怎么学好AI?秘诀就一句话!


说实话,我目前对AI的学习也有轻度的焦虑。资料太多、XXXAI的视频推得太多、开源的github项目太多!

如何在这纷繁的知识爆炸的时代才能真正学好AI并能学以致用?我们这期探讨。

秘诀就是一句话:
直接把问题丢给你认为最好的AI!
01

怎么理解?
AI圈的概念:深度学习DeepLearning、工作流Workflow、知识库、Promote、MCP、skills、Agent、Memory、markdown,还有最近的Harness等等。

光是这些概念就要完全了解透,这就需要不少时间。对于我们普通的人来说,大部分是使用者,就是把市场上所有的AI工具和App用好也就够了,完全不用理会上面哪些术语之类的。对话聊天,直接元宝、豆包、千问这些app就可以、深度思考和编程可以直接用chatgpt、Deepseek、zipu、minimax、Kimi等等官网聊天界面......
但如果要在AI时代掌握一些核心技能,当然这些远远不够的。我们之前分享的:别再到处找AI付费课了! 2026年全球7大免费AI课程合集整理,国内可直接访问哦!
尽管有这么多的资料,但是我自己都还来得及完整学习吸收!所以,要真正掌握AI,并学以致用确实是一段长期的过程。
02
即使有秘诀,也还要行动
即使我们今天分享的这个秘诀,实际上所有的学习都是痛苦的。对于我们所有人来说,都是陌生的,也就是最近这三年来突然爆火。不管是政府、高校、企业,还有些超级个体,都在呼吁AI+。
要知道,我们很多人,都是十多年的寒窗苦读出来的!学习AI不也需要这个过程,难得是怎么坚持,一直深入去学习!

我们这里分享的只是个人的一点感受,希望所有的人能掌控AI,而不是被AI掌控!
我们开篇就说,学好AI的秘诀就是把这个问题丢给最好的AI,让他给出详细的学习路线图,并且持之以恒!
我个人的计划也是要走这条路,如果感兴趣的朋友,敬请关注!
03
举例说明
我们这里以Free的方式向Claude进行提问,如下图示:
立马给出了关键的信息:
五大阶段:
- 数学 + Python 基础(1–3月)— 线性代数、微积分、概率统计
- 机器学习核心(3–5月)— 经典算法 + Kaggle 实战
- 深度学习 + PyTorch(5–9月)— Transformer 是重中之重
- 大模型与前沿(9–14月)— LLM 原理、微调、Agent 开发
- 工程化落地(14–18月)— MLOps、部署、开源贡献
三个核心建议:
- 🔑 基础优先:PyTorch + 线性代数打扎实,比追新工具更值钱
- 🔑 动手为王:每个知识点都要有对应代码,不能只看课程
- 🔑 选方向深耕:第四阶段后选应用开发或模型研究,二选一深入,避免浅尝辄止
我把详细的md文档贴这了,大家可以收藏和复制保存:
🤖 AI 系统学习路线图
以 AI 专家视角制定 · 适合零基础到工程落地的完整路径
📌 总览
阶段
名称
周期
目标
第一阶段
数学与编程基础
1–3 个月
打牢地基,消除数学恐惧
第二阶段
机器学习核心
3–5 个月
掌握经典算法与工程实践
第三阶段
深度学习与框架
5–9 个月
神经网络理论 + PyTorch 实战
第四阶段
大模型与前沿方向
9–14 个月
LLM、Agent、多模态等方向
第五阶段
工程化与落地
14–18 个月
MLOps、部署、商业应用
🧱 第一阶段:数学与编程基础(第 1–3 个月)
1.1 数学基础
线性代数(最重要)
向量、矩阵、张量的概念与运算
矩阵乘法、转置、逆矩阵
特征值与特征向量
SVD 分解(理解 PCA、推荐系统的基础)
推荐资源:3Blue1Brown《线性代数的本质》系列(B站有中文版)
微积分与优化
导数、偏导数、链式法则(反向传播的核心!)
