从零理解 RAG:LlamaIndex 入门指南

从零理解 RAG:LlamaIndex 入门指南

烟雨平生
发布于 2026-04-14 19:23:48
发布于 2026-04-14 19:23:48
读完本文,你将理解 RAG 的本质、Llam aIndex 解决什么问题,以及为什么需要向量检索。 本文重在讲思路。 代码示例仅用于说明概念,完整可运行的代码在项目仓库中。
目录
- LLM难言之痛
- RAG 是什么
- 向量:让计算机理解文字的相似
- 分块:切多少才合适
- LlamaIndex 是什么、解决什么问题
- LlamaIndex 核心架构
- LlamaIndex 与 LangChain、LangGraph 的关系
- Agent:不止是问答
- 进步让我快乐
一、LLM难言之痛!
大语言模型(LLM,Large Language Model)很强,但它有一个天然局限:它只知道训练时见过的东西。
你公司有一份内部文档,LLM 不知道; 你的个人笔记,LLM 不知道; 今天的新闻,LLM 不知道; 任何在它训练之后产生的内容,LLM 都不知道。
这就是知识边界问题。
解决方案有几种:
方案 | 原理 | 优点 | 缺点 |
|---|---|---|---|
Fine-tuning(微调) | 把知识"写进"模型参数 | 永久生效 | 成本高,幻觉风险 |
Prompt Engineering | 在提问时塞背景知识 | 简单灵活 | 上下文长度有限 |
RAG | 检索 + 生成,先找再答 | 可更新,幻觉少,可溯源 | 需要索引基础设施 |
RAG(Retrieval-Augmented Generation,检索增强生成) 是目前最主流的方案,也是本文的主角。
二、RAG 是什么
核心思想:让 LLM 先"查资料",再回答。
用户提问:"我们公司的年假政策是什么?"
↓
第一步:检索 —— 在知识库中找到与问题相关的文档片段
↓
第二步:增强 —— 把找到的片段和问题一起拼进 Prompt
↓
第三步:生成 —— LLM 基于这些片段生成答案举一个具体的例子。假设知识库里有一句话:
"公司年假政策:入职满一年享5天年假,满三年享10天,年假不可跨年累计。"
用户问:"入职多久有年假?"
没有 RAG 时: LLM 不知道答案,可能瞎编。
有 RAG 时:
- 系统先检索到上面那句话(语义相关)
- 把这句话和问题一起发给 LLM:「根据以下内容回答:入职多久有年假?」
- LLM 只能基于这句话回答:「入职满一年即享5天年假」
这样做有三个好处:
- 答案可溯源 — 用户能知道答案来自哪份文档
- 不会凭空编造 — LLM 只基于检索到的真实内容回答
- 知识可更新 — 换一批文档,不需要重新训练模型
三、向量:让计算机理解文字的"相似"
RAG 的第一步是「检索」,关键是找到"语义相似"的内容。这里引入一个关键概念:向量(Embedding)。
什么是向量?
向量本质上就是一串数字。例如:
"苹果" → [0.12, -0.34, 0.78, 0.05, ...] (384维)
"水果" → [0.15, -0.30, 0.82, 0.02, ...]
"手机" → [-0.45, 0.22, 0.10, 0.67, ...]这三段文字背后是一个384维的向量空间。关键是:语义相近的文字,在向量空间中距离更近。
向量空间示意图(简化到2维):
水果 🍎
● "苹果"
● "水果"
● "手机" "iPhone"
电脑 💻
"苹果"和"水果"向量距离近 → 语义相关
"手机"和"iPhone"向量距离近 → 同属科技领域
"苹果"和"手机"距离远 → 语义无关把文字转成向量的模型叫 Embedding 模型。不同的模型产出的向量维度不同(常见 384、768、1536 维),维度越高,理论上能表达的语义越精细。
为什么向量检索比关键词检索更好?
传统搜索靠"关键词匹配"——搜索「年假」,只返回含"年假"字样的文档。
但人有无数种表达方式:
- "入职多久可以休假?"
- "工作满一年有没有假期?"
- "第一年假有几天?"
