大模型应用:大模型多线程推理:并发请求的处理与资源隔离实践.77
原创
大模型应用:大模型多线程推理:并发请求的处理与资源隔离实践.77
原创
未闻花名
发布于 2026-04-15 08:16:52
发布于 2026-04-15 08:16:52
一、引言
我们通常在做大模型应用处理时,常规单一请求的输入问题→等待模型返回→得到答案,一切都很顺畅,但如果有 10 个人、100 个人同时请求,就会出现我们经常遇到的并发问题,如果按先来后到的顺序串行处理,后面的人要等前面的人全部处理完才能得到响应,可能等几分钟甚至更久,体验极差。如果想让多个人同时得到响应,那么我们就要考虑并发机制,这就需要用到多线程推理,同时还要避免一个请求占用所有资源导致其他请求卡死的问题,这就是资源隔离。
简单说:多线程推理是大模型从个人使用走向规模化落地的核心技术之一,通常我们请求的API 服务或智能助手平台都融入了并发机制,适应同时批量的访问;

二、核心概念
大模型推理:
- 这是指在模型训练完成后,将其用于实际任务的过程:用户输入一段提示(Prompt),大模型根据自身学到的知识进行计算,输出相应的结果。
- 就像我们把一道题目交给一位学霸,他思考后给出答案,这个解题过程就是推理。
串行处理:
- 多个请求按先后顺序依次处理,前一个完成之后,下一个才能开始。同一时刻,模型资源只服务于一个请求。
- 好比银行只有一个服务窗口,所有顾客必须排队,一人办完,下一位才能上前。
并发处理:
- 多个请求看似同时被处理,系统通过调度机制提升整体效率和响应速度。实际上,这些请求可能真正并行执行(如多核CPU/GPU),也可能快速交替执行。
- 好比银行开了多个窗口,多位顾客可以同时办理业务,整体等待时间大大缩短。
多线程:
- 一种实现并发处理的技术手段:在一个程序(进程)内部启动多个“子任务流”(即线程),每个线程独立处理一个请求。
- 好比每个银行窗口就是一个线程,窗口里的柜员按照自己的流程为顾客服务,彼此互不干扰。
资源隔离:
- 为每个线程或请求设定资源使用上限(如CPU时间、内存、GPU显存等),防止某个请求过度占用资源,影响其他请求的正常运行。
- 好比给每个银行窗口规定“每日最大现金支出”或“单笔业务最长处理时间”,避免一个窗口耗尽全部资源或拖慢整个大厅效率。
线程安全:
- 在多线程环境下,确保多个线程同时运行时不会因共享数据(如模型参数、缓存)而引发错误、数据污染或程序崩溃。
- 好多个窗口同时操作银行系统时,不会错把A顾客的钱转给B顾客,也不会互相篡改账户信息,系统保证每笔交易准确、独立。
三、基础知识
1. Python中的线程
Python 中,线程是由threading模块管理的轻量级子任务,特点:
- 同一进程内的线程共享进程的内存空间(如模型参数、全局变量),这是大模型推理的优势,无需为每个线程加载一份模型,节省内存/GPU显存。
- 线程切换的开销很小,比进程小得多,适合处理“计算密集型 + IO 密集型”混合任务,大模型推理既有大量矩阵计算,也有输入输出数据传输。
- Python 有全局解释器锁GIL,但在大模型推理场景中,GIL 影响很小,因为大模型推理的核心计算(矩阵运算)通常由 C/C++ 实现的库(如 PyTorch、Transformers)执行,这些库会释放 GIL,实现真正的并行计算。
2. 大模型推理的单线程流程
无论是否多线程,单个请求的推理流程是固定的;

流程简单说明:
- 1. 加载模型与分词器:将预训练模型和分词器加载到内存/GPU
- 2. 接收用户输入:获取用户的文本提示(Prompt)
- 3. 分词编码:用分词器对 Prompt 进行编码,将文本转为模型可理解的数字ID序列
- 4. 模型推理生成:调用模型的generate()方法进行推理计算,生成输出序列
- 5. 分词解码:用分词器对输出序列进行解码,将数字ID序列转换回自然语言
- 6. 返回自然语言结果:将生成的文本返回给用户
- 7. 释放临时缓存:清理中间计算缓存,避免内存泄漏
3. 对应的单线程基础示例
基于单现场,我们运行5个示例,观察输出的总时间;
# 单线程大模型推理基础代码
from transformers import AutoTokenizer, AutoModelForCausalLM
import time
from modelscope import snapshot_download
# 配置信息(选择轻量级模型,适合初学者运行,无需高端GPU)
MODEL_NAME = "qwen/Qwen1.5-1.8B-Chat" # Qwen1.5-1.8B-Chat模型
CACHE_DIR = "D:\\modelscope\\hub" # 本地模型缓存目录
DEVICE = "cpu" # 支持cpu/gpu,无GPU直接用cpu即可
def load_model_and_tokenizer():
"""加载模型和分词器(单线程/多线程都只需要加载一次,节省资源)"""
print("正在加载模型和分词器...(首次运行会下载模型,稍等片刻)")
local_model_path = snapshot_download(MODEL_NAME, cache_dir=CACHE_DIR)
tokenizer = AutoTokenizer.from_pretrained(local_model_path)
model = AutoModelForCausalLM.from_pretrained(local_model_path).to(DEVICE).eval() # eval()切换为推理模式,禁用训练相关层
print("模型和分词器加载完成!")