梯度下降直觉理解
泰勒展开(理解优化算法)
推荐资源:3Blue1Brown《微积分的本质》
概率与统计
概率分布(高斯、伯努利、泊松)
贝叶斯定理
最大似然估计(MLE)
信息熵与 KL 散度(理解损失函数)
推荐资源:StatQuest with Josh Starmer(YouTube)
⏱ 时间分配:每天 1–1.5 小时,线性代数 > 微积分 > 概率统计
1.2 Python 编程基础
Week 1–2:Python 语法、数据结构、函数、面向对象
Week 3–4:NumPy(矩阵运算)、Pandas(数据处理)
Week 5–6:Matplotlib / Seaborn(数据可视化)
Week 7–8:Jupyter Notebook 工作流、Git 版本控制
必须熟练的库:
numpy — 数值计算
pandas — 数据清洗
matplotlib /
seaborn — 可视化
scikit-learn — 入门机器学习(下一阶段核心)
练手项目:
[ ] 用 Pandas 分析一份 Kaggle 公开数据集(如泰坦尼克号)
[ ] 用 NumPy 手写矩阵乘法,与 PyTorch 结果对比
[ ] 做一个数据可视化仪表盘
⚙️ 第二阶段:机器学习核心(第 3–5 个月)
2.1 核心算法地图
监督学习
├── 回归:线性回归、岭回归、Lasso
├── 分类:逻辑回归、SVM、决策树
├── 集成方法:随机森林、XGBoost、LightGBM ⭐
└── 邻近方法:KNN
无监督学习
├── 聚类:K-Means、DBSCAN、层次聚类
├── 降维:PCA、t-SNE、UMAP
└── 异常检测:Isolation Forest
强化学习(入门了解)
└── Q-Learning、策略梯度基础
2.2 关键概念(必须掌握)
概念
为什么重要
偏差-方差权衡
理解过拟合/欠拟合的本质
交叉验证
正确评估模型性能
特征工程
实战中往往比算法更重要
超参数调优
Grid Search / Bayesian Optimization
数据不平衡处理
SMOTE、类权重调整
2.3 推荐学习路径
课程:吴恩达《机器学习》(Coursera,必刷经典)
教材:《Hands-On Machine Learning》(Aurélien Géron,有中文版)
实战:每个算法都在 Kaggle 上找一个对应比赛练手
里程碑项目:
[ ] 完整做完一个 Kaggle 结构化数据竞赛(前 30% 为目标)
[ ] 用 XGBoost 做一个房价预测,撰写完整分析报告
🧠 第三阶段:深度学习与框架(第 5–9 个月)
3.1 神经网络理论
基础架构
├── 全连接网络(MLP)
├── 激活函数:ReLU、Sigmoid、GELU
├── 反向传播(手推一遍!)
