IEEE 综述 | UAV + 大模型 40 页教程:2032 年 125 亿美元 UAV 市场的四维技术栈
原创
IEEE 综述 | UAV + 大模型 40 页教程:2032 年 125 亿美元 UAV 市场的四维技术栈
原创
CoovallyAIHub
发布于 2026-04-27 13:56:14
发布于 2026-04-27 13:56:14
导读
无人机(UAV)正在从"能飞的传感器"变成"能听、能思考、能协作"的智能节点——前提是要把 LLM 和 MLLM 塞进机载资源受限、链路不稳的环境。由 Yousef Emami、Hao Zhou、Radha Reddy、Atefeh Hajijamali Arani、Biliang Wang、Kai Li、Luis Almeida、Zhu Han组成的 8 人团队(含 4 位 IEEE Senior Member + 1 位 IEEE Fellow)发布了一份 40 页长综述,把 LLM 辅助的 UAV 操作与通信拆成四条主线:
- LLM 适配技术栈:Pre-training / Fine-tuning / Prompt Engineering / RAG 四条路线 + PEFT 6 种具体方法 + 4 种推理部署模式
- UAV 通信与控制:导航规划、蜂群控制、安全与网络优化、多 LLM 架构
- MLLM 驱动的下一代 UAV 智能:MCoT、M-ICL、VLN、人机协同、语义理解
- 伦理与可持续:隐私、偏见、问责、环境影响 4 类风险
作者同步给了 DCS-ICL 端到端案例(10 传感器、100m×100m 场景):Grok 和 Mistral-Large-3 在 2–3 步收敛到 0 丢包,LLaMA 停在约 8 个包。全文 13 张表格梳理 50+ 代表性工作与 UAVBench、UAVThreatBench 两个标准评测基准。
论文信息
- 标题:Large Language Model-Assisted UAV Operations and Communications: A Multifaceted Survey and Tutorial
- 作者:Yousef Emami, Hao Zhou, Radha Reddy, Atefeh Hajijamali Arani, Biliang Wang, Kai Li, Luis Almeida, Zhu Han
- 团队头衔:4 位 IEEE Senior Member(Emami、Zhou、Kai Li、Almeida)+ 1 位 IEEE Fellow(Zhu Han)
- 发表性质:IEEE 综述+教程类文章(Copyright 2026 IEEE)
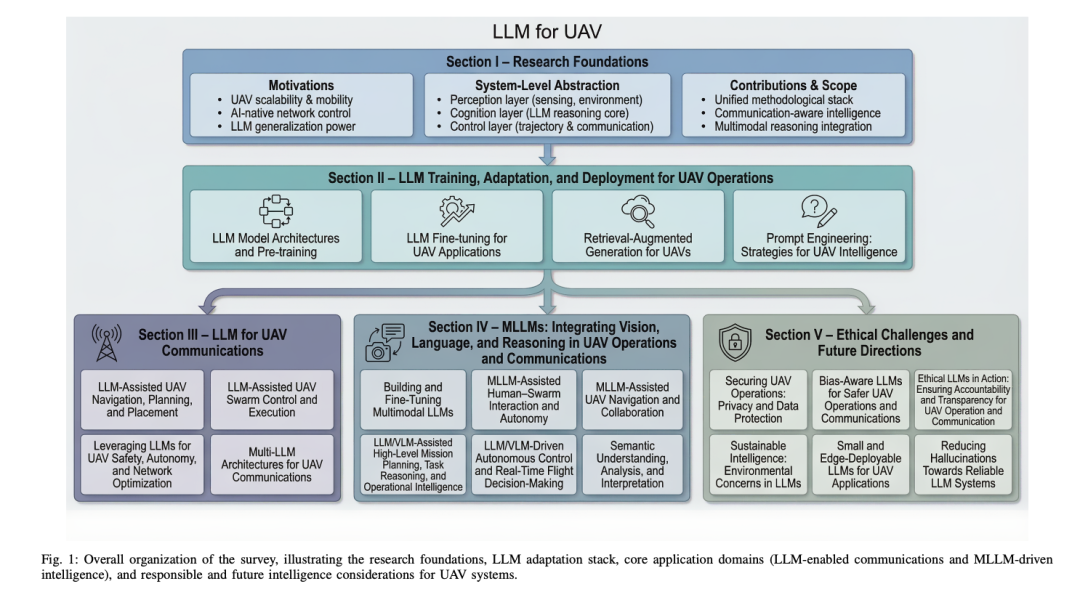
一、为什么要专门综述 UAV+LLM?三个根本问题
论文把 UAV 接入 LLM 的必要性归结为三点传统方法难以同时满足的挑战:状态/动作空间维度高(UAV 高机动+有限感知+间歇连接,对地面设备信息不完整)、环境高度动态(精确解析建模不可行,deep RL 有 sim-to-real gap)、需要跨层信息协同(同时处理网络拓扑、信道、任务描述、历史解——LLM 的语义理解正好补齐)。
UAV 市场数据:2024 年 36.41 亿美元 → 2032 年 125.91 亿美元,CAGR 17.3%。
论文的系统级抽象把 LLM-UAV 融合分三层:认知与决策层(LLM 作 meta-controller,任务目标+环境上下文+系统约束 → 结构化任务描述、分解、重规划);感知层(LLM 作多模态语义桥,视觉/LiDAR/频谱/IMU → 对象/活动/意图描述);控制与通信层(高层计划 → 控制命令、轨迹、通信策略)。