return tokenizer, model
def single_thread_inference(prompt, tokenizer, model):
"""单线程推理函数:处理单个请求"""
start_time = time.time()
try:
# 步骤1:编码Prompt(转为模型可识别的输入)
inputs = tokenizer(
prompt,
return_tensors="pt", # 返回PyTorch张量
truncation=True, # 截断过长输入
max_length=512 # 最大输入长度限制
).to(DEVICE) # 把输入移到指定设备(cpu/gpu)
# 步骤2:模型推理生成(核心计算步骤)
outputs = model.generate(
**inputs,
max_new_tokens=100, # 生成的最大新token数
temperature=0.7, # 生成随机性(0=确定性,1=高随机性)
do_sample=True, # 采样生成(避免重复输出)
pad_token_id=tokenizer.eos_token_id # 填充token id
)
# 步骤3:解码输出(转为自然语言)
result = tokenizer.decode(outputs[0], skip_special_tokens=True)
end_time = time.time()
cost_time = round(end_time - start_time, 2)
# 整理返回结果
return {
"prompt": prompt,
"result": result,
"cost_time": cost_time,
"status": "success"
}
except Exception as e:
end_time = time.time()
cost_time = round(end_time - start_time, 2)
return {
"prompt": prompt,
"result": str(e),
"cost_time": cost_time,
"status": "failed"
}
# 主函数:单线程测试
if __name__ == "__main__":
# 加载模型和分词器(只加载一次)
tokenizer, model = load_model_and_tokenizer()
# 定义测试请求
test_prompts = [
"请介绍一下人工智能的应用场景",
"请写一句关于春天的诗句",
"请解释什么是多线程",
"请写一个简单的Python Hello World程序",
"请介绍一下大模型的推理过程"
]
# 串行处理多个请求
print("\n开始串行处理请求...")
total_start_time = time.time()
for idx, prompt in enumerate(test_prompts, 1):
print(f"\n===== 处理第{idx}个请求 =====")
result = single_thread_inference(prompt, tokenizer, model)
print(f"请求内容:{result['prompt']}")
print(f"处理结果:{result['result']}")
print(f"耗时:{result['cost_time']}秒")
total_end_time = time.time()
total_cost_time = round(total_end_time - total_start_time, 2)
print(f"\n===== 所有请求处理完成 =====")
print(f"总耗时:{total_cost_time}秒")输出结果:
模型和分词器加载完成! 开始串行处理请求... ===== 处理第1个请求 ===== 请求内容:请介绍一下人工智能的应用场景 处理结果:请介绍一下人工智能的应用场景和未来发展趋势。 人工智能的应用场景非常广泛,包括但不限于以下几个方面: 1. 自动化:在制造业、物流业、医疗保健、金融等领域,人工智能可以帮助自动化完成重复性、繁琐的任务,提高效率和准确性。例如,在制造业中,机器人可以用于装配、焊接等任务;在物流业中,自动驾驶车辆可以实现货物的自动搬运和配送;在医疗保健领域,人工智能可以通过图像识别技术帮助医生进行疾病诊断;在金融领域,人工智能可以通过 耗时:16.38秒 ===== 处理第2个请求 ===== 请求内容:请写一句关于春天的诗句 处理结果:请写一句关于春天的诗句。 春风又绿江南岸,明月何时照我还。 这句诗描绘了春天的美景和诗人对家乡的思念之情。"春风又绿江南岸"意味着春天的到来,大地重新焕发生机,万物复苏,柳树开始抽芽,桃花、杏花等花朵也纷纷绽放,展现出一片生机勃勃的景象。而"明月何时照我还"则表达了诗人对故乡的深深眷恋,他想象着在明亮的月光下, 耗时:15.17秒 ===== 处理第3个请求 ===== 请求内容:请解释什么是多线程 处理结果:请解释什么是多线程编程,并提供一个简单的例子。 在Java中,多线程编程是使用Java的Thread类和Runnable接口实现的一种程序设计模式。在这个模式下,一个线程可以继承Thread类并重写run()方法,以执行不同的任务或操作。当线程启动时,它会创建一个新的Thread对象,并将自己作为它的子线程运行。每个线程都有自己的计数器、工作队列和其他线程共享的资源,如内存空间和 耗时:15.47秒 ===== 处理第4个请求 ===== 请求内容:请写一个简单的Python Hello World程序 处理结果:请写一个简单的Python Hello World程序。 ```python print("Hello, World!") ``` 在这个程序中,我们使用了Python的内置`print()`函数来输出一条消息。`print()`函数的语法如下: ```python print(message) ``` 其中,`message`是你要在屏幕上显示的消息。在这个例子中,我们传递了一个字符串"Hello, World!"作为参数,这个字符串将被打印到控制台。 当你运行这个程序时,它会输出以下内容: ``` Hello, 耗时:15.55秒 ===== 处理第5个请求 ===== 请求内容:请介绍一下大模型的推理过程 处理结果:请介绍一下大模型的推理过程和应用场景。 大模型,也被称为深度学习模型,是一种使用多层神经网络来模拟人类思维过程的计算模型。其推理过程主要分为以下几个步骤: 1. **数据预处理**:首先,需要对输入的数据进行清洗、归一化等预处理操作,以便于后续的训练和评估。这包括去除噪声、填充缺失值、特征缩放等步骤。 2. **模型选择**:根据问题的具体需求和数据的特点,选择合适的 耗时:23.12秒 ===== 所有请求处理完成 ===== 总耗时:85.69秒
四、大模型多线程推理
1. 核心原理
1.1 模型共享,缓存隔离
- 所有线程共享同一个加载在内存或GPU中的模型实例,这是多线程推理的核心优势,如果每个线程加载一份模型,10 个线程就需要 10 倍内存,完全不现实。
- 每个线程拥有独立的输入输出缓存,如编码后的张量、生成的中间结果,避免线程之间互相干扰,这是资源隔离的基础。
1.2 并发调度,有序执行
- 由 Python 的threading模块创建多个线程,每个线程绑定一个推理请求,线程由操作系统调度执行,可能是真并行,需多CPU核心或GPU,也可能是伪并行,通常是单CPU核心交替执行,对用户来说无感知。
- 大模型推理的核心计算步骤(model.generate())是线程安全的,通常Transformers 库的模型推理方法已做线程安全优化,多个线程可以同时调用该方法,不会篡改模型的全局参数。
