Claude Code 是怎么跑起来的:从 Agent Loop 理解代理循环实现

Claude Code 是怎么跑起来的:从 Agent Loop 理解代理循环实现

CandyTong
发布于 2026-04-14 19:49:44
发布于 2026-04-14 19:49:44
如果你已经会调用大模型、也知道 tool calling 和 agent 的基本概念,那接下来最值得看的问题通常不是“怎么再包一层 prompt”,而是:一个真正能跑任务的 agent,到底是怎么在代码里运转起来的
这篇文章不从抽象定义讲起,而是直接从 Claude Code 的实现思路切入,拆解它最核心的一条执行主线:Agent Loop。
1. 什么是 Agent Loop
一句话:Agent Loop 是让模型从“一次回答”升级为“持续决策系统”的控制循环。
你可以把它理解成一个回合制 runtime,每一回合都做同样的事情:
- 1. 读取当前上下文;
- 2. 调用模型生成动作意图;
- 3. 如果有工具调用就执行工具;
- 4. 把工具结果写回上下文;
- 5. 判断是否进入下一回合。
这个循环停止时,系统才真正产出“任务完成态”的结果,而不是中间状态。
2. 最小可用模型:先跑通闭环
先看一个最小版本:
let messages = [userMessage];
while (true) {
const assistant = awaitcallModel(messages);
messages.push(assistant);
const toolUses = extractToolUseBlocks(assistant);
if (toolUses.length === 0) {
break;
}
const toolResults = awaitrunTools(toolUses);
messages.push(...toolResults);
}
returnbuildFinalAnswer(messages);这段代码虽然简单,但已经包含了 agent 的本质:
- • 状态是累积的:不是每次从零思考;
- • 决策是迭代的:不是一轮生成定生死;
- • 外部世界可进入推理链:工具结果会回流给模型。
如果你只能记住一个原则,就是这个: 工具结果不是“展示给用户就完了”,而是“下一轮推理输入”。
3. 真实实现的主流程
在工程实现里,Agent Loop 一般会拆成“外层编排 + 内层循环 + 模型流式适配”三层:
是否Orchestrator(会话编排)Agent Loop(回合循环)Model Stream(流式消息)是否出现 tool_use?执行工具并产出 tool_result结束循环并输出结果这种分层有个明显好处: 你可以在不改核心循环逻辑的前提下,替换模型供应商、切换工具执行策略,或者接入远端会话。
这句话可以拆开理解。
核心循环真正关心的,其实只有几件事:
- 1. 当前消息上下文是什么;
- 2. 这一轮模型产出了什么事件;
- 3. 有没有
tool_use; - 4. 工具结果什么时候回流;
- 5. 当前任务是否应该继续下一轮。
也就是说,Agent Loop 关心的是“控制流程”,而不是某个具体实现细节。
比如:
- • 如果你把底层模型从 Anthropic 换成 OpenAI,只要新的模型适配层仍然能把输出整理成统一的消息事件流,循环本身就不需要重写。
- • 如果你把工具执行从“串行执行”换成“并发执行”或“流式执行”,只要工具结果最终还是按统一格式回到消息链,循环判断逻辑也不用变。
- • 如果你把运行方式从“本地单进程”换成“远端 agent 会话”,只要远端返回的消息还能被还原成同一套 assistant、tool result、status 事件,循环依然可以照常推进。
所以这层设计的关键价值是“隔离变化”:
- • 上层编排器负责会话和运行环境;
- • 中间的 Agent Loop 负责任务推进;
- • 下层适配器负责模型协议、工具协议、远端通信。
这样一来,变化最多的部分被压到了外围,最核心的循环本身反而能保持稳定。
4. 一个回合是怎么结束的:Claude Code 如何做健壮收口
这一节其实只想说明一个核心点:在 Claude Code 里,“这一轮没有新的工具调用了”并不等于“立刻结束”。
真正的逻辑是:
- 1. 先看这一轮是否还需要 follow-up;
- 2. 如果不需要,也不会马上返回;
- 3. 系统会先尝试几条恢复路径;
- 4. 只有恢复都失败了,才真正结束这一轮。
先看续轮判断本身。在 query.ts 里,Claude Code 还是会先根据消息内容里的真实 tool_use 来设置 needsFollowUp:
// query.ts
const toolUseBlocks: ToolUseBlock[] = [];
let needsFollowUp = false;
const msgToolUseBlocks = message.message.content.filter(
content => content.type === 'tool_use',
) as ToolUseBlock[];
if (msgToolUseBlocks.length > 0) {
toolUseBlocks.push(...msgToolUseBlocks);
needsFollowUp = true;
}但关键在后面。Claude Code 的健壮性,不在于它会判断 needsFollowUp,而在于它在 !needsFollowUp 时不会立刻退出,而是先检查“这次能不能修一修再继续跑”。
把这一段抽象后,可以写成下面这样:
// src/query.ts - 简化后的退出/恢复逻辑
if (!needsFollowUp) {
const lastMessage = assistantMessages.at(-1);
// 恢复路径 1: Prompt 太长 -> 尝试上下文折叠
if (isPromptTooLongMessage(lastMessage)) {
