使用 Elasticsearch 和 Jina Embeddings 进行无监督文档聚类

使用 Elasticsearch 和 Jina Embeddings 进行无监督文档聚类

点火三周
发布于 2026-04-15 15:18:25
发布于 2026-04-15 15:18:25
使用 Elasticsearch 和 Jina Embeddings 进行无监督文档聚类
从向量搜索到强大的 REST API,Elasticsearch 为开发人员提供了最全面的搜索工具包。您可以在 Elasticsearch Labs 仓库中的示例笔记本中尝试一些新的东西。您还可以开始 免费试用 或者在本地运行 Elasticsearch。
向量搜索 通常是从一个查询开始,但是如果您没有一个明确的查询呢?
许多组织积累了大量的文档集合,例如支持票据、法律文件、新闻提要和研究论文,需要在提出正确问题之前了解其中的内容。没有标签或训练数据,手动审核成千上万的文档是不切实际的。而且,当您不知道要搜索什么时,传统搜索也无能为力。
这篇文章将带您了解一种基于 Elasticsearch 的无监督文档聚类和时间线追踪的方法,解决这一发现问题。到文章结束时,您可以追踪跨越多天的故事轨迹:
时间故事链图
时间故事链图
您将发现:
- • 为什么当您想要在没有查询的情况下进行主题发现时,聚类 嵌入(而不是检索嵌入)很重要。
- • 如何利用 Elasticsearch 的 k 最近邻(kNN)和批量
msearch通过密度探测的中心点分类来将文档按主题分组。 - • 如何使用
significant_text自动为聚类打标签,使主题在无需训练模型的情况下可读。 - • 如何通过时间故事链将每日聚类链接起来,展示主题如何从一天发展到下一天。
这篇文章是从可运行的 Jupyter Notebook 生成的。 您在文中看到的内联输出是流水线的真实结果。克隆 伴随笔记本 来自己运行。
该流水线使用 2025 年 2 月 BBC 新闻和《卫报》的约 8,500 篇文章作为测试语料。新闻是一个方便的领域,因为它具有明显的时间行为,但该模式适用于任何文档发现重要的地方:法律审查、合规性监控、研究综合、客户支持分类。
技术栈:
- • Jina v5 聚类嵌入: 使用任务特定的低秩适应(LoRA)适配器进行主题分组。Jina 已加入 Elastic,并且其模型可通过 Elastic 推理服务(EIS) 本地使用。
- • Elasticsearch: 可扩展的 kNN、
significant_text标签和向量存储。 - • DiskBBQ: 一种基于磁盘的向量索引格式,将更好的二进制量化(BBQ) 与分层 k-means 分区结合,用于近似最近邻(ANN)加速。此索引分区是向量搜索的内部机制,与本文中使用的密度探测聚类算法无关。
bbq_disk将量化后的向量存储在磁盘上,仅在堆中保留分区元数据,与bbq_hnsw相比大大降低了资源需求,同时保持高召回率。 - • 全局聚类 + 每日时间链接: 发现和故事演变。
您需要准备:
- • 一个 Elasticsearch 部署(Elastic Cloud、Elasticsearch Serverless 或 Elastic 自管理 8.18+/9.0+):
bbq_disk需要 8.18 或更高版本。可选的多样化检索器部分需要 9.3+ 或 serverless。 - • 一个 Jina API 密钥:免费层包括 1000 万个令牌,涵盖核心聚类流水线(约 425 万个令牌)。可选的检索对比聚类比较使用第二次嵌入传递。
- • 一个 Guardian API 密钥(免费)。
设置
安装所需的包:
1
pip install elasticsearch pandas numpy plotly umap-learn python-dotenv pydantic-settings datasets requests
可选(仅在运行此仓库的抓取助手时需要):
1
pip install beautifulsoup4
然后在项目根目录下的 .env 文件中配置 API 密钥:
1
2
3
4
ELASTIC_CLOUD_ID=your-cloud-id
# 或者 ELASTIC_HOST=https://...ELASTIC_API_KEY=your-api-key
JINA_API_KEY=your-jina-key
GUARDIAN_API_KEY=your-guardian-key
该笔记本调用 load_dotenv(override=True),因此本地 .env 值具有优先权。
1
Connected to Elasticsearch
第 1 部分:发现聚类 - 为什么要聚类嵌入?
