OpenSpec + Superpowers:一个管写什么,一个管怎么做,6 步实现 AI 规格驱动 TDD 开发(实战版)
原创
OpenSpec + Superpowers:一个管写什么,一个管怎么做,6 步实现 AI 规格驱动 TDD 开发(实战版)
原创
运维有术
发布于 2026-05-07 23:02:19
发布于 2026-05-07 23:02:19
OpenSpec + Superpowers:一个管写什么,一个管怎么做,6 步实现 AI 规格驱动 TDD 开发(实战版)
🚩 2026 年「术哥无界」系列实战文档 X 篇原创计划 第 104 篇,AI 编程最佳实战「2026」系列第 29
大家好,欢迎来到 术哥无界 | ShugeX | 运维有术。
我是术哥,一名专注于 AI 编程、AI 智能体、Agent Skills、MCP、云原生、AIOps、Milvus 向量数据库的技术实践者与开源布道者!
Talk is cheap, let's explore。无界探索,有术而行。
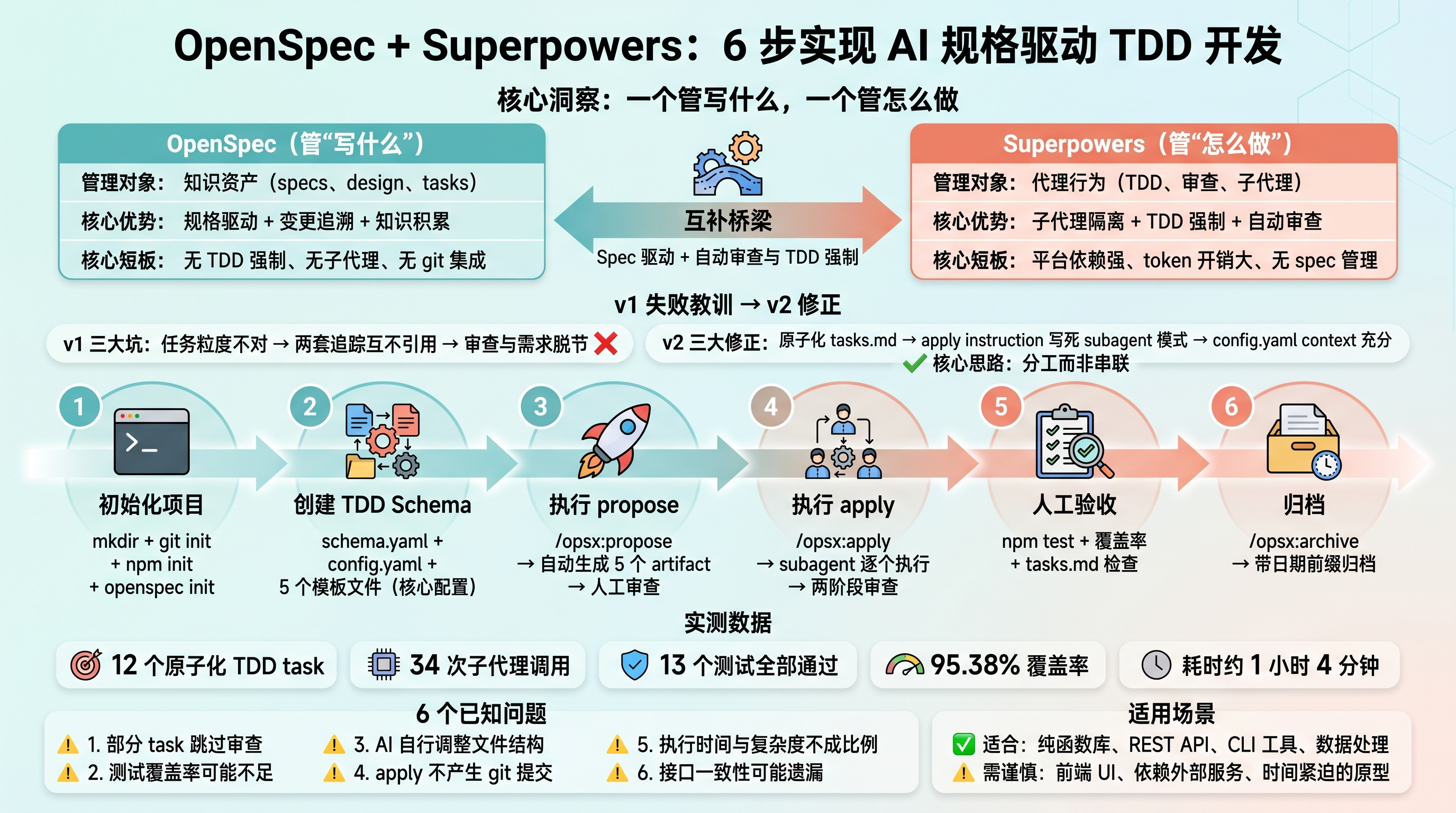
封面图:OpenSpec + Superpowers 协作方案流程概览
用 AI 编程助手写代码,很多人踩过同一个坑:代码跑起来了,但不是你想要的。
问题出在哪?不是 AI 能力不够,是你没告诉它写什么、怎么写才算对。需求模糊 → AI 自由发挥 → 你反复改,这个循环吞噬了大量时间。
这篇文章是 OpenSpec + Superpowers TDD 协作方案的第三次尝试(v3),也是第一次完整跑通 propose → apply → archive 全流程的版本。
前两版的故事是这样的:
v1 完全失败。 apply 阶段 AI 一口气写完所有代码,跳过了 RED 阶段,测试是写完实现后补的。TDD 形同虚设。失败根因不在 instruction 措辞,在任务粒度——一个 task 包含完整功能(RED+GREEN 混合),AI 一步完成是合理的。
v2 设计了 4 层防护。 原子化任务 + subagent 隔离 + 两阶段审查 + 验证证据,在 Mini Markdown 项目上拆了 26 个原子任务,dispatch 了 27 次 subagent,3 层通过、1 层被 AI 跳过。v2 证明了原子化任务和 subagent 隔离是有效的,但审查覆盖不完整(仅前 2/26 task 有审查),测试覆盖率 10/15,架构决策偏离 design.md。(详见上一篇:《OpenSpec + Superpowers TDD v2:4 层防护叠加 26 个原子任务,27 次 subagent 实测 3/4 通过》)
v3 做了三个关键修正:把 v2 的 4 层防护经验沉淀为一套可复用的中文版 Schema,补充了 propose 支持自然语言输入、archive 的日期前缀归档路径、以及更诚实的时间预期(实测 12 个 task 耗时 1 小时 4 分钟)。这一版用 Todo API 项目做验证,完整跑通了 6 个步骤:初始化 → 创建 Schema → propose → apply → 人工验收 → archive。