const drained = contextCollapse.recoverFromOverflow(messages);
if (drained.committed > 0) {
state.messages = drained.messages;
continue;
}
// 恢复路径 2: 响应式压缩
if (!state.hasAttemptedReactiveCompact) {
const compacted = reactiveCompact(messages);
state.messages = compacted;
state.hasAttemptedReactiveCompact = true;
continue;
}
}
// 恢复路径 3: max_tokens 截断 -> 增加 token 预算
if (lastStopReason === 'max_tokens') {
state.maxOutputTokensOverride = currentLimit * 2;
state.maxOutputTokensRecoveryCount++;
continue;
}
// 真正退出
return { reason: 'end_turn' };
}这段逻辑最值得注意的地方是连续的三个 continue。
它说明 Claude Code 对“结束”这件事的态度不是保守退出,而是优先恢复:
- • 如果是 prompt 太长,先尝试上下文折叠;
- • 折叠不够,再尝试响应式压缩;
- • 如果是输出被 token 上限截断,再提高 token 预算重试;
- • 只有这些恢复路径都走不通,才真正返回
end_turn。
所以这一节真正想表达的就是一句话:
在 Claude Code 里,一个回合结束不是“没工具了就退出”,而是“没工具了之后,先把能恢复的情况恢复掉,恢复不了才结束”。
这就是它和普通 demo 的差别。demo 往往只会判断“继续还是退出”,而 Claude Code 还多做了一层“退出前恢复”,因此在长上下文、输出截断这类真实问题面前,循环不会轻易中断。
5. queryLoop 才是真正的发动机,它的流式输出是“按消息块”推进的
如果说 Agent Loop 的概念骨架是 while (true),那真正让 Claude Code 跑起来的,是 queryLoop 这种“边接收、边判断、边产出”的实现方式。
这里有一个很值得讲清楚的点:Claude Code 的流式,不是很多人想象中的“逐字打印”。它更接近一种“按消息块、按事件块”的流式。
也就是说,系统不是每生成一个字就立刻往外吐一次,而是随着模型流中的事件推进,不断 yield message。
这个差别很重要,因为它直接影响你怎么理解 queryLoop。
5.1 为什么 yield message 就等于流式输出
理解 Claude Code 的流式,最好的方式不是只看一层代码,而是看它怎么“一层一层往外 yield”。
先看里面这一层,也就是 queryLoop。它一边跑 Agent Loop,一边把每轮里从模型拿到的消息往上抛:
// src/query.ts
asyncfunction* queryLoop(
params: QueryParams,
): AsyncGenerator<StreamEvent | Message, Terminal> {
while (true) {
forawait (const message ofqueryModel(
state.messages,
systemPrompt,
tools,
signal,
)) {
yield message;
}
// ---- 步骤 2: 检查是否需要继续 ----
if (!needsFollowUp) {
return { reason: 'end_turn' };
}
// ---- 步骤 3: 执行工具,收集结果 ----
// ---- 步骤 4: 追加工具结果到消息列表 ----
// ---- 步骤 5: 回到步骤 1 ----
state.turnCount++;
}
}这说明第一层流式非常直接:queryModel() 持续产生消息,queryLoop() 就持续 yield message。所以对 queryLoop 来说,流式的本质就是“这轮里有什么消息到达,我就继续往上一层送什么消息”。
再看外面这一层,也就是 QueryEngine。它接收用户输入,把消息放进跨轮次保存的 mutableMessages,然后继续消费内部的 query(),再把内部消息流转成对外消息流:
// src/QueryEngine.ts
exportclassQueryEngine {
// 跨轮次持久化的消息列表 —— 这就是教学版的 messages[]
privatemutableMessages: Message[]
privateabortController: AbortController
privatetotalUsage: NonNullableUsage
// 入口:用户输入进来,响应消息流出去
async *submitMessage(
prompt: string | ContentBlockParam[],
options?: { uuid?: string; isMeta?: boolean },
): AsyncGenerator<SDKMessage, void, unknown> {
// 1. 处理用户输入
const { messages: messagesFromUserInput } = awaitprocessUserInput({...})
this.mutableMessages.push(...messagesFromUserInput)
// 2. 调用核心查询循环
forawait (const message ofquery({
messages: [...this.mutableMessages],
tools: this.tools,
systemPrompt: this.systemPrompt,
...