大多数向量搜索使用的是训练来匹配 查询 和相关 文档 的 检索嵌入。这对于搜索来说是完美的,但对于发现则不然。当您想要在没有任何查询的情况下在语料库中找到存在的主题时,您需要能够将相似文档聚集在一起的嵌入。
Jina v5 通过 任务特定的低秩适应(LoRA)适配器 解决了这个问题。LoRA 向特定内部层添加小的低秩更新,同时保持大部分基础模型权重冻结,因此模型行为在不进行全面再训练的情况下转向特定任务。相同的基础模型根据 task 参数生成不同的嵌入:
任务 | 训练目的 | 用例 |
|---|---|---|
retrieval.passage | 查询文档匹配 | 搜索、检索增强生成(RAG) |
clustering | 主题分组(针对紧密聚类优化) | 发现、分类 |
聚类适配器经过训练,以使关于相同主题的文档在嵌入空间中更接近,而关于不同主题的文档则更远离。下面的视觉比较使差异变得具体。
检索与聚类:视觉比较
为了观察差异,使用两种任务类型对文档样本进行嵌入。聚类在原始的 1024 维嵌入空间中进行;统一流形近似与投影(UMAP)仅用于将这些嵌入投影到 2D 进行可视化。UMAP 保留局部邻域结构,使其在比较聚类分离时非常有用。
下图中,相同的 480 个文档样本分别使用两种任务类型进行嵌入,并使用 UMAP 投影到 2D。请注意在聚类面板中颜色组更紧密、更分离。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
全集:8,495 篇文章
来源:guardian: 5749, bbc: 2746
日期范围:2025-02-01 至 2025-02-28
样本:480 篇文档分布于 8 个部分
section
Film 60
World news 60
Australia news 60
Opinion 60
Football 60
US news 60
Sport 60
Business 60
聚类嵌入:480
检索嵌入:480
UMAP 投影完成
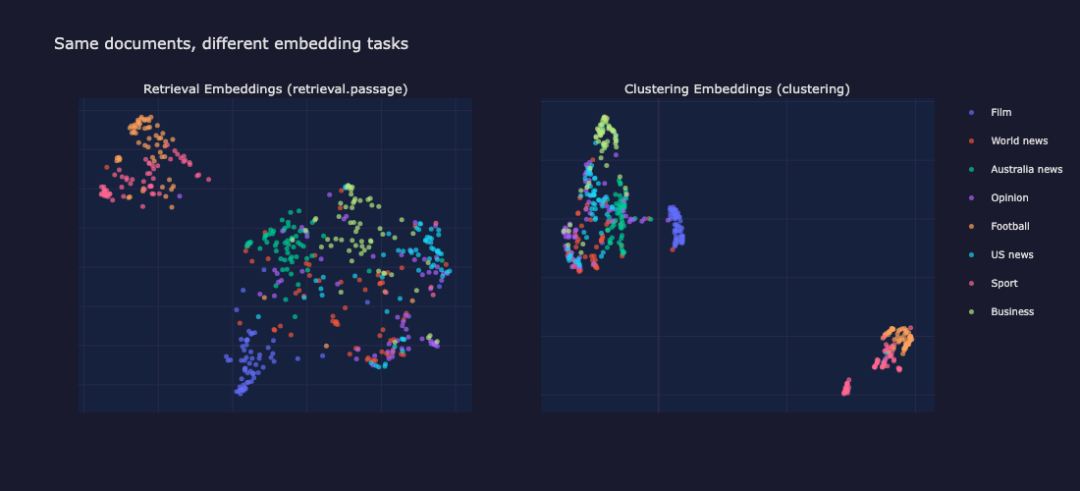
UMAP 检索与聚类嵌入对比
UMAP 检索与聚类嵌入对比
检索嵌入(左)大范围分布主题;聚类嵌入(右)使相同文档形成更紧密、更分离的组。
聚类嵌入产生了更紧密、视觉上更明显的组。检索嵌入更均匀地分布主题,适合搜索(细粒度相似性);但对于发现,紧密的主题聚类才是关键。
这就是为什么在本文的其余部分使用 task="clustering"。
加载数据集
语料结合了 2025 年 2 月的两个新闻来源:
- • BBC 新闻 通过 RealTimeData/bbc_news_alltime HuggingFace 数据集。
- • 《卫报》 通过 Guardian Open Platform API。
拥有多个来源有助于验证聚类发现的是 主题 而不是 来源特定的风格。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
总文章数: 8,495
来源分布:
source
guardian 5749
bbc 2746
日期范围:2025-02-01 → 2025-02-28
覆盖天数:28
样本文章:
来源: guardian
标题: Carbon monoxide poisoning ruled out in death of Gene Hackman and wife, police sa
部分: Film
文本: Authorities have ruled out that Gene Hackman and his wife, Betsy Arakawa, died from carbon monoxide poisoning earlier this week in their home in Santa Fe, New Mexico. The Santa Fe county sheriff, Adan...