用一句话概括方案核心:OpenSpec 管「写什么」,Superpowers 管「怎么做」,桥梁是 schema.yaml 里的 instruction 文本。
说明:本文内容基于 OpenSpec(Fission-AI/OpenSpec)和 Superpowers(obra/superpowers)的源码分析、官方文档和三天两次实战验证。v2 在 Mini Markdown 项目验证(26 个 task、27 次子代理调用、10/10 测试通过),v3 在 Todo API 项目验证(12 个 task、34 次子代理调用、13/13 测试通过、95.38% 覆盖率)。文中的配置模板和参数建议仅供参考,实际效果请以你的项目环境和技术栈测试结果为准。如果你有实际使用经验,欢迎在评论区分享交流。
你将完成什么
- ✅ 搭建 OpenSpec + Superpowers 的 TDD 协作环境
- ✅ 配置一套自定义 TDD Schema(完整的 schema.yaml、config.yaml、模板文件)
- ✅ 跑通 propose → apply → archive 完整流程
- ✅ 了解方案的已知局限和应对策略
环境准备
你需要准备
- Node.js 20.19.0 或更高版本
- Claude Code(已安装 Superpowers 插件)
- OpenSpec v1.3.1 或更高版本
- 稳定的网络连接
- 一个待开发的项目(纯函数库、REST API 或 CLI 工具效果较好)
预计时间
⏱️ 完成本实战大约需要 30-45 分钟(不含 AI 执行时间)
难度等级
⭐⭐ 中级 - 需要熟悉命令行和基本的 TDD 概念
为什么需要这两个工具?
单独用 OpenSpec,你能把需求管得很清楚——proposal、design、specs、tasks 一条龙生成。但到执行阶段,OpenSpec 的 apply 只是逐个勾选 task,没有 TDD 强制,没有子代理隔离,也没有自动审查。AI 一步完成整个功能是完全合理的,因为一个 task 可能就包含了 RED+GREEN 混合内容。
单独用 Superpowers,TDD 纪律很严——RED-GREEN-REFACTOR 强制循环,子代理隔离执行,两阶段自动审查。但 Superpowers 没有 spec 管理,没有变更追溯,需求全靠对话,换个会话就忘了。
两者互补关系很清晰:
维度 | OpenSpec | Superpowers |
|---|---|---|
管理对象 | 知识资产(specs、design、tasks) | 代理行为(TDD、审查、子代理) |
核心优势 | Spec 驱动 + 变更追溯 + 知识积累 | 子代理隔离 + TDD 强制 + 自动审查 |
核心短板 | 无 TDD 强制、无子代理、无 git 集成 | 平台依赖强、token 开销大、无 spec 管理 |
说到底,一个管"写什么",一个管"怎么做",组合起来正好覆盖从需求到实现的完整链路。
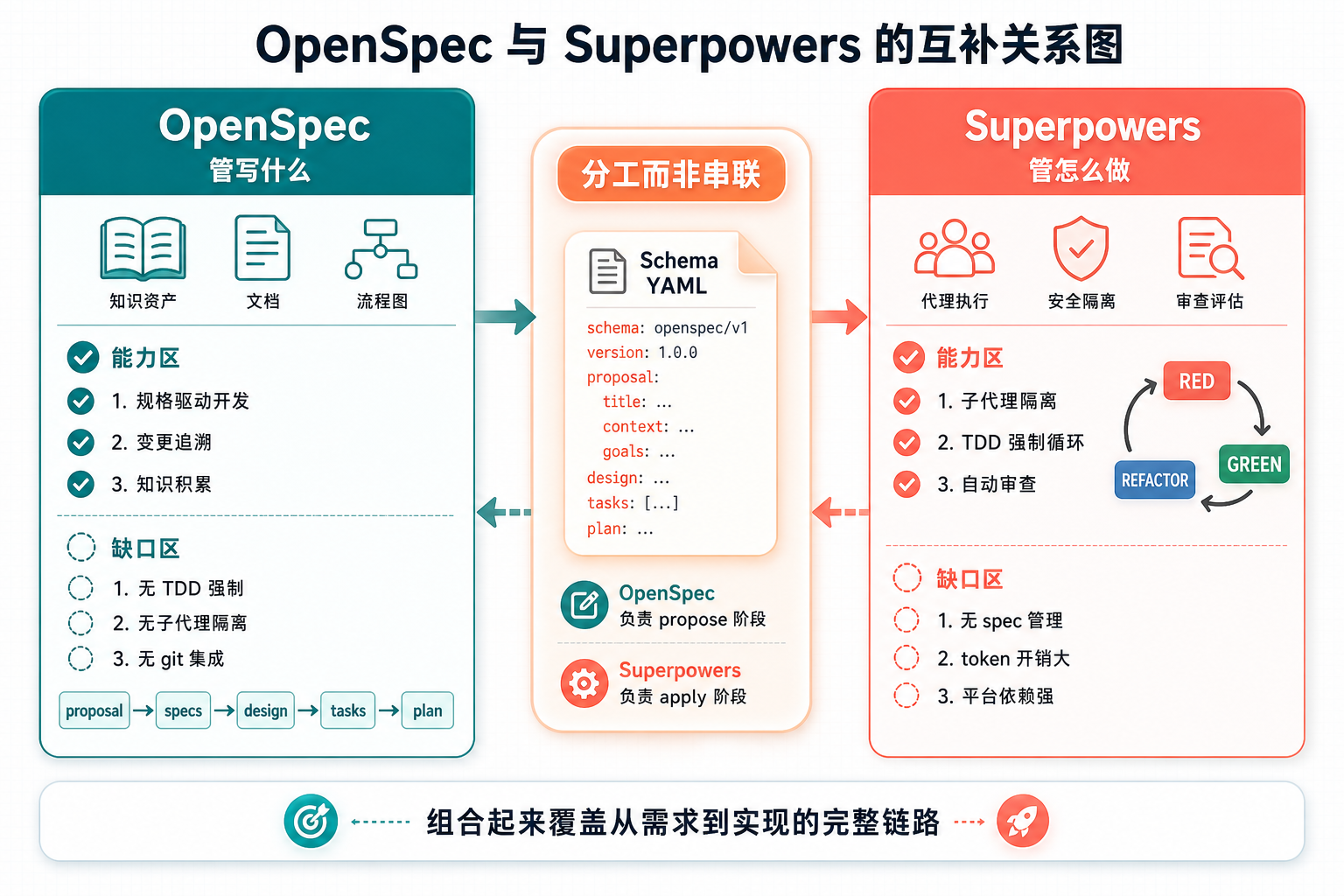
配图:OpenSpec 和 Superpowers 的互补关系图
图 1:OpenSpec 和 Superpowers 互补关系——一个管「写什么」,一个管「怎么做」
v1→v2→v3 的演进脉络
