如果古法编程岗位消失了,我们还能干什么?我做了一张技能迁移表

如果古法编程岗位消失了,我们还能干什么?我做了一张技能迁移表

苏三说技术
发布于 2026-04-14 21:46:19
发布于 2026-04-14 21:46:19
随着 AI 越来越火爆,很多开发者会有这样的疑问:"我传统研发做了七八年,这些经验在 AI 时代还有没有用?"
这个问题我也有过。两年前我转 AI 开发的时候,也带着同样的顾虑。今天这篇文章,给你一个明确的答案。
读完,你会知道:自己现在站在哪里,从事 AI 开发差的是哪里,接下来该做什么。
一、迥然不同的行情
上个月,一个在某头部电商的朋友跟我说,他们组从 8 个人缩到了 3 个,有裁员的,也有合同到期不续签的。
这两年很多大小厂陆续在收缩传统研发团队,业务系统的核心功能基本稳定了,用不了那么多人持续开发了。
与此同时,AI 工程师的招聘需求却在爆发。
不只是大模型公司,国内的内容、电商、金融、医疗行业,只要业务跟 "内容 + 用户" 沾边,都在招能落地 AI 应用的工程师。
这里藏着一个让很多传统研发工程师陷入焦虑的误判:
"AI 开发是全新的领域,我要从零学起。"
事实上,这是一种错误的想法!
二、AI 工程师到底在干什么
我已经转型 AI 开发两年了,根据这两年学习的技能,整理了一张 传统研发工程师和 AI 工程师的技能对照表 。
在看迁移表之前,先花两分钟搞清楚一件事:AI 工程师每天的工作,到底是什么 ?
很多人一听 "AI 工程师",脑子里浮现的是:好像很复杂啊,是不是要研究算法,搞推导损失函数、GPU 集群什么的……非也,那叫模型研究员 ,不是 AI 应用工程师。
模型研究员和 AI 应用工程师这两个岗位的关系,就像 Linux 系统开发和应用开发者的关系:
- Linux 系统开发者负责设计操作系统、优化底层性能,做的是底层那层的事。
- 应用开发者调用系统提供的 API,写业务逻辑,做的是上层应用的事
两边互相不需要懂对方的细节。
AI 应用工程师做的,和后者如出一辙:拿 OpenAI、DeepSeek 这些公司训练好的模型,调它们的 API,解决真实业务问题 —— 搭一个企业知识库、做一个智能客服、写一套内容自动生成系统。
我们使用各类成熟开发组件的时候,不需要懂它底层的实现细节。同样的,做 AI 应用,也不需要知道 Transformer 内部怎么运算。
所以说,AI 工程师 = 会写代码 + 知道怎么用好大模型 。
前半部分,是我们已经有的
三、技能迁移对照表:你的传统研发经验值多少
我把自己过往积累的研发技能,逐一对照了 AI 应用工程师实际工作中用到的技能。
按迁移难度分三档:直接复用 / 小幅学习 / 需要新学 。
3.1 这些是能直接复用的
传统研发技能 | 对应 AI 工程师技能 | 备注 |
|---|---|---|
各类网络库 HTTP 调用 | 调用 LLM API(OpenAI / DeepSeek SDK) | 本质都是网络请求,逻辑类似 |
流式数据处理 / 渲染 | SSE 流式响应处理(Stream API) | 一条一条拿数据、一条一条处理 / 显示,处理思路相同 |
请求拦截器 / 中间件 | LLM 调用中间件(日志 / 限流 / 重试) | 请求前后插逻辑,设计模式一模一样 |
应用性能监控 / 异常采集 | LLM 调用链追踪(LangSmith / 自建日志) | 可观测性思路一致,采集对象从应用变成了 AI 调用链 |
3.2 需要小幅学习的
传统研发技能 | 对应 AI 工程师技能 | 迁移说明 |
|---|---|---|
状态管理 / 上下文管理 | 多轮对话上下文管理(Session) | 核心都是 "管好有生命周期的状态",新增 Token 窗口限制的概念 |
后台 / 异步任务调度 | AI 异步任务队列(Celery / Redis Queue) | 任务入队、执行、重试的逻辑如出一辙,换了个运行环境 |
依赖注入 / 服务抽象 | AI 服务抽象层(支持多模型切换) | 抽象接口、注入实现的思路完全一样,用来灵活替换底层大模型 |
