大模型应用:低资源场景下的语言生成:N-Gram与大模型的协同之路.100
原创
大模型应用:低资源场景下的语言生成:N-Gram与大模型的协同之路.100
原创
未闻花名
发布于 2026-05-08 07:57:52
发布于 2026-05-08 07:57:52
一、前言
在自然语言处理领域,大模型凭借海量参数和强大的上下文理解能力,成为文本生成的主流方案,但在低资源语言、文本纠错、输入法预测等场景中,大模型偶尔会出现生成不流畅、乱码、逻辑断裂等问题。而诞生数十年的 N-Gram 统计语言模型,虽简单却能凭借局部上下文统计规律提供稳定的语言约束。将两者结合,以N-Gram做兜底校验,大模型做流畅生成,既能发挥大模型的创造性,又能借助 N-Gram 的统计特性保证文本的通顺性和准确性 。
今天我们由浅入深拆解 N-Gram 与大模型的融合应用,涵盖核心概念、基础原理、执行流程及实际应用价值,彻底理解经典统计模型如何赋能大模型

二、核心基础
1. 语言模型的本质
语言模型(Language Model,简称LM)的核心目标是计算一段文本序列的概率,本质是让机器理解哪些文字组合是符合语言习惯的。比如:
- 正确序列:“我想吃苹果” → 概率高
- 错误序列:“我吃想苹果” → 概率低
无论是N-Gram还是大模型,本质都是语言模型,只是建模方式不同:
- N-Gram:基于统计频率的“局部短视”模型,只看相邻几个词的组合规律;
- 大模型:基于深度神经网络的“全局长视”模型,能捕捉长距离上下文关联,但依赖海量数据和计算。
2. N-Gram 语言模型
2.1 核心定义
N-Gram是将文本拆分为长度为N的连续词序列,也可按字符拆分,通过统计这些序列的出现频率,计算文本的概率,核心就是从“词的组合”到概率。
- 1-Gram(Unigram):单个词的概率,如“苹果”出现的概率;
- 2-Gram(Bigram):两个连续词的概率,如“吃苹果”中“吃 + 苹果”的概率;
- 3-Gram(Trigram):三个连续词的概率,如“我吃苹果”中“我 + 吃 + 苹果”的概率;
- N通常取1-5,N越大,越能捕捉上下文,但计算量和数据需求指数级增长。
2.2 数学原理
N-Gram的核心是马尔可夫假设:一个词的出现概率仅依赖于前 N-1个词。
对于文本序列w1 ,w2 ,...,wT,其概率可分解为:
其中:
- P(w_t \mid w_{t-N+1}, \dots, w_{t-1}) 表示在前 N-1 个词已知的情况下,第 t 个词出现的概率;
- 当 N=1 时,{P(w_t \mid w_{t-0})=P(w_t)},即单个词的先验概率;
- 当 N=2 时,P(w_t \mid w_{t-1}) ,即前一个词决定当前词。
2.3 概率计算
N-Gram的概率通过最大似然估计(MLE)计算,核心是“频率代替概率”:
其中:
- count(序列) 表示该序列在语料库中出现的次数;
- 例:计算 Bigram概率 P(苹果|吃),若语料中“吃苹果”出现100次,“吃”出现1000次,则 P(苹果|吃) = 100/1000 = 0.1。