开头已经提过,这个方案经历了三次迭代。v3 的 Schema 不是凭空设计的,而是在 v2 实测基础上做了针对性改进。这里展开讲讲每版的教训和修正。
v1 完全失败(3 个原因)
坑 1:任务粒度不对。 一个 task 包含完整功能(RED+GREEN 混在一起),AI 一步完成是合理的——它没有做错什么,是你没约束它的操作空间。
坑 2:两套追踪系统互不引用。 OpenSpec 的 tasks.md 和 Superpowers 的 plan 是独立系统,AI 不知道该听谁的。
坑 3:审查审的不是 OpenSpec specs。 Superpowers 的 Spec Reviewer 审的是自己的 plan,不是 OpenSpec 产出的 specs,等于审查和需求脱节。
v2 的 4 层防护(3/4 通过)
v2 针对以上三个坑,设计了 4 层防护:
- 原子化 tasks.md - 每个 task = 一个 TDD 阶段(RED 或 GREEN 或 REFACTOR),物理约束 AI 的操作空间
- apply instruction 写死 subagent-driven-development - 27 次 subagent dispatch 实测通过
- config.yaml 的 context 写得充分 - propose 全自动完成,无需人工输入
- 验证证据 - subagent 必须报告测试输出,RED 阶段必须看到失败
v2 在 Mini Markdown 项目上实测,3 层通过、1 层(审查)被 AI 跳过。但暴露了新的问题:审查只覆盖前 2/26 个 task,测试覆盖率 10/15,AI 自行调整了文件结构。
v3 的改进(本文内容)
v3 把 v2 的经验沉淀为三个改进:
- 中文版 Schema - instruction 全部中文化,降低中文用户理解门槛
- 更诚实的时间预期 - v2 没提时间,v3 实测 12 个 task 耗时 1 小时 4 分钟,明确告知读者
- 已知问题的具体化 - v2 说"审查被跳过",v3 指出是 Task 8 和 Task 10 被跳过;v2 说"git 无 RED-only 提交",v3 发现是完全没有提交
核心思路始终不变:分工而非串联。OpenSpec 只管 propose 阶段,Superpowers 只管 apply 阶段,桥梁是 schema.yaml 里的 instruction 文本。
Step 1:初始化项目
先创建项目目录,初始化基础环境。
执行命令
# 创建项目目录
mkdir my-tdd-project && cd my-tdd-project
# 初始化 git
git init
# 根据你的技术栈初始化,这里以 TypeScript + Jest 为例
npm init -y
npm install --save-dev jest ts-jest @types/jest typescript
# 配置 test script(让 npm test 指向 jest)
npm pkg set scripts.test="jest"预期输出
- Creating OpenSpec structure...
▌ OpenSpec structure created
- Setting up Claude Code...
