10分钟带你从零搭建本地RAG:向量 + BM25 + RRF 混合检索,一篇就够+github完整源码

10分钟带你从零搭建本地RAG:向量 + BM25 + RRF 混合检索,一篇就够+github完整源码

烟雨平生
发布于 2026-04-14 19:20:33
发布于 2026-04-14 19:20:33
读完本文,你将:理解 RAG 为什么存在、掌握它的完整工作流程、能独立跑通一个本地知识库问答项目,并深入理解 混合检索(BM25 + 向量检索 + RRF 融合) 的实现原理与价值。配套github仓库地址见文末。
一、RAG是什么?为什么需要?
大模型很聪明,但它有一个天然的缺陷——知识有截止日期,而且它不认识你的私人文档。
举个例子:你问 GPT「我这篇论文的核心结论是什么?」它会一脸茫然,因为它根本没有读过你的论文。
RAG(检索增强生成) 就是来解决这个问题的:
用户提问 ──→ 在你的文档中检索 ──→ 把相关片段发给 LLM ──→ 生成答案说白了就三步:检索 → 拼上下文 → 让 LLM 回答。
这样做有三个直接好处:
- 回答基于真实文档,减少「胡说八道」
- 可以接入最新文档,不受模型训练数据限制
- 答案可溯源,你知道回答来自哪篇文档
本文聚焦实战,想深入了解RAG前世今生的小伙伴:2026 RAG 全景:从大模型基座到 Agent 记忆中枢——万字长文吃透全栈落地
二、项目概览:我们要搭什么?
今天我们基于 langchain-rag-tutorial 项目,手把手搭一个本地个人知识库问答系统,并实现混合检索。
技术选型(全部免费,本地运行):
组件 | 用途 | 用的是什么 |
|---|---|---|
LLM | 生成答案 | Ollama + DeepSeek-R1 1.5B |
Embedding | 把文字转成向量 | Ollama + nomic-embed-text |
稀疏检索 | 关键词精确匹配 | BM25(rank-bm25) |
稠密检索 | 语义相似度搜索 | FAISS |
融合算法 | 多路检索结果合并 | RRF(倒数排名融合) |
应用框架 | 串联整个流程 | LangChain |
为什么需要混合检索?
单一检索方式总有盲区:
- 纯向量检索:语义相近能搜到,但专有名词、精确短语容易漏(比如「Python list comprehension」搜「列表推导式」能命中,但反过来就不一定)
- 纯 BM25:关键词匹配精准,但不理解同义词和语义关联
混合检索让两路各发挥所长,再用 RRF 算法融合排名,兼顾精确和语义。
项目结构:
langchain-rag-tutorial/
├── main.py # 核心代码(包含混合检索)
├── pyproject.toml # 依赖配置
├── data/
│ └── knowledge_base.txt # 知识库文件
├── faiss_index/ # 运行后自动生成
│ ├── index.faiss # FAISS 向量索引
│ └── index.pkl # FAISS 索引元数据(原写法遗漏)
├── bm25_index.pkl # BM25 索引(持久化)
└── tests/
└── test_main.py三、环境准备
1. 安装 uv(Python 包管理工具)
# macOS
curl -LsSf https://astral.sh/uv/install.sh | sh
# Windows
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"2. 安装 Ollama
去 ollama.com 下载安装,然后运行:
# 下载所需模型(ollama serve 会自动后台运行,无需手动执行)
ollama pull deepseek-r1:1.5b # LLM 模型
ollama pull nomic-embed-text # 向量嵌入模型3. 克隆并安装项目依赖
git clone https://github.com/tangcheng/langchain-rag-tutorial.git
cd langchain-rag-tutorial
uv sync四、核心代码逐行拆解
下面我们从 main.py 出发,把整个 RAG 流程拆开来看。
4.1 两个自定义类:让 Ollama 对接 LangChain
LangChain 原生支持 OpenAI,但 Ollama 需要一个适配层:
Embedding 模型适配器:
from langchain_core.embeddings import Embeddings
from typing import List
import ollama
class OllamaEmbeddings(Embeddings):
def __init__(self, model: str = "nomic-embed-text"):
self.model_name = model
def embed_documents(self, texts: List[str]) -> List[List[float]]:
return [self.embed_query(text) for text in texts]
def embed_query(self, text: str) -> List[float]:
return ollama.embeddings(model=self.model_name, prompt=text)["embedding"]LLM 模型适配器:
from langchain_core.messages import BaseMessage
class OllamaChat:
def __init__(self, model: str = "deepseek-r1:1.5b"):
self.model = model
def invoke(self, messages: List[BaseMessage]) -> str:
# 拼接多轮消息
prompt = "\n".join([msg.content for msg in messages])
response = ollama.chat(
model=self.model,
messages=[{"role": "user", "content": prompt}]
)
return response["message"]["content"]这两个类的本质就是翻译器:一边是 LangChain 的标准接口,另一边是 Ollama 的 API。
4.2 文档加载:读入你的知识库
import os
from langchain_text_splitters import CharacterTextSplitter
from langchain_core.documents import Document as LCDocument
def load_documents():
with open("./data/knowledge_base.txt", "r", encoding="utf-8") as f:
content = f.read()
text_splitter = CharacterTextSplitter(
separator="\n\n",
chunk_size=500, # 每块最多 500 字符
chunk_overlap=50, # 块之间重叠 50 字符(防止割裂语义)
length_function=len
)
chunks = text_splitter.split_text(content)
documents = [
LCDocument(page_content=chunk, metadata={"source": "knowledge_base.txt"})
for chunk in chunks if chunk.strip()
]
return documents为什么要切块? LLM 有上下文窗口限制,语义连贯的段落更适合被检索。块之间留重叠是为了防止跨块的关键信息被切断。
4.3 两路索引:FAISS(稠密)+ BM25(稀疏)
这是本项目最关键的部分——同时维护两套索引。
FAISS 向量索引(稠密检索):
from langchain_community.vectorstores import FAISS
INDEX_DIR = "./faiss_index"
BM25_PKL = "./bm25_index.pkl"
RETRIEVE_K = 5
FUISON_K = 5
RRF_K = 60
def build_index(documents, embed_model):
# 已有则直接加载
if os.path.exists(INDEX_DIR):
print("📦 检测到已有 FAISS 索引,加载中...")
return FAISS.load_local(
INDEX_DIR, embed_model,
allow_dangerous_deserialization=True
)
print("🔍 构建 FAISS 向量索引...")
vectorstore = FAISS.from_documents(
documents=documents,
embedding=embed_model # OllamaEmbeddings 把文本转成向量
)
vectorstore.save_local(INDEX_DIR)
return vectorstoreBM25 倒排索引(稀疏检索):
import pickle
from rank_bm25 import BM25Okapi
def build_bm25_index(documents: List[LCDocument]):
"""构建 BM25 倒排索引,支持持久化"""
if os.path.exists(BM25_PKL):
print("📦 检测到已有 BM25 索引,加载中...")
with open(BM25_PKL, "rb") as f:
return pickle.load(f)
print("🔍 构建 BM25 索引...")
doc_texts = [doc.page_content for doc in documents]
# 简单分词:空格分割 + 小写化
tokenized_corpus = [doc.lower().split() for doc in doc_texts]
bm25 = BM25Okapi(tokenized_corpus)
# 持久化到本地
bm25_data = {"bm25": bm25, "doc_texts": doc_texts}
with open(BM25_PKL, "wb") as f:
pickle.dump(bm25_data, f)
print(" BM25 索引创建完成!")