2.4 平滑技术
平滑技术是为了解决“未登录词”问题,直接用MLE计算会遇到“零概率问题”:若某个N-Gram序列从未在语料中出现,其概率为 0,导致整个文本概率为 0。因此需要平滑技术,常见方法:
- 1. 加1平滑(Laplace):给所有N-Gram序列的计数加 1,避免零概率:
其中 V 是语料库中唯一词的总数;
- 2. 加k平滑(Add-k):加1的泛化,k∈(0,1),平衡过平滑和欠平滑;
- 3. 回退(Backoff):若N-Gram概率为0,退到N-1-Gram计算,如3-Gram为0则用2-Gram,2-Gram为0则用1-Gram;
- 4. 插值(Interpolation):加权融合不同N的N-Gram概率,如P=α1P1+α2P2+α3P3(α1+α2+α3=1)。
3. 大模型语言模型
3.1 核心逻辑
大模型本质是基于上下文的条件概率模型,与N-Gram的核心区别是:
- 不再依赖“固定长度的N-Gram序列”,而是通过自注意力机制捕捉任意长度的上下文关联;
- 概率计算基于神经网络的参数拟合,而非简单的频率统计;
- 能处理更复杂的语言规律,如语义、逻辑、多模态,但对数据质量、计算资源要求极高。
3.2 大模型的痛点
尽管大模型能力强大,但在实际应用中存在以下问题:
- 1. 低资源语言适配差:小语种语料少,大模型训练不充分,易生成无意义字符或乱码;
- 2. 局部流畅性不足:偶尔出现语法正确但局部词组合不符合语言习惯的情况,如“打游戏”被生成“玩游戏”虽正确,但“打游戏”更符合习惯;
- 3. 文本纠错能力弱:对拼写错误、语序错误的修正能力有限;
- 4. 生成可控性差:易出现幻觉生成不存在的信息或逻辑断裂。
这些痛点,正是N-Gram能发挥作用的地方,N-Gram虽简单,但能通过局部词频统计保证最基础的语言流畅性,成为大模型的兜底方案。
三、N-Gram+大模型的融合原理
1. 融合的核心逻辑
N-Gram和大模型的融合,核心是分工协作,是互补而非替代:
- 大模型:负责“全局语义 + 流畅生成”,基于上下文生成符合语义、逻辑的文本候选;
- N-Gram:负责“局部校验 + 兜底修正”,对大模型生成的文本进行概率评估,筛选、修正不符合语言习惯的部分,避免乱码、语序错误。
融合的核心目标:在保留大模型语义能力的前提下,提升文本的局部流畅性和准确性。
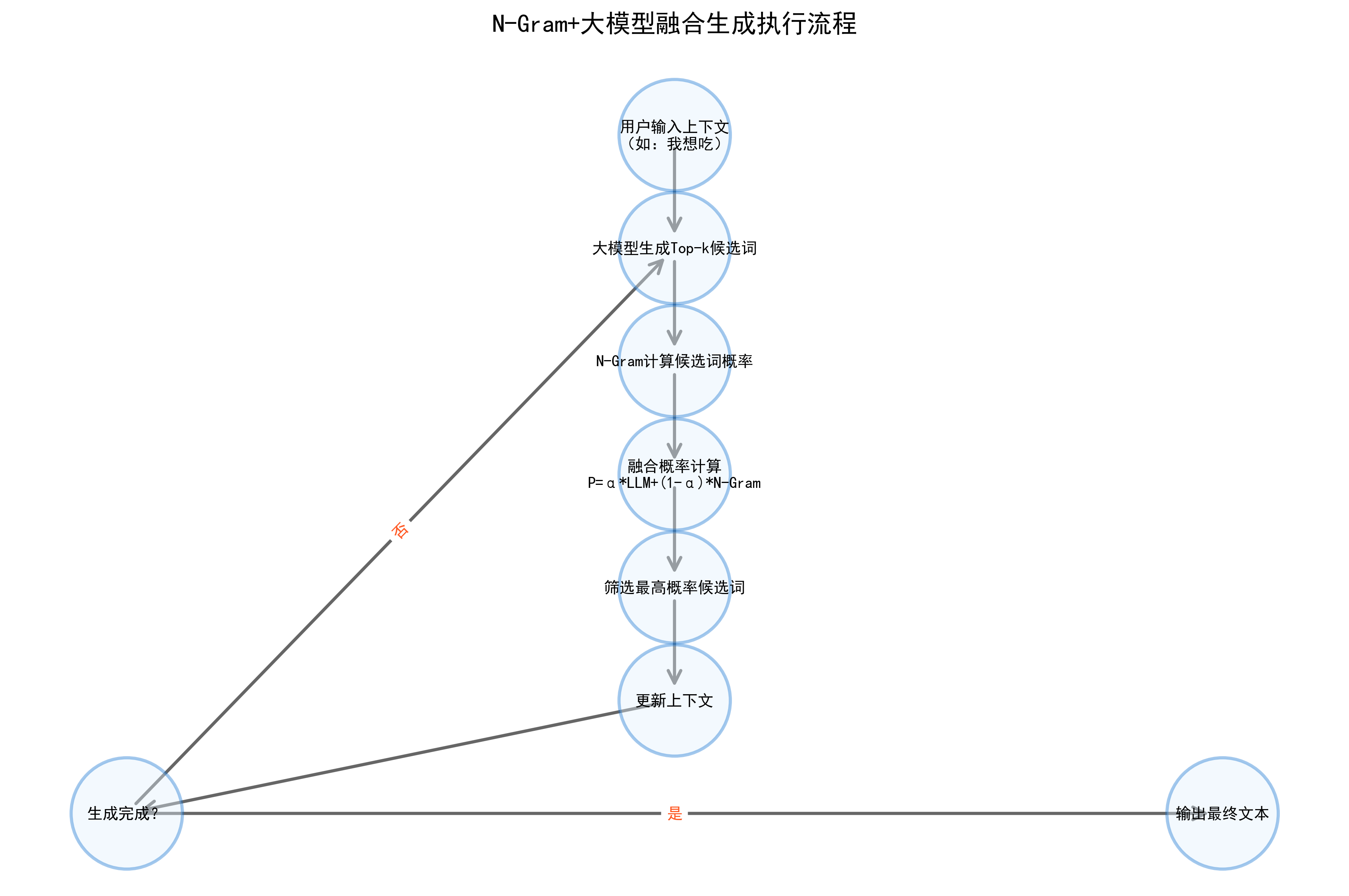
2. 两种融合模式
2.1 生成后校验模式,适用于文本纠错、输入法预测:
- 步骤 1:大模型基于输入上下文生成多个候选文本序列;
- 步骤 2:用 N-Gram计算每个候选序列的概率;
- 步骤 3:按融合概率排序,选择概率最高的候选作为最终输出。
2.2 生成中约束模式,适用于低资源语言生成:
- 步骤 1:大模型逐词生成文本,每生成一个词wt,先输出 k 个候选词(Top-k 采样);
- 步骤 2:用 N-Gram 计算这 k 个候选词的条件概率 P(w_t \mid w_{t-1}, \dots, w_{t-N+1}) ;
