当AI走进物理世界:机器人学习、AI科学家和新交互方式

当AI走进物理世界:机器人学习、AI科学家和新交互方式

AI 男神说
发布于 2026-04-30 15:55:05
发布于 2026-04-30 15:55:05
这些领域不仅技术在进步,还在吸引越来越多的人才、资金和创业者加入。过去18个月的进展速度表明,这些领域可能很快就会进入自己的“越用越强”增长阶段。
在任何技术发展路线中,最值得关注的往往是那些:现在还不起眼,但未来几年可能实现跨越式发展的领域。这些领域的特点是:它们能享受与当前主流AI相同的“越做越强”的规模增长红利,但又不是简单地复制现有技术,而是需要做大量额外的研发工作。这种“有所延伸但又不是简单复制”的特点带来两个好处:一是构建了技术壁垒,让跟风者不容易追上;二是这些问题本身更有挑战性、更有探索价值,也更容易诞生全新的能力。
五大核心技术模块
在讨论具体应用之前,我们先来了解让这些前沿系统成为可能的技术底座。可以把它们理解为“积木”——不是专属于某个特定场景,而是可以被多个场景复用的基础能力。它们的成熟正是物理AI快速发展的关键。

1. 学习物理规律的表示能力
最基础的能力,是让AI学会“理解”物理世界的运作规律——物体怎么移动、怎么碰撞、怎么变形、怎么受力。没有这个能力,每个物理AI系统都得从零开始学物理,这成本太高了。
目前有三条技术路线在同时推进:
第一条路线是“从上往下”。视觉-语言-动作模型(VLA)先利用已经在互联网上预训练好的视觉-语言模型(这些模型已经很懂看图说话),然后给它们加上“动手能力”。这样做的好处是,“看图说话”的能力可以被充分利用,不用重头开始训练。Physical Intelligence的π₀、Google DeepMind的Gemini Robotics、NVIDIA的GR00T N1都是这个思路。
第二条路线是“从下往上”。世界动作模型(WAM)先让AI看大量视频,学习物体怎么运动、碰撞、互动,然后在这个基础上加上行动能力。NVIDIA的DreamZero就能零样本快速适应新任务和新环境,还能从人类操作视频中学习。
第三条路线更有趣,完全不用现成的视觉-语言模型或视频模型,而是从零开始“原生训练”。Generalist的GEN-1就是这样——它用低成本的可穿戴设备收集了超过50万小时的人类日常操作数据(比如撿东西、撕开包装等),然后从这些真实的物理交互中学习。它不是在调教现成模型,而是从人与物体的接触统计中学习物理规律。
2. 让AI学会行动的架构
理解了物理世界还不够,还得能把理解转化为精确的行动。这需要解决几个关键问题:如何把“折叠毛巾”这样的高层指令转换成具体的电机命令?如何在很长的操作中保持一致性?如何在实时响应的时间要求内完成?如何让系统越用越好?
目前流行的解法是“双系统架构”:用一个慢而强大的视觉-语言模型做场景理解和任务规划(类似人的慢思维),再用一个快而轻量的视觉运动策略做实时控制(类似人的反射动作)。GR00T N1、Gemini Robotics和Figure的Helix都采用了这种方案。
最让人兴奋的是强化学习(RL)在机器人领域的应用。这个思路很简单:先让AI模仿人类操作学会基本动作,然后让它自己练习、自己改进,就像人类通过反复练习掌握技能一样。Physical Intelligence的π*₀.₆就是这个思路的最好例子。