二、LLM 怎么适配到 UAV 上?4 条路线 + PEFT + 推理优化
四条适配路线的核心权衡:
维度 | Pre-training | Fine-tuning | Prompt Eng | RAG |
|---|---|---|---|---|
资源强度 | 极高 | 中–高 | 极低 | 低–中 |
UAV 适用性 | 基础模型层 | 特定任务(充足数据) | 实时低延迟 | 需动态协议/数据 |
从零预训练 LLaMA 3.1 (405B) 需数千万 GPU 小时+数千万美元成本——对 UAV 场景,微调+RAG+提示工程的组合更可行。
图片来源于原论文
PEFT 6 种方法:Adapters、LoRA、QLoRA、Prefix-tuning、Prompt-tuning、P-tuning——让 GPT-3/BERT/LLaMA 级别模型能在有限硬件上适配到 UAV。
RAG 的 UAV 落地代表性数据:Hybrid LLM-RAG [40] 动态环境 IoD 任务 92% 决策准确率、94% 任务成功率;Augmented LLM-RAG [41] 多 UAV 协同 BLEU 0.82、cosine 0.87、决策延迟 120 ms;GraphRAG / HybridRAG 把语义检索 (VectorRAG) 与图关系推理 (GraphRAG) 结合。评估工具:RAGAS(参考无关三维评估)、RAGCHECKER(细粒度组件评估)。
Prompt Engineering 四大策略:ICL(任务+示例+查询,单模型仅推理,适合 few-shot 实时决策)、CoT(任务+多步推理示例,可解释性、结构化多步推理)、Prompt-Based Planning(高层目标+约束,长 horizon 规划)、Self-Refinement(初始+自批评,错误纠正、鲁棒性)。
ICL 在应急 UAV 的代表工作:ICLDC[52] UASNets 应急数据采集(vs DQN 和 Max Channel Gain 基线累积丢包显著降低);FRSICL[53] 野火监测(AoI 更低 vs PPO);AIC-VDS[55] 多 UAV 灾后监测(91% 丢包降低vs MADQN);LLM-CRF[56] SAR 人机协同(64.2% 任务时间降低、94% 成功率、42.9% 认知负荷降低)。
LLM 推理部署:Centralized Edge Inference(实时决策但依赖稳定连接)、Local On-Device(隐私低延迟但能耗高)、Split Inference(降 UAV 算力但需协调)、Collaborative Device-Server(带宽友好,适合不稳定链路)。边缘参数上界 P = M × 8 / b(M 字节数、b 每参数比特精度)——8–16 GB RAM 理论支持 4–8B FP16 或 16–32B 4-bit 量化,实际限在 1–10B,与 Gemini Nano、Qualcomm 10B 级规模一致。
长上下文处理:Selective Context(token 自信息过滤)、LLMLingua(分层压缩)、Short-Term Working Memory(动态缓冲)、Long-Term Summary Memory(关键模式抽象)、AGI-Assisted Designs(episodic + semantic 记忆)。
三、LLM 如何帮 UAV 做通信与控制?