- 步骤 3:对 k 个候选词的概率进行加权(大模型概率 + N-Gram 概率),选择最终的wt;
- 步骤 4:重复上述过程,直到文本生成完成
3. 融合的处理细节
3.1 N-Gram的预处理适配
为了让N-Gram更好地适配大模型,需要做以下预处理:
- 1. 分词对齐:大模型的分词方式(如 BPE、WordPiece)需与N-Gram的分词方式一致,避免统计维度不匹配;
- 2. 语料对齐:训练N-Gram的语料应与大模型的下游任务语料(如输入法语料、低资源语言语料)一致,保证统计规律的适配性;
- 3. 平滑策略优化:针对低资源场景,优先使用“回退 + 插值”平滑,避免零概率问题导致的误判。
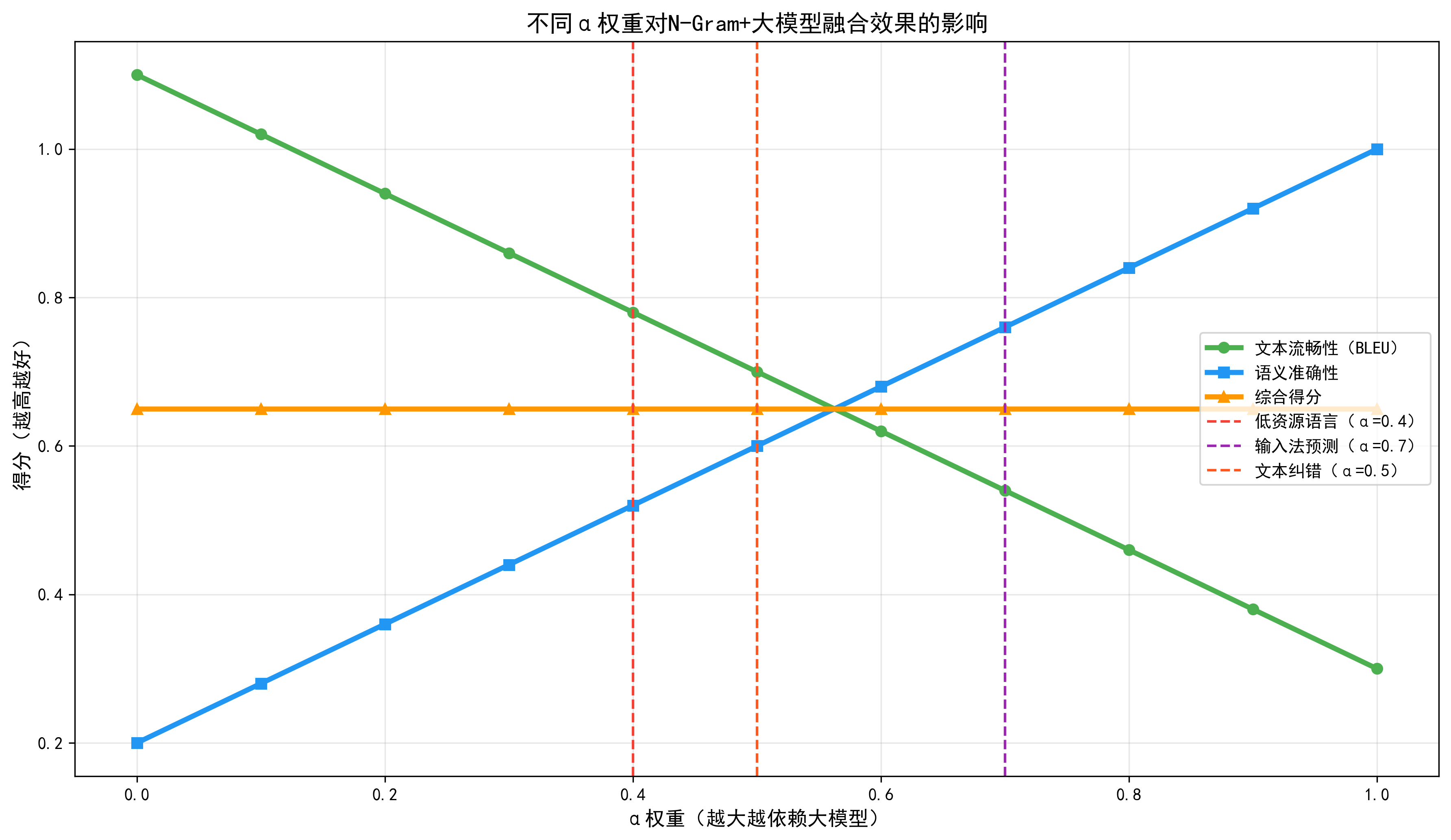
3.2 权重系数α的动态调整
α并非固定值,可根据场景动态调整:
- 低资源语言场景:α取0.3-0.5,让N-Gram发挥更大作用;
- 通用文本生成场景:α取0.7-0.9,优先保留大模型的语义能力;
- 文本纠错场景:α取0.5-0.7,平衡语义正确性和语法流畅性。
3.3 乱码、无意义字符的过滤
大模型在低资源场景下易生成乱码,如小语种的无效字符,N-Gram可通过以下方式过滤:
- 预构建“有效字符、词表”:基于 N-Gram 的语料,统计所有出现过的字符、词,形成有效表;
- 生成校验:大模型生成的每个字符、词,若不在有效表中,直接过滤,用 N-Gram 预测的高概率字符、词替换;
- 示例:低资源语言生成中,大模型生成乱码,N-Gram测到该字符组合概率为0,替换为语料中高频的预测词。
4. 应用场景生成流程
4.1 场景 1:输入法预测
输入法预测的核心是“基于用户已输入的字符,预测下一个或多个字符”,融合流程:
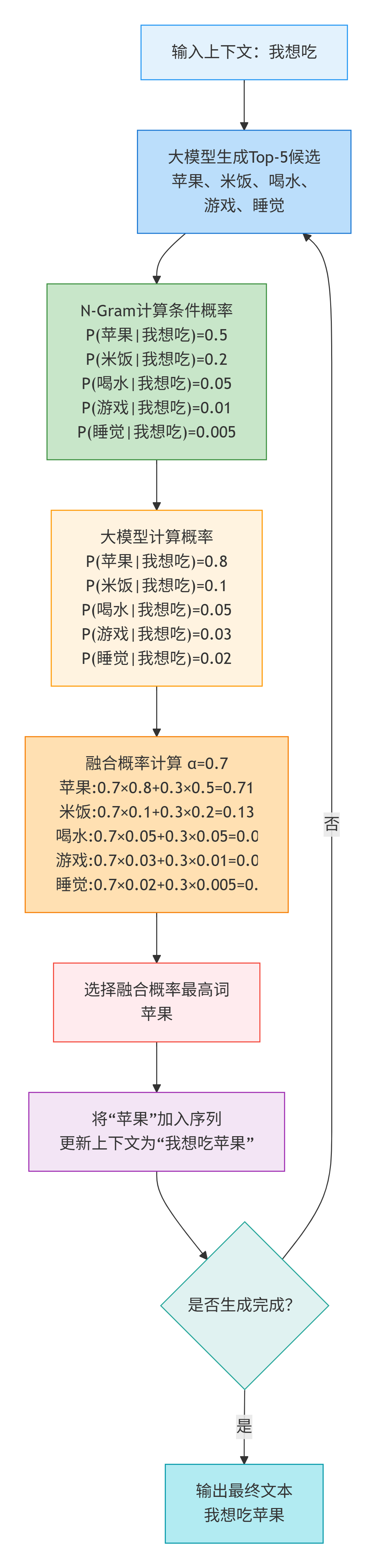
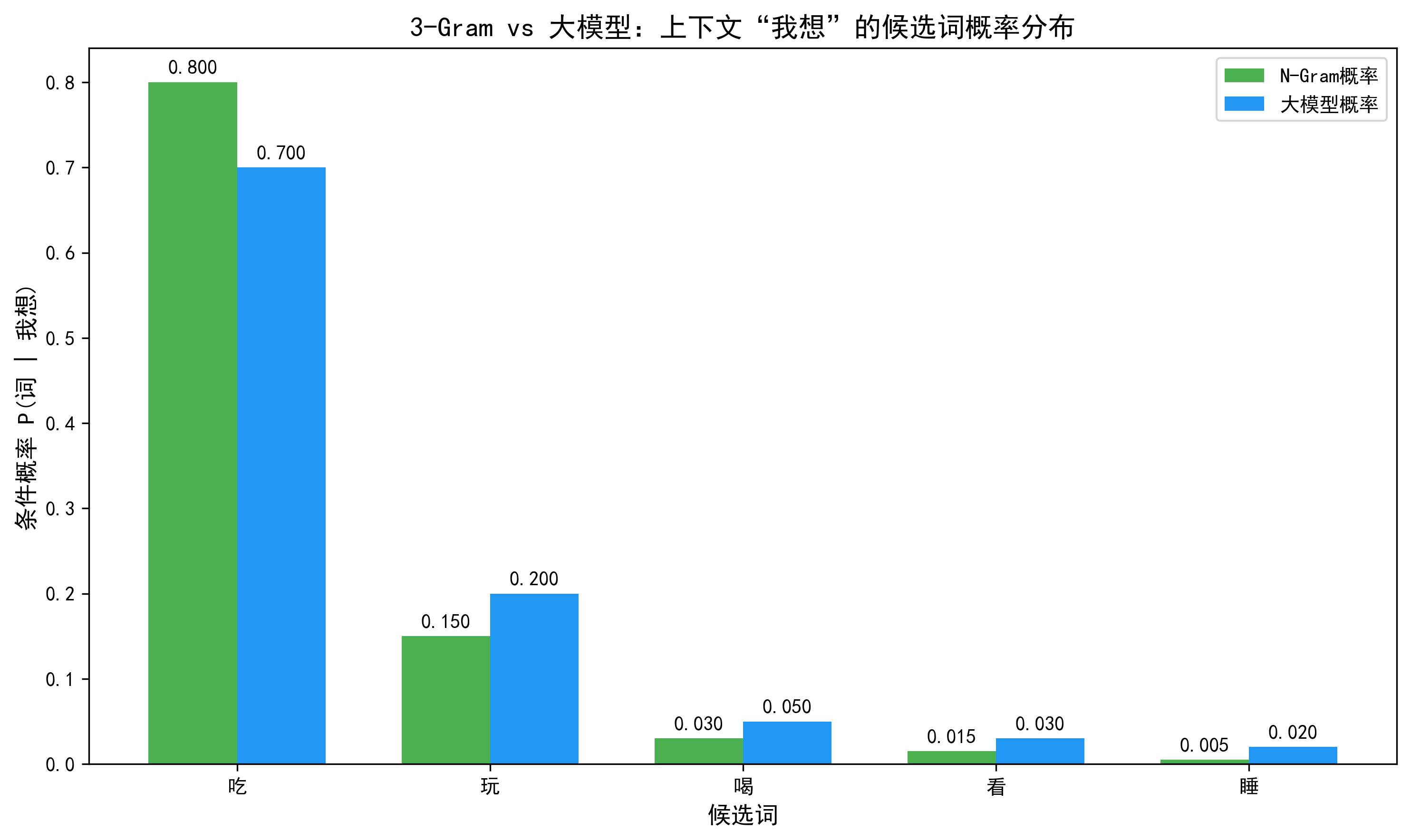
- 1. 用户输入:“我想吃”;
- 2. 大模型生成 Top-5 候选:["苹果", "米饭", "喝水", "游戏", "睡觉"];
- 3. N-Gram 计算候选的3-Gram概率:
- P(苹果|我想吃) = count(我想吃苹果)/count(我想吃) = 500/1000 = 0.5;
- P(米饭|我想吃) = 200/1000 = 0.2;
- P(喝水|我想吃) = 50/1000 = 0.05;
- P(游戏|我想吃) = 10/1000 = 0.01;
- P(睡觉|我想吃) = 5/1000 = 0.005;
- 4. 融合概率计算(α=0.7):
- 大模型对候选的概率:[0.8, 0.1, 0.05, 0.03, 0.02];
- 融合后概率:
- 苹果:0.70.8 + 0.30.5 = 0.71;
- 米饭:0.70.1 + 0.30.2 = 0.13;
- 喝水:0.70.05 + 0.30.05 = 0.05;
- 游戏:0.70.03 + 0.30.01 = 0.024;
- 睡觉:0.70.02 + 0.30.005 = 0.0155;