他们的RECAP方法解决了一个关键问题:当机器人在一个很长的任务中犯错,它得知道是哪一步引发了失败。比如抓咖啡机过滤网的角度偏了一点,可能几步之后插入失败时才发现。单纯模仿学不会这个,但强化学习可以。
结果很鼓舞人心:π*₀.₆能在真实家庭中折叠50种不同的衣物,稳定地组装箱子,在专业咖啡机上冲制咖啡,连续工作数小时而无需人类干预。在最难的任务上,它的效率提高了一倍以上,失败率降低了一半以上。更重要的是,它展现出了模仿学不会的行为:更平滑的恢复、更高效的抓取策略、自主纠错等。
3. 仿真与合成数据:解决数据不够的问题
在语言领域,数据问题已经被互联网解决了——数以万亿的文本免费可用。但在物理世界,数据问题难了几个数量级——真实的机器人操作数据很贵、很危险、很难收集。一个语言模型可以从10亿段对话中学习,但机器人还不能进行10亿次物理互动。
仿真技术和合成数据就是解决这个问题的关键。现代仿真技术已经可以:
• 用物理引擎模拟真实的物理规律
• 用光线追踪渲染出避真的画面
• 用程序化方法自动生成各种环境
• 用世界基础模型弥合仿真与现实之间的差距
其实现流程是:用手机扫描现实环境,自动构建物理级精度的三维场景,然后在里面生成大量带标注的训练数据。
这个意义很大:如果物理AI的瓶颈从“收集真实数据”变成“设计虚拟环境”,成本将大幅下降。仿真的成本随算力增加,不随人工或硬件增加。这就像互联网文本数据曾经改变了语言模型的训练经济学一样——仿真正在改变物理AI的经济学。
仿真不仅仅用于机器人。它同样服务于AI科学研究(实验设备的数字孪生、反应环境的模拟)、新型人机交互(训练脑机接口解码器、校准新型传感器)等领域。仿真是物理AI的通用数据引擎。
4. 扩展AI的感官能力
物理世界传递的信息远比视觉和语言丰富得多。触觉告诉我们物体的材质、握力稳定性和接触面的形状——这些是摄像头看不到的。神经信号可以编码运动意图、认知状态和感知体验——带宽远超现有的任何人机界面。肌肉活动可以在发出声音之前就编码语音意图。
第四个核心技术模块,就是让AI能够访问这些以前无法触及的感官信息。这不仅仅是研究的进步,更是一个生态系统的成熟——从设备制造、软件开发到基础设施,让这些传感器能够在消费级规模上捕捉和处理这些信号。
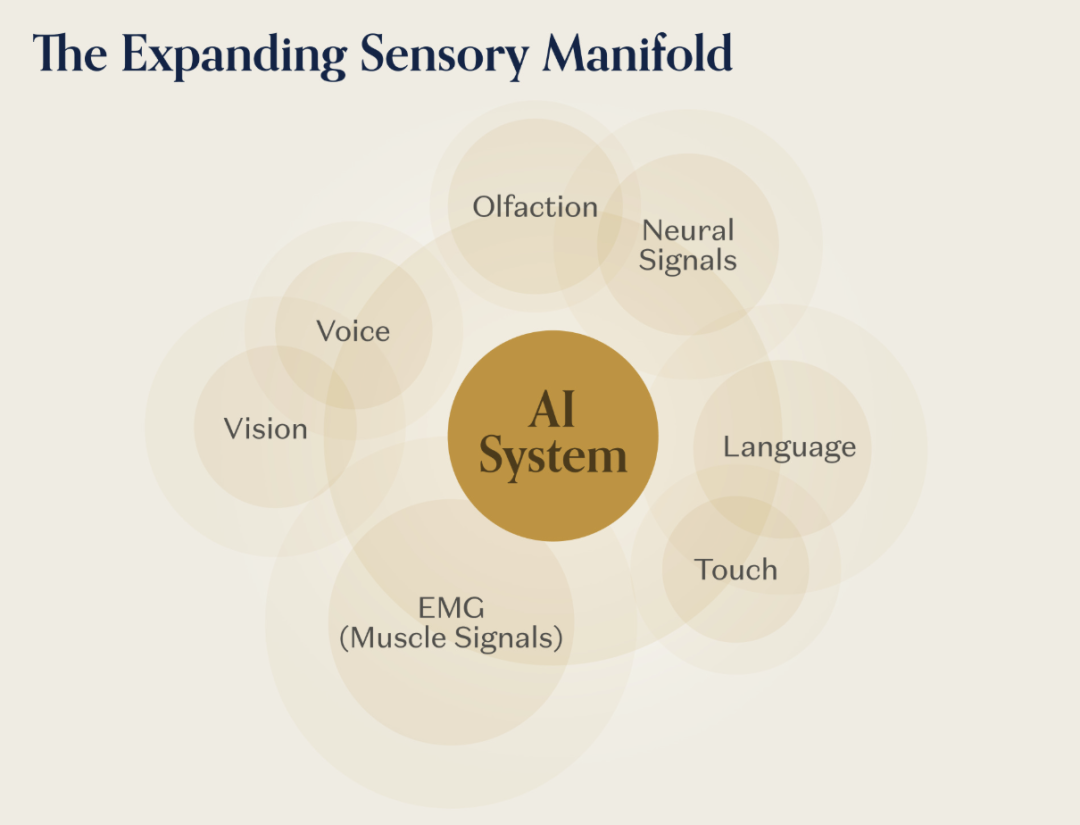
• AR眼镜持续收集用户与物理环境交互的视觉和空间数据
• EMG(肌电图)腕带捕捉人类运动意图的神经信号
• 无声语音界面捕捉下意识的语音运动
• 脑机接口在最高精度上捕捉神经活动
• 触觉传感器捕捉物理操作的接触动态
每一种新设备都是一个数据生成平台,为多个应用领域的模型提供训练数据。用EMG数据训练的机器人学会了与仅仅用遥控操作训练不同的抓取策略。响应下意识语音命令的实验室界面实现了与键盘不同的人机交互。用高密度脑机接口数据训练的神经解码器能够提取其他任何渠道无法获取的运动规划表示。
这些设备的普及正在扩大物理AI训练数据的范围和维度——而且这种扩大大部分是由资金雄厚的消费品公司而不仅仅是学术实验室推动的,这意味着数据的良性循环可以随市场接受度而扩大。