return bm25_dataBM25 的原理(简单理解):
BM25 是 TF-IDF 的改良版。对于一个查询词:
- TF(词频):这个词在文档里出现越多越相关,但出现太多会被「惩罚」
- IDF(逆文档频率):这个词越罕见,区分度越高,越重要
公式中的「饱和函数」让词频达到一定量后不再无限增长,解决了简单词频统计的过度倾向问题。
4.4 RRF 融合算法:把两路结果合并排序
两路检索各说各话,怎么合并成一个统一排名?这就用到了 RRF(Reciprocal Rank Fusion,倒数排名融合):
def reciprocal_rank_fusion(results: List[List[dict]], k: int = 60) -> List[dict]:
"""
RRF 算法核心思想:
对每个检索器返回的结果,按排名分配分数:score = 1 / (k + rank)
排名越靠前,分数贡献越大。不同检索器中同一文档的分数累加。
"""
doc_scores = {}
for retriever_results in results:
for rank, item in enumerate(retriever_results, start=1):
doc_key = item["doc"].page_content
if doc_key not in doc_scores:
doc_scores[doc_key] = {"doc": item["doc"], "rrf_score": 0.0}
# 累加 RRF 分数(排名越靠前,贡献越大)
doc_scores[doc_key]["rrf_score"] += 1.0 / (k + rank)
# 按综合分数降序排列
fused = sorted(doc_scores.values(),
key=lambda x: x["rrf_score"], reverse=True)
return fusedRRF 为什么有效?
假设一个文档在 FAISS 里排第 2,在 BM25 里排第 1:
- FAISS 贡献:
1 / (60 + 2) ≈ 0.0161 - BM25 贡献:
1 / (60 + 1) ≈ 0.0164 - 综合分数:
0.0325
另一个文档只在 FAISS 里排第 1,综合分数只有 1/61 ≈ 0.0164,被前者超越。这就是 RRF 的魔力——综合排名优于任何单一检索器的结果。
参数 k=60 是经验值,越大两路结果越均衡。
4.5 混合检索:把三件事串起来
def dense_search(vectorstore, query: str, k: int) -> List[dict]:
docs = vectorstore.similarity_search(query, k=k)
return [{"doc": doc, "score": 1.0} for doc in docs]
def hybrid_search(vectorstore, bm25_data, documents, query: str) -> List[LCDocument]:
"""
混合检索完整流程:
1. FAISS 向量检索 → Top-5
2. BM25 稀疏检索 → Top-5
3. RRF 融合 → 最终 Top-5 排名
"""
bm25 = bm25_data["bm25"]
doc_texts = bm25_data["doc_texts"]
# 两路并行检索
dense_results = dense_search(vectorstore, query, k=RETRIEVE_K)
sparse_results = sparse_search(bm25, doc_texts, query, documents, k=RETRIEVE_K)
print(f" 📊 FAISS 命中: {len(dense_results)} 条 | BM25 命中: {len(sparse_results)} 条")
if not sparse_results:
# 无 BM25 时,降级为纯向量检索
return [item["doc"] for item in dense_results[:FUISON_K]]
# RRF 融合
fused = reciprocal_rank_fusion([dense_results, sparse_results], k=RRF_K)
# 打印融合排名(方便调试理解)
print(" 🏆 RRF 融合排名(Top-5):")
for i, item in enumerate(fused[:5], 1):
preview = item["doc"].page_content[:40].replace("\n", " ")
print(f" [{i}] 分数={item['rrf_score']:.3f} | {preview}...")
return [item["doc"] for item in fused[:FUISON_K]]稀疏检索实现:
def sparse_search(bm25, doc_texts, query, documents, k):
if bm25 is None:
return []
tokenized_query = query.lower().split()
scores = bm25.get_scores(tokenized_query)
top_indices = sorted(range(len(scores)),
key=lambda i: scores[i], reverse=True)[:k]
return [
{"doc": documents[idx], "score": float(scores[idx])}
for idx in top_indices if scores[idx] > 0
]4.6 问答:检索 + 生成
def answer_question(question, vectorstore, bm25_data, documents, llm):
# 混合检索 Top-5
docs = hybrid_search(vectorstore, bm25_data, documents, question)
# 拼 Prompt,发给 LLM
context = "\n\n".join([doc.page_content for doc in docs])
prompt = f"""基于以下上下文回答问题。如果无法从上下文找到答案,请如实说明。
上下文:
{context}
问题: {question}
回答:"""
print(f"\n❓ 问题: {question}")
print(f"📖 参考 {len(docs)} 个文档片段:")
for i, doc in enumerate(docs, 1):
print(f" [{i}] {doc.page_content[:60].replace(chr(10), ' ')}...")
response = llm.invoke([prompt])
print(f"\n✅ 答案:\n{response}")五、跑起来
uv run python main.py首次运行会同时构建 FAISS 索引和 BM25 索引(大约 10–30 秒),之后每次直接加载。正常运行输出:
🔧 初始化 Ollama LLM...