- 5. 按融合概率排序,输出 Top-3:苹果、米饭、喝水,符合用户输入习惯。
4.2 场景 2:低资源语言生成
低资源语言(如藏语、苗语)的大模型训练数据少,易生成乱码,融合流程:
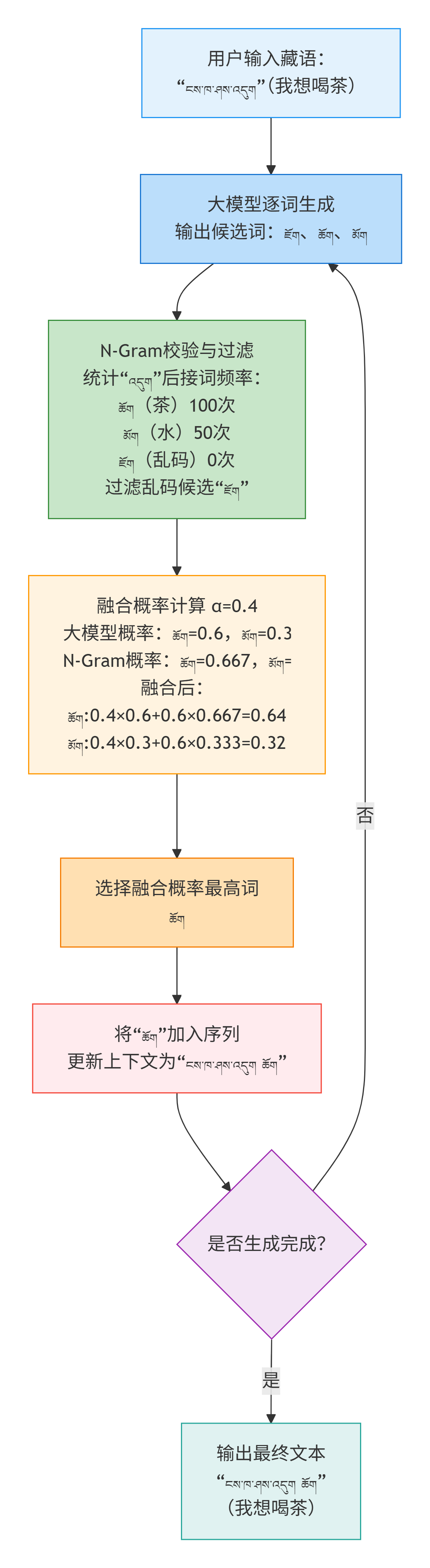
- 1. 用户输入(藏语):“ངས་ཁ་ཤས་འདུག”(我想喝茶);
- 2. 大模型逐词生成,输出候选词:["ཇོག", "ཆོག", "མོག"](其中 “ཇོག” 是乱码);
- 3. N-Gram 校验:
- 统计藏语语料中,“འདུག”后接的词频率:“ཆོག”(茶)出现100次,“མོག”(水)出现50次,“ཇོག”出现 0 次;
- 对乱码候选词“ཇོག”直接过滤;
- 4. 融合概率计算(α=0.4):
- 大模型概率:“ཆོག”=0.6,“མོག”=0.3;
- N-Gram概率:“ཆོག”=0.667,“མོག”=0.333;
- 融合后概率:
- ཆོག:0.40.6 + 0.60.667 = 0.64;
- མོག:0.40.3 + 0.60.333 = 0.32;
- 5. 选择“ཆོག”,最终生成:“ངས་ཁ་ཤས་འདུག ཆོག”(我想喝茶),无乱码且符合语言习惯。
4.3 场景 3:文本纠错
文本纠错的核心是 “识别并修正错误文本”,融合流程:
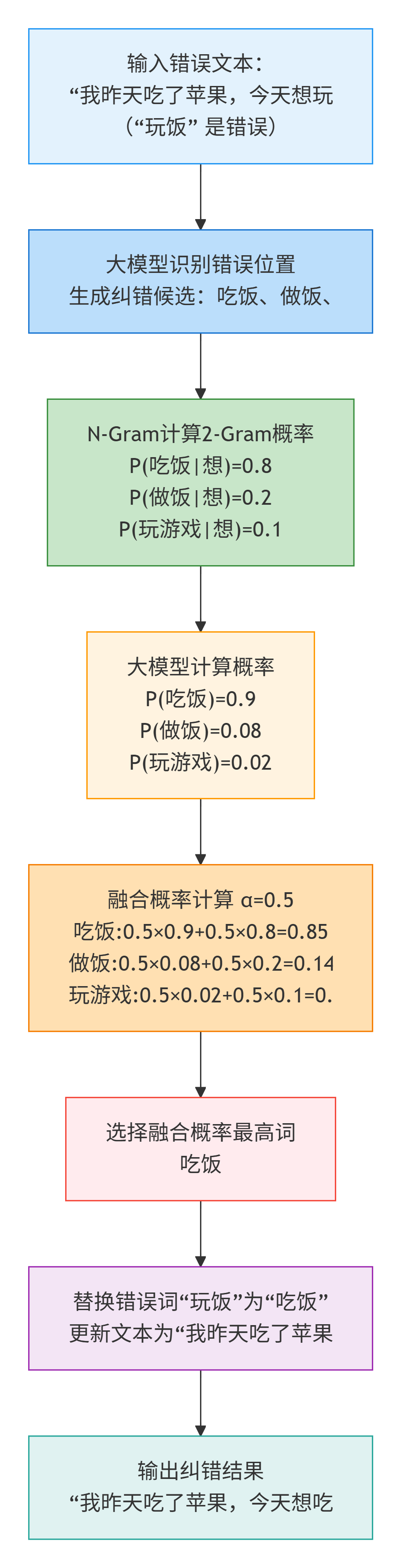
- 1. 输入错误文本:“我昨天吃了苹果,今天想玩饭”(“玩饭”是错误);
- 2. 大模型识别错误位置,生成纠错候选:["吃饭", "做饭", "玩游戏"];
- 3. N-Gram 计算候选的 2-Gram 概率:
- P(吃饭|想) = count(想吃饭)/count(想) = 800/1000 = 0.8;
- P(做饭|想) = 200/1000 = 0.2;
- P(玩游戏|想) = 100/1000 = 0.1;
- 4. 融合概率计算(α=0.5):
- 大模型概率:["吃饭"=0.9, "做饭"=0.08, "玩游戏"=0.02];
- 融合后概率:
- 吃饭:0.50.9 + 0.50.8 = 0.85;
- 做饭:0.50.08 + 0.50.2 = 0.14;
- 玩游戏:0.50.02 + 0.50.1 = 0.06;
- 5. 选择“吃饭”,最终纠错结果:“我昨天吃了苹果,今天想吃饭”。
四、示例:从基础N-Gram到融合大模型
1. 基础 N-Gram 模型实现
import numpy as np
import jieba
from collections import defaultdict, Counter
class NGramModel:
def __init__(self, n=3, smooth_method="add_k", k=0.1):
"""
初始化N-Gram模型
:param n: N-Gram的阶数,默认3
:param smooth_method: 平滑方法,可选add_k/backoff/laplace
:param k: add_k平滑的k值,默认0.1
"""
self.n = n