使用聚类任务进行嵌入
使用 task="clustering" 调用 Jina v5 API 对所有文档进行处理。嵌入缓存到磁盘,因此后续运行将跳过 API 调用。
API 调用很简单。task 参数是与典型嵌入用法的关键区别:
1
payload = { "model": "jina-embeddings-v5-text-small", "input": texts, "task": "clustering", # ← 选择聚类 LoRA 适配器}
以下的时间反映了缓存命中。首次运行 API 会更长,具体取决于语料大小。
1
2
嵌入准备好:8,495 个维度为 1024 的向量
时间:0.6秒
索引到单个 Elasticsearch 索引中
为了发现聚类,整个月份的数据进入一个索引(docs-clustering-all)。时间线链接的每日分区稍后进行。
索引映射使用 bbq_disk 作为向量字段:
1
{ "embedding": { "type": "dense_vector", "dims": 1024, "index": true, "similarity": "cosine", "index_options": { "type": "bbq_disk" // 用于 ANN 索引查找的分层 k-means 分区;与本文的聚类算法无关 } }}
一个 1024 维的 float32 向量是 4 KB。bbq_disk 使用分层 k-means 将向量分区成小聚类,对其进行二进制量化,并将全精度向量存储在磁盘上进行重评分。只有分区元数据存储在堆中,因此即使对于大型语料,内存需求也保持较低。对于能够承担更多堆内存的工作负载,bbq_hnsw 构建了一个分层可导航小世界(HNSW)图,以更快地查找,但资源成本更高。
dense_vector 字段类型支持多种 量化 策略:bbq_disk 和 bbq_hnsw 是高维嵌入的最佳选择,例如此处使用的 1024 维向量。
1
2
索引了 8,495 篇文档到 docs-clustering-all
时间:57.5 秒
聚类:密度探测的中心点分类
传统聚类算法如 HDBSCAN 假设您可以将完整的 N×d 向量矩阵保存在内存中,并运行重复的全遍更新。对于 8,495 篇文档和 1024 维度,这个大小是可管理的(约 35 MB),但对于数百万文档的规模,这种方法在没有额外基础设施的情况下就不适用了。
该算法在概念上类似于 KMeans++ 初始化与 Voronoi 分配和噪声基线,但它使用 Elasticsearch kNN 搜索 作为计算基元,几乎所有工作都保持在服务器端:
- 1. 抽样 5% 的文档作为密度探测(随机抽样,最少 50 个)。
- 2. 通过批量
msearchkNN 探测密度。每个探测发出一个 kNN 查询并记录其邻居的平均相似度。高平均相似度 = 嵌入空间的密集区域。msearch通过单个 HTTP 调用发送多个搜索请求,这在此处至关重要:密度探测生成数百个 kNN 查询,批量处理它们可以避免每个请求的开销。 - 3. 使用多样化选择高密度种子:高于中位密度的候选者按密度降序排序,仅在其与每个现有种子的余弦相似度低于分离阈值时贪婪地接受。这是唯一的客户端计算(约 0.01 秒用于 8k 文档)。
- 4. 通过
msearchkNN 将所有文档分类到中心点:每个种子作为一个中心点;一个 kNN 搜索检索出超过相似度阈值的附近文档。每个文档被分配到得分最高的中心点。小的聚类被解散为噪声。
