迟
- ❌ 跨文档关联推理:“A 和 B 两个文档里的信息联合说明了什么”这类问题,基础 RAG 效果较差
这些问题是 Advanced RAG 和 Agentic RAG 要解决的,我们后面会讲。
第二章:RAG 技术的发展迭代
RAG 技术从提出到今天,经历了清晰可辨的五代演进。
2.1 第一代:概念诞生(2020 年)
RAG 这个词最早由 Facebook AI Research 在 2020 年的论文
《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》 里明确提出。
这篇论文里的 RAG 和我们今天用的有本质区别:它是端到端可训练的。检索器和生成器是一个整体,用联合训练的方式来优化。
当时这个架构的问题很明显:
- 训练成本高,工程难度大
- 需要有标注数据才能训练检索器
- 无法直接使用“现成大模型”,必须联合训练
所以这一代 RAG 主要停留在学术圈,没有大规模落地。
2.2 第二代:范式确立(2022–2023 年)
ChatGPT 的爆火是一个分水岭。大量企业迫切需要把大模型用起来,但又面临“幻觉”和“知识时效”两大问题。
这时候,一种更务实的 RAG 范式出现了:
不做联合训练,直接用 Prompt Engineering 把检索结果塞进上下文。
这一代 RAG 的架构变成了松散耦合的两个独立组件:
- 检索器:负责找相关内容,通常是向量数据库 + Embedding 模型
- 生成器:任意大模型(GPT-4、Claude 等),通过 Prompt 输入检索结果
这个范式彻底降低了门槛。LangChain、LlamaIndex 等框架的出现,让“5 分钟搭一个 RAG demo”成为可能。
2023 年是 RAG 的“野蛮生长年”,每家公司都在搭自己的知识库问答,大量 RAG 应用上线。
但很快大家发现:Demo 效果好,生产效果差。 这催生了对 RAG 的深度优化需求。
2.3 第三代:Advanced RAG(2023–2024 年)
研究者和工程师开始分析 RAG 失效的原因,总结出核心问题出在三个环节:
① 检索前(Pre-Retrieval)问题
- 用户提问本身质量差,导致检索出错
- 歧义表达、口语化表达导致语义匹配失败
② 检索中(During Retrieval)问题
- 文本切分(Chunking)策略不当,把关键信息切断
- 纯向量检索对精确匹配词(人名、代号、型号)效果差
③ 检索后(Post-Retrieval)问题
- 召回内容过多,把重要信息“淹没”
- 没有对召回结果做质量过滤
Advanced RAG 针对这三个环节提出了对应优化:
Pre-Retrieval 优化:
- Query Rewriting(查询改写):用大模型把模糊问题改写成检索友好格式
- Query Expansion(查询扩展):一个问题扩展成多个角度子问题,提升召回率
- HyDE(假设文档嵌入):先让大模型“假设”一个答案,用假设答案去检索
During Retrieval 优化:
- 混合检索(Hybrid Search):向量检索(语义)+ BM25(关键词)并行
- Chunk 策略优化:小块检索、大块喂给 LLM
- 父文档检索(Parent Document Retrieval):细粒度定位,粗粒度返回上下文
Post-Retrieval 优化:
- Re-ranking(重排序):用 Cross-Encoder 精细打分,提升 Top-K 质量
- 上下文压缩(Context Compression):剔除无关冗余,减轻 LLM 上下文压力
这一阶段 RAG 效果显著提升,但系统复杂度也大幅增加。
2.4 第四代:Modular RAG(2024 年)
随着 Advanced RAG 组件越来越多,研究者开始思考一个更高层次的问题:
不同查询场景,需要的 RAG 流程不同。能不能让 RAG 流程动态可配置?