})) {
// 3. 累积消息并持久化
if (message.type === 'assistant') {
this.mutableMessages.push(message)
yield* normalizeMessage(message)
}
}
}
}这样一来,整条链路就清楚了:
- 1.
queryModel()先在最底层按事件产生消息; - 2.
queryLoop()在每一轮里把这些消息yield出来; - 3.
QueryEngine.submitMessage()再把内部消息流继续yield给外部。
所以 Claude Code 的“流式”本质上不是某一层单独在流,而是异步生成器在层层传递消息。
可以用一张图先把这条链路记住:
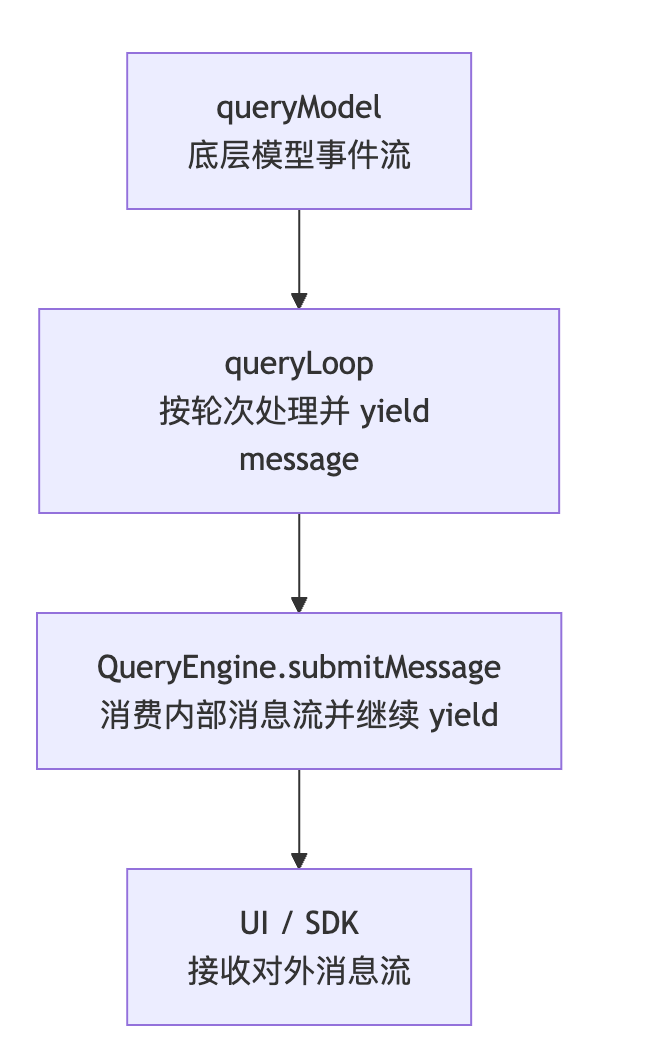
很多人以为“流式”就一定是 token 级别的逐字显示,但 Claude Code 这类 runtime 通常不会直接把最底层 token 流暴露给最外层逻辑。
原因是 runtime 真正要处理的,不只是文本,还有很多结构化信息:
- • assistant message
- • stream event
- • tool use
- • tool result
- • progress
- • status
- • result
这些东西本身就不是“一个字一个字”的概念,而是分段、分块、分事件到达的。
所以更准确地说,Claude Code 的流式是:
- • LLM 底层协议是更细粒度的事件流;
- • 中间层把这些事件整理成可消费的消息块;
- •
queryLoop再把这些消息块持续yield给外层。
这就是为什么你会感觉它是“一段一段出来”,而不是终端里那种纯文本逐字打印。
6. QueryEngine 是外层编排器,它不负责思考,但负责把循环组织起来
理解完 queryLoop 之后,再看 QueryEngine 会更清楚。
queryLoop 是发动机,但发动机本身并不负责整辆车的所有事情。Claude Code 还需要有一个更外层的组件,把会话、消息记录、结果聚合、状态同步这些事情组织起来,这就是 QueryEngine 这类角色存在的意义。
你可以把它理解成“外层编排器”。
它通常不直接决定模型这一轮该不该调工具,也不直接决定工具参数是什么。那些都是 loop 内部和模型共同完成的事情。QueryEngine 更关心的是:
- • 这次查询从哪里开始;
- • 初始消息怎么组装;
- • 流式过程中哪些消息要记录;
- • 哪些中间消息要回放给 UI 或 SDK;
- • 本轮结束后,最终结果应该如何包装返回;
- • 会话级别的 usage、cost、turn count 如何累计。
这件事在源码里也非常直观。QueryEngine 一开始维护的就是一批会话级状态:
// QueryEngine.ts
exportclassQueryEngine {
privatemutableMessages: Message[];
privateabortController: AbortController;
privatepermissionDenials: SDKPermissionDenial[];
privatetotalUsage: NonNullableUsage;
privatereadFileState: FileStateCache;
}进入一次查询之后,它会继续跟踪这次会话的关键统计:
// QueryEngine.ts
let currentMessageUsage: NonNullableUsage = EMPTY_USAGE
let turnCount = 1
let lastStopReason: string | null = null