└── Batch Normalization、Dropout、残差连接
计算机视觉(CV)
├── CNN 卷积神经网络
├── 经典架构:ResNet、VGG、EfficientNet
└── 目标检测:YOLO 系列、Faster R-CNN
自然语言处理(NLP)
├── Word Embedding:Word2Vec、GloVe
├── RNN / LSTM / GRU
├── Attention 机制 ⭐⭐⭐
└── Transformer 架构(现代 AI 的基石)
3.2 PyTorch 实战路线
# 第 1 步:张量操作与自动求导
# 第 2 步:Dataset / DataLoader 数据管道
# 第 3 步:nn.Module 构建自定义模型
# 第 4 步:训练循环(train/eval/loss/optimizer)
# 第 5 步:模型保存、加载、断点续训
# 第 6 步:使用 GPU(CUDA)加速训练
# 第 7 步:TorchVision / TorchText 生态
💡 专家建议:优先深度掌握 PyTorch,TensorFlow 了解即可。工业界 PyTorch 占主导。
3.3 推荐课程
课程
平台
特点
吴恩达《深度学习专项》
Coursera
理论扎实,适合入门
Fast.ai
fast.ai
自顶向下,快速上手
CS231n(斯坦福)
YouTube
CV 方向权威课程
CS224n(斯坦福)
YouTube
NLP 方向权威课程
里程碑项目:
[ ] 从零实现一个 Transformer(不调包)
[ ] 训练一个图像分类模型(ImageNet 子集,Top-5 准确率 > 85%)
[ ] 做一个文本情感分析项目并部署为 API
🚀 第四阶段:大模型与前沿方向(第 9–14 个月)
4.1 大语言模型(LLM)核心
理论基础
├── GPT 系列架构(Decoder-only Transformer)
├── BERT 系列(Encoder-only,双向注意力)
├── T5 / BART(Encoder-Decoder)
└── Scaling Laws(模型规模与性能的关系)
训练技术
├── 预训练(Pretraining)
├── 监督微调(SFT)
├── 人类反馈强化学习(RLHF)
└── DPO / PPO 对齐方法
高效训练与推理
├── LoRA / QLoRA(低秩适配微调)⭐
├── 量化(INT8 / INT4)
├── FlashAttention
└── vLLM / TensorRT-LLM(推理加速)
4.2 实践方向选择(二选一深耕)
方向 A:应用开发(工程导向)
LangChain / LlamaIndex → RAG 系统构建
→ Agent 开发(Tool Use、ReAct 框架)
→ 多模态应用(GPT-4V、Claude、Gemini API)
→ Prompt Engineering 工程化
方向 B:模型研究(研究导向)
精读论文:Attention Is All You Need / GPT 系列 / LLaMA
→ 在 HuggingFace 上微调开源模型(LLaMA 3、Qwen、Mistral)
→ 参与开源项目贡献
→ 复现 SOTA 论文结果
4.3 前沿方向概览
方向
代表工作
入门建议
多模态
GPT-4o、LLaVA、Stable Diffusion
先做图文理解任务
AI Agent
AutoGPT、Claude Agent
LangChain + Tool Use
代码生成
Copilot、CodeLlama
参与 HumanEval 基准
具身智能
RT-2、OpenVLA
了解 ROS 基础
科学 AI
AlphaFold、AlphaGeometry
选择垂直领域深耕
必读论文清单:
[ ] Attention Is All You Need(2017)
[ ] BERT(2018)
[ ] GPT-3(2020)
[ ] InstructGPT(2022)
[ ] LLaMA 系列(2023–2024)