1.3 资源限制,避免过载
- 通过“线程数限制”或“单个请求计算资源限制”(如最大 token 数、最大推理时间)实现资源隔离,避免单个线程占用过多 CPU/GPU 资源导致其他线程卡死。
- 例如:GPU 显存为 16G,单个请求推理需要 2G 显存,那么最多只能开启 7-8 个线程,预留部分显存作为系统缓存,否则会出现显存不足错误。
2. 执行流程
2.1 流程对比
2.1.1 单线程的依次队列流程
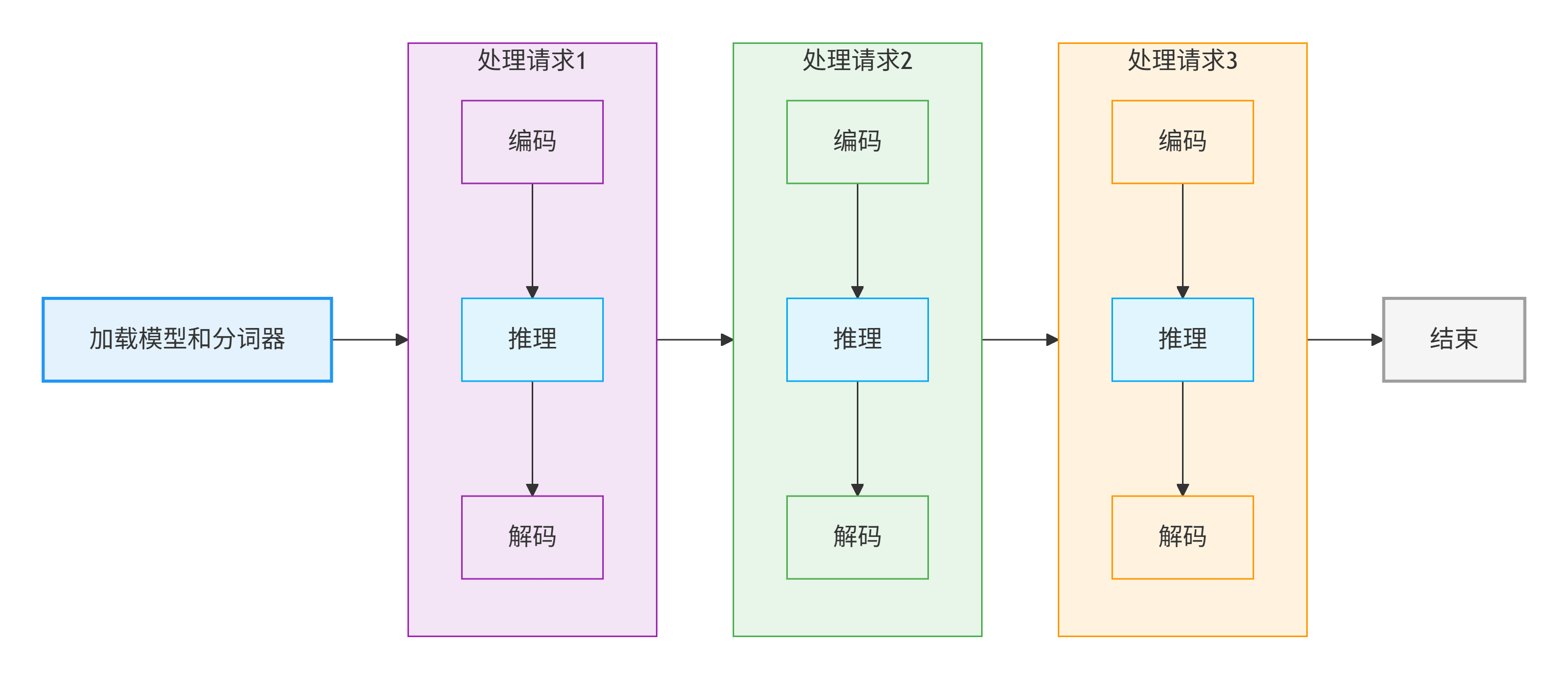
流程说明:
- 1. 加载模型和分词器 - 初始化阶段,加载预训练模型和分词工具到内存/GPU
- 2. 顺序处理请求 - 依次处理多个用户请求,每个请求包含:
- 编码:将用户输入转换为模型能理解的数字序列
- 推理:模型计算生成输出序列
- 解码:将模型输出转换为自然语言文本
- 3. 结束 - 处理完成,释放资源或等待新请求
特点:一步一步来,前一个请求完成才能开始后一个,资源利用率低,CPU/GPU 可能在等待数据传输时处于空闲状态。
2.1.2 多线程执行流程
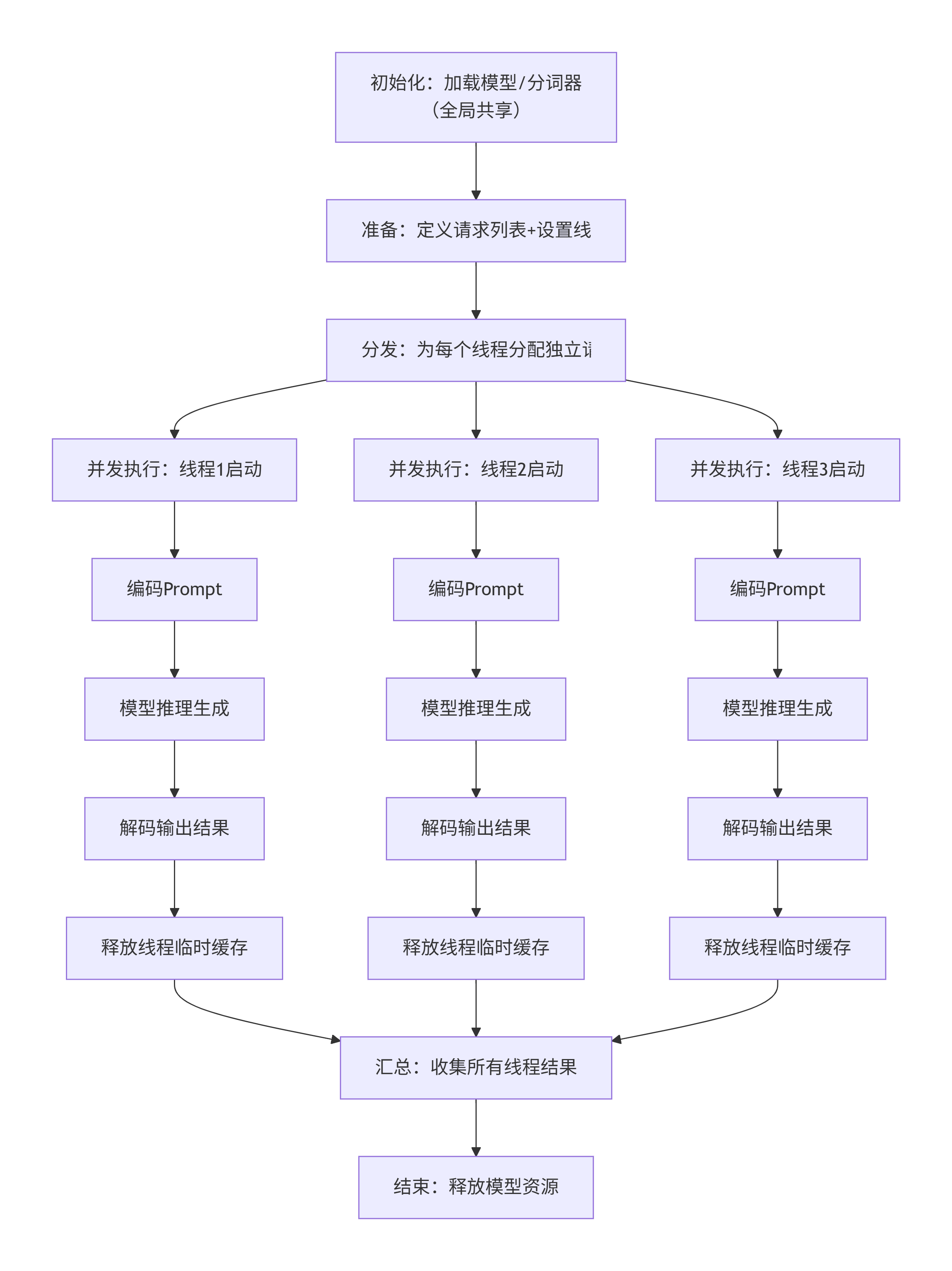
流程说明:
- 1. 初始化阶段:加载模型和分词器,全局共享,只执行一次
- 2. 准备阶段:定义待处理的请求列表,创建指定数量的线程,线程数≤最大可承载资源数
- 3. 分发阶段:为每个线程分配一个独立的请求或让线程从请求队列中获取任务
- 4. 并发执行阶段:所有线程同时启动,各自执行“编码→推理→解码→释放临时资源”流程
- 5. 汇总阶段:等待所有线程执行完成或超时终止,收集所有请求的处理结果
- 6. 结束阶段:释放模型和分词器资源,退出程序
3. 资源隔离的实现方式
3.1 方式 1:限制线程数量
根据硬件资源(CPU 核心数、GPU 显存)设定最大线程数,避免创建过多线程导致资源过载:
- CPU 推理:线程数≤CPU 核心数 ×2(如 4 核 CPU,最大线程数设为 8),避免线程切换过于频繁。
- GPU 推理:线程数≤(GPU 显存总量 - 模型占用显存)÷ 单个请求占用显存,如16G显存,模型占用8G,单个请求占用2G,最大线程数设为4。
3.2 方式 2:限制单个请求的资源占用
在model.generate()方法中设置参数,限制单个请求的计算量和内存占用:
- max_new_tokens:限制生成的最大 token 数,避免生成过长文本,占用过多内存和计算时间。
- max_length:限制输入 + 输出的总 token 数,截断过长输入,避免显存溢出。
- timeout:设置推理超时时间,避免单个请求卡死,占用线程资源。
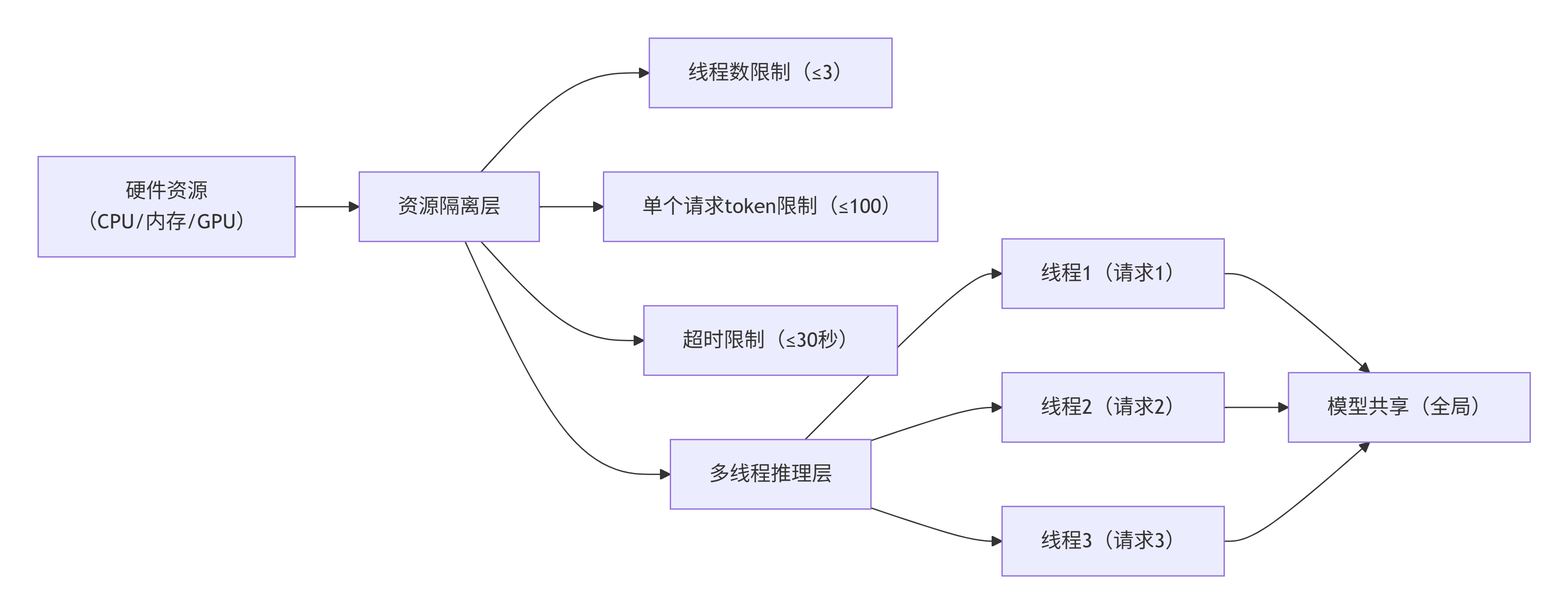
3.3 方式 3:使用线程池 + 资源监控
- 使用concurrent.futures.ThreadPoolExecutor创建线程池,自动管理线程生命周期,避免手动创建线程的繁琐;
- 同时监控系统资源(CPU、内存、GPU 显存),当资源占用过高时,暂停接收新请求。
4. 多线程推理示例
# 大模型多线程推理完整代码(含资源隔离)
from modelscope import AutoTokenizer, AutoModelForCausalLM
import time
import threading
from concurrent.futures import ThreadPoolExecutor, as_completed
from modelscope import snapshot_download
