眼不见,心不忘!华科&快手联手发布混合记忆新范式:攻克视频世界模型最致命缺陷

眼不见,心不忘!华科&快手联手发布混合记忆新范式:攻克视频世界模型最致命缺陷

AI生成未来
发布于 2026-04-15 18:47:38
发布于 2026-04-15 18:47:38
作者:Kaijin Chen等
解读:AI生成未来
论文链接:https://arxiv.org/pdf/2603.25716 项目链接:https://kj-chen666.github.io/Hybrid-Memory-in-Video-World-Models/ 代码链接:https://github.com/H-EmbodVis/HyDRA
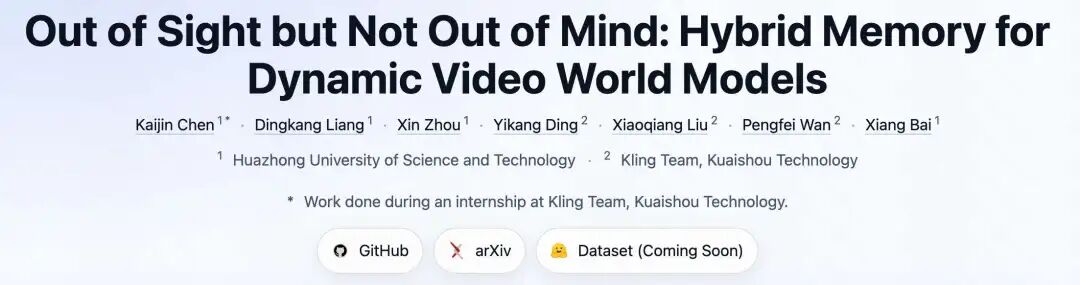
华中科技大学和快手可灵的这篇文章《Out of Sight but Not Out of Mind: Hybrid Memory for Dynamic Video World Models》提出了一种新颖的混合记忆范式,以解决当前视频世界模型在处理动态主体进出视野时的挑战。
文章链接:arXiv:2603.25716v2 项目链接:Hybrid-Memory-in-Video-World-Models GitHub 链接:https://github.com/H-EmbodVis/HyDRA
亮点直击
- 识别了现有以静态为中心的记忆机制的局限性,并提出了混合记忆(Hybrid Memory),这是一种新颖的范式,要求模型在复杂的退出-进入间隔期间,同时保持静态背景的空间一致性和动态主体的运动连续性。
- 引入了 HM-World,这是第一个致力于混合记忆研究的大规模视频数据集。它具有 5.9 万个包含多样场景、主体和运动模式的片段,为评估复杂动态环境中的时空连贯性提供了严格的基准。
- 提出了 HyDRA,一种专门的记忆架构,利用时空相关性驱动的检索机制和记忆 tokens。通过关注相关的运动线索,HyDRA 有效地寻找并重新发现隐藏主体,并保留其身份和运动,显著优于现有SOTA方法。
总结速览
解决的问题
现有视频世界模型在处理动态主体进出视野时,常常导致主体停滞、变形或消失,因为它们主要将环境视为静态画布,缺乏对动态主体在视野外运动的持续追踪能力。
提出的方案
引入了混合记忆(Hybrid Memory)范式,要求模型同时精确记忆静态背景并警惕追踪动态主体,确保在主体进出视野时其运动的连续性。为此,构建了 HM-World 数据集并提出了 HyDRA 记忆架构。
应用的技术
HM-World 是一个包含 5.9 万个高保真视频片段的大规模数据集,具有解耦的相机和主体轨迹。HyDRA(Hybrid Dynamic Retrieval Attention)架构包含一个记忆分词器(Memory Tokenizer),用于将记忆潜在表示压缩为信息更丰富的 tokens,并利用时空相关性驱动的检索机制来动态选择和利用这些 tokens。该方法构建在全序列视频扩散模型(包含 3D VAE 和 Diffusion Transformer (DiT))之上,并通过 MLP 编码扩散时间步。