5. 闭环自主系统:让各部分协同工作
最后一个核心模块更偏向于架构层面。它是将感知、推理和行动编排成持续自主运行的闭环系统的能力——可以在没有人类干预的情况下在很长时间内独立工作。
在语言模型中,类似的发展是“智能体”的出现——多步推理、工具使用、自我纠正的工作流,让模型从单纯问答进化为自主问题解决者。在物理世界,同样的转变正在进行,但要求高得多。语言AI犯错可以随时撤回,但物理AI打翻试剂烧杯就不能了。
物理世界的自主系统有三个特点:
• 实际参与:直接连接到仪器数据流、物理状态传感器和执行机构,让推理锚定在物理现实而不是文本描述上
• 持续记忆:记住过往操作、跟踪数据来源、监控安全、在出错时恢复,而不是每次都从零开始
• 闭环迭代:根据物理结果而不仅仅根据文本反馈来调整策略
这个模块是将各种单项能力(好的世界模型、可靠的行动架构、丰富的传感器组)集成起来的粘合剂。它的成熟让下面三个应用领域从研究demo变成真正的产业应用。
三大应用领域
上述技术模块是通用的基础能力,它们本身不决定最重要的应用会在哪里出现。但有三个领域的“技术能力与基础设施的叠加效应”最强——不仅性能更好,还能实现以前不可能的全新能力。它们是:机器人学习、AI驱动科学研究、新型人机交互界面。
机器人学习:让AI动手做事
机器人是这个论断最直接的体现:AI需要能够感知、理解并且真正在物理世界中操作。这也是同时考验所有技术模块的领域。
想想一个通用机器人要折一条毛巾需要做什么:
• 理解柔软材料在受力下怎么变形——这个物理知识不是语言训练能得到的
• 把“折毛巾”这个高层指令转换成连续的电机命令(控制频率至少20Hz)
• 需要仿真生成的训练数据,因为没人收集过几百万次真实的折毛巾操作
• 需要触觉反馈来检测滑动并调整握力,因为纯视觉无法区分稳定抓取和即将失败的抓取
• 需要闭环控制器在折叠出错时检测并恢复,而不是盲目执行固定程序
机器人学习的关键在于数据良性循环:每个部署的机器人都会生成训练数据,改进控制它的模型,让所有机器人变得更好,从而实现更多部署。这个循环在语言模型中运行得很好,因为数据是数字的、可复制的、容易收集的。对于机器人,数据是物理的、昂贵的、难以获取的。
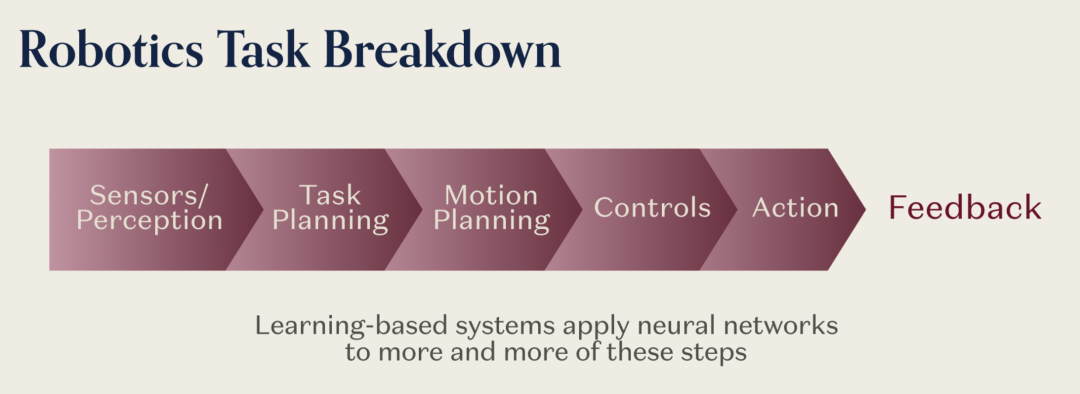
目前有两条路径在探索解决方案:一是集中收集高质量机器人数据(遥控操作、仿真到现实迁移、大规模部署);二是通过可穿戴设备捕捉人类的物理体验——Generalist的思路,利用人类日常已经在做的操作任务作为训练数据源。
不管数据从哪里来,底层逻辑是相同的:更多的物理交互数据产生更好的物理世界模型,产生更可靠的机器人行为,产生更多的部署和更多的数据。这就是机器人学习的“越用越强”增长曲线,它刚刚开始显现轮廓。
AI驱动科学研究:让AI做实验
自主科学是技术模块结合得最完整的领域。一个自动化实验室需要:
• 学习物理和化学动态规律来预测实验结果
• 具备操作能力来移液试剂、放置样品、操作分析仪器
• 仿真筛选候选实验方案,合理分配珍贵的仪器时间
• 扩展感知能力(光谱、色谱、质谱等)来分析结果
• 闭环自主系统维持多轮假设-实验-分析-修正工作流
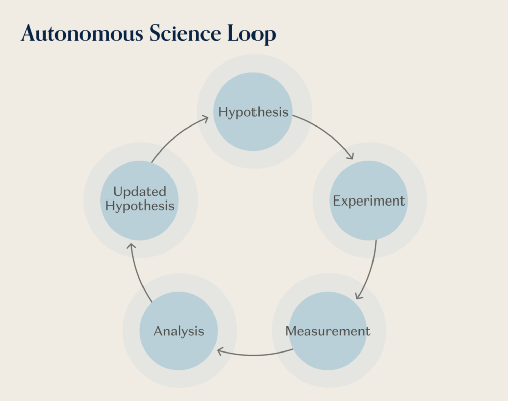