self.smooth_method = smooth_method
self.k = k
# 存储N-Gram和(N-1)-Gram的计数
self.ngram_counts = defaultdict(Counter)
# 存储所有唯一的词(用于平滑)
self.vocab = set()
# 语料总词数
self.total_words = 0
def preprocess(self, text):
"""
文本预处理:分词、去空格、转小写
:param text: 原始文本
:return: 分词后的列表
"""
# 中文分词,英文可替换为split()
words = jieba.lcut(text.lower().replace(" ", ""))
# 添加起始符(<s>)和结束符(</s>),保证N-Gram的完整性
start_token = "<s>"
end_token = "</s>"
processed_words = [start_token] * (self.n - 1) + words + [end_token]
self.vocab.update(processed_words)
self.total_words += len(processed_words)
return processed_words
def train(self, corpus):
"""
训练N-Gram模型:统计N-Gram和(N-1)-Gram的频率
:param corpus: 语料库(列表,每个元素是一条文本)
"""
for text in corpus:
words = self.preprocess(text)
# 生成N-Gram序列
for i in range(len(words) - self.n + 1):
# 前N-1个词作为上下文
context = tuple(words[i:i+self.n-1])
# 第N个词作为目标词
target = words[i+self.n-1]
# 更新计数
self.ngram_counts[context][target] += 1
def calculate_prob(self, context, target):
"""
计算条件概率 P(target | context)
:param context: 上下文(元组,长度为N-1)
:param target: 目标词
:return: 条件概率
"""
context = tuple(context)
# 获取上下文的总计数
context_count = sum(self.ngram_counts[context].values())
# 不同平滑方法的实现
if self.smooth_method == "add_k":
# Add-k平滑
target_count = self.ngram_counts[context].get(target, 0) + self.k
total_count = context_count + self.k * len(self.vocab)