这些都不含"年假"二字,关键词检索全部漏掉。
向量检索靠语义理解: 上面三句话和问题「入职多久有年假」在向量空间中距离都很近,系统能把它们全部检索回来——不管用的是"年假"、"休假"还是"假期"。
四、分块:切多少才合适
检索的基本单位不是「文档」,而是块(Chunk)。
为什么要切?因为:
- LLM 上下文长度有限 — 不可能把整本书塞进一个 Prompt
- 检索精度 — 如果把所有内容混在一起,检索回来的上下文会包含大量无关信息,LLM 容易被干扰
- 成本控制 — Token 按量计费,上下文越长,费用越高
分块大小的选择
chunk_size 太小(比如50字):
❌ 块太小,上下文不完整,答案残缺
✅ 适合:精确短问答、FAQ
chunk_size 太大(比如2000字):
❌ 块太大,无关内容多,LLM 容易被干扰,费用高
✅ 适合:需要全局上下文的长文档总结
chunk_size 适中(512字):
✅ 平衡精度和完整性,适合大多数场景相邻块之间的重叠
分块时通常设置 chunk_overlap(重叠字数),例如 50 字。
[块1: 0-512字] ←50字重叠→ [块2: 462-974字]这样做的原因是:一条重要信息如果恰好被切在边界上,单块检索会漏掉。 重叠确保边界附近的内容在两个块里都有。
五、LlamaIndex 是什么、解决什么问题
RAG 的完整技术流程如下:
【索引阶段】(离线,一次性的)
文档加载 → 文本分割(Chunk) → 向量化 → 存入向量数据库
【查询阶段】(在线,每次查询都执行)
用户问题 → 向量化 → 在向量库中搜索最相似的K个块 → 拼进Prompt → LLM生成答案从零实现这套流程,你需要:
- 找一个 Embedding 模型,理解它的 API
- 找一个向量数据库(Milvus、Pinecone、Chroma……),理解怎么存怎么查
- 写分块逻辑,处理各种文档格式
- 写 Prompt 拼接,处理上下文溢出
- 写检索逻辑,处理相关性排序
LlamaIndex 把这些全部封装好了。 你不需要关心向量数据库的细节,不需要手写分块算法,不需要拼接 Prompt——LlamaIndex 提供了开箱即用的组件,你只需要把业务数据接进去。
六、LlamaIndex 核心架构
LlamaIndex 的设计哲学是「数据优先」:一切从你的文档出发,帮你把数据变成可查询的索引,再把索引变成可交互的应用。
整体架构分三层:
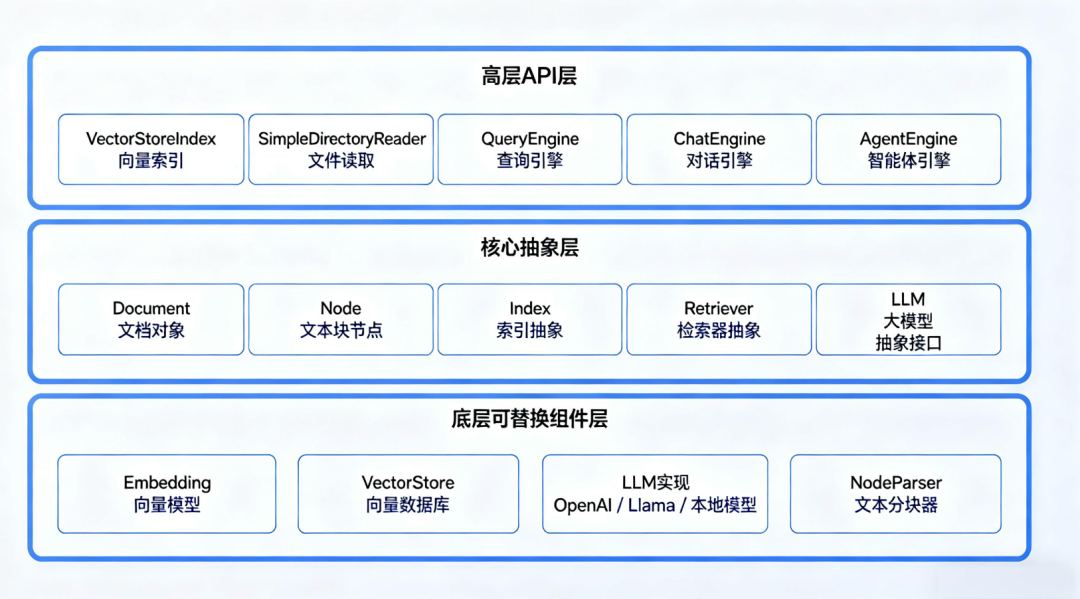
三层分别做什么
底层(可自由替换的零件):
组件 | 作用 | 可替换为 |
|---|---|---|
Embedding | 把文字转成向量 | OpenAI Embedding、本地 sentence-transformers、任何兼容模型 |
VectorStore | 存储和检索向量 | Chroma、Milvus、Pinecone、Weaviate |
LLM | 生成答案 | DeepSeek、GPT-4、Claude、本地模型 |
NodeParser | 分块策略 | 按句子、按段落、按 Token、语义感知分块 |
核心层(LlamaIndex 自己的抽象):
这些是 LlamaIndex 定义的核心概念,不依赖任何具体实现:
Document:原始文档(文本 + 元数据)Node:被切分后的块,包含原始文本和元信息Index:索引结构(最常用的是VectorStoreIndex)Retriever:从索引中检索相关节点的策略QueryEngine:完整查询流程(检索 → 拼接 → 生成)
高层 API(一行代码上手):
LlamaIndex 封装了从加载到查询的完整流程,三行代码就能跑起来:
documents = SimpleDirectoryReader("./data").load_data()
index = VectorStoreIndex.from_documents(documents)
response = index.as_query_engine().query("文档里讲了什么?")为什么分层设计很重要?