✔ Setup complete for Claude Code
OpenSpec Setup Complete
Created: Claude Code
4 skills and 4 commands in .claude/
Config: skipped (non-interactive mode)
Getting started:
Start your first change: /opsx:propose "your idea"验证点
✅ 检查 openspec/ 目录已创建,包含 changes/ 和 specs/ 子目录
注意:openspec init 不会创建 schemas/ 目录和 config.yaml,这两个需要手动创建,接下来会讲到。
另外,npm init -y 生成的 package.json 中 scripts.test 默认是 echo "Error: no test specified" && exit 1。上面这行 npm pkg set 把它改成了 jest,这样后面 npm test 就能直接用。如果跳过这步,后面验收阶段可以用 npx jest 代替,效果一样。
Step 2:创建 TDD Schema
这是整个方案的核心配置步骤。我们通过自定义 Schema 把 TDD 纪律注入 OpenSpec 的 artifact 生成流程。
2.1 创建目录结构
# 创建 Schema 目录和模板目录
mkdir -p openspec/schemas/tdd-driven-v2/templates2.2 创建 schema.yaml
保存到 openspec/schemas/tdd-driven-v2/schema.yaml:
name: tdd-driven-v2
version: 2
description: 原子化 TDD 工作流,子代理隔离执行,证据驱动验证
artifacts:
- id: proposal
generates: proposal.md
description: 变更提案——为什么做、期望什么行为
template: proposal.md
instruction: |
创建一份变更提案,说明为什么要做这个改动。
必须用 WHEN/THEN 格式列出每一个可测试行为:
- WHEN <函数名>(<输入>) 被调用 THEN 结果为 <期望值>
只描述"期望发生什么",不要描述实现细节。
requires: []
- id: specs
generates: specs/**/*.md
description: 行为规格——用场景描述期望行为
template: spec.md
instruction: |
用 GIVEN/WHEN/THEN 格式编写行为规格:
- 每个场景必须可独立测试
- 覆盖:正常路径、边界情况、错误处理
- 只描述期望行为,不描述实现方式
requires:
- proposal
- id: design
generates: design.md
description: 技术设计——怎么实现、测试策略
template: design.md
instruction: |
编写技术设计方案,说明如何实现。
必须包含:
- 要创建的文件列表(测试文件 + 源码文件,给出完整路径)
- 每个测试文件的测试策略(单元测试 / 集成测试)
- 源码文件与测试文件的对应关系
- 测试运行命令
requires:
- proposal
- id: tasks
generates: tasks.md
description: 原子化 TDD 任务列表
template: tasks.md
instruction: |
关键要求:将工作拆分为原子化 TDD 任务。
每个任务必须是且仅是一个 TDD 阶段(RED / GREEN / REFACTOR)。
必须使用 checkbox 格式书写每个任务:
### Feature: [功能名称]
- [ ] RED: 编写失败测试 —— [测试什么行为]
- [ ] GREEN: 最小实现 —— [实现描述,引用对应的 RED 任务]
- [ ] REFACTOR: 重构清理 —— [清理描述](可选)
规则:
1. 禁止将 RED 和 GREEN 合并到一个任务
2. 每个 GREEN 任务必须引用对应的 RED 测试
3. 每个任务必须使用 "- [ ]" checkbox 格式
4. 任务严格交替:RED → GREEN →(可选 REFACTOR)
5. 每个任务应在 2-5 分钟内可完成
requires:
- specs
- design
- id: plans
generates: plan.md
description: 执行计划——每步对应一个任务,附验证命令
template: plan.md
instruction: |
创建详细的执行计划。
每个计划步骤必须精确对应 tasks.md 中的一个任务。
RED 任务需包含:测试文件路径、断言内容、预期失败原因、验证命令。
GREEN 任务需包含:要通过的测试、最小实现描述、验证命令。
计划末尾必须追加:
---
## Execution Mode Selection
REQUIRED: Use superpowers:subagent-driven-development skill.
DO NOT use executing-plans or inline execution.
requires:
- tasks
apply:
requires: [plans]
tracks: tasks.md
instruction: |
必须使用 superpowers:subagent-driven-development skill 执行。
禁止使用 executing-plans 或 inline 执行。
执行规则:
1. 每个任务是一个原子 TDD 阶段——每个任务派遣一个子代理
2. 禁止并行派遣多个实现子代理
3. 任务必须按顺序执行
每个子代理的证据要求:
- RED 任务:必须包含测试失败输出
如果 RED 阶段报告"所有测试通过"→ 异常 → 重新派遣
- GREEN 任务:必须包含测试通过输出
如果 GREEN 阶段报告"测试仍失败"→ 不要标记完成 → 重新派遣
每个任务完成后(必须逐个执行,不可跳过):
1. Spec 审查:子代理是否精确实现了任务要求?
2. 代码质量审查:代码是否干净、有测试、可维护?
3. 两项审查都通过后 → 标记完成(- [ ] → - [x])
4. 继续下一个任务
全部任务完成后:
1. 运行完整测试套件
2. 验证所有 spec 已满足
3. 检查测试覆盖率2.3 创建 config.yaml
保存到 openspec/config.yaml(注意:在 openspec/ 根目录,不是 schemas 里面):
schema: tdd-driven-v2
context: |
技术栈:TypeScript + Node.js
测试框架:Jest
测试运行命令:npx jest
项目说明:<替换为你的项目描述>
核心函数签名:<替换为核心函数签名>
所有生产代码必须有对应的测试。
rules:
proposal:
- 用 WHEN/THEN 格式列出每一个可测试行为
- 不要描述实现细节
specs:
- 每个场景使用 GIVEN/WHEN/THEN 格式
- 每个场景必须可独立测试
design:
- 必须指定精确的测试文件路径
- 必须指定每个文件的测试策略
tasks:
- 必须使用 checkbox 格式 "- [ ]"
- 每个任务是且仅是一个 TDD 阶段(RED / GREEN / REFACTOR)
- 任务严格交替 RED → GREEN →(可选 REFACTOR)
- GREEN 任务必须引用对应的 RED 任务
plans:
- 每个计划步骤精确对应一个任务
- 必须指定验证命令和预期证据2.4 创建模板文件
保存到 openspec/schemas/tdd-driven-v2/templates/:
模板说明:模板文件使用 HTML 注释(<!-- -->)标注结构提示,不是变量占位符。OpenSpec 不会"替换"这些注释,而是由 AI 根据 schema.yaml 中的 instruction 字段来生成每个 artifact 的实际内容。模板的作用是提供结构骨架,让 AI 知道每个 artifact 应该包含哪些区域。
proposal.md:
# Proposal
## Problem
<!-- 描述要解决的问题 -->
## Testable Behaviors
<!-- WHEN/THEN 格式列出每一个可测试行为 -->
## Acceptance Criteria
<!-- 验收标准 -->spec.md:
# Spec
## Scenarios
### Scenario 1: [name]
- GIVEN: [前置条件]
- WHEN: [操作]
- THEN: [期望结果]design.md:
# Design
## File Structure
<!-- 列出要创建的文件,包括测试文件 -->
## Test Strategy
<!-- 每个 test 文件的测试策略 -->tasks.md:
# Tasks
## Atomic TDD Task List
<!-- 每个 task 只能是一个 TDD 阶段 -->
<!-- 必须使用 checkbox 格式 -->
### [Feature name]
- [ ] RED: ...