没有其他领域如此深入地调用这些技术模块。这就是自主科学不同于简单的“软件升级版实验室自动化”的地方。像Periodic Labs和Medra这样的公司将科学推理能力与验证这些推理的物理能力结合起来,实现科学迭代并生成实验训练数据。
这类系统的价值很直观:传统材料发现从概念到商业化通常需要数年时间,而AI加速的流程可能将这个过程大幅压缩。瓶颈正在从“提出假设”(基础模型很容易帮助)转向“制备和验证”(需要物理仪器、机器人执行和闭环优化)。自主实验室正是为了解决这个瓶颈。
自主科学还有一个重要属性:它是整个物理AI生态的数据引擎。AI科学家进行的每一次真实实验,都产生经过物理验证的、因果关系明确的训练信号。比如测量聚合物在特定条件下如何结晶,可以丰富世界模型对材料动态的理解。验证的合成路线变成物理推理的训练数据。失败案例则教会智能体系统它的预测在哪里不准。这种数据与互联网爬取的文本或仿真输出在质量上完全不同——它是结构化的、因果性的、经验验证的。这正是物理推理模型最需要且无法从其他渠道获取的数据。
新型人机交互:让AI理解人的身体
机器人将AI延伸到物理行动,自主科学将其延伸到物理研究。新的交互方式则通过AR眼镜、EMG腕带、脑机接口等设备,将AI与人类的感知、体验和身体信号直接连接起来。统一这个类别的不是单一技术,而是其共同目标:扩展人与AI系统之间信息传递的带宽和方式,并在这个过程中收集人与世界交互的数据。
这个领域的挑战和机遇都来自于它与现有技术的距离。语言模型概念上了解这些传感方式,但并不天生熔炼无声语音的运动模式、嗅觉受体的几何结构或EMG信号的时间变化。解码这些信号的表示必须从扩展的感知数据中学习。
很多这些传感方式没有互联网规模的预训练数据库,数据往往必须来自设备本身。这意味着系统和它们的训练数据以语言AI中没有前例的方式共同演化。这些设备的普及正在扩大物理AI数据的范围和维度,而且大部分由资金雄厚的消费品公司推动,这意味着数据的良性循环可以随市场采用而扩大。
这个领域在近期最直观的表现,就是AI可穿戴设备作为消费品类别的快速崛起。AR眼镜可能是这个类别中最引人注目的例子,还有其他采用语音或视觉优先输入方式的可穿戴消费设备。
这些消费设备构成的生态系统,既为AI进入物理世界创造了新的硬件平台,也成为物理世界数据的基础设施。一个戴着AI眼镜的人,可以持续生成第一人称视角的视频流,记录人类如何在物理环境中移动、如何操作物体、如何与世界互动。其他可穿戴设备则持续捕捉生物特征和运动数据。综合来看,AI可穿戴设备的用户群正在变成一个分布式的物理AI数据收集网络——以前所未有的规模,系统化地记录人类的物理体验。想想智能手机作为消费设备的规模——如果一种新型消费设备能以同样的规模让计算机获得感知世界的新方式,那也将为AI与物理世界互动开辟一条巨大的新通道。
脑机接口则代表了更深远的 frontier。Neuralink已经为多名患者植入设备,并持续迭代其手术机器人和解码软件。Synchron的血管内支架电极Stentrode已用于让瘫痪用户控制数字和物理环境。Echo Neurotechnologies正在开发用于语言恢复的脑机接口系统,基于他们在高分辨率皮层语音解码方面的研究。此外,像Nudge这样的新公司也在汇聚人才和资本,构建新的神经接口和大脑交互平台。研究领域的技术里程碑同样值得关注:BISC芯片实现了单芯片65,536个电极的无线神经记录,BrainGate团队则直接从运动皮层解码了内心语言。