Section III 分 4 个子方向。
导航/规划/放置 8 个代表框架:SPINE[77] 城市与农村环境公里级语言指定任务;MSDTMD-SG[78] 多步思考运动决策采样 + RL 奖励,任务完成率胜 DRL 与 Ant Colony;Multi-UAV Placement[79] 迭代结构化提示优化 IAB 网络部署;FlockGPT[81] GPT-4 把几何命令翻译成 SDF 群飞控制代码;RALLY[82] LLM+MARL 动态角色分配(Commander/Coordinator/Executor);SwarmChain (CoLLM)[83] 张量并行 + 自适应负载分发,蜂群片上推理 1.9–2.3× 加速、无云依赖;TypeFly[84] MiniSpec 流式解释+重规划,响应时间最多 62% 降低。
安全/自治/网络优化:LLM-HFACS[85] UAV 事故调查 macro-F1 0.58–0.76(18 类)、最佳类别 F1 0.76;LLM-Satellite-UAV-IoT[86] 6G 集成网络优化,微调 LLaMA-3 70B,27% 频谱效率提升、35% 决策延迟降低;Embodied Aerial Intelligent Agent[88] 开放世界 UAV 任务,14B 模型边缘部署、5–6 tokens/s @220W;LLM-Assisted UTM[89] 无人交通管理 最高 91.7% 决策准确率、平均响应 5.7 秒。
多 LLM 架构定义 3 种部署范式:Parallel/Ensemble(并行融合)、Hierarchical(Onboard→Edge→Cloud 分层资源感知)、Distributed Specialized Agents(角色分工)。代表工作 Aero-LLM(分层安全决策)、AEC 行业多 Agent 视觉检查框架(Router/PathPlanner/Controller/Perceptioner/Retriever)。
两个新的评测基准:UAVBench[100] 50,000 验证场景 + 50,000 MCQ + 10 种推理风格,评测 32 个 SOTA LLM——当前模型在感知和策略推理较好,但伦理判断、资源受限规划、多目标权衡仍弱;UAVThreatBench924 专家场景 + 4,620 RED 映射威胁,GPT-4o 接近 87% 的总威胁匹配率,小模型在可用性和后端层显著弱。
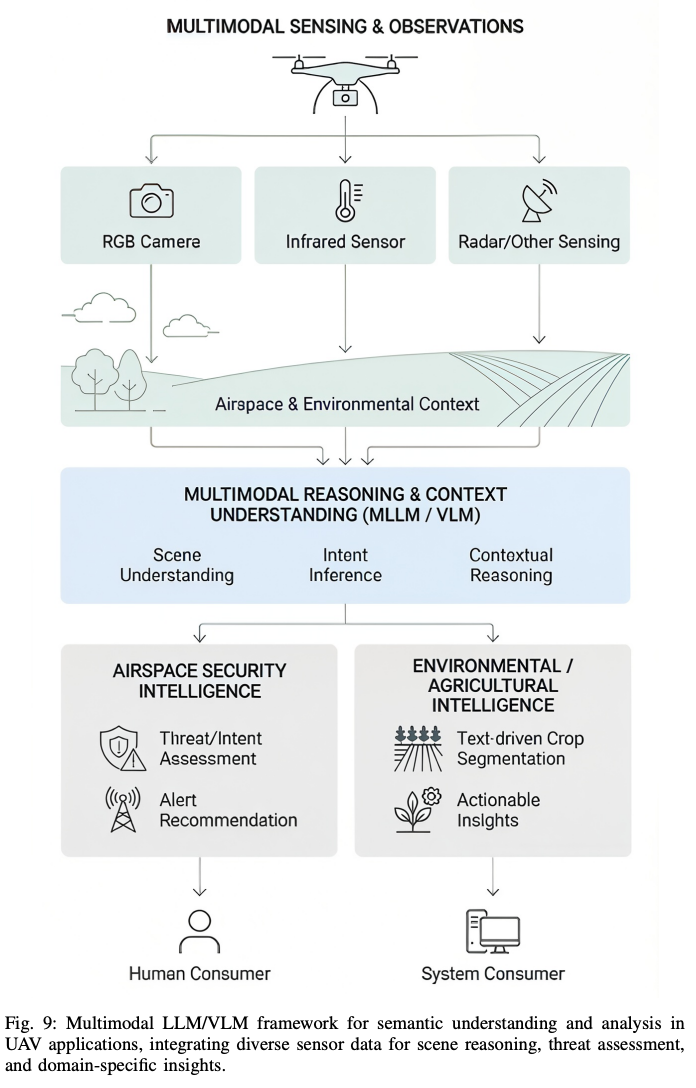
四、MLLM:下一代 UAV 的多模态智能
两项新兴推理机制:MCoT(Multimodal CoT)把 CoT 扩展到多模态;M-ICL(Multimodal ICL)推理时无梯度更新、用少量多模态示例对直接激活 LMM。
