AFR-CLIP:零样本工业缺陷检测的终极杀器——精度暴涨,全面碾压现有方法

AFR-CLIP:零样本工业缺陷检测的终极杀器——精度暴涨,全面碾压现有方法

OpenCV学堂
发布于 2026-04-15 18:18:55
发布于 2026-04-15 18:18:55
介绍
AFR-CLIP 是一种新颖的零样本异常检测框架。它解决了现有基于 CLIP 的方法主要关注目标类别(如“螺丝”、“瓶子”)而忽略其异常状态(正常或异常)的核心问题。AFR-CLIP 通过两大创新实现高性能:
- 无状态到有状态的跨模态特征校正:将图像中的隐含缺陷信息嵌入到不包含状态信息的文本提示中。
- 文本-文本异常评分:将校正后的文本嵌入与两个预定义的有状态原型(正常和异常)进行匹配,生成异常图。 此外,框架还引入了自提示和多块特征聚合模块,以增强对多尺度特征和复杂异常(如细微划痕、小裂缝)的感知能力。在11个工业和医学数据集上的实验证明了其优越性。
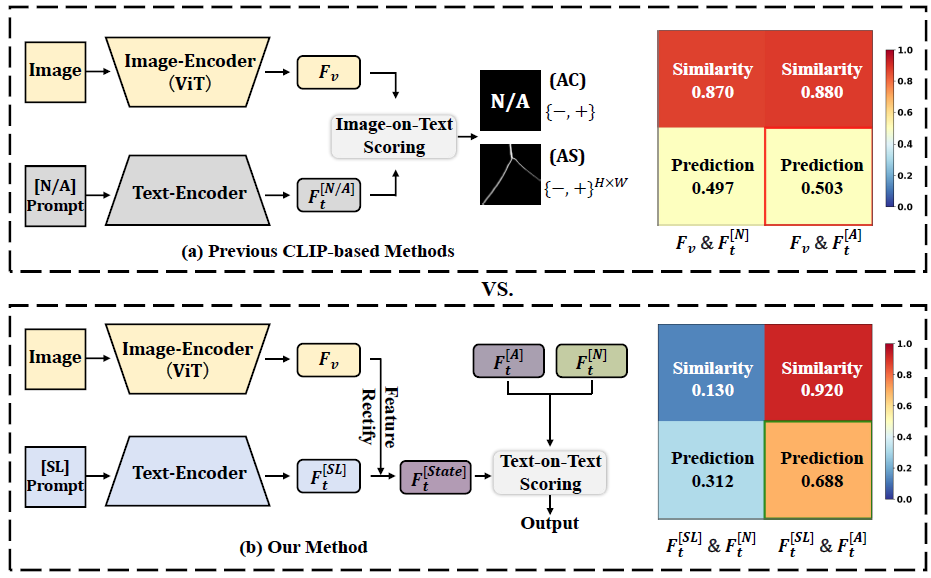
核心问题分析
现有 CLIP-based ZSAD 方法的局限:
- 类别语义主导:CLIP 的预训练对齐过程主要由对象类别驱动,而非其状态(“正常的对象” vs “异常的对象”)。
- 状态语义不敏感:直接计算图像特征与“正常/异常”文本提示的余弦相似度时,两类分数常集中在0.5附近,难以区分。
AFR-CLIP 的核心思想: 将模型焦点从对象类别转移到异常状态。通过一个校正模块,将视觉缺陷线索注入无状态提示,再与通用状态原型进行比较,从而放大正常与异常状态之间的特征差异。
方法框架
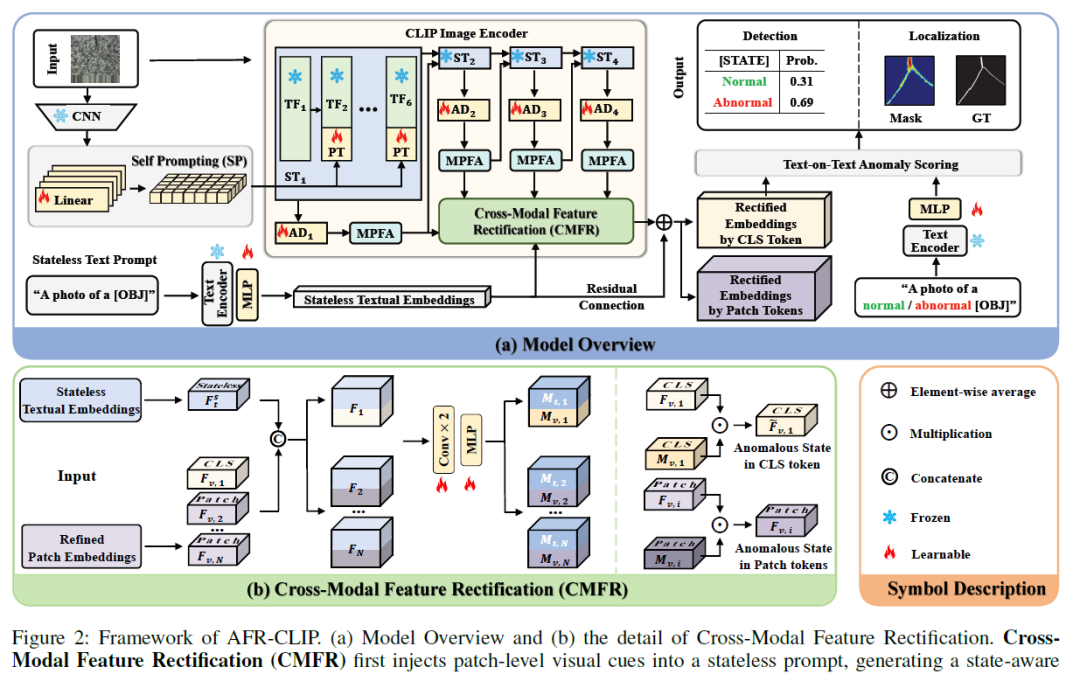
AFR-CLIP 采用 CLIP (ViT-L-14@336) 作为骨干网络,包含以下核心组件:
- 图像分支:输入图像 → CLIP图像编码器 → 自提示模块(融合CNN局部特征与ViT全局特征) → 多块特征聚合模块(聚合邻域多尺度特征)。
- 文本分支:输入无状态提示(如“一张螺丝的照片”) → CLIP文本编码器 → 线性投影。
- 跨模态特征校正模块:用校正后的视觉特征来校正无状态文本嵌入。
- 文本-文本异常评分:计算校正后的文本嵌入与“正常/异常”文本原型之间的相似度,生成最终异常分数和热图。
3.2 跨模态特征校正
目的:将图像中隐含的异常状态信息注入到无状态文本提示中。
输入:
- 视觉特征 Fv∈RN×DFv∈RN×D (N个图像块)