Elasticsearch 负责繁重的计算:msearch 用于密度探测,msearch 用于分类,以及 significant_text 用于标记。对于这个语料(8,495 篇文档),5% 的密度探测样本启动了 425 个 kNN 探测查询,msearch 将这些查询批量处理成九个 HTTP 调用(批量大小为 50),避免了每个探测一次请求的开销。结合 bbq_disk ANN 查找,这使得聚类阶段快速且可扩展。kNN 查询在聚类过程中使用最小的 num_candidates 值以提升速度;生产搜索查询应使用更高的 num_candidates 值以提高召回率,但会增加延迟。
聚类具有自然大小,由每个中心点周围的嵌入空间密度决定,而不是由一个硬性的 k 上限决定。密集的主题区域产生较大的聚类;小众主题产生较小的聚类。
为什么不用 KMeans 或 HDBSCAN?
KMeans 假设球形聚类并要求完整的 N×d 矩阵在内存中。对于适合内存的语料,HDBSCAN 是一个强有力的替代。它能够处理任意聚类形状,并具有公认的密度语义。
密度探测的中心点方法针对的是不同的场景:当您希望在一个系统中实现存储、检索和聚类,或当规模使得客户端矩阵操作不切实际时。它使用 Elasticsearch kNN 作为计算基元,能够处理任意聚类大小,并且几乎将所有计算保持在服务器端。
1
2
3
4
全局索引聚类耗时 31.6 秒
总聚类数:82
总噪声: 2420 (28.5%)
密度探测:425 个 kNN 查询通过 9 个 _msearch HTTP 调用
理解噪声率
大约 28% 的噪声率是设计上的结果,并不是故障模式。那些不符合配置的 similarity_threshold 的密集聚类的文档不会被强行分配到不合适的组中,而是保持未分配。这就像一个质量门槛:意见专栏、短篇文章和单一主题的故事通常难以聚类,因为它们缺乏定义一个一致组的主题密度。
这个阈值是可调的:降低 similarity_threshold 会产生更激进的聚类(更多文档被分配,但聚类更松散),而提高它则会收紧聚类并增加噪声比例。对于这个混合新闻内容的语料库,约 30% 的噪声是一个合理的操作点。生产部署应根据领域特定的质量标准调整阈值。
使用 significant_text 自动生成标签
现在每个聚类都需要一个人类可读的标签。Elasticsearch 的 significant_text 聚合查找在前景集(聚类)中出现频率异常的术语,和背景集(整个语料)相比。
在后台,它使用一种统计启发式(默认是 JLH 分数),平衡绝对和相对频率变化,无需机器学习,无需 大型语言模型(LLM)调用。一个关于英国政治的聚类可能会出现 starmer、labour、downing 这样的术语,因为这些术语在该聚类中比在整体新闻语料中更常见。
对于这个全局传递,标签直接在 docs-clustering-all 上计算,因此前景和背景都来自整个月份。在第 2 部分,标签使用每日索引模式(docs-clustering-*),这是一个通配符,可以让查询同时跨越所有匹配的索引,以便为 significant_text 提供更广泛的背景进行更好的对比。
一个最小的查询结构如下所示:
1
{ "size": 0, "query": { "term": { "cluster_id": "72" } }, "aggs": { "label_terms": { "significant_text": { "field": "text", "size": 5, "filter_duplicate_text": true } } }}
significant_text 也充当质量门槛:如果聚类没有生成显著术语,就说明没有突出的词汇。这些是应解散回噪声的无效组,而不是给予误导性标签。
一个轻量级的确定性清理步骤会去除噪声标签术语(数字标记、通用词),并在需要时回退到代表性的标题。这将标签保持为 Elasticsearch 本地的同时提高可读性。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