for await (const message of query({ ... })) {
// 消费 query() 产出的消息,并累计 usage / turn / stop_reason
}最后再把这些状态收束成对外返回的 result:
// QueryEngine.ts
yield {
type: 'result',
subtype: 'error_max_budget_usd',
duration_ms: Date.now() - startTime,
num_turns: turnCount,
stop_reason: lastStopReason,
total_cost_usd: getTotalCost(),
usage: this.totalUsage,
}这里虽然展示的是一个具体错误分支,但它已经足够说明 QueryEngine 的职责:
它负责把 loop 过程中分散产生的状态,最后整理成一个完整、统一、可返回的结果对象。
也就是说,QueryEngine 解决的是“这一整次交互怎么被托管”,而 queryLoop 解决的是“这一轮又一轮怎么往前跑”。
6.1 为什么要有这一层
如果没有 QueryEngine 这一层,很多原本应该属于“会话级”的工作,就会被硬塞进 loop 里,比如:
- • transcript 持久化;
- • 历史消息回放;
- • result 聚合;
- • session 级别统计;
- • UI/SDK 的输出适配。
这样一来,queryLoop 会越来越胖,最后既要管控制流,又要管存储,又要管展示,维护成本会非常高。
把 QueryEngine 单独拉出来之后,职责边界就清楚了:
- •
QueryEngine负责托管整次查询; - •
queryLoop负责推进 agent 回合; - • 更底层的 model adapter 负责协议流;
- • 工具执行器负责工具生命周期。
这正是前面提到的“隔离变化”的具体体现。
7. 结语
如果只用一句话总结这篇文章,我会说:Claude Code 的 Agent Loop,本质上是一套围绕“消息流”组织起来的运行时。
前面几节其实都在说明这件事,只是从不同层次切进去:
- • 在第 4 节里,我们看到一个回合并不是“没工具了就退出”,而是会先尝试恢复,恢复不了才真正结束;
- • 在第 5 节里,我们看到所谓流式输出,并不是单层函数在打印文本,而是
queryLoop和QueryEngine两层异步生成器在层层yield; - • 在第 6 节里,我们又看到
QueryEngine如何把这些分散的中间状态组织成一整次可托管、可返回的查询过程。
把这些点连起来看,Claude Code 其实回答了一个很实际的问题:
一个 agent 为什么能持续跑下去,而且还能在复杂情况下不轻易跑崩?
答案不是“它 prompt 写得更好”,而是它把消息、回合、恢复和对外输出组织成了一套清晰的 runtime 结构。
所以读完这篇文章之后,最值得带走的并不是某个具体函数名,而是这条主线:
- 1.
queryLoop负责把一轮一轮的 agent 行为跑起来; - 2.
QueryEngine负责把这套循环托管成一次完整交互; - 3. 整个系统通过消息流把模型输出、工具结果和最终结果串成同一条链路。
当你理解了这一点,再回头看 Claude Code,就会发现它真正厉害的地方,不是“会调用工具”,而是它把 agent 的执行过程做成了一个稳定、连续、可恢复的运行时。
如果这篇文章对您有所帮助,可以点赞加收藏👍,您的鼓励是我创作路上的最大的动力
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-01,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号