需求自动生成用例:基于OCR+ LLM的设计方案(附落地指南)

需求自动生成用例:基于OCR+ LLM的设计方案(附落地指南)

测试开发技术
发布于 2026-04-15 18:29:31
发布于 2026-04-15 18:29:31

当产品经理甩过来一份50页的需求文档,要求"这周把测试用例写完"时,你会怎么做?手动复制粘贴到Excel?还是让AI直接读图生成用例?
随着AI技术的普及,OCR(光学字符识别)与LLM(大语言模型)的结合,彻底打破了“手写用例”的效率瓶颈。今天给大家分享一套可落地的《自动生成用例:基于OCR+ LLM的设计方案》,从背景、痛点、架构、关键设计到落地建议,帮你快速实现用例自动生成,解放双手。
💡 文章篇符较长,建议先点赞收藏,慢慢看
一、背景:测试用例编写的痛点?
测试用例编写是软件测试中最"体力活"的环节。据统计,一个中等复杂度的需求,测试工程师平均需要花费:
环节 | 耗时占比 | 痛点 |
|---|---|---|
理解需求文档 | 30% | 文档格式混乱,PRD、原型图、流程图分散 |
提取测试点 | 40% | 需要人工识别边界条件、异常场景 |
编写用例格式 | 20% | 重复劳动,复制粘贴到用例管理工具 |
评审与修正 | 10% | 遗漏场景、描述不清 |
传统AI方案的局限:
早期的"AI生成用例"大多基于纯文本输入,比如把需求文档的Word/PDF文字提取出来喂给ChatGPT、DeepSeek。但现实中,大量关键信息藏在图片里——产品原型图、流程图、手绘草图、甚至Excel截图。
我们曾遇到过一个案例:某金融系统的"转账限额规则"只存在于一张复杂的Excel配置表截图中,文字提取工具完全失效,测试工程师只能肉眼识别37个单元格,手动编写142条用例,耗时2天。
这就是OCR+LLM方案的出发点:让AI不仅能"读文字",还能"看懂图"。
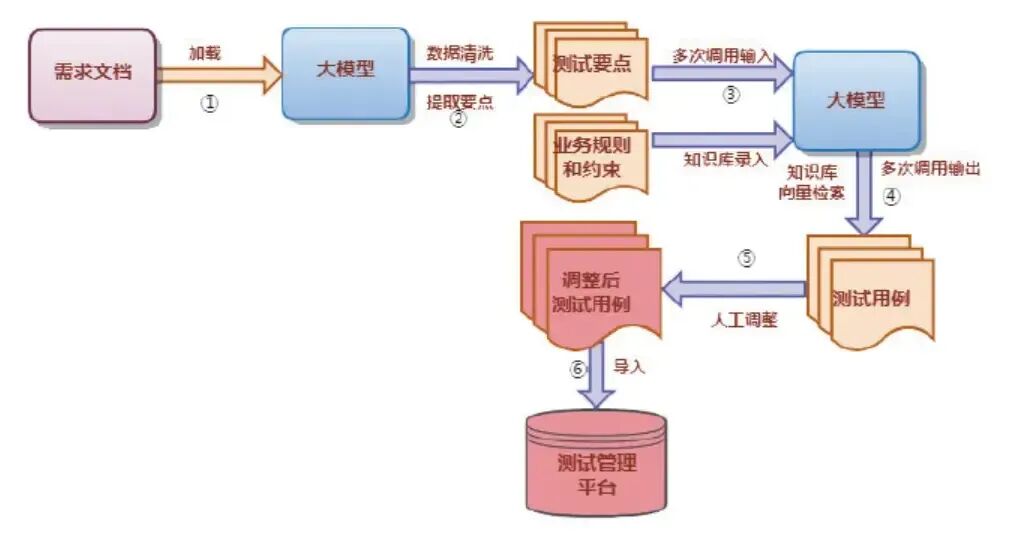
利用OCR与LLM的结合:
- • OCR负责“读懂”设计稿/原型图中的视觉元素(按钮、输入框、弹窗等),
- • LLM负责“理解”产品逻辑、补齐测试场景、生成标准化用例。两者协同,实现“输入设计稿,输出可评审用例”的闭环。
除此之外,随着产品迭代速度加快,每次需求变更都需要重新修改、补充用例,传统手写方式无法适配敏捷开发的节奏,而自动生成方案可快速响应需求变更,大幅提升测试效率,让测试工程师将精力聚焦在核心场景优化、缺陷排查上,而非重复的用例编写工作。
二、解决什么问题?