样本聚类标签:
聚类 3 (200 个文档) arsenal | mikel | villa
聚类 1 (198 个文档) volodymyr | ukrainian | kyiv
聚类 0 (196 个文档) hostages | hamas | israeli
聚类 4 (187 个文档) scrum | rugby | borthwick
聚类 52 (185 个文档) fossil | renewable | renewables
聚类 10 (156 个文档) labour | gwynne | mps
聚类 40 (151 个文档) novel | novels | literary
聚类 11 (149 个文档) mewis | sarina | wiegman
聚类 44 (143 个文档) flooding | rainfall | rain
聚类 13 (131 个文档) doge | musk | elon
聚类 12 (128 个文档) murder | insp | knockholt
聚类 5 (124 个文档) putin | backstop | starmer
将 35 个文档从无效聚类重新分配到噪声
总文档数:8,495
聚类的: 6,040 (71.1%)
噪声: 2,455 (28.9%)
可视化聚类
下面的可视化展示了全局聚类传递所发现的内容:聚类文档与噪声文档的日期分布、整个月的 UMAP 投影,以及一个来源混合图,确认聚类反映的是主题而非来源。
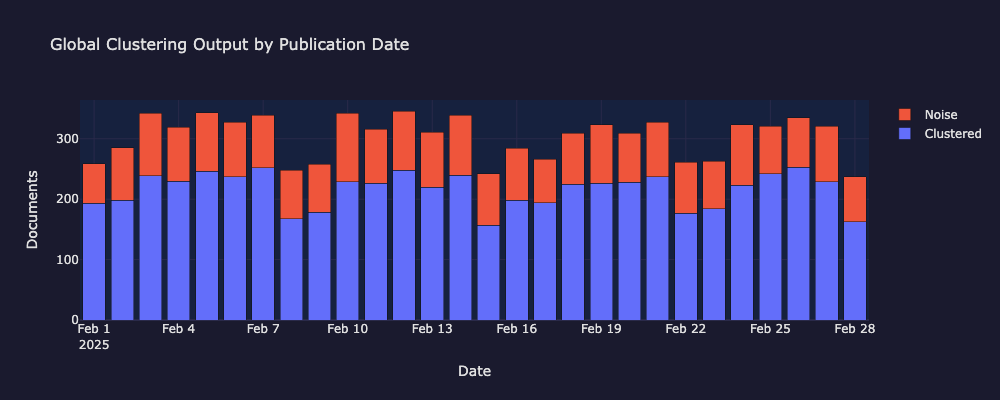
每日聚类与噪声文档分布
每日聚类与噪声文档分布
2025 年 2 月每日聚类与噪声文档分布。
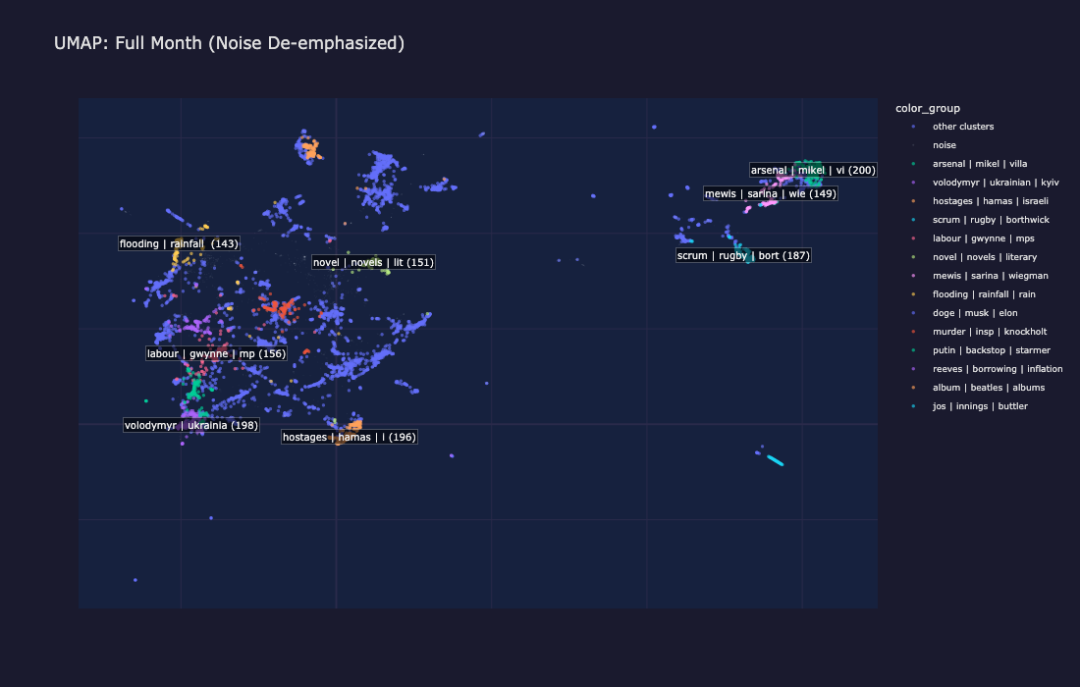
整月 UMAP 投影与所有文档
整月 UMAP 投影与所有文档
整月 UMAP 投影:每个彩色岛屿是一个主题聚类,灰色点是噪声
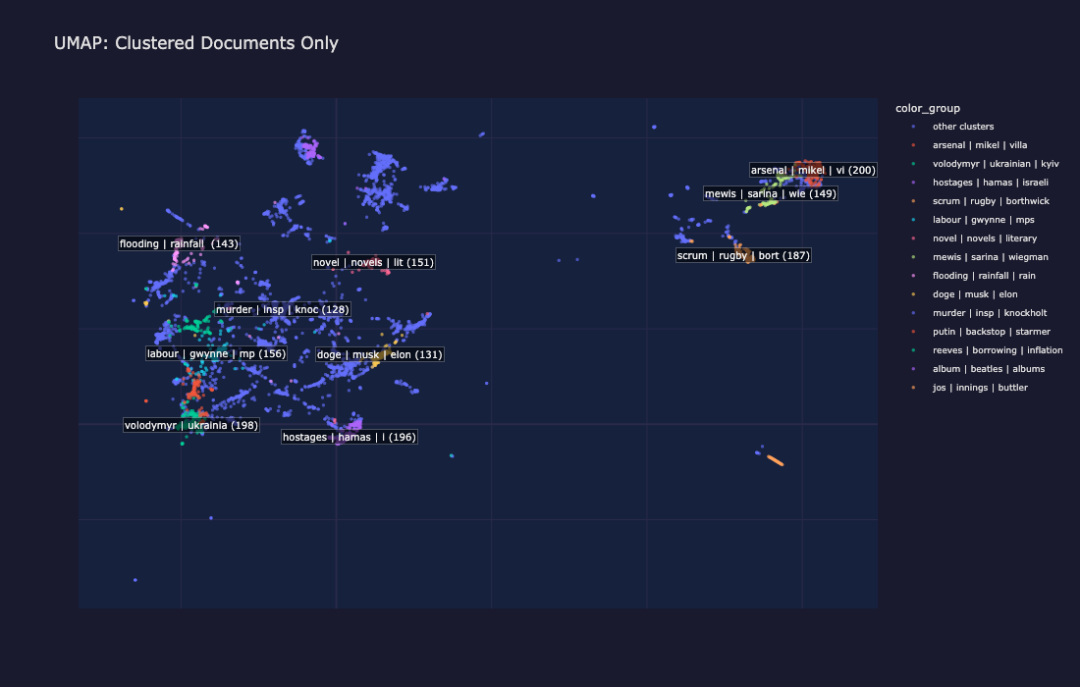
仅聚类文档的 UMAP 投影
仅聚类文档的 UMAP 投影
仅聚类文档:移除噪声更清楚地展现主题结构
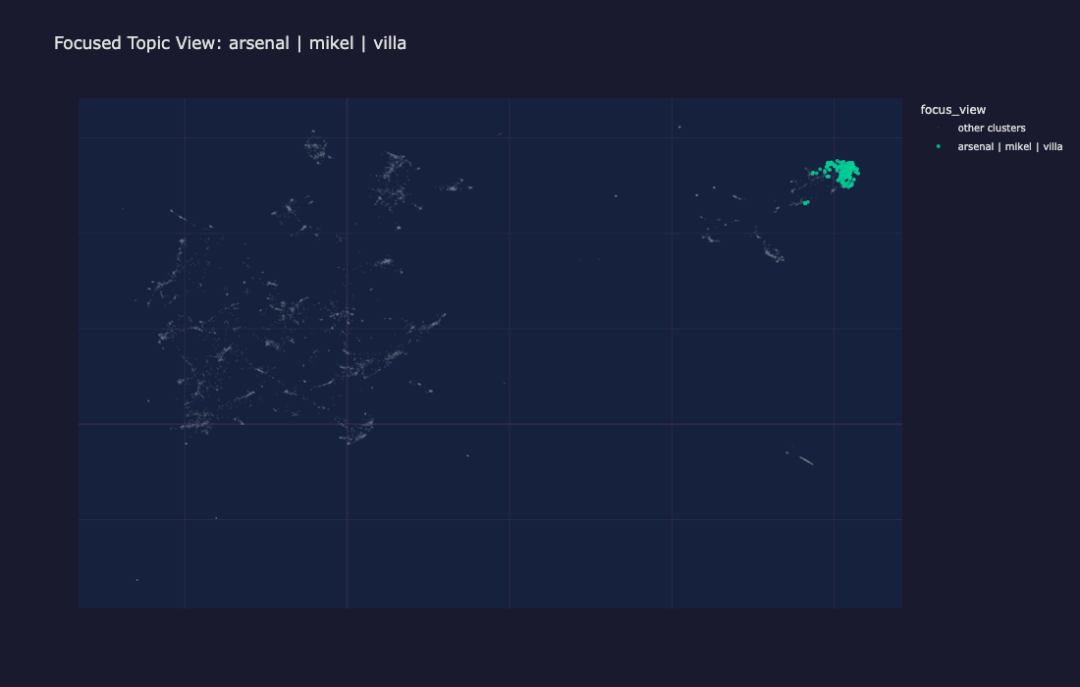
UMAP 投影中突出显示单个聚类
UMAP 投影中突出显示单个聚类
聚焦视图突出显示一个聚类(英超足球)与其他所有聚类的对比。
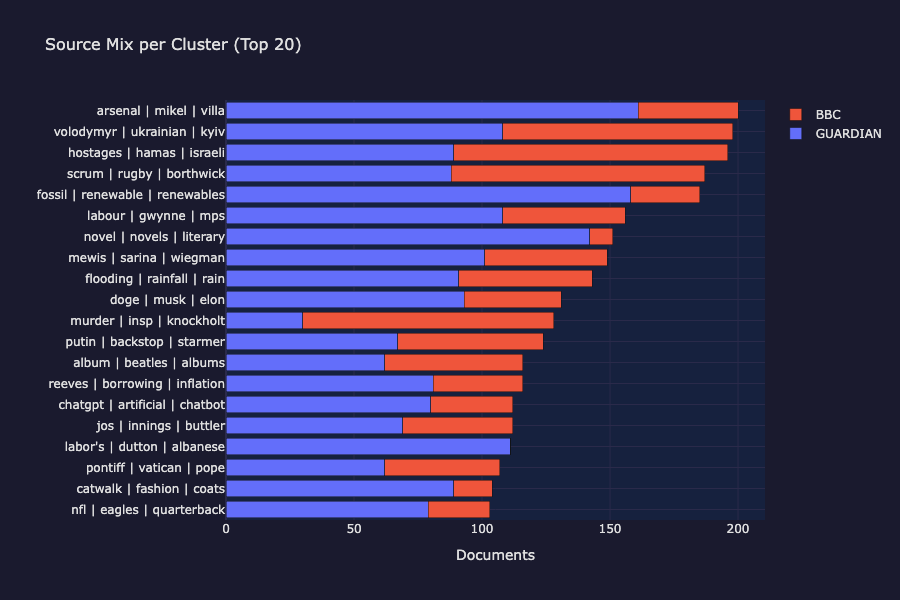
每个聚类的来源混合显示基于主题的分组
每个聚类的来源混合显示基于主题的分组
每个聚类的来源混合:BBC 和《卫报》出现在每个主要聚类中,确认是基于主题而非来源的分组。
UMAP 中的每个彩色岛屿代表一个聚类:一组关于相同主题的文章,纯粹基于嵌入相似性发现。灰色噪声点是那些没有清晰归入任何聚类的文章(通常是短文、意见文章或一次性故事)。
来源分解图表确认聚类包含来自 BBC 新闻 和 《卫报》 的文章。聚类正在发现 主题,而不是 来源,正是无监督发现应该产生的结果。
使用多样化检索器探索聚类广度
普通的 kNN 返回的是最接近聚类中心的文档(密集核心)。但真正的聚类覆盖子主题。多样化检索器 使用最大边缘相关性(MMR)来展示与中心相关但彼此不同的文档。
关键参数是 λ(lambda):
- • λ = 1.0 → 纯相关性(与普通 kNN 相同)。
- • λ = 0.0 → 纯多样性(最大程度分散结果)。
- • λ = 0.5 → 平衡:即与主题相关,但覆盖不同角度。