从AR眼镜、AI可穿戴设备、无声语音设备到植入式脑机接口,贯穿所有这些设备的主线不仅仅在于它们都是交互界面。更关键的是,它们共同构成了一条从人类物理体验到AI系统的、带宽逐步提升的通道谱系——而这个谱系上的每一个点都在支撑本文讨论的物理AI三大领域持续进步。一个在数百万AI眼镜用户的高质量第一视角视频上训练的机器人,学到的操作直觉与只在精选的遥控操作数据集上训练的机器人不同;一个响应下意识语音指令的实验室AI,其响应速度和流畅度与用键盘控制的AI不同;一个在高清脑机接口数据上训练的神经解码器,能够提取的运动规划表征是其他任何渠道都无法获取的。

三个领域的互相促进
这三个领域不是孤立的,它们之间形成了强大的互相促进关系:
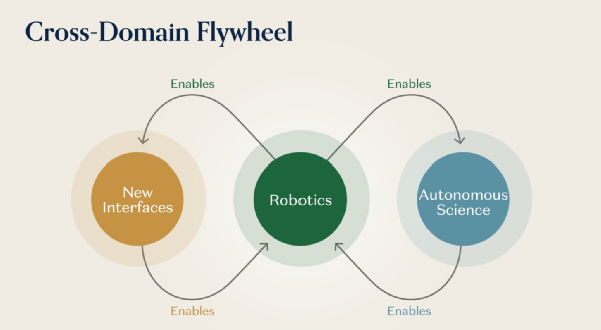
机器人学习 → 自主科学
自动化实验室本质上就是机器人系统。灵巧抓取、液体处理、精确定位、多步操作等通用机器人能力可以直接转用到实验室自动化。随着机器人模型在通用性和稳健性上的提升,自动化实验室能执行的实验协议范围也在扩大。机器人学习的每一步进步都在降低自主实验的成本、提高实验通量。
自主科学 → 机器人学习
自动化实验室产生的科学数据——经过验证的物理测量、因果实验结果、材料属性数据库——可以为世界模型和物理推理引擎提供结构化的、经过验证的训练数据。此外,下一代机器人需要的材料和设备(更好的驱动器、更灵敏的触觉传感器、更高密度的电池等)本身就是材料科学的产品。加速材料创新的自主发现平台可以直接改善机器人学习所依赖的硬件基础。
新交互界面 → 机器人学习
AR设备是收集感知和与物理环境交互数据的可扩展方式。神经界面生成关于人类运动意图、认知规划和感知处理的数据。这些数据对训练机器人学习系统至关重要,尤其是涉及人机协作或遥控操作的任务。
结语:物理AI的时代即将到来
这里有一个更深层的观点。语言/代码技术路线已经取得了非凡的成就,并且在规模化时代继续强劲改进。物理世界提供了几乎无穷的新问题、新数据类型、新反馈信号和新评估标准。通过让AI系统与物理现实对接(操作物体的机器人、合成材料的实验室、连接生物和物理世界的界面),我们开启了与现有数字前沿相互补充的新增长轴——而且很可能是相互促进的。
我们应该预期这些系统会产生什么样的新能力,很难精确预测——因为新能力本质上来自于单个能力合并后的集体效应。但历史规律是鼓舞人心的。当AI系统获得与世界交互的新方式时——当它们能看见(计算机视觉)、能说话(语音识别)、能读写(语言模型)——产生的能力远超各个单项改进之和。向物理世界系统的过渡代表了下一个这样的“质的飞跃”。
在这个意义上,本文讨论的技术模块正在快速成熟,它们可能让前沿AI系统能够感知、理解并与物理世界交互,在物理领域解锁巨大的价值和进步。
END
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-21,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号