这个方案设计初衷主要为了解决三类场景:
场景1:原型图/设计稿 → 功能用例
产品经理给的是Axure/墨刀导出的PNG,包含页面元素、交互说明、业务规则。传统方式需要测试工程师对着图一条条写,现在让AI直接看图生成。
场景2:流程图/时序图 → 流程用例
复杂的业务状态流转(如订单从"待支付"到"已完成"的7个状态),流程图里画得很清楚,但文字提取会丢失箭头逻辑。OCR需要识别节点和连接关系。
场景3:配置表/规则表 → 组合用例
权限矩阵、费率表、风控规则等,往往以Excel截图或表格图片形式存在。需要识别行列关系,并应用组合测试/正交试验法生成用例。
核心目标:
- • 输入:任意格式的需求载体(PDF、图片、Word混排)
- • 处理:结构化提取业务规则、页面元素、流程节点
- • 输出:符合团队规范的测试用例(Excel/XMind/TestRail格式)
三、技术方案架构
整体架构分为感知层→认知层→生成层,模拟人类测试工程师"看→懂→写"的过程:
┌─────────────────────────────────────────────────────────┐
│ 输入层 │
│ ┌─────────┐ ┌─────────┐ ┌─────────┐ ┌─────────┐ │
│ │ PDF │ │ 图片 │ │ Word │ │ 原型链接 │ │
│ │ 文档 │ │ (PNG/JPG)│ │ 文档 │ │ (可选) │ │
│ └────┬────┘ └────┬────┘ └────┬────┘ └────┬────┘ │
└───────┼────────────┼────────────┼────────────┼────────┘
│ │ │ │
└────────────┴────────────┘ │
│ │
▼ │
┌──────────────────────────────────────────────┴─────────┐
│ 感知层 (OCR Engine) │
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────────┐ │
│ │ 通用OCR │ │ 表格OCR │ │ 版面分析 │ │
│ │ (PaddleOCR/ │ │ (TableMaster│ │ (LayoutParser │ │
│ │ Azure AI) │ │ /Structurize)│ │ /DocLayout-YOLO)│ │
│ └─────────────┘ └─────────────┘ └─────────────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ 结构化文本 + 坐标信息 │ │
│ │ {text: "用户名", bbox: [x1,y1,x2,y2], type: "input"}│ │
│ └─────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────┐
│ 认知层 (LLM Engine) │
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────────┐ │
│ │ 多模态 │ │ 提示工程 │ │ 知识注入 │ │
│ │ 理解 (GPT-4V│ │ (Few-shot │ │ (RAG检索业务 │ │
│ │ /Claude/Qwen│ │ CoT) │ │ 术语库) │ │
│ │ -VL) │ │ │ │ │ │
│ └─────────────┘ └─────────────┘ └─────────────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ 测试实体识别:页面元素、业务规则、状态流转、边界值 │ │
│ │ 关系抽取:点击关系、依赖关系、前置条件、后置结果 │ │
│ └─────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────┐
│ 生成层 (Case Builder) │
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────────┐ │
│ │ 用例模板 │ │ 组合策略 │ │ 格式导出 │ │
│ │ 引擎 │ │ (Pairwise/ │ │ (Excel/XMind/ │ │
│ │ │ │ 正交/全排列) │ │ TestRail API) │ │
│ └─────────────┘ └─────────────┘ └─────────────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ 标准测试用例:ID、标题、前置条件、步骤、预期结果、 │ │
│ │ 优先级、类型(功能/异常/边界)、关联需求 │ │