版本说明: 多样化检索器在 Elastic Cloud Serverless 和自管理 Elasticsearch 9.3+ 上可用。较早版本仍然可以遵循聚类和时间链接部分;只有这个探索步骤需要多样化检索器。
一个最小的检索器请求结构如下所示:
1
{ "size": 8, "retriever": { "diversify": { "type": "mmr", "field": "embedding", "lambda": 0.5, "query_vector": "<cluster-centroid-vector>", "retriever": { "knn": { "field": "embedding", "query_vector": "<cluster-centroid-vector>", "k": 50, "num_candidates": 100 } } } }}
在多样化级别,type、field 和 query_vector 参数是必需的:field 告诉 MMR 使用哪个 dense_vector 字段进行结果间相似性计算,query_vector 提供相关性评分的参考点。
这让您可以回答:“这个聚类实际上涵盖了什么?”而不仅仅是“它的中心是什么?”
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
探索聚类 52 (185 个文档)
标签:fossil | renewable | renewables
计算出的中心点(维度=1024)
========================================================================
普通 kNN(最接近中心点)
========================================================================
1. [0.9738] 绿色活动人士担心政府准备向 Drax 发电站提供数十亿英镑的新补贴,尽管存在强烈的担忧...
2. [0.9710] 13 个石油和天然气许可证可能被取消,因为部长们决定新的化石燃料开采指导意见后做出决定...
3. [0.9699] 专家指责化石燃料行业寻求特殊待遇,因为游说者声称油田的温室气体排放量...
4. [0.9681] 燃烧木材是一种可怕的发电方式。砍伐树木破坏了野生动物的栖息地,而种植新树无法...
5. [0.9649] 如果凯尔·斯塔默屈服于政治压力并允许开发...
6. [0.9641] 工党将在下周面临严峻的政策选择,这些选择可能会暴露财政部与...
7. [0.9638] 位于北约克郡塞尔比附近的 Drax 发电站燃烧进口木屑颗粒。政府已同意与...
8. [0.9581] 如果您关心我们将传递给后代的世界,周四早上的新闻是戏剧性的。这一月的新闻是...
========================================================================
多样化检索器(MMR,lambda=0.5)
========================================================================
1. [0.9738] 绿色活动人士担心政府准备向 Drax 发电站提供数十亿英镑的新补贴,尽管存在强烈的担忧...
2. [0.9434] 石油和天然气利益相关者发起了一场协调运动,以阻止禁止新建筑中天然气连接的政策...
3. [0.9303] 读到北海石油和天然气生产的新许可证因法律诉讼而延迟(13 个以上...
4. [0.9139] 美国能源部长克里斯·赖特表示,他“希望看到澳大利亚开始供应铀并可能...
5. [0.9077] 周六晚些时候,瑞秋·里夫斯面临批评,因为她引用了一份报告作为证据,证明...