Modular RAG 的思路是:把每个 RAG 环节抽象成独立模块,根据查询类型、数据源动态组合。
核心组件拆分:
- Search Module:向量、关键词、知识图谱、SQL 查询
- Memory Module:短期上下文记忆、长期知识存储
- Fusion Module:多路召回结果融合
- Routing Module:根据查询类型路由到不同检索策略
- Predict Module:子问题拆分与迭代检索
这个架构更灵活,更像一个“平台”而不是一条“流水线”。
2.5 第五代:Agentic RAG(2025 年起)
更进一步的演化:把 RAG 流程里的控制权交给大模型自己决策。
Agentic RAG 就是让智能体(Agent)自主思考、规划、调用工具,代替固定流程去完成检索、推理、纠错,最终更聪明地回答复杂问题的 RAG。
传统 RAG 是固定单次检索流程:检索一次 → 生成。
Agentic RAG 让大模型能够:
- 判断当前召回内容是否足够
- 决定是否需要多轮检索(多跳检索)
- 选择从哪个数据源检索
- 评估生成答案是否可靠
本质是 Agent 推理能力 + RAG 知识检索能力 的结合。这是 RAG 当前最前沿方向,第五章详细展开。
第三章:落地 RAG 时的技术选型
很多人做 RAG 技术选型时犯了同一个错误:把选型当成收集“最强组件”的游戏,最终搭出臃肿系统,效果不升反降。
技术选型核心原则:匹配场景,简单优先。
下面逐层拆解每个环节选型要点。
3.1 文档解析层
为什么重要: 数据工程是 RAG 效果的天花板。内容解析得差,后面怎么优化都是填坑。
主要挑战:
- PDF 里的表格、多栏布局、图片处理
- 扫描版 PDF 需要 OCR
- Word、PPT、网页等多格式统一处理
工具选型:
工具 | 特点 | 适用场景 |
|---|---|---|
PyMuPDF | 轻量快速,纯文本提取准确 | 文字版 PDF,快速上手 |
Docling | 支持 GPU,表格/图表识别强 | 复杂排版,生产环境 |
Unstructured | 格式支持最广(20+ 种) | 多格式混合文档库 |
LlamaParse | 云服务,专为 RAG 优化 | 不想自建解析基础设施 |
MinerU | 中文支持好,开源免费 | 中文文档为主的场景 |
pdfplumber | 轻量、精准,表格提取极强,可定位坐标,纯 Python | 文字版 PDF、精准表格抽取、无需复杂排版 |
实践建议:
- 先用最简单工具跑通,再根据问题针对性升级
- 表格是解析难点:大表格拆成“属性-值对”单独存储效果更好
- 自建正则清理逻辑,去掉页眉页脚、目录页码等噪声
3.2 文本切分层(Chunking)
这是被低估最严重的环节。 切分策略直接决定检索质量,没有“万能大小”,只有“适合场景的策略”。
常见策略对比:
① 固定大小切分(Fixed-size Chunking)
- 按 Token/字符截断,可设重叠窗口
- 优点:简单,索引高效
- 缺点:容易在关键信息处截断
- 参考:300–512 Token,50–100 Token 重叠
② 语义切分(Semantic Chunking)
- 基于句子嵌入相似度,在语义断点切割
- 优点:保持语义完整性
- 缺点:计算成本高,结果不均
③ 递归结构切分(Recursive Split)
- 先按段落、再按句子、再按字符递归切分
- LangChain
RecursiveCharacterTextSplitter代表 - 适合大多数通用场景
④ 文档感知切分(Document-aware Chunking)
- Markdown 按标题层级切分
- 代码按函数/类切分
- 根据文档结构而非纯文本切分
⑤ 父子 Chunk(Parent-Child Chunking)
- 小 Chunk(128 Token)用于精确检索
- 大 Chunk(512–1024 Token)用于给 LLM 提供上下文
- 检索用小 Chunk 定位,返回对应大 Chunk
推荐策略:
- 入门:固定大小 + 重叠(300 Token,50 Token 重叠)
- 进阶:父子 Chunk
- 复杂文档:文档感知切分
3.3 Embedding 模型选型
Embedding 模型负责把文本转成向量,是语义搜索核心。
主要评估维度:
- 语义表征能力(MTEB 榜单)
- 支持最大 Token 长度
- 中文支持
- 推理速度与成本
- 是否支持本地部署
主流选型:
模型 | 类型 | 维度 | 特点 |
|---|---|---|---|
text-embedding-3-large | API | 3072 | OpenAI,英文强,成本低 |
text-embedding-3-small | API | 1536 | 性价比高,轻量任务首选 |
BGE-M3 | 开源/本地 | 1024 | 中英双语强,支持密集+稀疏+多向量 |
BGE-large-zh | 开源/本地 | 1024 | 中文专项优化 |
Jina Embeddings v3 | API/本地 | 1024 | 多语言,支持长文本 |
nomic-embed-text | 开源 | 768 | 轻量高效,本地部署友好 |
m3e-base/m3e-large | 开源/本地 | 768/1024 | 国产中文专属,效果稳、速度快,社区常用 |
选型建议:
- 中文场景:优先 BGE-M3 / BGE-large-zh
- 纯 API 不想自建:text-embedding-3-small
- 数据保密要求高:本地部署 BGE 系列
3.4 向量数据库选型
向量数据库负责存储向量并高效执行相似度搜索。
选型前先想清楚:
- 数据量级:百万级以内还是以上?