│ └─────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────┘但从交互角度来说,可细分为五层: 输入层 → 预处理层 → OCR识别层 → LLM推理层 → 输出层
1. 输入层:接收原始设计文件
支持多种输入格式,覆盖日常工作中常见的设计文件类型,无需转换格式,降低使用门槛:
- • 原型图:Axure、Figma导出的图片(PNG/JPG)、PDF文件;
- • UI设计稿:PS、Sketch导出的图片、切图文件;
- • 需求文档:包含页面截图的Word、PDF需求稿。
2. 预处理层:优化识别效果
原始设计文件可能存在模糊、倾斜、水印、多页面等问题,影响OCR识别准确率,预处理层主要做3件事:
- • 图像优化:去水印、去噪点、调整亮度对比度,确保元素清晰;
- • 倾斜校正:自动校正倾斜的设计图,避免文字、元素识别偏差;
- • 分页拆分:对多页面PDF、长图进行拆分,逐页识别,避免遗漏页面元素。
3. OCR识别层:提取页面核心元素
这一层是“读懂设计稿”的核心,采用成熟的OCR模型(如PaddleOCR、Tesseract,可根据需求选择),重点提取3类信息,为LLM生成用例提供基础:
- • 元素信息:识别页面中的输入框、按钮、下拉框、弹窗、文本标签等,标注元素名称(如“手机号输入框”“登录按钮”);
- • 元素属性:提取输入框的长度限制、默认提示文本,按钮的状态(可点击/不可点击),下拉框的选项等;
- • 页面结构:识别页面的模块划分(如“登录模块”“注册模块”)、元素的位置关系,梳理页面交互逻辑。
补充:OCR识别后,会生成一份“元素清单”,包含所有提取的信息,便于后续LLM调用,同时支持人工手动修正识别错误,提升准确率。
4. LLM推理层:生成标准化测试用例
这一层是“生成用例”的核心,也是方案的灵魂。我们选用适配中文场景、推理速度快的LLM模型(如Claude、通义千问、讯飞星火,可根据团队成本、隐私需求选择),核心工作流程如下:
- 1. Prompt工程:将OCR提取的“元素清单”,结合测试用例生成规则(如覆盖正常/异常/边界场景、统一输出格式),组装成Prompt,传递给LLM;
- 2. 逻辑推理:LLM结合Prompt,理解页面交互逻辑,自动补齐各类测试场景,比如输入框的格式校验(手机号、邮箱)、按钮的重复点击、验证码的过期校验等;
- 3. 格式标准化:按照“模块 | 用例标题 | 前置条件 | 操作步骤 | 预期结果”的格式,生成标准化用例,确保可直接用于评审、执行。
5. 输出层:输出可落地的测试用例
支持多种输出格式,适配不同团队的使用习惯,同时支持人工优化:
- • 文档格式:Word、Excel、PDF,可直接用于评审;
- • 测试工具格式:导出为JIRA、TestRail等测试管理工具可导入的格式,直接落地执行;
- • 编辑界面:提供简单的在线编辑界面,可手动修改、补充用例,优化场景覆盖。
四、关键环节设计
1、OCR层:通用OCR vs 专用模型,怎么选?
OCR识别准确率直接影响LLM生成用例的质量,若识别错误(如把“验证码输入框”识别成“密码输入框”),会导致用例生成偏差。
建议采用组合策略:
内容类型 | 推荐方案 | 理由 |
|---|---|---|
纯文字段落 | PaddleOCR / EasyOCR | 开源、可私有化部署、中文效果好 |
复杂表格 | TableMaster / Structurize | 能识别单元格合并、行列关系 |
流程图/架构图 | Azure Document Intelligence | 对线条、箭头、框图识别准确 |
手写草图 | 暂不处理,提示用户转电子稿 | 识别率低,人工兜底 |
另外,还可以通过3个优化手段,将识别准确率提升至95%以上:
- • 模型选型:优先选用中文识别效果好的模型,比如PaddleOCR(开源免费,中文识别准确率高),针对设计稿场景,可微调模型参数,提升元素识别精度;
- • 人工校正:OCR识别后,提供简单的校正界面,测试工程师可快速修正识别错误的元素名称、属性,耗时不超过1-2分钟;
- • 关键词匹配:预设常用测试元素关键词(如“验证码”“登录”“注册”“提交”),当OCR识别到相关关键词时,自动关联对应元素属性,减少识别偏差。
2、LLM层:多模态理解还是OCR+文本LLM?
这是架构设计的核心抉择。我们对比了两种路线:
路线A:端到端多模态(GPT-4V/Claude 3/Qwen-VL)
- • 优点:直接输入图片,省去OCR环节,理解更整体
- • 缺点:成本高(GPT-4V约$0.00765/图),对表格细节容易
路线B:OCR提取结构化文本 + 文本LLM(GPT-4/Claude 3.5/Qwen-Max)
- • 优点:成本低(文本模型便宜一个数量级),表格数据准确
- • 缺点:丢失视觉信息(如红色警告框、禁用状态样式)
建议的混合策略:
if 内容以文字/表格为主:
使用路线B(OCR+文本LLM),成本低且准确
elif 内容包含复杂交互/视觉状态(如原型图):
使用路线A(多模态),保留视觉上下文
else:
双路并行,投票机制决定最终输出3、认知层:如何让LLM"像测试工程师一样思考"?