关系型数据持久化 | 向量数据库(Chroma / Milvus) | 存取数据的操作方式类似,新增 "向量" 这个概念 |
3.3 需要新学,但没你想象的复杂
需要新学的技能 | 难度 | 一句话说清楚 |
|---|---|---|
Embedding 向量化 | ⭐⭐ | 把一段文字变成一组数字,数字里藏着这段话的语义特征 |
RAG 检索增强生成 | ⭐⭐⭐ | 给大模型开卷考试 —— 考前把参考资料塞进去,让它对着回答 |
Agent 工具调用(Function Calling) | ⭐⭐ | 注册一批工具,让大模型自己决定调哪个、按什么顺序调 |
LangChain / LangGraph 框架 | ⭐⭐⭐ | AI 调用层的通用开发框架,封装了常用操作,不用重复造轮子 |
可以看到,从传统古法研发到 AI 应用开发,直接复用的经验约 60%,小幅学习的大概 20%,真正要新学的只剩 20%。
而那 20%,核心就是三个概念:Embedding、RAG、Agent。
四、需要新学什么,以及转型路上最常踩的坑
先把三个新概念建立认识,快速过一遍。
Embedding(向量化)
你玩过英雄联盟吗?每个英雄都有攻击力、防御力、法力值这几个数字来描述他的特征 —— 两个特征相近的英雄,数字组合也接近。
Embedding 做的是同一件事:把一段文字变成一组数字。"今天天气真好" 和 "今天阳光明媚" 变出来的数字很接近,因为语义相近。"今天天气真好" 和 "我要吃火锅" 就差很多。语义越像,数字越近,这就是语义搜索的原理。
实际 AI 业务里,向量化不仅仅用在 RAG,还会用于特征提取、搜推等场景。
RAG(检索增强生成)
不论大模型怎么发展,业务私有的知识它始终无法感知。一旦要用到内部知识,就需要用到 RAG 。
它把闭卷考试改成开卷:用户问问题之前,先去资料库里搜出相关内容,把它一起塞给大模型,让它对着这些资料回答。
这就是为什么做企业知识库、智能客服、私有数据问答,都离不开 RAG。
Agent(智能体)
在 AI Native 组织的终极形态里,一定是 AI Agent 作为执行任务的主题。
很多公司已经明确了未来的岗位,基本就两类:做智能体的和用智能体的。
Agent 其实也不复杂,以前是我们代码里写死执行路径,尔 Agent 是让大模型来决定执行路径。
好,这是要学习的几个点的基本概念。
下面说三个转型 AI 开发常踩的坑。
坑一:以为会写 Prompt 就等于会做 AI 开发
Prompt 只是 AI 应用开发的一小部分。
会写 Prompt,你只是能用好 ChatGPT。但企业里的 AI 系统,要处理上下文截断、要对接私有数据、要保证稳定性和线上可观测性 —— 这些都需要写代码解决,不是调整几句 Prompt 能搞定的。
坑二:跳过 RAG 直接学 Agent
Agent 是建在 RAG 之上的。很多人觉得 Agent 更高级、更酷,直接去学 LangGraph 多智能体,学到一半发现根本不知道工具的数据从哪来、怎么检索。
正确学习顺序是:LLM API 调用 → 上下文管理 → RAG → Agent 。
按着顺序来才能学的扎实。
坑三:只看教程,不跑真实数据
AI 工程里的大量问题,只有在真实数据面前才会暴露。
我在公司做第一个 RAG 项目的时候,本地测试召回率 90%,信心满满上线。结果切换到真实用户的提问数据,直接掉到 60%。排查了将近两个星期,才把问题收敛到文本分块策略上 —— 用户的问题太口语化,和我们按标准段落切的内容对不上。
这个教训是:不跑真实数据,你不知道自己到底学会了没有。
五、总结
总结一下这篇文章,主要讲了:
- 传统研发工程师转 AI 的迁移成本,比大多数人想象的低 ——60% 的技能可以直接继承,真正需要新学的只有 Embedding / RAG / Agent 编排这三块
- 学习顺序比学什么更重要:LLM API → 上下文管理 → RAG → Agent,一步步来
- Prompt 工程是起点,不是终点;Agent 是高阶,不是入门
- 教程里的 Demo 不算数,上线跑过真实数据才算真正学会
知道了要学什么,接着怎么学呢?