- 三类文本提示(经CLIP文本编码器和线性层后):
- FtnFtn: 正常提示 (e.g., “一张正常螺丝的照片”)
- FtaFta: 异常提示 (e.g., “一张缺陷螺丝的照片”)
- FtsFts: 无状态提示 (e.g., “一张螺丝的照片”)
校正过程 (图2(b)):
- 将每个图像块特征 Fv,iFv,i 与无状态文本特征 FtsFts 拼接。
- 通过卷积层和 Sigmoid 函数生成两个空间权重图 Mv,iMv,i 和 Mt,iMt,i。
- 校正公式:Ft,is=Fts+Fv,i⊙Mv,iFt,is=Fts+Fv,i⊙Mv,i
- 将图像特定的视觉线索(残差)加到原始文本嵌入上,生成校正后的、包含状态信息的文本特征。
3.3 文本-文本异常评分
图像级评分:
- 使用全局校正后的文本特征 Ft,1sFt,1s(对应类别标记)分别与正常原型 FtnFtn 和异常原型 FtaFta 计算余弦相似度。
- 通过 Softmax 将相似度转换为异常概率 PaPa。
像素级评分:
- 对每个图像块 ii,使用其校正后的文本特征 Ft,isFt,is 重复上述过程,得到每个块的异常概率 Pa,iPa,i。
- 将所有块的 {Pa,i}{Pa,i} 重塑并上采样至原始图像分辨率,生成异常热图。
优势:通过“文本-文本”比较,从根本上避免了图像特征中类别语义的干扰,使分数直接反映异常状态。
3.4 自提示模块
目的:增强对局部纹理细节的感知,弥补 ViT 全局建模对细微缺陷捕捉不足的问题。
方法:
- 使用 CNN 提取图像的局部特征。
- 通过线性适配器将 CNN 特征转换为图像特定视觉提示 PvPv,并与 K 个可学习的通用提示 PlPl 相加,形成最终视觉提示 Pv~Pv~。
- 在 ViT 编码器的第一阶段(第2-6层),将输出的最后 KK 个 token 替换为 Pv~Pv~,实现局部与全局特征的融合。
3.5 多块特征聚合模块
目的:解决小尺度缺陷和复杂缺陷的定位问题,增强边界连贯性和多尺度上下文。
将每阶段的块嵌入 FviFvi 重塑为空间网格 F~viF~vi。
对每个块周围的 m×mm×m 邻域(默认 m=3m=3)执行自适应平均池化,聚合邻域信息。
将聚合后的特征重塑回块格式,用于后续处理。实验与结果
4.1 实验设置
- 数据集:工业领域 (MVTec AD, VisA, BTAD, MPDD) 和医学领域 (Brain MRI, Head CT, ISIC 等)。采用跨数据集协议进行训练和测试。