LLM生成用例的质量,完全依赖Prompt的设计。我们设计的Prompt包含3个核心部分,确保用例覆盖全面、格式标准:
- • 角色定义:明确LLM的身份——“资深测试工程师,擅长生成可评审、可落地的功能测试用例,熟悉各类场景的测试要点”;
- • 需求约束:明确用例覆盖范围(正常场景、异常场景、边界场景、格式校验、验证码、第三方登录、重复提交等),以及输出格式;
- • 基础信息:传入OCR提取的“元素清单”,让LLM明确页面结构、元素属性,避免生成与页面无关的用例。
这是生成高质量用例的关键,也是让LLM像测试工程师一样思考的关键,我们通过三层提示工程实现:
第一层:角色与思维链(CoT)
你是一位有10年经验的资深测试工程师,擅长从需求文档中提取测试点。
请按以下步骤思考:
1. 识别需求中的功能点(页面元素、业务操作、数据处理)
2. 对每个功能点,识别:正常场景、异常场景、边界条件、性能考量、安全考量
3. 输出结构化的测试点列表,格式为JSON第二层:Few-shot示例
在提示词中嵌入2-3个高质量用例示例,教会LLM团队的书写规范:
示例1:
输入:登录页面(用户名输入框、密码输入框、登录按钮)
输出:
[
{"test_point": "用户名输入-正常输入", "category": "功能", "priority": "P0"},
{"test_point": "用户名输入-特殊字符", "category": "异常", "priority": "P1"},
{"test_point": "密码输入-掩码显示", "category": "安全", "priority": "P0"}
]第三层:RAG知识注入
通过检索增强生成(RAG),注入业务领域知识。比如金融系统需要知道"大额交易需二次确认"是监管要求,电商系统需要知道"库存扣减"的并发处理逻辑。
# 伪代码:RAG检索
business_context = vector_db.search(query="转账限额", top_k=3)
prompt = f"基于以下业务规则:{business_context},生成测试用例..."4、生成层:场景补齐策略、组合爆炸问题怎么解?
为了避免LLM遗漏关键场景,我们预设了“场景模板库”,包含10+类高频测试场景,LLM生成用例时,会自动匹配模板,补齐场景:
- • 格式校验场景:手机号、邮箱、密码、验证码的格式、长度、特殊字符校验;
- • 异常交互场景:重复提交、弱网超时、接口异常返回、元素不可点击时的操作;
- • 权限场景:未登录态访问、游客态操作、权限越权;
- • 关联场景:第三方登录绑定、解绑、重复绑定,验证码过期、错误次数锁定。
同时,支持团队自定义场景模板,比如针对特定产品的专属场景(如支付场景的金额校验),可添加到模板库,提升用例的针对性。
当配置表有10个维度,每个维度3个取值时,全排列是3^10=59049条用例,不可接受。
建议采用的组合策略:
策略 | 适用场景 | 工具 |
|---|---|---|
Pairwise(两两组合) | 配置项之间无强依赖 | Microsoft PICT / 自研算法 |
正交试验法 | 需要均匀覆盖,有统计基础 | 正交表查询 |
全排列(局部) | 关键路径、高风险模块 | 人工指定维度 |
基于规则的过滤 | 业务规则排除无效组合 | 规则引擎 |
示例:一个"用户等级+支付方式+优惠券"的组合场景,Pairwise可将用例从120条压缩到12条,覆盖所有两两组合。
5、用例质量校验(确保可评审、可落地)
LLM生成用例后,需经过自动校验+人工抽检,确保用例可评审、可落地,避免出现“步骤缺失、预期结果不明确”的问题:
- • 自动校验:校验用例格式是否标准、步骤是否完整、预期结果是否明确,若存在问题,自动返回LLM重新生成;
- • 人工抽检:测试工程师抽取10%-20%的用例,检查场景覆盖是否全面、是否符合产品逻辑,若有遗漏,可手动补充或让LLM重新优化。
五、实际落地建议:从0到1快速落地
这套方案无需复杂的底层开发,可基于现有工具快速落地,适合个人、小团队、中大型团队,以下是具体落地建议,帮你降低落地成本,快速见成效。
1. 选型建议(低成本优先)