达到的效果
在 HM-World 数据集上的大量实验表明,HyDRA 在动态主体一致性和整体生成质量方面显著优于最先进的方法和商业模型,在 PSNR、SSIM 和本文提出的 DSC 指标上均表现出色。
架构方法
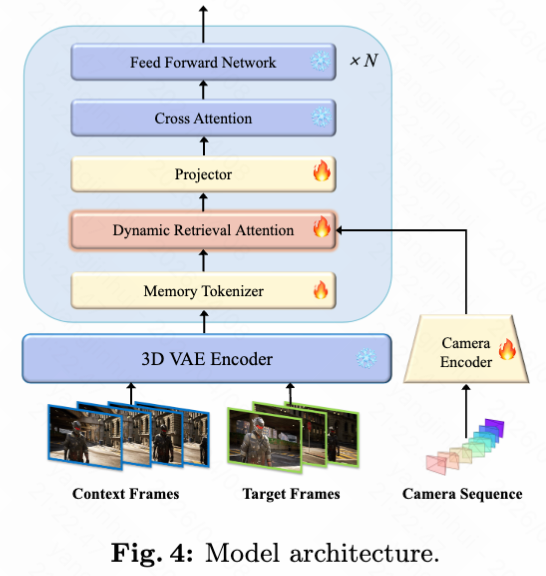
本文中,HyDRA 方法建立在全序列视频扩散模型之上,包含一个因果 3D VAE 和一个扩散 Transformer (DiT)。每个 DiT 块集成了动态检索注意力、一个投影器、交叉注意力和一个前馈网络 (FFN)。扩散时间步通过多层感知机 (MLP) 编码以调制 DiT 块。模型遵循 Flow Matching。给定视频帧序列 ,3D VAE 将其编码为视频潜在表示 ,压缩时间和空间维度。在训练阶段,时间步 处的噪声潜在表示 通过 和高斯噪声 之间的线性插值获得。模型 学习预测时间步 处的地面实况速度 ,损失函数定义为:
其中 表示模型参数。在推理阶段,随机采样的高斯噪声逐渐去噪以产生干净的潜在表示,然后由 3D VAE 解码器解码以重建视频序列。
相机注入
为了实现对生成内容精确的空间控制,相机轨迹被作为显式条件注入到模型中。假设长度为 的相机姿态序列表示为 ,其中 和 分别表示第 帧的旋转矩阵和平移向量。这些参数被扁平化并连接起来,形成统一的相机条件 。遵循 ReCamMaster [1],论文采用相机编码器 ,其实现为 MLP 层以编码 。编码后的相机特征在空间上广播并逐元素添加到潜在特征中。形式上,设 为输入到 DiT 块的序列特征,相机注入特征 公式为:
其中 被投影以匹配 的确切通道维度。
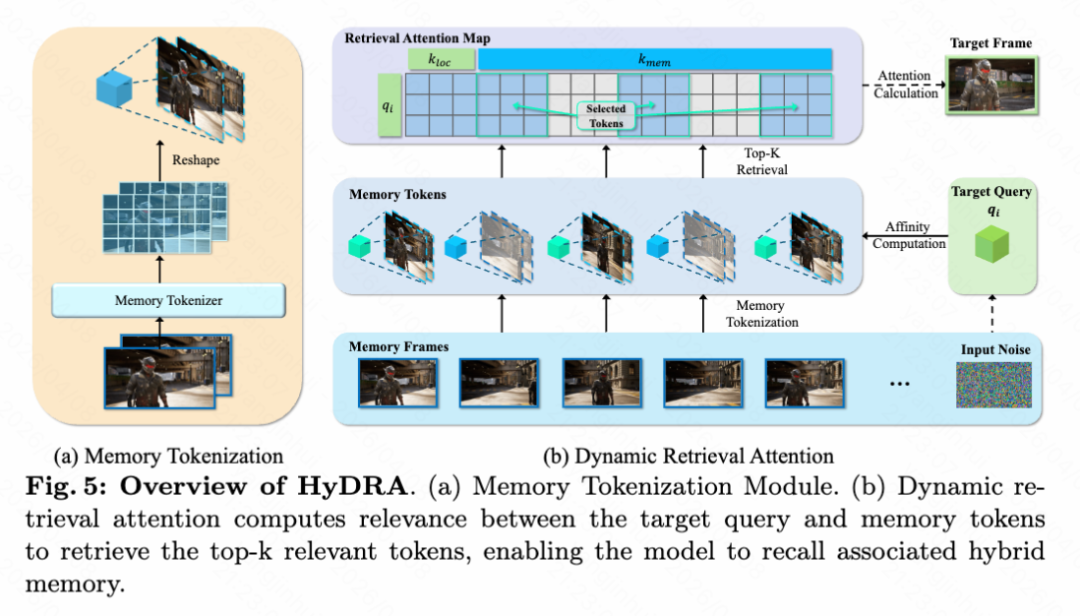
用于检索的记忆分词
在 HyDRA 框架中,编码的记忆潜在表示 是记忆的主要表示。为了解决简单地注入整个 导致的计算开销和不相关噪声问题,论文引入了一个基于 3D 卷积的记忆分词器,旨在同时处理空间和时间维度。分词器通过 3D 卷积扩展时空感受野以捕获长时间运动信息。形式上,这种转换定义为:
其中 表示时间维度, 表示下采样后的空间分辨率。通过将原始潜在表示压缩成密集、时空感知的记忆 tokens ,模型有效地过滤掉了不相关的上下文,同时保留了必要的运动和外观线索。这些经过精炼的 tokens 随后成为动态检索注意力模块的基础。
动态检索注意力
动态检索注意力是一种时空信息驱动的检索方法和记忆机制,它直接取代了基础模型中的标准 3D 自注意力层。
给定去噪目标潜在表示 和记忆 tokens ,论文首先将它们投影到各自的 Query、Key 和 Value 中。具体来说,目标潜在表示被投影为 queries ,而记忆 tokens 被投影为 keys 和 values 。
为了执行动态检索,论文按顺序处理对应于每个目标潜在表示 的 query 集 。由于 和 在不同的空间分辨率下操作,论文首先应用空间池化将 下采样为 ,使其与记忆 tokens 对齐。然后,论文计算下采样后的 query 和记忆 key 的每个时间片 (其中 )之间的时空亲和度度量 。亲和度 通过在空间维度上取逐元素乘积来计算:
其中 表示通道级内积, 是用于缩放的通道维度。
亲和度度量有效地量化了当前目标潜在表示与记忆 token 之间的时空对应关系。基于这些亲和度,论文采用 Top-K 选择策略来过滤记忆 tokens,隔离出与 表现出最强相关性的记忆子集:
其中 表示 个最相关记忆 tokens 的索引。
为了保持局部去噪稳定性,论文强制将查询自身的局部时间窗口包含在注意力计算中。设 和 表示目标序列中以帧 为中心的局部窗口 内相邻潜在表示派生的 keys 和 values。论文首先将这些局部特征和检索到的记忆特征扁平化,然后将它们连接起来形成最终的 keys 和 values 。
最后,在扁平化 query 之后,第 个潜在表示的动态检索注意力使用标准注意力公式计算:
如下图4的模型架构图所示,这一过程在 DiT 块中实现,并如下图5所示的 HyDRA 概览图所示,通过内存分词和动态检索注意力机制,模型能够有选择地关注看不见的主体的最相关的运动和外观线索。
实验总结
论文对所提出的 HyDRA 方法进行了全面的实验评估,包括实现细节、评估协议、主要结果以及消融研究。
实验设置
实现细节:HyDRA 方法基于 Wan2.1-T2V-1.3B 模型,处理 77 个上下文帧,并将其时间下采样。记忆分词器采用 3D 卷积(核大小 2 × 4 × 4),动态检索注意力中的检索 token 长度设置为 10,去噪潜在表示的局部窗口为 5。模型在 HM-World 数据集上训练 10K 次迭代,使用 32 个 GPU,总批量大小为 32。
评估协议:构建了包含 1000 个 HM-World 数据集样本的测试集,用于评估模型的泛化能力。评估指标分为三类:
- 通用记忆能力:使用 PSNR、SSIM 和 LPIPS 衡量整体重建保真度。
- 帧级一致性:采用 Vbench中的主体一致性 (Subject Consistency) 和背景一致性 (Background Consistency)。
- 动态主体一致性 (DSC):本文引入了新的指标 DSC,它使用 YOLOv11 和 CLIP提取的主体区域特征,通过余弦相似度计算 DSC(与历史上下文比较)和 DSC(与地面实况比较)。
主要结果
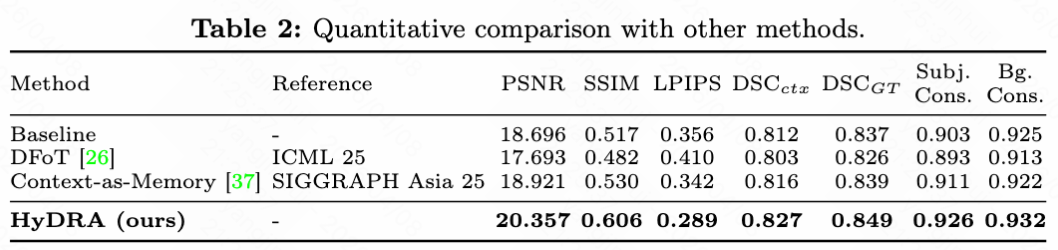
定量比较:如下表2所示,HyDRA 在所有评估指标上均显著优于基线模型(Wan2.1-T2V-1.3B 加相机编码器)、DFoT和 Context-as-Memory。例如,HyDRA 将 PSNR 从基线的 18.696 提高到 20.357,SSIM 从 0.517 提高到 0.606。DSC 和 DSC 也达到了最高分(0.827 和 0.849),表明其在跟踪主体和保持运动一致性方面的强大能力。
如下表3所示,与最先进的商业模型 WorldPlay 进行零样本评估比较时,HyDRA 在所有指标上均超越 WorldPlay,PSNR 差距达到 5.502。这不仅验证了 DSC 指标的合理性,也凸显了 HyDRA 的卓越性能。