我还有一张学习地图。前面的对照表,就是那张地图的第一页。
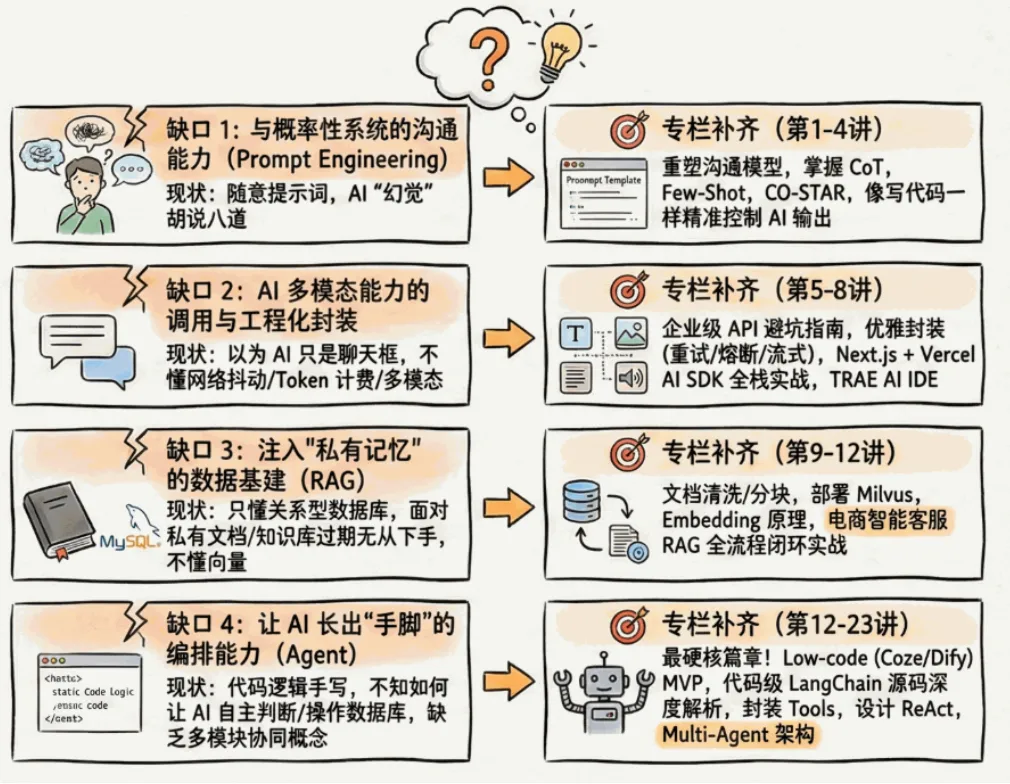
图片
下一步,是把表格右边那一列真正跑通 —— 从调第一个 LLM API,到搭出一个生产级 RAG 系统,到写出能自主决策的 Agent。
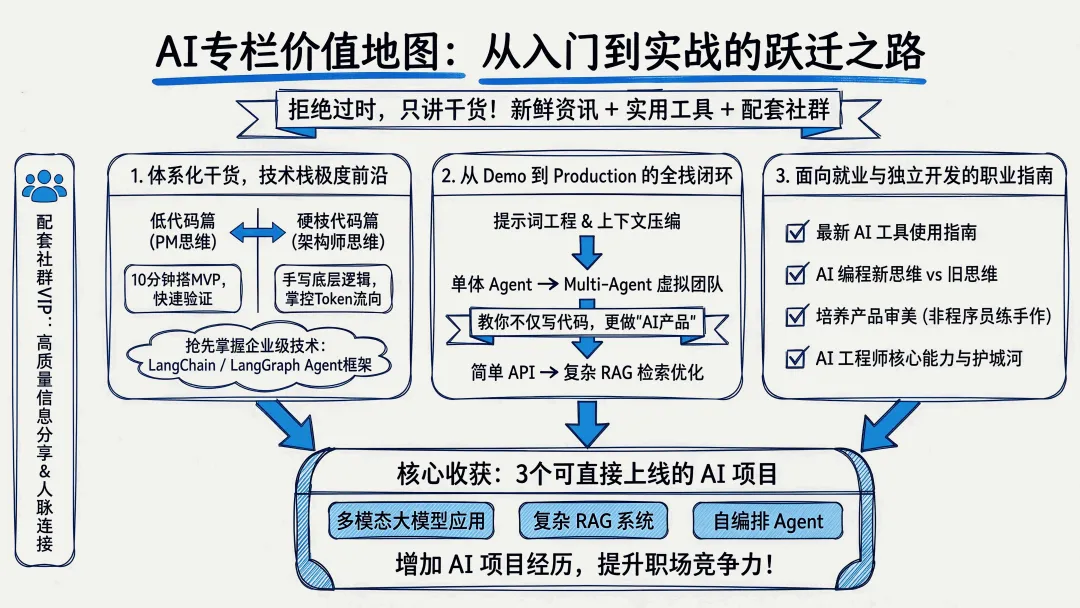
如果你想系统学习 AI 应用开发 ,欢迎看看我在做的 AI 工程师专栏,完整覆盖从 API 调用到 Multi-Agent 的全链路,每一步都有可以直接跑起来的代码和真实项目。
学完你就能得到至少 3 个可以直接上线的 AI 项目,直接丰富你的 AI 项目经历:
- 多模态大模型应用:支持文本聊天、图片 / 视频生成的全功能多模态聊天应用,还自带短期 + 长期记忆功能,是当下最热门的可落地 AI 应用形态
- 复杂 RAG 企业级系统:基于进阶 RAG 技术实现的电商智能客服,用到了本地向量模型、检索重排等生产级技术,完美适配企业私有数据问答场景
- 代码编排 Agent:复刻精简版 Claude Code,能根据你的需求自动生成代码、编排任务执行,掌握当下最前沿的 Agent 落地能力
这些项目全部有完整的可运行代码,跟着做下来,你不仅能学会技术,还能直接拥有拿得出手的 AI 项目经历,帮你节省大量的 AI 学习时间。
摘取几个读者反馈:
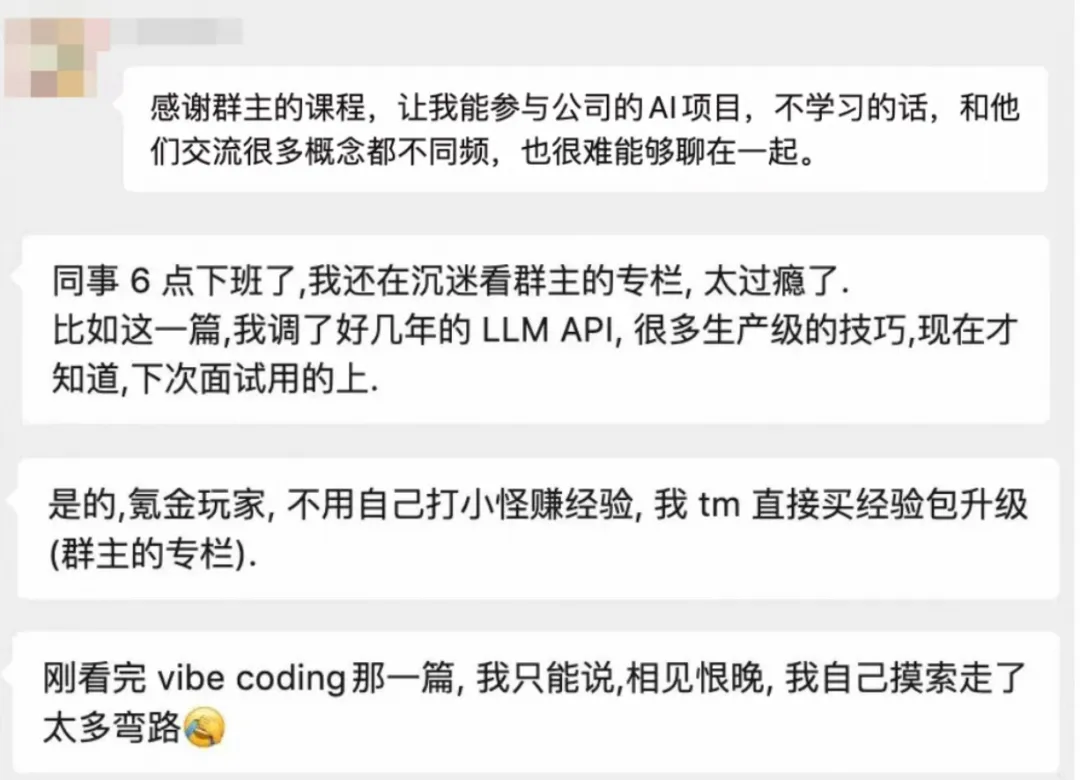
图片
图片
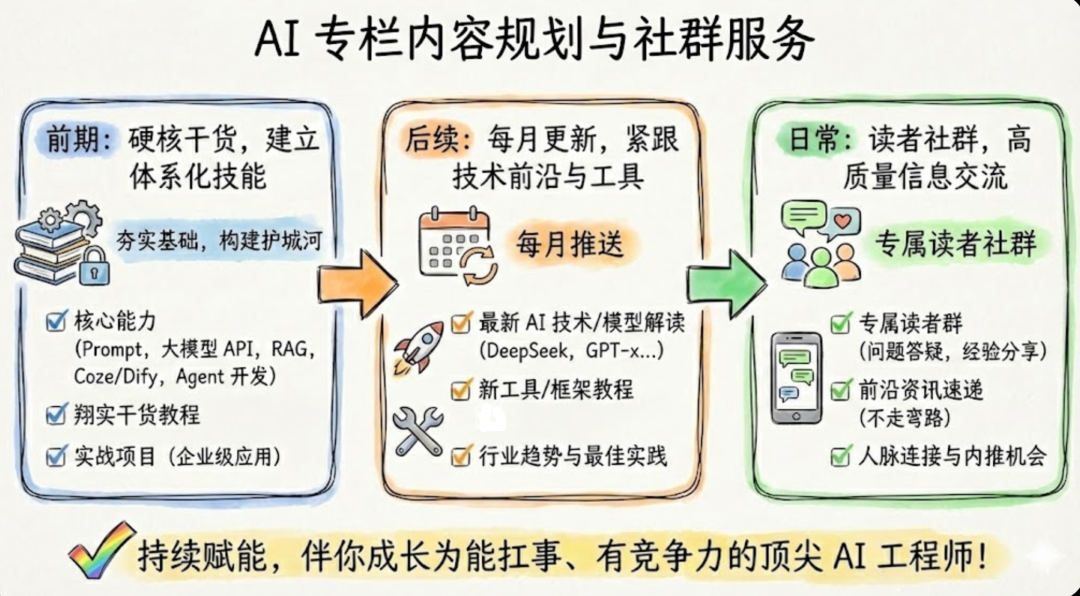
体系化的 AI 技能干货更新完成后,每月更新还会最新 AI 技术发展和工具教程,比如 OpenClaw、HarnessEngineering 等。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-13,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号