CVPR 2026 YOLO之父回归!OlmoEarth:多模态地球观测的基础模型

CVPR 2026 YOLO之父回归!OlmoEarth:多模态地球观测的基础模型

Amusi
发布于 2026-04-29 13:41:32
发布于 2026-04-29 13:41:32
转载自:遥感与深度学习

题目:OlmoEarth: Stable Latent Image Modeling for Multimodal Earth Observation
论文:https://pjreddie.com/static/papers/OlmoEarth.pdf
项目:https://allenai.org/olmoearth
平台:https://olmoearth.allenai.org/
单位:Allen 人工智能研究所,华盛顿大学,亚利桑那州立大学,不列颠哥伦比亚大学
YOLOv1-v3 的原作者Joseph Redmon也是本文的共同一作,看到在大佬的网站上也有更新:
创新点
- Latent MIM Lite:用随机初始化的冻结线性投影层替代传统目标编码器,在保持latent space建模优势的同时解决了训练不稳定和表征崩溃问题。
- 模态感知掩码策略:针对遥感数据的时空冗余特性,结合随机token掩码和完整模态重建,使预训练任务更具挑战性且无需极高掩码率。
- 模态内对比损失:仅在相同bandset的token间计算patch discrimination loss,消除跨模态简单负样本,聚焦更有效的学习目标。
- 观测-标注统一建模:将卫星观测数据和地图标注通过同一冻结投影层处理,优雅地统一了自监督和监督学习框架。
背景
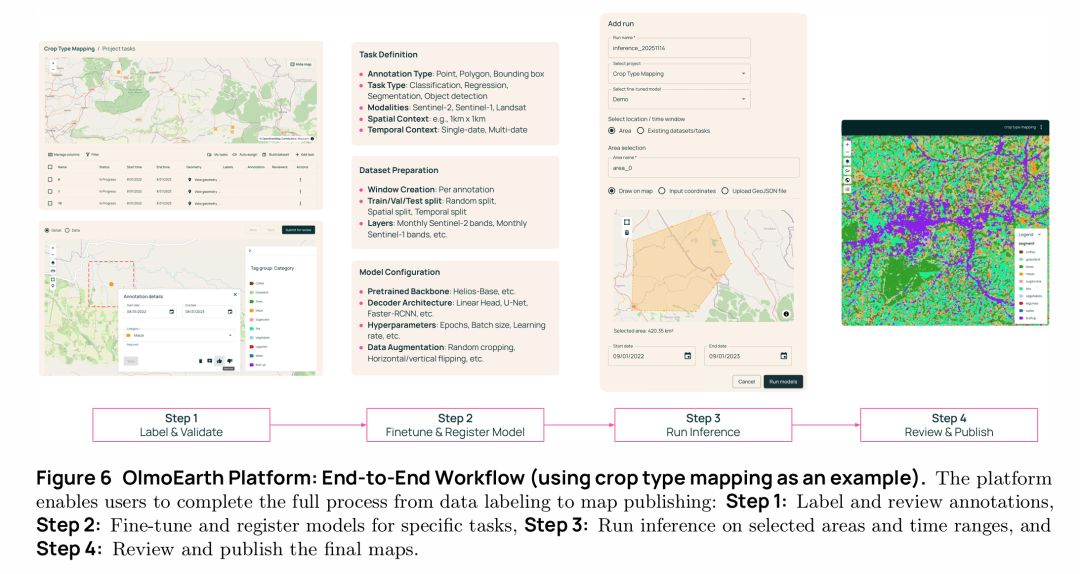
地球观测数据具有独特挑战:它既像图像一样具有空间性,又像视频或文本一样具有序列性,且高度多模态。虽然遥感基础模型在研究环境中显示出良好前景,但其在真实世界任务中的应用仍然滞后,特别是在非营利部门。这主要是因为基础模型规模大、训练复杂、部署成本高昂,且现有模型训练常遇到不稳定性、表征崩溃等问题,性能无法达到预期。此外,缺乏标准化的评估体系使得模型间难以直接比较。OlmoEarth旨在通过稳定的训练方法、全面的评估和开放的端到端平台,将前沿基础模型真正交到从事环境保护、气候行动和粮食安全等全球重大问题的非营利组织手中,解决研究到应用的"最后一公里"问题。