无需搭建复杂的服务器,优先选用开源工具+成熟LLM API,降低开发、维护成本:
- • OCR选型:个人/小团队用PaddleOCR(开源免费,中文识别准,支持本地部署);中大型团队可选用阿里云OCR、腾讯云OCR(API调用,稳定性高,按需付费);
- • LLM选型:优先选用API调用模式(无需本地部署),比如Claude API、通义千问API(推理速度快,中文适配好);若有隐私需求,可选用本地部署的模型(如Llama 2、通义千问本地化版本);
- • 开发工具:用Python快速开发(核心代码不超过500行),调用OCR和LLM的API,组装流程,无需前端开发,可直接用命令行或简单的Web界面(如Streamlit)交互。
技术栈参考
层级 | 推荐方案 | 备选方案 |
|---|---|---|
OCR | PaddleOCR(中文)/ Azure DI(表格) | EasyOCR / Tesseract |
版面分析 | DocLayout-YOLO | LayoutParser |
LLM(多模态) | GPT-4V / Claude 4.5 Sonnet | Qwen-VL / Yi-VL |
LLM(文本) | GPT-5.3 / Claude 4.5 / Qwen-Max | DeepSeek-V3 / GLM-5 |
组合测试 | 自研Pairwise算法 | Microsoft PICT |
用例管理 | TestRail API / 禅道API | 自研XMind导出 |
2. 落地步骤
- 1. 第一阶段:完成选型,搭建基础环境,调用OCR API,实现设计稿元素提取,生成元素清单;
- 2. 第二阶段:设计Prompt,调用LLM API,实现用例自动生成,完成格式标准化;
- 3. 第三阶段:优化OCR识别准确率,添加场景模板库,实现自动校验,测试落地效果,调整参数。
3. 避坑提醒(实际落地常见问题)
- • 避免过度依赖LLM:LLM生成的用例可能存在少量逻辑偏差,需人工抽检、优化,不能直接用于执行;
- • 控制成本:LLM API按调用次数收费,可设置缓存机制,相同设计稿重复生成时,直接调用缓存结果,降低成本;
- • 适配产品特性:不同产品的测试场景不同,需自定义场景模板库,避免用例“通用化”,提升针对性;
4. 迭代优化方向
落地后,可根据实际使用情况,逐步优化方案,提升用例质量和效率:
- • 优化LLM Prompt:根据评审反馈,调整Prompt的约束条件,让用例更贴合团队评审标准;
- • 扩展场景模板:新增性能测试、接口测试用例生成模板,实现多类型用例自动生成;
- • 对接测试管理工具:实现用例自动导入JIRA、TestRail,打通“生成-评审-执行”的闭环;
- • 多模态支持:支持Figma、Axure源文件直接导入,无需导出图片,进一步降低使用门槛。
六、小结
基于OCR+LLM的自动生成用例方案,核心是“用技术替代重复劳动”,解决手写用例效率低、易遗漏、标准化难的痛点,让测试工程师从繁琐的用例编写中解放出来,聚焦核心的质量保障工作。
这套方案的优势的是“低成本、可落地、易扩展”,无需复杂的底层开发,个人和小团队可快速上手,中大型团队可基于此方案扩展,适配更多测试场景。
在AI辅助测试的大趋势下,自动生成用例不是“替代测试工程师”,而是“成为测试工程师的得力助手”。落地这套方案后,你会发现:以前1小时才能完成的用例,现在10分钟就能搞定,评审时再也不用怕漏场景,有更多时间去优化测试策略、提升产品质量。
最后一点建议: 不要追求100%自动化。根据我的经验,AI生成+人工审核的模式最可持续——AI负责广覆盖和快速草稿,人负责精准判断和复杂场景。这种人机协作,才是AI时代测试工程师的最佳站位。
延伸阅读:
- • https://github.com/PaddlePaddle/PaddleOCR
- •https://github.com/microsoft/pict
💡 更多、更详细、全面的AI测试、AI编程、AI技能进阶系统化实战教程,欢迎加入:「狂师. AI进化社」一起探讨学习!

图片
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号