- 更新频率:静态库还是实时更新?
- 是否需要向量 + 标量过滤混合查询?
- 有无运维能力?
- 预算是否支持云服务?
主流向量数据库对比:
数据库 | 部署方式 | 特点 | 适用场景 |
|---|---|---|---|
Milvus | 自建/云服务 | 功能最全,性能强,企业级 | 大规模生产环境 |
Weaviate | 自建/云服务 | GraphQL 接口,模块化 | 复杂查询、多模态 |
Qdrant | 自建/云服务 | Rust 编写,高性能,支持过滤 | 高性能要求,中小规模 |
Chroma | 本地嵌入 | 简单友好,无需独立服务 | 原型开发、小规模 |
FAISS | 库(非服务) | Meta,高性能,无持久化 | 学习、小项目、自定义封装 |
pgvector | PostgreSQL 扩展 | 无需新技术栈,与 PG 深度集成 | 已有 PostgreSQL 基础设施 |
Pinecone | 全托管云服务 | 零运维,无限扩展 | 不想运维,快速上线 |
Elasticsearch / OpenSearch | 自建 / 云服务 | 成熟生态,全文检索 + 向量检索一体,插件化(k-NN),社区极大 | 已有 ES/OpenSearch 业务,混合文本 + 向量检索,企业级搜索 |
选型路径:
- 快速验证/个人项目:Chroma / FAISS
- 已有 PG:pgvector
- 中小企业自建:Qdrant / Milvus Lite
- 大规模企业:Milvus + 云部署
- 不想运维:Pinecone
3.5 LLM 选型
LLM 是“大脑”,RAG 是“外接记忆”。LLM 选型主要看:
需求 | 推荐选型 |
|---|---|
最强效果,不计成本 | GPT-4o / Claude 3.5 Sonnet |
效果成本平衡 | GPT-4o-mini / Gemini 1.5 Flash |
中文理解,国产方案 | Qwen2.5-72B / DeepSeek-V3 |
本地部署,数据保密 | Qwen2.5-32B / Llama 3.3 70B |
超长上下文需求 | Gemini 1.5 Pro(200万 Token) |
微信生态 + 中文日常 | 元宝(全系列) |
注意:
LLM 没有一劳永逸。建议先用强模型验证方向,再逐步替换为高性价比模型。
实战常用路径:GPT-4o 验证 → Qwen-plus 降本。
3.6 RAG 框架选型
不想从零搭建,可以基于现有框架。
代码框架:
- LangChain:生态最全,事实标准;缺点是抽象层多,性能与灵活性有损耗
- LlamaIndex:专注 RAG,组件粒度更细,高级特性支持好
- Haystack:企业级,Pipeline 设计,适合生产
低代码/无代码平台:
- Dify:国内最流行,支持工作流编排
- FastGPT:知识库问答专项优化
- Coze:字节跳动出品,Agent 与工具集成强
什么时候用框架,什么时候自研?