因为不同的业务场景需要不同的零件组合:
- 文档量小(< 1万篇)→ 用内存索引,不需要向量数据库
- 文档量大(> 100万篇)→ 换 Chroma / Milvus 做持久化存储
- 需要中文语义好 → 换中文 Embedding 模型(text2vec、BGE)
- 需要多模态(图片 + 文字)→ 换多模态 Embedding
LlamaIndex 的分层让你可以只替换需要换的那个零件,不用重写整个系统。
七、LlamaIndex 与 LangChain、LangGraph 的关系
这是初学者最容易混淆的三件工具,放在一起对比:
LlamaIndex | LangChain | LangGraph | |
|---|---|---|---|
定位 | 数据框架 | 应用开发框架 | 工作流编排框架 |
核心问题 | "如何让 LLM 用我的数据?" | "如何用 LLM 构建应用?" | "如何编排多步骤复杂流程?" |
设计哲学 | 数据优先,从文档出发 | 链式组合,模块化 | 图结构,显式流程控制 |
擅长场景 | RAG、知识库问答 | LLM + 工具 + 记忆的组合应用 | Agent 长期记忆、多轮推理链路 |
学习曲线 | 中等,专注一个领域 | 高,概念多 | 高,概念新 |
形象比喻
- LlamaIndex:一本厚厚的《数据接入手册》——专门讲怎么把你的数据接进来、索引好、查询出去
- LangChain:一个"乐高工具箱"——LLM、工具、记忆、提示词,你能想到的组件全有,但需要自己搭
- LangGraph:一张"流程图"——适合 Agent 这种需要多步骤、有分支、会循环的任务
实际选择
需求 | 推荐 |
|---|---|
纯 RAG / 文档问答 | LlamaIndex ✅ |
LLM + 外部 API 调用 + 记忆 | LangChain |
Agent 多步推理 + 长期记忆 | LangGraph |
RAG + 多个工具调用 | LlamaIndex(做 RAG)+ LangChain(做工具链) |
RAG + 多步复杂推理 | LlamaIndex + LangGraph |
关键结论: 三个框架不是互斥的。LlamaIndex 专注「数据 → 索引 → 检索」这一环,是 RAG 场景的首选。如果你的需求超出 RAG 范围,再引入 LangChain 或 LangGraph。
八、Agent:不止是问答
RAG 是「问答」,Agent 是「任务执行」。
两者核心区别在于:Agent 有工具调用能力,LLM 可以自主决定调用哪些工具。
按照Harness Engineering的方法论:LLM是骑手,Agent是马,Harness就是马鞍、缰绳和围栏。没有Harness,马也会跑,但跑哪去不确定。 为什么? 模型(LLM)= 骑手有脑子、会思考、会决策,但不会自己跑、不会自己干活,需要载体。 Agent = 马能跑、能执行、能行动,是真正干活的主体。Agent 就是 “会动的智能体”,有目标、有行动、有记忆、有工具。 Harness = 马鞍 + 缰绳 + 围栏用来约束、控制、引导、保护 Agent,不让它乱跑、发疯、掉坑、乱花钱
Agent 怎么工作的?