- [ ] GREEN: ...plan.md:
# Execution Plan
## Steps
### Step 1: RED — [description]
- Test file: [path]
- Assertion: [what to test]
- Expected failure: [reason]
- Verify: `npx jest [test-file]`
### Step 2: GREEN — [description]
- Pass test from: Step 1
- Minimal code: [what to implement]
- Verify: `npx jest [test-file]`2.5 验证 Schema
# 验证 schema 格式(会出现 experimental 提示,正常,不影响使用)
openspec schema validate tdd-driven-v2验证点
✅ 目录结构如下:
openspec/
├── schemas/tdd-driven-v2/
│ ├── schema.yaml
│ └── templates/
│ ├── proposal.md
│ ├── spec.md
│ ├── design.md
│ ├── tasks.md
│ └── plan.md
├── config.yaml
├── changes/
└── specs/到这里,TDD Schema 配置完成。这是整个方案里工作量比较大的一个步骤,但也是一次性投入——配好之后,后续每个功能都可以复用。
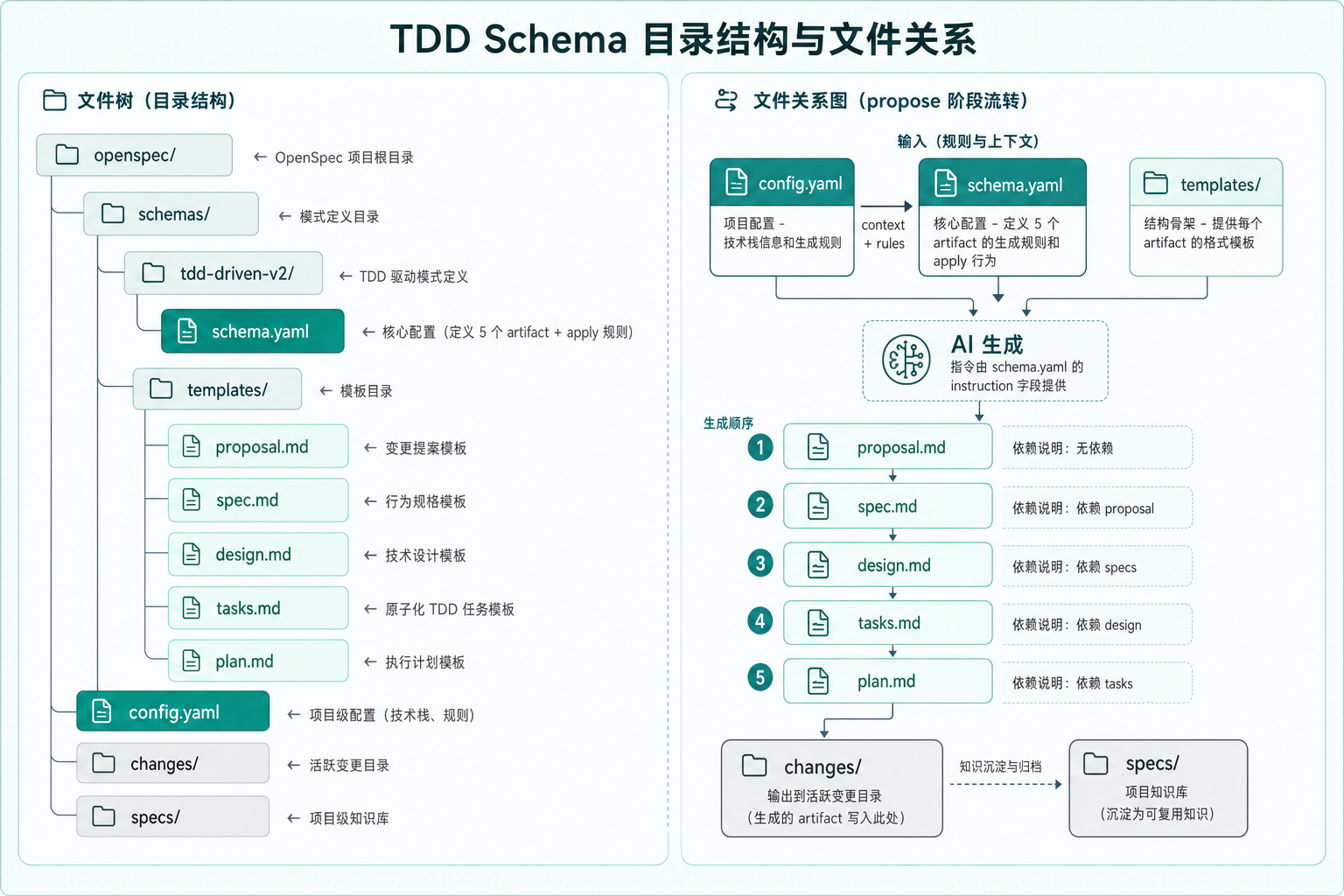
配图:目录结构和文件关系
图 2:TDD Schema 目录结构——schema.yaml 定义规则,templates 提供骨架,config.yaml 注入项目上下文
Step 3:执行 propose
准备工作做完了,开始让 AI 生成规格文档。
执行命令
在 Claude Code 中输入:
/opsx:propose <你的功能描述>输入格式:支持 kebab-case 名称(如 add-todo-priority)或自然语言描述(如"给 Todo API 加上任务优先级功能")。自然语言输入时,AI 会自动提取 change name。
举个例子,执行 /opsx:propose 后输入你的功能描述,可以用自然语言:
给 Todo API 加上任务优先级功能
AI 会自动提取 change name(本例中为 add-todo-priority),依次调用 openspec instructions <artifact> 获取每个 artifact 的增强指令,然后逐个生成 5 个 artifact。如果你的 config.yaml 的 context 写得足够详细,这一步是全自动的——用户只输入一次需求描述,无需二次交互。
预期行为
如果你的 config.yaml 的 context 写得足够详细,这一步是全自动的。AI 会在 2-3 分钟内生成 5 个 artifact:
proposal.md- 变更提案(WHY + 可测试行为列表)specs/- 行为规格(GIVEN/WHEN/THEN 场景)design.md- 技术设计(文件结构 + 测试策略)tasks.md- 原子化 TDD 任务列表plan.md- 执行计划(每步映射到具体 task)
propose 后必须人工审查
别急着执行。花 5 分钟审查这三个文件:
1. proposal.md:WHEN/THEN 行为列表是否完整?有没有遗漏的边界情况?