快速验证、非核心业务:框架优先
性能要求高、深度定制、核心竞争力:自研
一个真实判断标准:当你为绕开框架限制写的代码,比直接自研还多时,就该自研了。
第四章:业界经典实践
技术选型搞定后,更重要的是:怎么把组件组合成真正好用的 RAG 系统。
这一章是经过生产验证的经典实践。
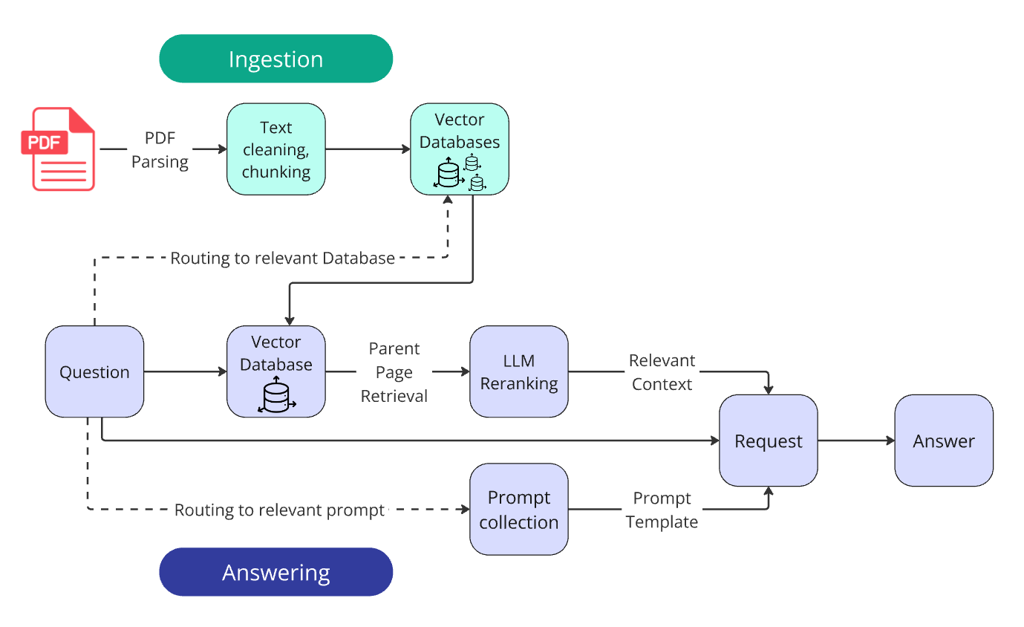
4.1 数据入库流水线
完整知识库建设流程(Ingestion Pipeline):
原始文档(PDF/Word/网页/数据库)
│
▼
[1] 文档解析(Parser)
│ → 提取纯文本,处理表格、图片
▼
[2] 文本清洗(Cleaner)
│ → 去噪声:页码、页眉页脚、乱码
▼
[3] 文本切分(Chunker)
│ → 按策略切分,附加元数据(来源、页码)
▼
[4] 向量化(Embedder)
│ → 每个 Chunk 生成向量
▼
[5] 写入向量库(Indexer)
│ → 存入向量数据库,建立索引
▼
知识库就绪 ✅关键细节:
元数据(Metadata)至关重要
每个 Chunk 必须附带丰富元数据:
{
"chunk_id": "doc_001_chunk_023",
"source": "产品手册v2.0.pdf",
"page": 15,
"chapter": "高级功能",
"created_at": "2025-01-15",
"doc_type": "manual"
}后续可按元数据过滤,例如“只在 2025 年后文档中搜索”。
增量更新策略
生产环境文档持续更新,需要支持:
- 新文档增量入库
- 文档更新时删除旧 Chunk、写入新 Chunk
- 文档删除时清理对应向量
4.2 查询增强:不要用原始问题直接检索
这是提升 RAG 效果最直接有效的手段之一。
问题一:用户原始提问质量差
用户说:“那个客户上次说的 API 的事情怎么解决的?”