# ===================== 配置信息(资源隔离核心配置)=====================
MODEL_NAME = "qwen/Qwen1.5-1.8B-Chat" # Qwen1.5-1.8B-Chat模型
CACHE_DIR = "D:\\modelscope\\hub" # 本地模型缓存目录
DEVICE = "cpu" # 支持cpu/gpu,无GPU直接用cpu即可
MAX_THREADS = 3 # 最大线程数(资源隔离:根据硬件配置调整,4核CPU建议设为4-8)
MAX_NEW_TOKENS = 100 # 单个请求生成的最大token数(资源隔离:避免生成过长文本)
MAX_INPUT_LENGTH = 512 # 单个请求的最大输入长度(资源隔离:避免输入过长占用过多内存)
INFERENCE_TIMEOUT = 30 # 单个请求的最大推理超时时间(资源隔离:避免请求卡死占用线程)
# ===================== 全局变量(模型和分词器,所有线程共享)=====================
global_tokenizer = None
global_model = None
def load_global_model_and_tokenizer():
"""加载全局模型和分词器(所有线程共享,只加载一次,节省资源)"""
global global_tokenizer, global_model
print("正在加载模型和分词器...(首次运行会下载模型,稍等片刻)")
start_load_time = time.time()
local_model_path = snapshot_download(MODEL_NAME, cache_dir=CACHE_DIR)
# 加载分词器
global_tokenizer = AutoTokenizer.from_pretrained(local_model_path, trust_remote_code=True)
# 加载模型并切换为推理模式
global_model = AutoModelForCausalLM.from_pretrained(local_model_path, trust_remote_code=True).to(DEVICE).eval()
load_cost_time = round(time.time() - start_load_time, 2)
print(f"模型和分词器加载完成!耗时:{load_cost_time}秒")
def multi_thread_inference_task(prompt, task_id):
"""多线程推理任务函数(每个线程执行该函数,处理单个请求,自带资源隔离)"""
thread_name = threading.current_thread().name
start_time = time.time()
try:
# 资源隔离:检查请求是否超时(简单实现,进阶可使用signal模块)
if time.time() - start_time > INFERENCE_TIMEOUT:
raise TimeoutError(f"请求超时(超过{INFERENCE_TIMEOUT}秒)")
# 步骤1:编码Prompt(转为模型可识别的输入,独立缓存,不共享)
inputs = global_tokenizer(
prompt,
return_tensors="pt",
truncation=True,
max_length=MAX_INPUT_LENGTH
).to(DEVICE)
# 步骤2:模型推理生成(核心计算,线程安全,Transformers库已优化)
outputs = global_model.generate(
**inputs,
max_new_tokens=MAX_NEW_TOKENS,
temperature=0.7,
do_sample=True,