🔧 初始化 Ollama Embedding...
📚 加载知识库文档...
已加载 8 个文档块
📦 检测到已有 FAISS 索引,加载中...
📦 检测到已有 BM25 索引,加载中...
==================================================
💬 开始混合检索问答测试(FAISS + BM25 + RRF)
==================================================
❓ 问题: 什么是 LlamaIndex?
🔎 混合检索: query =「什么是 LlamaIndex?」
📊 FAISS 命中: 5 条 | BM25 命中: 5 条
🏆 RRF 融合排名(Top-5):
[1] 分数=0.0325 | LlamaIndex(formerly GPT Index)是一...
[2] 分数=0.0246 | RAG(检索增强生成)是 LlamaIndex 的...
[3] 分数=0.0245 | 核心概念包括文档加载器、索引、查询引...
[4] 分数=0.0164 | LlamaIndex 为构建 LLM 应用提供了...
[5] 分数=0.0161 | 与 LangChain 的关系:两者可以结合使用
📖 参考 5 个文档片段:
[1] LlamaIndex(formerly GPT Index)是一...
...
✅ 答案:
LlamaIndex 是一个强大的数据框架...看 RRF 排名那一列,可以清楚看到两路检索各自的贡献——有些文档 FAISS 排第1但 BM25 没命中,有些反过来——融合后的 Top-1 就是综合最优解。
六、完整的混合检索流程图解
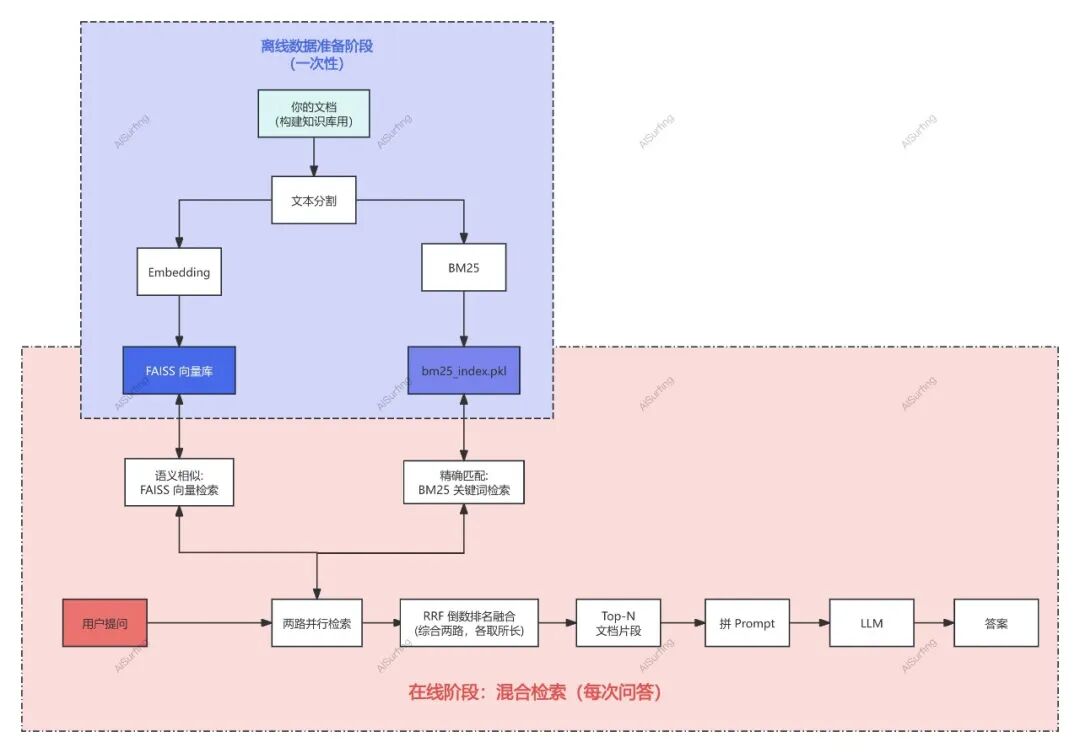
该流程先离线构建文档向量库与 BM25 索引,在线问答时并行语义检索与关键词检索,经 RRF 融合后将 Top-5 片段输入 LLM 生成最终答案。
七、核心概念回顾
概念 | 在项目里对应什么 | 作用 |
|---|---|---|
Document | LCDocument(page_content=chunk) | 一个可检索的文本块 |
Embeddings | OllamaEmbeddings | 把文本转成向量(稠密表示) |
VectorStore | FAISS | 存向量 + 做相似度搜索 |
BM25 | BM25Okapi | 倒排索引,基于词频稀疏检索 |
RRF | reciprocal_rank_fusion() | 多路检索结果融合算法 |
LLM | OllamaChat | 基于上下文生成答案 |
Text Splitter | CharacterTextSplitter | 把大文档切成小块 |
Retrieval | hybrid_search() | 混合检索获取相关片段 |
八、跑通之后,你可以做什么?
扩展 1:换成你自己的文档
把 data/knowledge_base.txt 换成你的内容即可。支持接入:
- PDF:
PyPDFLoader - Word:
Docx2txtLoader - 网页:
WebBaseLoader - Notion、Slack、数据库……
扩展 2:加聊天历史(多轮对话)