直接检索效果必然很差。
解决方案:查询改写(Query Rewriting)
rewrite_prompt = """
你是一个查询优化专家。用户提出了一个问题,请将它改写为更适合文档检索的形式。
要求:
- 去除口语化表达
- 补全指代不明的部分(如"那个""上次")
- 保留核心意图
原始问题:{user_query}
改写后的问题:
"""问题二:单个问题角度有限,召回率低
解决方案:多查询生成(Multi-Query Generation)
一个问题扩展成 3–5 个不同角度子查询,分别检索后合并去重。
问题三:复杂问题需要多步检索
解决方案:问题分解(Query Decomposition)
把“比较 A 与 B 产品性能差异”分解为:
- A 产品性能指标?
- B 产品性能指标?
- 共同评估维度?
分别检索,再综合回答。
进阶技巧:HyDE(假设文档嵌入)
不直接用问题检索,而是:
- 让 LLM 生成一个“假设答案”
- 用假设答案去检索
- 返回与假设答案最相关的真实文档
原因:答案的语义空间通常比问题更接近文档。
4.3 混合检索:向量 + 关键词,缺一不可
单纯向量检索有硬伤:对精确词汇不敏感。
例如“iPhone 15 Pro Max 电池容量”,向量相似度不高,BM25 反而能精确命中。
混合检索架构:
用户查询
│
├──── 向量检索(语义) ─── 召回 Top-20
│
└──── BM25 检索(关键词) ─ 召回 Top-20
两路结果 → 融合排序(RRF)→ Top-10RRF(Reciprocal Rank Fusion)融合算法:
def reciprocal_rank_fusion(results_list, k=60):
scores = {}
for results in results_list:
for rank, doc_id in enumerate(results):
scores[doc_id] = scores.get(doc_id, 0) + 1 / (k + rank + 1)
return sorted(scores.keys(), key=lambda x: scores[x], reverse=True)实践经验: 混合检索普遍优于单一检索,初始权重建议向量:BM25 = 0.7:0.3。
4.4 重排序:召回质量的最后一道关
召回 Top-20,最终只给 LLM Top-5。这个从 20 到 5 的筛选,就是重排序(Reranking)。
为什么需要重排序?
向量检索用 Bi-Encoder:查询和文档分别编码再算相似度,速度快但精度有限。
重排序用 Cross-Encoder:把查询和文档拼接一起输入模型,精度更高但更慢。
最佳实践:Bi-Encoder 大范围快速召回,Cross-Encoder 精确重排。
常用重排序工具:
- BGE-Reranker(中文首选)
- Cohere Rerank
- Jina Reranker
- LLM 直接打分
4.5 生成层优化:让 LLM 用好检索结果
检索到好内容,如果 Prompt 写得差,LLM 依然会给出糟糕答案。
核心 Prompt 结构:
[系统角色]
你是专业企业知识助手,只基于提供的参考文档回答。
若无相关信息,请明确说明,不要编造。
[检索结果]
文档1(来源:{source_1}):
{content_1}
文档2(来源:{source_2}):
{content_2}
[用户问题]
{user_query}
[输出要求]
1. 基于文档回答
2. 引用内容标注来源
3. 信息不足时说明缺失内容对复杂问题,加入链式思考(CoT),减少错误。
对程序处理场景,用 Pydantic 做结构化输出。
4.6 数据飞轮:让系统越用越聪明
这是生产级 RAG 区别于 Demo 级最重要特征。
飞轮逻辑:
用户提问 → RAG 作答
│
├── 置信度高 → 直接回答,记录日志
│
└── 置信度低 → 触发飞轮
│
标准化问题 → 生成候选答案 → 人工审核 → 入库
│
下次同类问题 → 置信度提升 ♻️关键监控指标:
- 置信度分布
- 问题覆盖率
- 知识库增长速度
- 答案准确率
4.7 系统可观测性
“不可观测的系统,无法持续改进。”
生产级 RAG 必须记录完整链路:
log_entry = {
"request_id": "req_20250406_001",
"user_query": "...",
"rewritten_query": "...",
"retrieved_chunks": [...],
"reranked_results": [...],
"prompt_tokens": 1523,
"llm_response": "...",
"confidence": 0.82,
"latency_ms": 1240,
"feedback": None
}通过日志你能回答:
- 用户最常问什么?
- 哪类问题召回差?
- 哪些文档被高频引用?
- 整体时延如何?