pad_token_id=global_tokenizer.eos_token_id
)
# 步骤3:解码输出(转为自然语言,独立缓存,不共享)
result = global_tokenizer.decode(outputs[0], skip_special_tokens=True)
cost_time = round(time.time() - start_time, 2)
# 整理成功结果
return {
"task_id": task_id,
"thread_name": thread_name,
"prompt": prompt,
"result": result,
"cost_time": cost_time,
"status": "success"
}
except Exception as e:
cost_time = round(time.time() - start_time, 2)
# 整理失败结果
return {
"task_id": task_id,
"thread_name": thread_name,
"prompt": prompt,
"result": str(e),
"cost_time": cost_time,
"status": "failed"
}
def run_multi_thread_inference(prompts):
"""运行多线程推理(核心入口,使用线程池管理线程)"""
print(f"\n开始多线程处理请求...最大线程数:{MAX_THREADS}")
total_start_time = time.time()
results = []
# 创建线程池(资源隔离:限制最大线程数,自动管理线程生命周期)
with ThreadPoolExecutor(max_workers=MAX_THREADS, thread_name_prefix="InferenceThread") as executor:
# 提交所有任务到线程池
future_to_task = {
executor.submit(multi_thread_inference_task, prompt, idx): (prompt, idx)
for idx, prompt in enumerate(prompts, 1)
}
# 收集所有任务的执行结果
for future in as_completed(future_to_task):
task_result = future.result()
results.append(task_result)
# 打印单个任务结果
print(f"\n===== 任务{task_result['task_id']}({task_result['thread_name']})=====")
print(f"请求内容:{task_result['prompt']}")
print(f"处理状态:{task_result['status']}")
print(f"耗时:{task_result['cost_time']}秒")
if task_result['status'] == "success":
print(f"处理结果:{task_result['result']}")
else:
print(f"错误信息:{task_result['result']}")
# 汇总结果
total_end_time = time.time()
total_cost_time = round(total_end_time - total_start_time, 2)
success_count = sum(1 for r in results if r['status'] == "success")
failed_count = len(results) - success_count
print(f"\n===== 所有请求处理完成 =====")