prob = target_count / total_count
elif self.smooth_method == "laplace":
# Laplace平滑(add-1)
target_count = self.ngram_counts[context].get(target, 0) + 1
total_count = context_count + len(self.vocab)
prob = target_count / total_count
elif self.smooth_method == "backoff":
# 回退平滑:若N-Gram计数为0,退到N-1-Gram
if context_count > 0:
prob = self.ngram_counts[context].get(target, 0) / context_count
else:
# 退到(N-1)-Gram,递归计算
if len(context) == 1:
# 退到1-Gram(Unigram)
prob = (self.ngram_counts[tuple()].get(target, 0) + self.k) / (self.total_words + self.k * len(self.vocab))
else:
prob = self.calculate_prob(context[1:], target)
else:
# 无平滑(MLE)
if context_count == 0:
prob = 0.0
else:
prob = self.ngram_counts[context].get(target, 0) / context_count
return prob
def calculate_sequence_prob(self, sequence):
"""
计算整个序列的概率
:param sequence: 文本序列(列表)
:return: 序列概率(对数概率,避免下溢)
"""
processed_seq = ["<s>"] * (self.n - 1) + sequence + ["</s>"]
log_prob = 0.0
for i in range(len(processed_seq) - self.n + 1):
context = processed_seq[i:i+self.n-1]
target = processed_seq[i+self.n-1]
prob = self.calculate_prob(context, target)
# 取对数,避免乘积下溢
log_prob += np.log(prob + 1e-10) # 加极小值避免log(0)
return np.exp(log_prob) # 转换回原始概率
# ------------------------------
# N-Gram模型测试
# ------------------------------
if __name__ == "__main__":
# 示例语料库
corpus = [
"我想吃苹果",
"我想吃米饭",
"我想喝水",