第五章:RAG 未来的发展方向
RAG 高速演进,不看方向容易在细节里迷失。这里讲 6 个关键方向。
5.1 Agentic RAG:让模型自己决定怎么检索
传统 RAG 流程硬编码:一次检索,一次生成。
复杂问题需要多轮:比较、趋势、原因分析等。
Agentic RAG 核心:赋予 LLM 检索工具调用权,自主决策检索策略。
基于 ReAct 框架。ReAct(Reasoning + Acting,推理+行动)是大模型构建AI Agent的核心推理框架,让模型实现 “边思考、边行动、边验证” 的闭环,解决复杂、需要外部交互的任务。
ReAct = 思考 → 动手 → 看结果 → 再思考 → 解决问题。
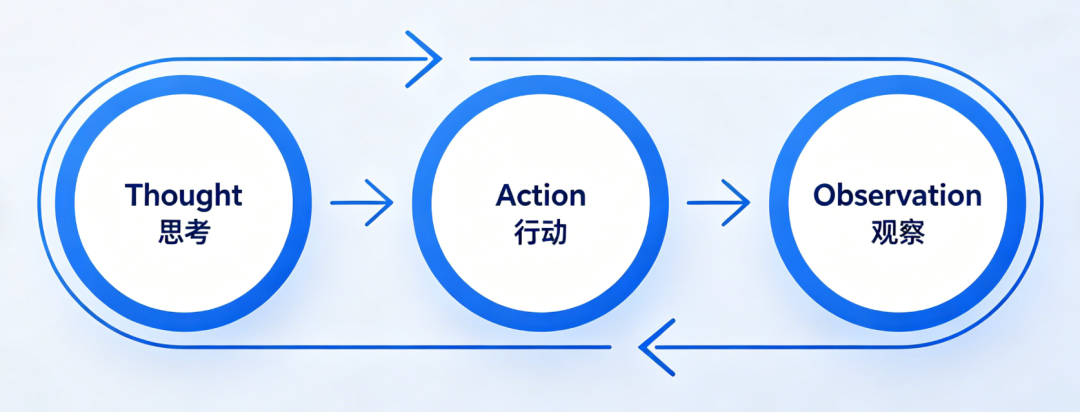
ReAct 严格遵循Thought → Action → Observation → Thought的迭代,可无限循环直到任务结束,把 LLM 从 “纯文本推理” 变成 “会查、会做、会纠错” 的智能体。
Think: 要比较 A 和 B,需分别检索
Act: search("A 产品规格")
Observation: ...
Think: 再查 B
Act: search("B 产品规格")
Think: 信息足够,可以回答
Answer: ...适用场景: 复杂多跳问答、跨数据源查询、分析类问题。
5.2 GraphRAG:知识图谱增强的 RAG
传统 RAG 根本局限:Chunk 之间没有显式关系。
“张三和李四什么关系?”这类问题,向量检索很难关联。
GraphRAG(微软)思路:
- 抽取实体与关系
- 构建知识图谱
- 检索时支持图遍历与多跳查询
优势: 关联推理、全局摘要、可解释性强。
代价: 构建与维护成本高、延迟更高。
5.3 多模态 RAG:不再局限于文字
企业知识不只在文字里:图表、示意图、视频教程。
两大路线:
- 文字化:OCR / 多模态 LLM 转文本描述,接入传统 RAG
- 多模态向量:CLIP 类模型统一编码图文,实现跨模态检索
适用场景: 工业手册、医学影像、多媒体知识库。
5.4 长上下文 vs RAG 的博弈
Gemini 1.5 Pro 支持 200 万 Token,有人问:上下文够长了,还需要 RAG 吗?