from langchain_core.chat_history import InMemoryChatMessageHistory
from langchain_core.runnables.history import RunnableWithMessageHistory
history = InMemoryChatMessageHistory()
chain_with_history = RunnableWithMessageHistory(
rag_chain,
history,
input_messages_key="question",
history_messages_key="chat_history"
)扩展 3:做个 Web UI
用 Streamlit 几行代码就能跑出网页界面:
import streamlit as st
question = st.text_input("问一个问题:")
if question:
docs = hybrid_search(vectorstore, bm25_data, documents, question)
st.write(llm.invoke([build_prompt(docs, question)]))扩展 4:部署成 API 服务
from fastapi import FastAPI
app = FastAPI()
@app.post("/ask")
def ask(question: str):
docs = hybrid_search(vectorstore, bm25_data, documents, question)
return {"answer": llm.invoke([build_prompt(docs, question)])}扩展 5:调参优化
混合检索有几个关键参数可以调:
RETRIEVE_K:每路检索取多少条(越多混合越充分,但噪音也越多)RRF_K:融合参数,越大两路越均衡(通常 60 左右)chunk_size:太小语义碎片化,太大引入噪音,500 是经验起点
九、总结
我们从零跑通了一个完整的本地 RAG 系统,核心链路分三层:
索引层(一次性)
文档 → 切块 → FAISS 向量库 + BM25 倒排索引检索层(每次问答)
问题 → FAISS Top-5 + BM25 Top-5 → RRF 融合 → Top-5生成层(每次问答)
Top-5 文档 + 问题 → 拼 Prompt → DeepSeek-R1 → 答案三条关键经验:
- 混合检索 > 单一检索:两路各发挥所长,比单独用向量或 BM25 都更鲁棒
- RRF 简洁而有效:不需要手动调权重,排名本身就能说明问题
- 索引持久化很重要:构建一次,之后每次问答都直接加载,不浪费算力
整个项目约 300 行 Python 代码,完整覆盖了现代 RAG 系统的核心链路。从这里出发,你可以接更多数据源、加多轮对话、加重排序模型——完全取决于你想解决什么问题。
项目地址:https://github.com/helloworldtang/langchain-rag-tutorial
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-07,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号