数据
预训练数据集规模
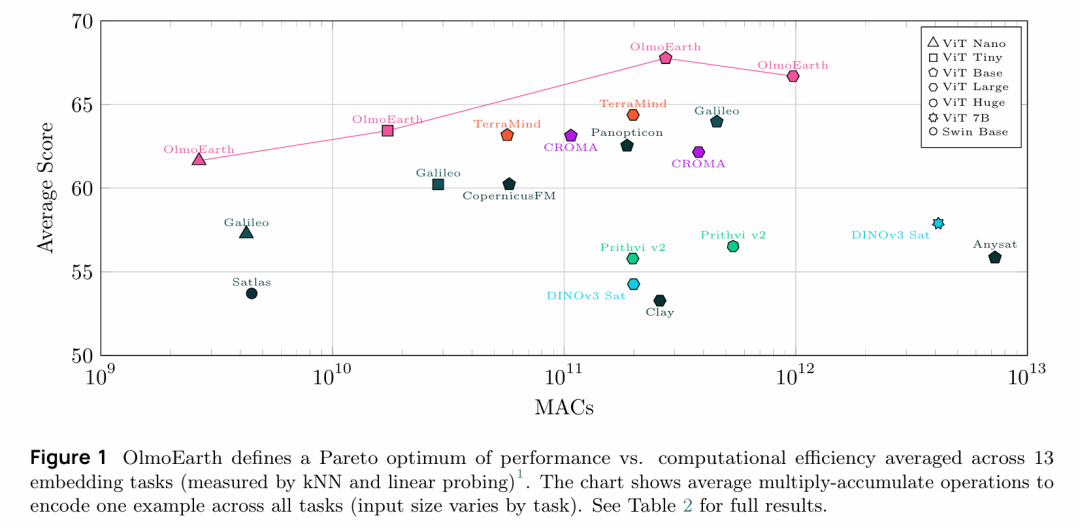
- 样本数量:285,288个全球分布的地理位置
- 空间范围:每个样本覆盖2.56km × 2.56km区域
- 时间范围:2016年1月至2024年12月,每个样本包含1年时间窗口
- 时间采样:最多12个月度时间步(monthly timesteps)
- 空间分辨率:所有模态统一重采样至10米/像素
数据模态构成
卫星观测数据(3种传感器):
- Sentinel-1:合成孔径雷达(SAR)数据
- Sentinel-2:光学多光谱数据,按原始分辨率细分为3个bandsets
- Landsat-8:光学多光谱数据,按原始分辨率细分为2个bandsets
衍生地图数据(6种高质量标注):
- WorldCereal:全球作物分布图
- WorldCover:全球土地覆盖分类图
- OpenStreetMap:开源地理特征数据
- Cropland Data Layer (CDL):美国农田分类数据
- SRTM:航天飞机雷达地形测绘数据
- Canopy Height Map:植被冠层高度图
采样策略
- 基于OpenStreetMap选择120个特征类别(从道路到地热发电站等)
- 枚举包含每个类别的所有2.56km × 2.56km tiles
- 每个类别随机采样最多10,000个tiles
- 全球分布覆盖(如Figure 2所示)
评估数据集
- 研究基准测试(18个):
- GEO-Bench数据集(7个):m-bigearthnet、m-so2sat、m-brick-kiln、m-forestnet、m-eurosat、m-cashewplant、m-SA-crop-type
- 其他标准数据集(5个):BreizhCrops(61万样本)、CropHarvest(9.5万样本)、PASTIS(2433样本)、MADOS(2803样本)、Sen1Floods11(4831样本)
- 合作伙伴真实任务(19个数据集,来自7个组织):