答案:仍然需要,但场景会分化。
长上下文优势: 无需检索,避免检索失败。
长上下文劣势: 成本极高、大海捞针、更新困难、延迟高。
RAG 不可替代:
- 超大规模知识库(百 GB 以上)
- 强可溯源要求
- 频繁实时更新
- 成本敏感业务
未来趋势:RAG + 长上下文融合。
先 RAG 精拣少量文档,再全部喂给长上下文 LLM。
5.5 Self-RAG 与 CRAG:让模型自己“批改作业”
Self-RAG(自反思 RAG):
让 LLM 在生成时判断:是否需要检索、内容是否相关、答案是否有依据。
CRAG(Corrective RAG):
召回质量不足时,自动触发 Web Search 补充信息,再去噪生成。
代表方向:从人工调优 → 系统自动优化。
5.6 RAG 评估体系建设
生产级 RAG 必须可度量,才能持续迭代。
主流评估框架: RAGAS、TruLens、LangSmith。
RAGAS 核心指标:
- Faithfulness:忠实度(幻觉程度)
- Answer Relevancy:答案相关性
- Context Precision:上下文精确率
- Context Recall:上下文召回率
建议: 从真实问题抽 100–200 条,人工标注标准答案,作为固定评估集。
第六章:从零到一的 RAG 实战路径
6.1 三阶段落地
阶段一:快速验证(1–2 周)
目标:跑通流程,验证 RAG 对业务有效
技术栈:PyMuPDF/Unstructured + Chroma + BGE-M3 + GPT-4o-mini + LlamaIndex
验收:测试问题回答率 ≥70%
阶段二:效果优化(2–4 周)
目标:准确率从 70% → 85%+
动作:建评估集、查询改写、混合检索、重排序、Prompt 优化
阶段三:生产化(4–8 周)
目标:支撑真实用户,持续迭代
动作:迁移生产向量库、全链路日志、数据飞轮、监控仪表盘、定期评估机制
6.2 避坑清单
- ❌ 过早优化:没跑通基础 RAG 就玩 GraphRAG/Agentic RAG
- ❌ 忽视数据质量:垃圾进,垃圾出
- ❌ 一刀切 Chunk:不同文档用同一套切分参数
- ❌ 只依赖向量检索:精确词场景必须配合 BM25
- ❌ 不做权限控制:企业知识库必须按角色过滤
- ❌ 只看最终答案,不看召回质量:检索坏了,LLM 再强也没用
- ❌ 过度依赖框架:看不到中间日志,出问题无法定位
- ❌ Demo 好就上生产:生产数据远比 Demo 脏
总结:RAG 的本质与边界
RAG 是一种思路,不是一项单一技术。
它的本质是:
在需要知识时动态检索,而不是把所有知识固化在模型里。
这个思路不会消失。
但 RAG 不是银弹:知识库质量、检索精度、上下文组织——每一环都决定最终效果。
RAG 80% 的问题是数据问题,不是技术问题。
这句话值得反复读。
附录:核心工具速查表
开源工具
类别 | 工具 | 链接 |
|---|---|---|
文档解析 | Docling | github.com/DS4SD/docling |
文档解析 | Unstructured | github.com/Unstructured-IO/unstructured |
文档解析 | MinerU | github.com/opendatalab/MinerU |
向量数据库 | Milvus | milvus.io |
向量数据库 | Qdrant | qdrant.tech |
向量数据库 | Chroma | trychroma.com |
Embedding | BGE-M3 | huggingface.co/BAAI/bge-m3 |
Reranker | BGE-Reranker | huggingface.co/BAAI/bge-reranker-large |
RAG 框架 | LlamaIndex | llamaindex.ai |
RAG 框架 | LangChain | langchain.com |
低代码平台 | Dify | dify.ai |
评估框架 | RAGAS | github.com/explodinggradients/ragas |
GraphRAG | Microsoft GraphRAG | github.com/microsoft/graphrag |
关键论文
论文 | 核心贡献 |
|---|---|
RAG (Lewis et al., 2020) | RAG 概念原始论文 |
Self-RAG (Asai et al., 2023) | 自反思 RAG |
CRAG (Yan et al., 2024) | 修正式 RAG |
GraphRAG (Edge et al., 2024) | 知识图谱增强 RAG |
HyDE (Gao et al., 2022) | 假设文档嵌入 |
文章持续更新,如有问题欢迎交流。RAG 领域变化极快,建议关注 Hugging Face Papers 等平台,跟踪最新论文与开源实现。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-06,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号