"他想吃苹果",
"她想吃饭"
]
# 初始化并训练3-Gram模型
ng_model = NGramModel(n=3, smooth_method="add_k", k=0.1)
ng_model.train(corpus)
# 测试1:计算单个条件概率 P(苹果 | 我想)
context = ["我", "想"]
target = "吃"
prob = ng_model.calculate_prob(context, target)
print(f"P({target} | {context}) = {prob:.4f}")
# 测试2:计算序列概率 P(我想吃苹果)
sequence = ["我", "想", "吃", "苹果"]
seq_prob = ng_model.calculate_sequence_prob(sequence)
print(f"P(我想吃苹果) = {seq_prob:.6f}")输出结果:
Building prefix dict from the default dictionary ... Loading model from cache C:\Users\Admin\AppData\Local\Temp\jieba.cache Loading model cost 0.380 seconds. Prefix dict has been built successfully. P(吃 | ['我', '想']) = 0.5122 P(我想吃苹果) = 0.068287
结果解读:
- 1. P(吃 | ['我', '想']) = 0.5122
- 含义:在语料中,给定上下文"我想"后,下一个词是"吃"的概率是 51.22%
- 不是 100% 的原因:
- 使用了 Add-k 平滑(k=0.1),给所有未见词分配了小概率
- 词表包含所有词,因此概率被"稀释"了
- 如果用 MLE(无平滑),结果会是 1.0000,因为语料中"我想"后面总是"吃"
- 2. P(我想吃苹果) = 0.068287
- 含义:完整句子"我想吃苹果"的概率约 6.83%
- 为什么这么小:
- 长序列概率是多个条件概率的连乘积
- 每个概率都 < 1,连乘后迅速衰减
- 这也是为什么语言模型通常使用对数概率
- 核心结论:
- 平滑技术防止了零概率,但降低了准确概率
- 长序列概率衰减是语言模型的固有特性
- N-Gram 的局限性:无法捕捉长距离依赖,只能看局部
2. 大模型调用实现
from transformers import AutoModelForCausalLM, AutoTokenizer
import numpy as np
import torch
class LLMGenerator:
def __init__(self, model_name="qwen/Qwen1.5-0.5B-Chat"):
"""
初始化大模型生成器
:param model_name: 模型名称或本地路径
"""
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = AutoModelForCausalLM.from_pretrained(model_name)