2. design.md:文件结构和测试策略是否合理?测试文件路径是否正确?
3. tasks.md(最关键):
- 每个
- [ ]是否只有一个 TDD 阶段? - RED 和 GREEN 是否严格交替?
- 如果不是,手动修改 tasks.md 再继续
如果 tasks.md 里出现了"RED+GREEN: 写测试并实现"这种合并任务,说明 AI 没遵守原子化约束。手动拆开它。
REFACTOR 任务:schema 中 REFACTOR 标注为可选,AI 可能不生成 REFACTOR 任务。如果某个 Feature 确实需要重构清理,可以手动在 tasks.md 中补充。
调试命令
如果生成结果不理想,可以查看 AI 实际收到的 instruction:
前提:需要先执行 /opsx:propose 创建一个活跃 change,否则会报 No changes found 错误。这些命令是 propose 之后的调试手段。
# 查看 tasks 阶段的 instruction
openspec instructions tasks --change <change-name> --json
# 查看 apply 阶段的 instruction
openspec instructions apply --change <change-name> --json验证点
✅ openspec/changes/<change-name>/ 下生成了 5 个 artifact
✅ tasks.md 的每个 task 都是原子化的(单个 TDD 阶段)
✅ proposal.md 使用 WHEN/THEN 格式列出所有可测试行为
Step 4:执行 apply
人工审查通过后,让 AI 开始实现代码。
执行命令
在 Claude Code 中输入:
/opsx:apply <change-name>预期行为
AI 会自动:
- 读取 apply instruction
- 逐个 dispatch subagent 执行每个 TDD task
- 每个 subagent 完成后进行两阶段审查(Spec 合规 → 代码质量)
- 审查通过后勾选 checkbox,进入下一个 task
apply 阶段是全自动的,用户只需等待。以 Todo API 加优先级功能的实测为例:
- 输入:12 个原子化 TDD task(6 × RED+GREEN)
- 执行:34 次子代理调用(24 次
general-purposeimplementer/spec-reviewer + 10 次superpowers:code-reviewer) - 结果:13 个测试全部通过,覆盖率 95.38%
- 耗时:约 1 小时 4 分钟
⚠️ 实测耗时远超预期。核心瓶颈不是模型推理速度,而是流程纪律开销—
—subagent-driven-development 要求每个原子 task 走 implementer → spec-reviewer → code-reviewer 三轮子代理,34 次调用中每次都需要独立的上下文构建。这个流程开销与需求复杂度关联不大——v2 验证(26 个 task)是 27 次调用,本次(12 个 task)是 34 次调用。对于简单需求,流程纪律的成本不成比例。如果你赶时间,可以考虑修改plan.md 末尾的 Execution Mode Selection,改用 inline 模式快速实现。
重要提醒:apply 是长时间运行的过程(实测 1 小时+),过程中不要中断。中途中断可能导致部分 task 已完成但 tasks.md 未更新,恢复起来很麻烦。建议在开始 apply 前确认网络稳定,并且有足够的时间等待。
apply 结束后,AI 会输出一份完成摘要:
## Implementation Complete
**Change:** `add-todo-priority`
**Schema:** `tdd-driven-v2`
**Progress:** 12/12 tasks complete ✓
### Final Test Results
Test Suites: 3 passed, 3 total
Tests: 13 passed, 13 total
Coverage: 95.38%如果 AI 没用 subagent 模式
如果 AI 直接 inline 执行(跳过了 subagent dispatch),手动提醒它:
请使用 superpowers:subagent-driven-development skill 执行 apply 阶段,不要使用 inline 执行。
这种情况在上下文窗口比较紧张时可能出现。
验证点
✅ AI 使用了 subagent-driven-development 模式
✅ 每个 task 有独立的 subagent dispatch
✅ 每个 subagent 报告了测试输出(RED 阶段有失败输出,GREEN 阶段有通过输出)
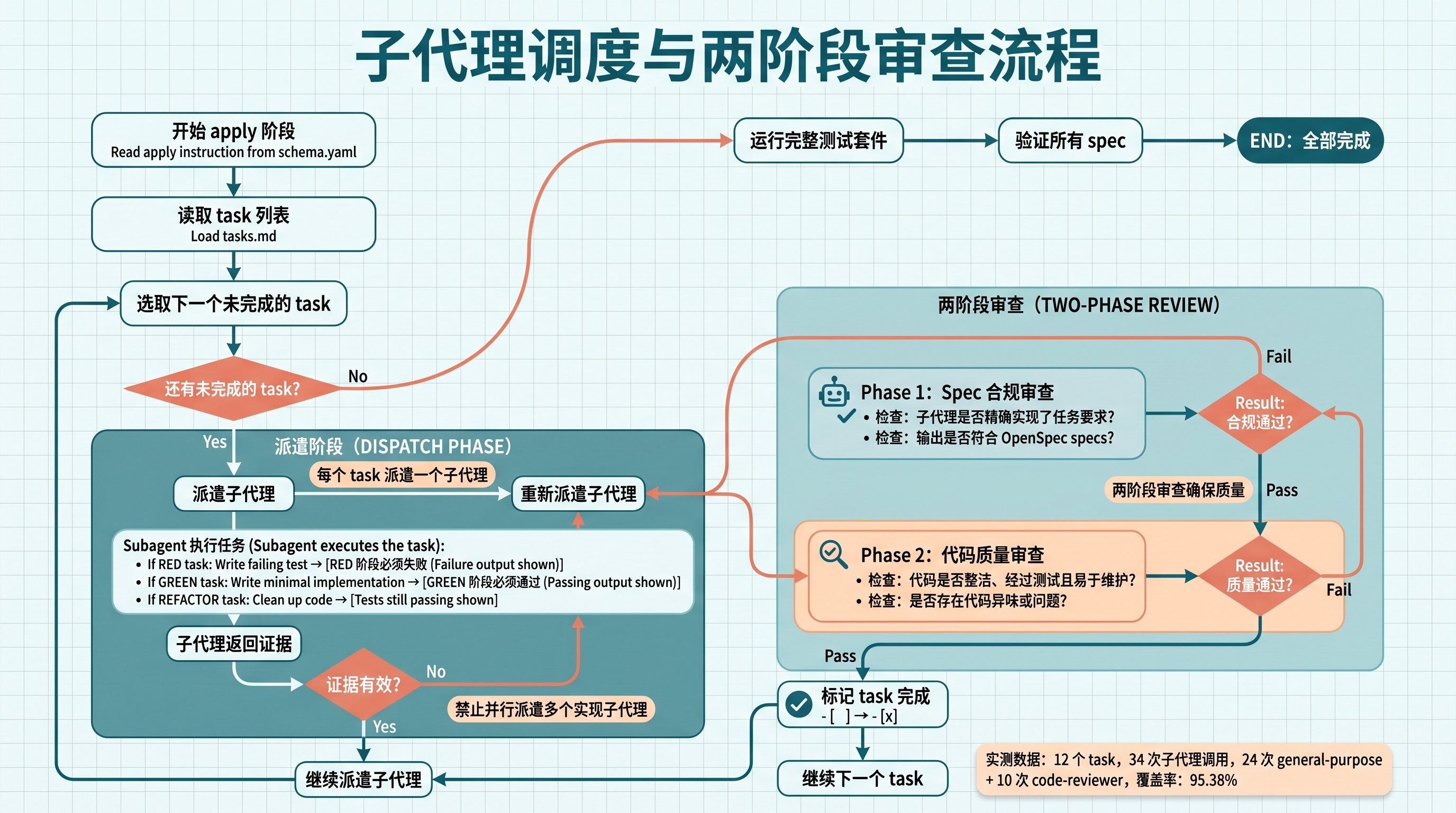
配图:subagent dispatch 和两阶段审查流程
图 3:子代理调度与两阶段审查流程——每个 task 走 implementer → spec-reviewer → code-reviewer 三轮子代理