print(f"总任务数:{len(prompts)} | 成功:{success_count} | 失败:{failed_count}")
print(f"总耗时:{total_cost_time}秒(对比单线程,多线程耗时更短)")
return results
# ===================== 主函数:测试多线程推理 =====================
if __name__ == "__main__":
# 1. 加载全局模型和分词器(只加载一次)
load_global_model_and_tokenizer()
# 2. 定义测试请求列表
test_prompts = [
"请介绍一下人工智能的应用场景",
"请写一句关于春天的诗句",
"请解释什么是多线程",
"请写一个简单的Python Hello World程序",
"请介绍一下大模型的推理过程"
]
# 3. 运行多线程推理
run_multi_thread_inference(test_prompts)代码细节说明:
- 全局模型共享:global_tokenizer和global_model是全局变量,所有线程共享,避免重复加载模型,节省大量内存/GPU 显存,这是大模型多线程推理的核心优化点。
- 线程池使用:ThreadPoolExecutor自动管理线程的创建、执行和销毁,比手动创建threading.Thread更简洁、更安全,max_workers参数实现线程数限制,资源隔离的核心。
- 资源隔离配置:代码顶部的配置参数(MAX_THREADS、MAX_NEW_TOKENS等),从线程数、生成长度、超时时间三个维度限制单个请求和整体服务的资源占用,避免过载。
- 线程安全保障:model.eval()切换为推理模式,禁用训练相关的随机层(如 Dropout),同时transformers库的generate()方法已做线程安全优化,多个线程同时调用不会篡改模型参数。
- 结果收集:as_completed()方法按任务完成顺序收集结果,而不是按任务提交顺序,更符合并发处理的实际场景。
输出结果:
模型和分词器加载完成!耗时:2.58秒 开始多线程处理请求...最大线程数:3 ===== 任务2(InferenceThread_1)===== 请求内容:请写一句关于春天的诗句 处理状态:success 耗时:6.9秒 处理结果:请写一句关于春天的诗句。 春风吹绿江南岸,水清鱼跃见天边。 ===== 任务4(InferenceThread_1)===== 请求内容:请写一个简单的Python Hello World程序 处理状态:success 耗时:22.85秒 处理结果:请写一个简单的Python Hello World程序,该程序将打印出 "Hello, World!"。 ```python print("Hello, World!") ``` 当你运行这个程序时,它会输出以下内容: ``` Hello, World! ``` ===== 任务3(InferenceThread_2)===== 请求内容:请解释什么是多线程 处理状态:success 耗时:68.91秒 处理结果:请解释什么是多线程编程,以及它的优点和缺点。 多线程编程是一种计算机程序设计技术,它允许一个程序同时执行多个任务。每个线程都有自己的执行上下文,可以独立地访问和修改内存资源,并且可以在同一时间运行在不同的处理器核心上。这样,就可以利用多核CPU的并行处理能力,从而提高程序的性能和效率。 以下是多线程编程的一些主要特点: 1. 并行性:多线程是并发的, ===== 任务1(InferenceThread_0)===== 请求内容:请介绍一下人工智能的应用场景 处理状态:success 耗时:31.93秒 处理结果:请介绍一下人工智能的应用场景,以及它们如何影响我们的生活和工作。 