- 评价指标:AUROC (图像级/像素级) 和 max-F1。
- 实现细节:CLIP ViT-L-14@336 骨干,输入尺寸 518x518,训练100轮,批量大小4,Adam优化器,初始学习率 0.001。
4.2 主要结果
- 图像级异常检测
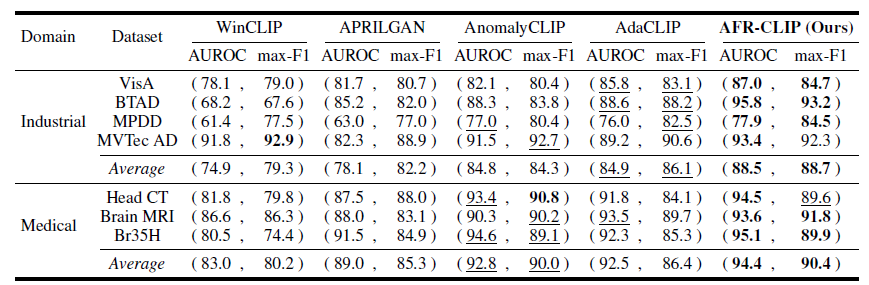
- 在工业领域 VisA 数据集上,AFR-CLIP 达到 87.0% AUROC 和 84.7% max-F1,领先第二名 5.3% (AUROC)。
- 在医学领域 Head CT 数据集上,达到 94.5% AUROC,显著优于其他方法。
- 像素级异常定位
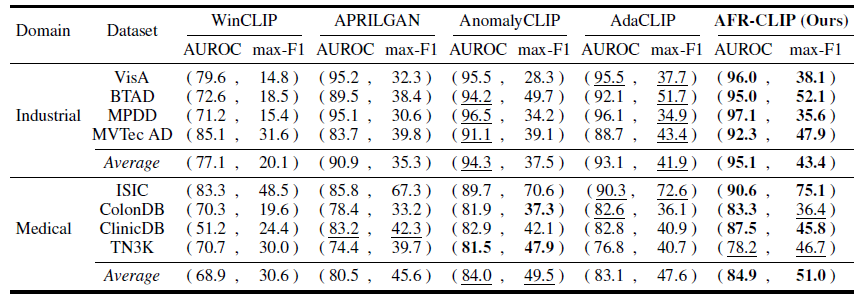
- 在 MVTec AD 上,AFR-CLIP 的像素级 AUROC 达到 92.3%,相比 AdaCLIP 提升 3.6%。
- 在几乎所有数据集上均取得最佳或次佳的像素级性能,证明了其精细定位能力。
4.3 消融研究
在 MVTec AD 上的消融实验:
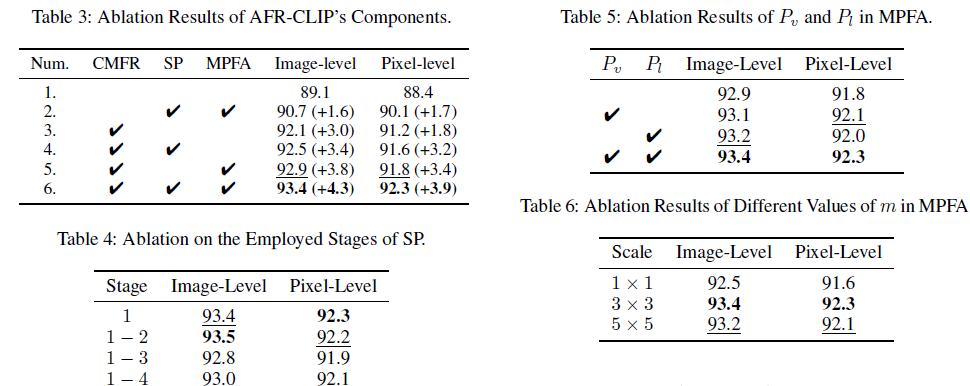
- 仅使用 CMFR (+SP, +MPFA):图像级 AUROC 从 89.1% → 92.1% (+3.0%)。
- 完整模型 (CMFR + SP + MPFA):达到最佳性能 93.4% (图像级) 和 92.3% (像素级),验证了每个模块的有效性。
- 其他消融实验 (表4,5,6) 验证了 SP 模块的最佳插入阶段、两种视觉提示的必要性以及 MPFA 中最佳邻域大小为 3x3。
结论
AFR-CLIP 通过创新的无状态到有状态的跨模态特征校正和文本-文本异常评分机制,成功将零样本异常检测的焦点从对象类别转移到异常状态。结合自提示与多块特征聚合模块,该框架在多个工业及医学数据集上取得了最先进的性能,展现了强大的跨领域泛化能力和精细的缺陷定位能力。这项工作为利用视觉语言模型解决数据稀缺领域的异常检测问题提供了新的有效范式。
未来的AI,必将是感知与认知交融的“全能思考者”。率先掌握多模态与视觉语言模型(VLM)这项技术,就是掌握了塑造新产业、定义缺陷检测新规则的核心主动权。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-10,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号