Step 5:人工验收
AI 执行完了,但别急着归档。验收这步不能省。
执行验收命令
# 运行全部测试(如果已在 Step 1 配置了 npm pkg set scripts.test="jest")
npm test
# 或者直接用 npx(不依赖 package.json 配置)
npx jest
# 检查测试覆盖率
npx jest --coverage注意:如果你在 Step 1 没有更新 package.json 的 test script,直接运行 npm test 会报错。可以用 npx jest 代替,效果一样。
# 查看 tasks 完成情况
cat openspec/changes/<change-name>/tasks.md
# 查看 git 提交记录
git log --oneline验收检查清单
逐项检查:
npm test或npx jest全部通过tasks.md所有 checkbox 已勾选- 测试覆盖率 >= proposal 中的行为数量
- 源码文件结构与
design.md一致(或偏离可接受) - 无 TODO 标记或未完成的桩代码
不通过时怎么办
测试没全过 → 让 AI 修复失败的测试,或手动修复
覆盖率不足 → 参考 proposal.md 补充遗漏的测试用例
文件结构偏离 → 判断偏离是否可接受。如果 AI 把两个文件合并成一个,且功能正确,可以接受
有未完成的桩代码 → 让 AI 补全实现,或标记为下一个 change
Step 6:归档
验收通过后,归档这次变更。
执行命令
/opsx:archive <change-name>预期行为
AI 将 openspec/changes/<change-name>/ 移动到 openspec/changes/archive/YYYY-MM-DD-<change-name>/ 目录下,自动添加日期前缀便于时间排序。
执行 /opsx:archive 后,AI 会输出归档摘要:
## Archive Complete
**Change:** `add-todo-priority`
**Schema:** `tdd-driven-v2`
**Archived to:** `openspec/changes/archive/2026-05-06-add-todo-priority/`
**Specs:** No delta specs (main specs directory empty)
All artifacts complete. All 12 tasks complete.验证点
✅ openspec/changes/archive/ 下出现了带日期前缀的归档目录(如 2026-05-06-add-todo-priority/)
✅ 原活跃目录已清理
关于 Spec 同步:archive 后 openspec/specs/ 目录可能仍为空。这是因为 OpenSpec 的 spec 同步需要额外配置(如在 schema 中定义 sync 行为),当前版本的 TDD schema 没有触发自动同步。如果你需要将归档的 specs 累积到项目级知识库,可以在 archive 后手动将 changes/archive/*/specs/ 下的文件复制到 openspec/specs/。
下一次 propose:archive 后目录已清理,直接运行 /opsx:propose <新功能描述> 即可创建新的 change。已有的 TDD Schema(tdd-driven-v2)会被自动复用,无需重新配置。每个 change 的 specs、tasks、plan 都会独立生成,互不干扰。
完整流程回顾
把 6 个步骤串起来:
初始化项目 → 创建 TDD Schema → /opsx:propose → 人工审查 → /opsx:apply → 人工验收 → /opsx:archive
(Step 1) (Step 2) (Step 3) (必须做) (Step 4) (必须做) (Step 6)对应的命令序列:
# Step 1: 初始化
mkdir my-project && cd my-project
git init && npm init -y
npm install --save-dev jest ts-jest @types/jest typescript
npm pkg set scripts.test="jest"
openspec init --tools claude
# Step 2: 创建 Schema(一次性配置)
mkdir -p openspec/schemas/tdd-driven-v2/templates
# 手动创建 schema.yaml、config.yaml 和 5 个模板文件
# Step 3: 生成规格
# 在 Claude Code 中: /opsx:propose "你的功能描述"
# 人工审查 proposal、design、tasks
# Step 4: 执行实现
# 在 Claude Code 中: /opsx:apply <change-name>
# Step 5: 人工验收
npx jest && npx jest --coverage