[ ] Chain-of-Thought Prompting(2022)
🏭 第五阶段:工程化与落地(第 14–18 个月)
5.1 MLOps 体系
数据管理
└── DVC(数据版本控制)、Feature Store
实验管理
└── MLflow、Weights & Biases(wandb)
模型部署
├── FastAPI / Flask 封装推理服务
├── Docker 容器化
├── Kubernetes 集群调度(入门)
└── 云平台:AWS SageMaker / 阿里云 PAI / Google Vertex AI
监控与维护
├── 模型漂移检测
├── A/B 测试框架
└── 数据质量监控
5.2 系统设计能力
高并发推理服务设计(QPS 优化)
向量数据库选型(Milvus、Weaviate、Pinecone)
RAG 系统架构(检索 + 生成)
模型压缩与边缘部署
5.3 软实力建设
写作:在技术博客(知乎 / Medium / 掘金)持续输出
开源:在 GitHub 维护至少一个有影响力的 AI 项目
社区:参与 Kaggle 竞赛、HuggingFace 贡献
论文:养成每周精读 1–2 篇 ArXiv 论文的习惯
📅 18 个月时间表(精简版)
Month 1–2 :Python 熟练 + 数学补充
Month 3 :机器学习入门(吴恩达 ML 课)
Month 4–5 :Sklearn 实战 + Kaggle 第一个竞赛
Month 6–7 :PyTorch 入门 + CNN/RNN 基础
Month 8–9 :Transformer 精读 + NLP 项目
Month 10–11 :LLM 原理 + HuggingFace 微调实践
Month 12–13 :选方向(应用/研究)深耕
Month 14–15 :MLOps + 完整项目端到端部署
Month 16–18 :开源贡献 / 论文投稿 / 求职准备
🛠 工具与资源清单
必备工具
开发环境:VS Code + Jupyter Lab + Conda
GPU 资源:Google Colab(免费)→ AutoDL / 阿里云(付费)
版本控制:Git + GitHub
论文阅读:Semantic Scholar、ArXiv、Paper With Code
推荐学习平台
平台
特点
Coursera(吴恩达系列)
系统课程,证书认可度高
fast.ai
工程实践导向,免费
HuggingFace Learn
LLM / NLP 最新实践
Kaggle Learn
免费短课 + 直接练手
李沐《动手学深度学习》
中文友好,代码详尽
⚠️ 常见误区与专家建议
误区 1:工具学太多,基础打太少
✅ 建议:先把线性代数和 PyTorch 吃透,框架可以快速切换
误区 2:只看课程不动手
✅ 建议:每个概念都要有对应的代码实现,边学边写
误区 3:追新论文但没有深度
✅ 建议:精读 10 篇经典 > 泛读 100 篇新论文
误区 4:忽视工程能力
✅ 建议:模型能跑不算完,能部署、能监控才是真本事
误区 5:单打独斗
✅ 建议:加入学习群、参与开源、找 mentor,进步速度翻倍
🎯 阶段性验收标准
3 个月:能独立完成一个 Kaggle 结构化数据项目
6 个月:能复现一篇经典 CV/NLP 论文
12 个月:能微调并部署一个开源 LLM(如 Qwen / LLaMA)
18 个月:具备独立承担 AI 工程项目的能力,可以求职 AI Engineer 或 MLE
路线图版本:2025 年版 · 持续更新中
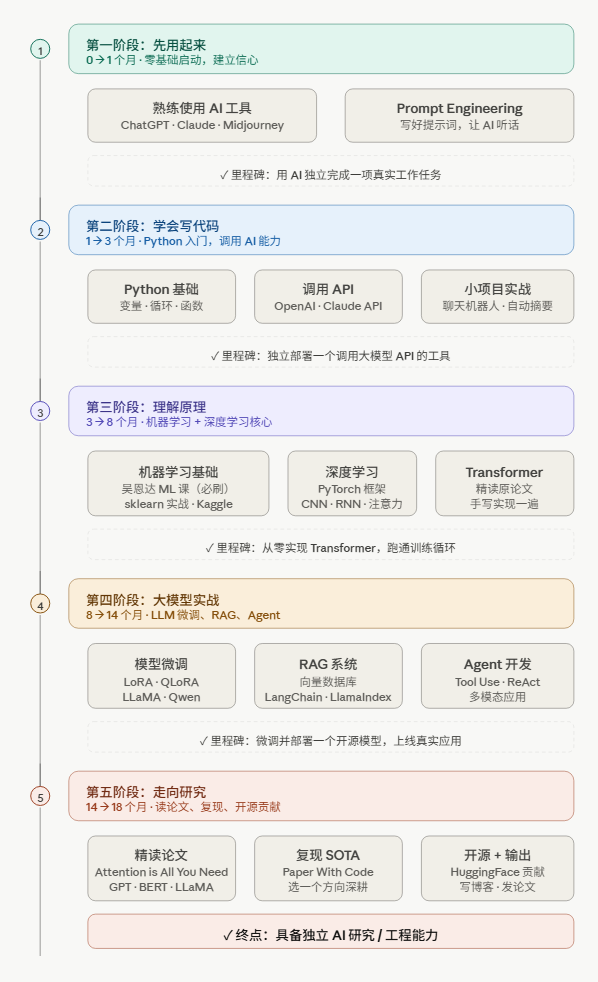
建议配合 Paper With Code 跟踪最新 SOTA要是觉得这份太复杂了,可以按照下面路线图进行:
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-10,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号