定性比较:如下图6所示,定性结果进一步证实了 HyDRA 的优势。在复杂的退出-进入事件中,基线和 Context-as-Memory 出现严重的主体失真和运动不连贯,DFoT 甚至导致主体完全消失。WorldPlay 虽能保持外观一致性,但存在运动卡顿。相比之下,HyDRA 成功保持了主体的身份和运动连贯性,实现了混合一致性。

消融研究
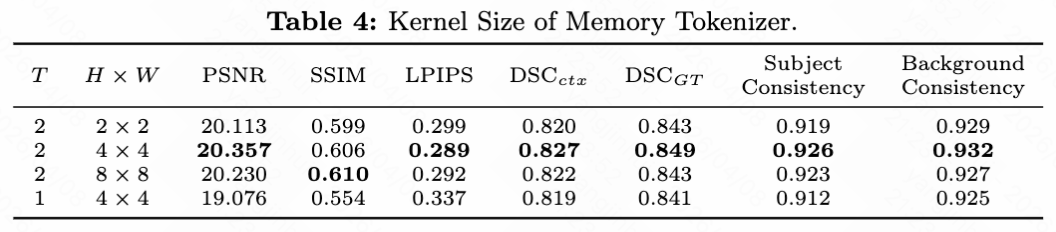
记忆分词器的核大小:如下表4所示,论文研究了记忆分词器中 3D 卷积核大小 的影响。结果表明,模型对空间维度()变化具有鲁棒性,性能差异微小。然而,当时间维度 减小到 1 时,PSNR 和 DSC 显著下降,强调了时间交互对于捕获长期动态信息的必要性。
检索到的 token 数量:如下表5所示,论文调查了检索到的记忆 token 数量的影响。检索 5 个 token 导致次优性能(PSNR 为 19.309),表明信息丢失严重。将数量增加到 10 或 15 产生了更好且更稳定的结果,两者差异可忽略不计,这表明适量的 token 足以提供必要信息。

token 检索方法:如下表6所示,论文比较了动态亲和度检索与基于 FOV 重叠的检索方法。动态亲和度方法在所有指标上均优于基于 FOV 的方法,将主体一致性从 0.908 提高到 0.926。这是因为动态亲和度利用 QK 交互评估细粒度时空相关性,而基于 FOV 的方法仅依赖静态几何重叠。补充材料中的下图3和上图4进一步从定性角度验证了动态亲和度在选择关键帧和动态适应性方面的优势。


结论
本文中,Kaijin Chen 等人引入了混合记忆这一新颖范式,旨在挑战模型同时保持静态背景一致性和动态主体连贯性,特别是在复杂的退出和重新进入事件期间。为了系统地促进该领域的研究,构建了 HM-World,这是第一个致力于混合记忆的大规模视频数据集,其具有高度多样化的场景和复杂的动态过程。为了解决混合记忆的挑战,提出了 HyDRA,一种先进的记忆架构,专门设计用于有效提取和检索运动和外观线索以实现一致性生成。大量的实验表明,HyDRA 显著优于现有方法。论文希望混合记忆范式以及 HM-World 数据集和 HyDRA 框架将激发新的研究,并为推进视频世界模型提供坚实的基础。
尽管取得了可喜的成果,本文的工作仍然存在某些局限性。具体而言,HyDRA 在涉及三个或更多主体或严重遮挡的高度复杂场景中保持一致性生成的性能往往会下降。在未来的工作中,论文计划探索更先进和稳健的记忆机制,以处理复杂的多主体动态,并将方法扩展到不受约束的真实世界环境。
参考文献
[1] Out of Sight but Not Out of Mind: Hybrid Memory for Dynamic Video World Models
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-13,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号