6. [0.8996] 当玛格丽特·撒切尔在 1990 年成立哈德利气候变化中心时,记者们建议她试图表现得像...
7. [0.8993] 大多数政府可能会错过即将到来的最后期限,以提交决定世界是否能...
8. [0.8987] 欧洲海运天然气进口去年下降了五分之一,达到自大流行以来的最低水平,根据一份新报告...
重叠:1/8 个文档出现在两个结果集中
平均对比相似度(越低越多样化):
普通 kNN: 0.9057
多样化检索器: 0.6965
普通的 kNN 结果聚焦于主题的一个角度:最接近中心点的文档和彼此非常相似的文档。多样化检索器则揭示了同一聚类的不同方面:子主题、不同来源和不同视角。
多样性指标在数量上证实了这一点:多样化检索器结果的平均对比相似度较低,意味着返回的文档覆盖了更多领域。
这对以下方面有用:
- • 理解聚类实际涵盖的内容,不仅是其中心,还包括其边缘。
- • 生成摘要。多样化的代表性文档为 LLM 提供更好的材料。
- • 寻找代表性示例,供人工审查或下游标记。
- • 质量检查。如果多样化结果看起来不连贯,则可能需要拆分聚类。
第 2 部分:时间故事链
跨天跟踪故事
第 1 部分对整个月份进行了全局聚类以进行主题发现。为了观察时间流动,相同的密度探测中心点分类将独立应用于 每日索引,然后将聚类跨相邻天链接。请注意,每日聚类独立于第 1 部分的全局聚类;每一天产生其自己的聚类分配和标签,以适应当天的内容。
链接方法:采样与查询
对于 A 天的每个聚类:
- 1. 抽取一些代表性文档。
- 2. 对 B 天的索引运行 kNN。
- 3. 计算有多少命中落在 B 天的每个聚类中。
- 4. 如果命中比例超过阈值(kNN 比例 ≥ 0.4),记录一个链接。
这种方法快速(每个聚类只查询几个文档,而不是全部)并使用 Elasticsearch 的原生 kNN,无需外部工具。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
准备时间链的每日索引...
将 8,495 个文档索引到 28 个每日索引中
找到时间链接:808 个,耗时 145.4 秒
最强链接:
2025.02.01 'league | arsenal | premier' -> 2025.02.02 'league | season | striker' (100%)
2025.02.03 'league | striker | loan' -> 2025.02.04 'league | striker | season' (100%)
2025.02.03 'score | operator | gedling' -> 2025.02.04 'league | striker | season' (100%)
2025.02.12 'playoff | leg | bayern' -> 2025.02.13 'league | players | injury' (100%)
2025.02.14 'league | injury | football' -> 2025.02.15 'league | premier | football' (100%)
2025.02.18 'russia | ukraine | talks' -> 2025.02.19 'saudi | russia | arabia' (100%)
2025.02.18 'football | league | bayern' -> 2025.02.19 'league | manchester | players' (100%)
2025.02.21 'league | premier | manchester' -> 2025.02.22 'game | players | defeat' (100%)
2025.02.21 'rugby | calcutta | brilliant' -> 2025.02.22 'game | players | defeat' (100%)
2025.02.26 'metals | kyiv | ukrainian' -> 2025.02.27 'ukraine | russia | talks' (100%)
kNN 比例为 100% 意味着来自源聚类的每个抽样文档都进入了同一个目标聚类,是可能的最强跨日链接。上面的大多数链接都与足球有关,这很合理:英超联赛的报道每天都有,主题一致性很高。
score | operator | gedling → league | striker | season 链接是一个例子,显示一个小众的本地足球聚类(Gedling 是一个非联盟俱乐部)在第二天被吸收到更广泛的英超联赛聚类中,这是每日重新聚类在不同粒度上自然发生的效果。
构建故事链
故事链是跨连续天链接的聚类序列。
单个成对链接告诉您星期一的“英国政治”聚类连接到星期二的。链则揭示整个弧线:一个从星期一开始的故事,随着一周的进展而演变,到星期五逐渐消退。