VLN 框架对比5 个代表:UAV-VLN[109] 把 VLN 重构为 QA、开放词汇视觉感知,强 zero-shot 泛化;SkyVLN[110] VLN 集成 NMPC 安全控制;LLMIR[111] OOD 指令改写器,绝对成功率 +1.39%、OOD 测试集 +1.51%;DuAI-VLN (AeroDuo)[112] 双 UAV 高/低空协作;AerialVLN[113] 连续 3D 城市空间 UAV VLN 基准。
MLLM 在 UAV 蜂群 6 个框架覆盖人-蜂群交互、队形控制、灾难监测、威胁检测等:自主蜂群 [105] 82.7% 命令提取准确率、83.8% 队形规划成功率;PromptPilot[107] 自然语言 UAV 控制 97.58% 视频选择效率。
MLLM 关键挑战 6 项:模型不确定性与幻觉、决策可解释性缺失、机载算力受限、复杂环境感知、人机意图理解、长上下文建模。
五、总结与思考:案例实证与治理层
DCS-ICL 端到端案例:10 传感器、100m×100m,每传感器 50 J 电池、40 packets 队列、100 mW 发射功率,DCS-ICL 边缘 LLM 输出调度决策,基线 MADQN。核心发现:GPT-4o-mini 下 DCS-ICL 与 MADQN 收敛后可比;但不同 LLM 差异极大——Grok 和两个 Mistral 模型前 2–3 步收敛到 0 丢包,LLaMA 停在约 8 个。
治理层 6 组件:Observability、Prompts & Feedback Logging、Tracing、Latency & Usage Monitoring、Safety Verification Layer、LLM + Safety Verifier 集成。核心论断:Observability + Safety Verifier + HITL三层叠加是从"功能组件"升级到"可治理系统"的底线。
图片来源于原论文
在此基础上,有几点值得进一步思考:
- "LLM 替代 DRL"的边界需谨慎:DCS-ICL 和 MADQN 收敛后相近——LLM 的优势不在稳态质量,而在无需训练、快速响应新任务。综述没给稳态差距的量化对比
- 不同 LLM 差异显著意味着选型不是规模问题:Grok/Mistral vs LLaMA 在同任务 0 vs 8 包的差距说明模型规模不是主要变量,需要同任务同基准的对比评测
- UAVBench + UAVThreatBench 是隐藏价值:50,000 验证场景 + 50,000 MCQ + 10 种推理风格是目前 UAV 领域最大规模的 LLM 评测基准
- MLLM 视觉幻觉在安全场景是硬约束:AeroCaps 数据集分析显示 MLLM 在航拍视角下幻觉率高于普通图像——Safety Verifier + HITL 不是可选项
综述的最大价值不在具体技术判断,而在把跨学科快速演进的领域系统化——让后续研究者能在 13 张表格组织的坐标系里找到位置。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号