# Step 6: 归档
# 在 Claude Code 中: /opsx:archive <change-name>已知问题和应对
说实话,这个方案不是银弹。v2 实测发现了 6 个已知局限,需要在人工验收阶段兜底。
问题 1:部分 task 跳过了审查
AI 会选择性跳过某些 task 的 spec-reviewer 和 code-reviewer,直接标记完成。跳过的不是"后几个",而是分散在中间——实测中 Task 8 和 Task 10 被跳过。
应对:apply 结束后,不要假设所有 task 都经过了审查。对照 session 日志或 AI 输出,确认每个 task 是否都有审查报告,跳过的部分手动补审。
问题 2:测试覆盖率可能不足
实测中 15 个行为只覆盖了 10 个,AI 跳过了部分边界情况。
应对:对照 proposal.md 的 WHEN/THEN 列表,逐个检查是否有对应测试,缺的补上。
问题 3:AI 可能自行调整文件结构
比如你在 design.md 里规划了两个文件,AI 合并成了一个。这不一定错,但偏离了设计。
应对:判断偏离是否合理。如果功能正确、代码质量没问题,可以接受。
问题 4:apply 阶段不产生 git 提交
实测中 apply 结束后 git log 没有任何提交记录。AI 在子代理模式下不做 git add/commit。
应对:apply 结束后手动验收并提交:
git add -A
git commit -m "feat: implement <change-name> via OpenSpec + Superpowers TDD workflow"问题 5:执行时间与需求复杂度不成比例
subagent-driven-development 的流程纪律开销是系统性的。12 个 task 实测 64 分钟,26 个 task 实测约 90 分钟。即使简单需求(如"给 interface 加一个字段"),每个 task 仍需三轮子代理审查。本质是用"流程纪律"换"代码质量"。
应对:
- 对于简单需求,可以修改
plan.md末尾的 Execution Mode Selection,使用 inline 模式而非 subagent-driven-development - 或者只在关键 task 上启用审查,跳过简单的 CRUD task
- apply 结束后人工验收是不可省的,这是兜底环节
问题 6(接口一致性):子代理模式下的 code review 可能遗漏接口定义不一致的问题。实测中 todo.model.ts 和 todo.service.ts 各自定义了不同的 Todo 接口(model 缺少 createdAt 字段),code reviewer 未发现。
应对:apply 结束后,特别检查跨文件的接口/类型定义是否一致。如果多个文件引用同一数据结构,确认它们引用的是同一个 type/interface 定义,而不是各自重新定义。
适用场景分析
这个方案不是所有场景都适合。
适合:
- 纯函数库、工具函数
- REST API(CRUD 类)
- CLI 工具
- 数据转换/处理逻辑
需要谨慎:
- 前端 UI 组件(测试行为难以用 WHEN/THEN 表达)
- 依赖外部服务的功能(数据库、第三方 API、文件系统)
- 时间紧迫的原型开发(Schema 配置 + 审查需要额外时间)
进阶技巧
技巧一:复用 Schema
TDD Schema 配好一次就能复用。新建项目时只需要把 openspec/schemas/tdd-driven-v2/ 和 openspec/config.yaml 复制过去,改一下 config.yaml 里的技术栈信息就行。
技巧二:config.yaml 的 context 越详细越好
context 字段写得越详细,propose 阶段的全自动率越高。核心函数签名、输入输出类型、已有的工具函数列表 - 这些信息都能帮助 AI 一次生成正确的 proposal,省去多轮修改。
技巧三:propose 后审查是 ROI 很高的 5 分钟
别跳过 propose 后的人工审查。特别是 tasks.md,一旦原子化约束没生效,后续整个 apply 阶段都会跑偏。5 分钟的人工审查能省下 30 分钟的返工。
总结
OpenSpec + Superpowers 的 TDD 协作方案,核心思路就一句话:让 OpenSpec 把需求拆细,让 Superpowers 把执行管严。
三次迭代,一次比一次清醒:v1 失败教会了三个教训(任务粒度必须原子化、两套系统不能各自为战、审查必须对齐需求);v2 用 4 层防护验证了原子化任务和 subagent 隔离的有效性(3/4 通过);v3 在此基础上沉淀为可复用的中文版 Schema,完整跑通了 propose → apply → archive 全流程。
这个方案用时间换质量——一个中等功能可能要等 1 小时,但换来了 95%+ 的测试覆盖率和完整的变更追溯。如果你在赶进度,它可能不是最优选;如果你在追求工程化,它值得一试。
如果你也在用 OpenSpec 或 Superpowers,欢迎在评论区聊聊你的使用体验。
好啦,谢谢你观看我的文章,如果喜欢可以点赞转发给需要的朋友,我们下一期再见!敬请期待!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号