链是从 kNN 比例 ≥ 0.4 的链接贪婪构建的,意味着至少 40% 的来自源聚类的抽样文档进入了一个目标聚类。从最早的聚类开始,算法总是跟随最强的出链。
1
2
3
4
5
6
7
8
9
10
强链接(kNN 比例 >= 0.4):244
跨越 3 天以上的故事链:18
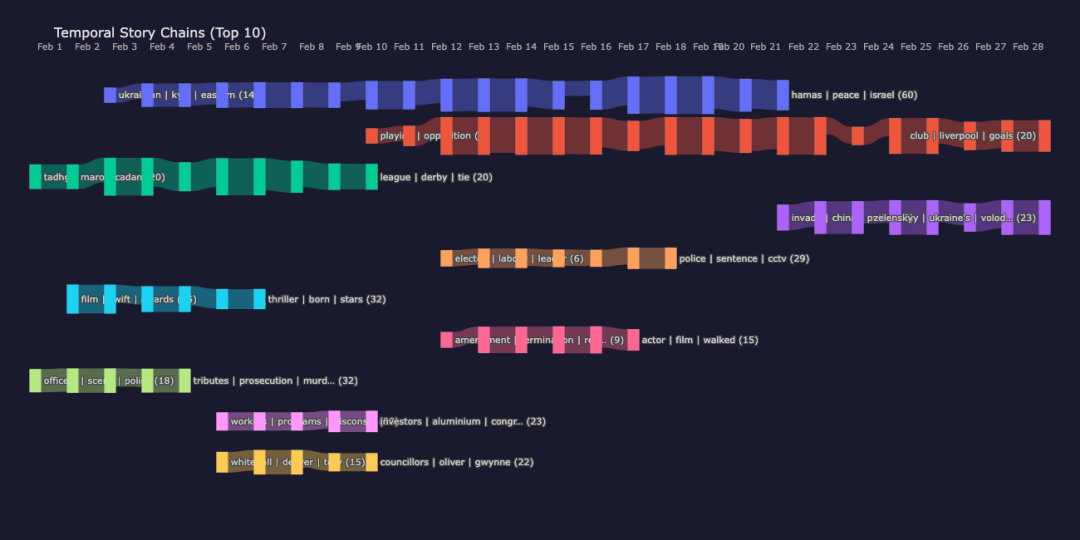
链 1:'ukrainian | kyiv | eastern' (19 天:2月3日 → 2月21日)
链 2:'playing | opposition' (19 天:2月10日 → 2月28日)
链 3:'tadhg | maro | cadan' (10 天:2月1日 → 2月10日)
链 4:'invade | china | putin' (8 天:2月21日 → 2月28日)
链 5:'elected | labour |leader' (7 天:2月12日 → 2月18日)
链 6:'film | swift | awards' (6 天:2月2日 → 2月7日)
链 7:'amendment | termination | reporting' (6 天:2月12日 → 2月17日)
链 8:'officers | scene | police' (5 天:2月1日 → 2月5日)
最长的链条跟踪乌克兰与俄罗斯的报道,连续 19 天,这在 2025 年 2 月的地缘政治紧张局势下并不意外。第二长的链条则是围绕英超足球的报道,贯穿了当月的 19 天。较短的链条则捕捉了奖项季(电影/奖项,6 天)、六国橄榄球赛(10 天)以及英国政治领导人报道(7 天)。每个链条代表了一个故事弧,该算法纯粹根据跨每日索引的嵌入相似性发现。
桑基图:可视化故事流
桑基图是一种流动可视化,其中链接宽度代表连接强度。在这里,每个垂直带是一天,每个节点是一个每日聚类(按文档数大小显示),每条彩色路径追踪一个故事链跨越时间。链接宽度编码 kNN 重叠强度:更粗的链接意味着更多的抽样文档进入目标聚类。颜色在链内是一致的,因此从左到右的单色路径代表一个故事的进展。
例如,乌克兰与俄罗斯链(可见为较长的路径之一)从二月初一直流动到第三周,持续较厚的链接表示跨日的主题连续性很强。
2025年2月的时间故事链
2025年2月的时间故事链
2025年2月的时间故事链。每条彩色路径代表持续多天的故事;链接宽度表示 kNN 重叠强度。
这种方法提供了什么
这篇文章介绍了一个完整的基于 Elasticsearch 的无监督文档聚类流水线:
- 1. 聚类嵌入: Jina v5 的任务特定适配器生成的嵌入针对主题分组进行了优化,而不仅仅是查询-文档匹配。
- 2. 全局发现聚类: 将整个月份的数据聚类到一个索引中,最大化跨日主题发现。
- 3. 密度探测的中心点分类: 抽样 5%、通过
msearchkNN 探测密度、选择多样化的高密度种子、将所有文档分类到中心点。Elasticsearch 处理大量计算;只有种子选择在客户端运行(约 0.01 秒)。 - 4.
significant_text标签: 显著性测试在没有任何机器学习模型或人工标注的情况下生成有意义的聚类标签。无法产生显著术语的聚类是无效的,被降级为噪声——这是一种内置的质量门槛。 - 5. 时间故事链接: 每日索引和跨索引采样与查询 kNN 追踪故事如何随时间演变。
关键要点:
- • 嵌入任务类型很重要:聚类嵌入产生了显著更紧密的主题组。
- • Elasticsearch 可以同时作为存储层和聚类引擎,通过 kNN 搜索 实现。
- • 密度探测的中心点分类几乎将所有计算保持在服务器端,并产生由嵌入空间密度决定的自然大小的聚类。
- •
significant_text快速、可解释且对自动标签和质量门槛有效。
这种方法何时有用:
- • 您有时间戳文本,并希望在没有标记训练数据的情况下进行主题发现。
- • 您希望一个系统同时处理存储、向量搜索、标签和时间链接。
探索的扩展:
- • 多周期聚类(每周、每月汇总)。
- • 实时摄取与增量聚类分配。
- • 使用 significant_text 术语作为种子生成 LLM 的聚类摘要。
- • 在更大规模上,采样的 KMeans 中心点可以作为密度聚类的暖启动种子,降低探测阶段的成本。
自行尝试
替换为您自己的带时间戳的文档语料;任何包含日期的文本集合都适用于此流水线。完整的笔记本和支持代码可在 伴随仓库 中找到。
- • 开始免费的 Elastic Cloud 试用:在几分钟内启动一个支持
bbq_disk的托管集群。 - • 尝试 Elasticsearch Serverless:无需集群管理,自动扩展,并支持本文的所有内容。
您觉得这篇内容如何?
😔不太有帮助
😐有一点帮助
😁非常有帮助
报告问题
📡 更多 Elastic & AI 可观测性干货
关注「点火三周」,第一时间获取最新技术文章
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-12,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号