用户:"帮我查一下年假政策,然后把剩余天数填到表格里"
LLM 分析任务 → 发现需要两个步骤
步骤1:调用"文档搜索"工具 → 得到年假政策
步骤2:调用"写表格"工具 → 执行写入
LLM 整合结果 → 返回最终答案这个「决定调用哪个工具」的过程,叫工具规划(Tool Planning)。LLM 根据用户的输入和它对工具描述的理解,自主选择最合适的工具组合——不需要人工预设流程。
在代码中,工具只是一个带 docstring 的函数:
def search_documents(query: str) -> str:
"""
搜索公司知识库中的相关文档。
Args:
query: 搜索关键词或问题
Returns:
相关文档内容片段
"""
...LLM 靠这个 docstring 理解工具能做什么。Docstring 写得越清楚,工具调用越准确。
为什么 Agent 比 RAG 更灵活?
RAG 的流程是固定的:检索 → 生成 → 返回。
Agent 可以:
- 把一个复杂问题拆成多个子任务
- 根据中间结果决定下一步做什么
- 组合使用多个工具(搜索 + 计算 + 查天气 + 写文件……)
- 记住对话历史,支持多轮对话
九、进阶
到这,你是不是对RAG的完整链条有了体感?
文档 → 分块 → 向量化 → 存入索引
用户提问 → 向量化 → 检索最相似块 → 拼Prompt → LLM生成答案以及 LlamaIndex 在其中的位置:它负责把上面这套流程封装成可组合的组件,让你不用从零造轮子。
带着这些理解去读项目源码,你会发现自己不再是被代码牵着走,而是主动知道每个模块在流程中对应什么。
推荐的学习顺序:
- 先理解本文的流程图(不要急着看代码)
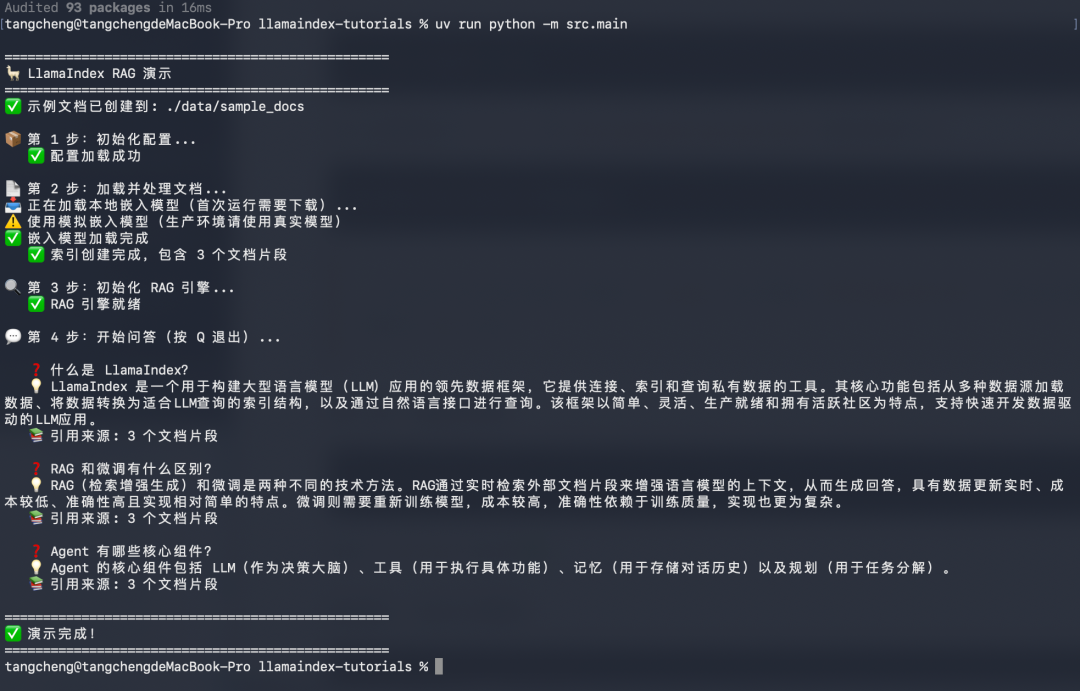
- Clone 项目,跑通
src/main.py,看输出 - 对照 README 的「文件结构」,一个模块一个模块读
- 尝试修改参数观察变化(如
chunk_size、top_k) - 换成自己的文档,体验真实效果
完整可运行的代码见项目仓库:
https://github.com/helloworldtang/llamaindex-tutorials
相关资料:
https://github.com/run-llama/llama_index
https://developers.llamaindex.ai/python/framework/#introduction
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-12,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号