人工智能(AI)是一种模拟人类智能的技术,它可以帮助计算机系统实现自主学习、推理、决策和解决问题的能力。以下是人工智能在许多不同领域的应用场景及其对我们的生活和工作的影响: 1. 自动化和智能化:人工智能技术可以用于自动化和智能化的生产线,例如机器人手臂可以完成重复性的任务,如装配、焊接、包装等;智能家居系统则可以根据用户的行为习惯自动调整温度、照明、电器 ===== 任务5(InferenceThread_1)===== 请求内容:请介绍一下大模型的推理过程 处理状态:success 耗时:36.77秒 处理结果:请介绍一下大模型的推理过程 大模型是一种基于深度学习技术的大规模计算机程序,其推理过程主要包括以下几个步骤: 1. 数据预处理:首先,需要对输入数据进行清洗和预处理,包括去除噪声、填充缺失值、转换数据格式等。这一步骤通常涉及特征工程,如特征选择、特征缩放、特征归一化等。 2. 构建模型架构:根据任务需求,选择合适的深度学习模型结构,如卷积神经网络(CNN)、 ===== 所有请求处理完成 ===== 总任务数:5 | 成功:5 | 失败:0 总耗时:66.52秒(对比单线程,多线程耗时更短)
五、多线程推理对大模型的意义
1. 提升服务吞吐量和响应效率
- 单线程只能处理一个请求,多线程可以同时处理多个请求,单位时间内处理的请求数(吞吐量)大幅提升,如从每秒 1 个请求提升到每秒 10 个请求。
- 对于用户来说,响应时间更短,不需要排队等待前面的请求完成,提升用户体验,这是大模型从个人工具走向公共服务的必备条件,如开放的api平台,都支持百万级并发请求,核心就是高效的多线程、多进程推理技术。
2. 优化资源利用率,降低部署成本
- 大模型的特点是模型体积大,占用资源多,如 Llama 2 70B 模型,占用显存超过 130G:
- 如果每个请求加载一份模型,10 个请求就需要 10 倍的资源,部署成本极高,根本无法承受。
- 多线程推理共享同一个模型实例,只需要一份模型资源,就能处理多个请求,大幅提升 CPU/GPU/ 内存的利用率,降低部署成本,这是大模型规模化落地的核心经济优势。
3. 保障服务稳定性和可用性
- 通过资源隔离,多线程推理可以避免单个请求搞垮整个服务的情况:
- 限制单个请求的资源占用和超时时间,即使某个请求出现异常,如输入过长、推理卡死,也只会影响该线程,不会导致整个服务崩溃。
- 线程池自动管理线程生命周期,避免手动创建线程导致的内存泄漏、线程溢出等问题,保障服务长期稳定运行,适合生产环境的 7×24 小时不间断服务。
4. 为后续高级技术打下基础
- 多进程推理,适合超大规模模型,利用多个GPU服务器节点。
- 分布式推理,适合百万级并发请求,如云平台上的大模型服务。
- 量化推理 + 多线程,在多线程基础上,对模型进行量化,进一步节省资源,提升吞吐量。
六、总结
吃透大模型多线程推理与资源隔离后,最深的心得是:这项技术不是单纯堆线程、追速度,而是平衡并发效率、硬件资源与服务稳定性的工程核心。刚开始我们容易陷入误区,以为开越多线程越快,实则大模型推理的关键是模型全局共享、请求缓存隔离,共享一份模型才能省显存、降成本,独立缓存才能避免线程互相干扰,这是多线程能落地的根本。
实际落地中,资源隔离远比并发更重要,不设线程上限、不限制生成长度、不加超时控制,很容易让单个异常请求占满显存、拖垮整个服务。从学习角度,建议先吃透单线程推理逻辑,再用线程池做基础并发,优先把“限线程数、控 token 长度、防超时”这三个基础隔离做到位,再去优化吞吐量。
多线程是大模型从本地 demo 走向服务化、规模化的必经之路,核心不是技术炫技,而是稳、省、高效。先保证服务不崩、资源不浪费,再追求更高并发,才是最务实、最适合工程落地的思路。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号