- African Wildlife Foundation (AWF):肯尼亚南部土地覆盖分类(1459样本,9类)
- NASA JPL:Live Fuel Moisture Content回归(4.1万样本)
- Global Mangrove Watch:红树林分类(10万样本,3类)
- CGIAR:Nandi县作物类型分类(6924样本,6类)
- Global Ecosystem Atlas:北非生态系统分类(2361样本,110类)
- Amazon Conservation:森林损失驱动因素分类(10类)
- Skylight:海洋基础设施检测、船只检测/分类/长度估计(数十万样本)
- Solar Farm Detection:太阳能农场分割(3561样本)
方法
整体架构设计
OlmoEarth采用编码器-解码器的Vision Transformer架构,专门设计用于处理多模态地球观测时间序列数据。
编码器负责主要建模(4种尺寸:1.4M-300M参数),解码器只有4层用于轻量级预测。输入经过FlexiViT风格的灵活patch embedding后,添加2D位置编码、时间编码和模态编码。
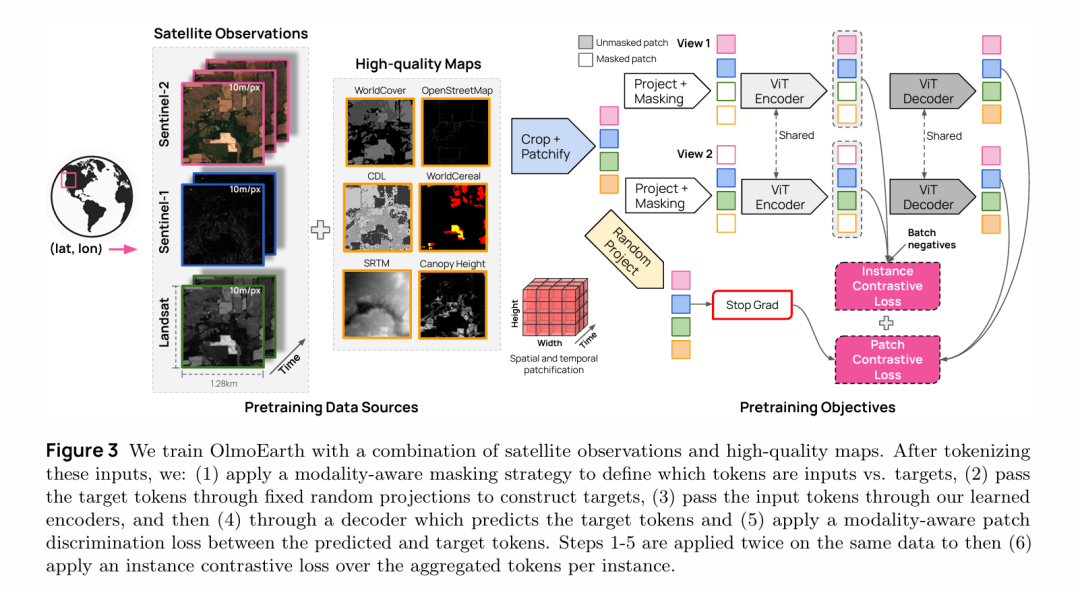
编码器设计:
- 基于标准Vision Transformer,提供4种模型尺寸(Nano/Tiny/Base/Large)
- 参数量从1.4M到300M不等
- 负责主要的特征建模工作
解码器设计:
- 固定深度为4层(远小于编码器)
- 特征维度和注意力头数与编码器匹配
- 设计理念:让编码器承担主要建模任务,解码器仅做轻量级预测
核心创新方法
1. Latent MIM Lite(稳定的潜在空间建模)
- 用随机初始化且完全冻结的线性投影层替代传统的可学习目标编码器
- 将原始图像块投影到token空间作为预测目标
- 解决了Latent MIM的训练不稳定问题,同时保持在特征空间建模的优势
- 统一了自监督和监督学习:观测数据和地图标注都通过同一冻结投影层处理
2. Modality-Aware Masking(模态感知掩码)
- 针对遥感数据的时空冗余性,设计了四种bandset状态:
- 未选择、仅编码(随机掩码)、仅解码(完整保留)、编码+解码
- 关键规则:地图数据只能作为解码目标,不能输入编码器(因为推理时只用观测数据)
- 将任务从"重建被掩码patch"转为"从部分模态重建缺失模态",避免了需要极高掩码率(90%)的问题
3. Modality Patch Discrimination Loss(模态内对比损失)
- 标准方法将预测token与所有target token对比,导致大量来自不同模态的"简单负样本"
- 改进:仅在同一bandset内的token之间进行对比
- 消除简单负样本,聚焦于更具挑战性的学习目标
4. Instance Contrastive Loss(全局表征对比)
- 对同一输入应用两次不同的随机掩码,生成两个视图
- 对编码器输出做平均池化得到全局表征
- 使用SimCLR风格的对比损失,促进不同模态token在统一空间协同工作
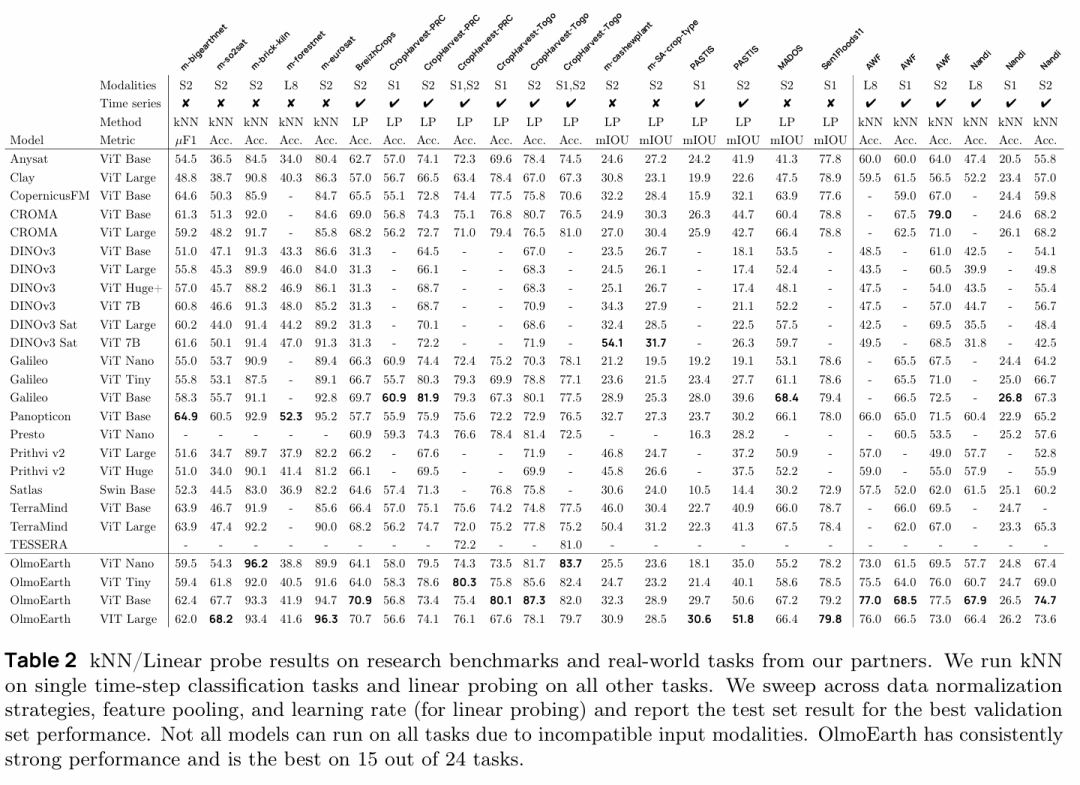
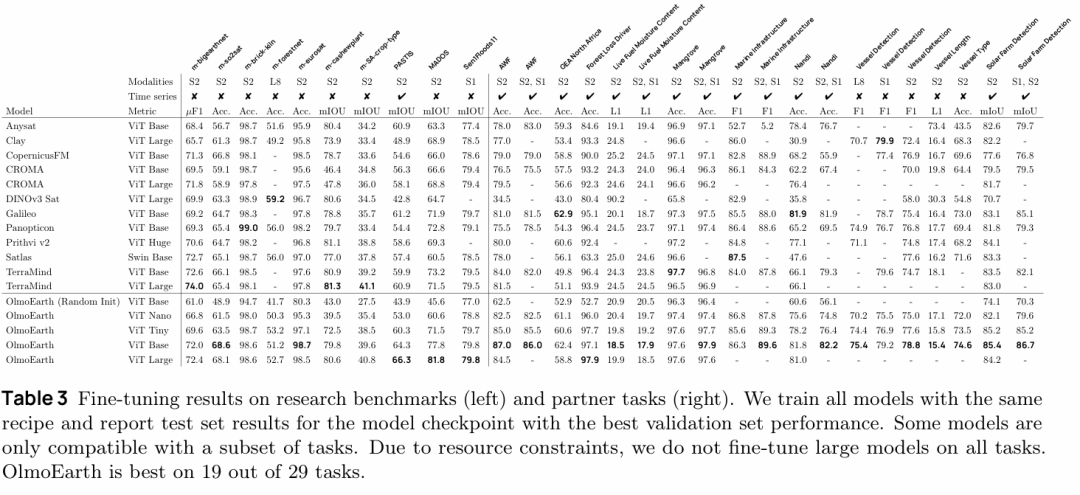
实验与分析
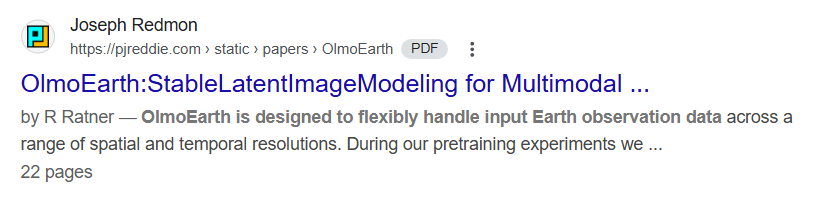
OlmoEarth在综合评估中表现优异,在冻结特征评估的任务中取得最佳成绩的比例超过六成,在端到端微调评估中的最佳任务比例接近三分之二,同时在性能与计算效率的平衡上达到了多个模型尺寸的最优配置。
消融实验验证了各创新组件的有效性,其中Latent MIM Lite相比传统Latent MIM避免了训练崩溃并大幅提升性能,模态感知掩码、模态内对比损失和地图数据的加入均带来渐进式的性能提升。
与Google的AlphaEarth Foundations相比,OlmoEarth在开放模型支持端到端微调的优势下,在所有评估任务上都取得了更好的效果,凸显了开源可微调模型相比仅提供embeddings的显著价值。
更多图表分析可见原文
本文系学术转载,如有侵权,请联系CVer小助手删文
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-29,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号