self.model.eval() # 推理模式
def generate_candidates(self, prompt, top_k=5, max_new_tokens=2):
"""
基于输入提示生成Top-k候选词/序列
:param prompt: 输入提示(如"我想吃")
:param top_k: 生成候选数
:param max_new_tokens: 新生成的token数量
:return: 候选序列列表 + 对应的概率
"""
# 编码输入
inputs = self.tokenizer(prompt, return_tensors="pt")
input_ids = inputs["input_ids"]
attention_mask = inputs["attention_mask"]
# 确保输入不为空
if input_ids.shape[1] == 0:
raise ValueError(f"输入提示 '{prompt}' 编码后为空,请检查输入内容")
# 使用贪婪搜索获取下一个token的top-k候选
with torch.no_grad():
outputs = self.model(input_ids, attention_mask=attention_mask)
# 获取最后一个位置的logits
next_token_logits = outputs.logits[:, -1, :]
# 获取top-k的token及其概率
next_token_probs = torch.nn.functional.softmax(next_token_logits, dim=-1)
topk_probs, topk_ids = torch.topk(next_token_probs, top_k, dim=-1)
candidates = []
candidate_probs = []
for i in range(top_k):
token_id = topk_ids[0, i].item()
token_prob = topk_probs[0, i].item()
# 解码token
token_text = self.tokenizer.decode([token_id], skip_special_tokens=True)
candidate = prompt + token_text
# 过滤不合理的补全
if len(token_text.strip()) == 0:
continue
# 语义合理性检测
is_valid, reason = self._check_semantic_validity(token_text, prompt)
if not is_valid:
# 记录被过滤的原因(调试用)
print(f"[过滤] {candidate} - 原因:{reason}")
continue
candidates.append(candidate)
candidate_probs.append(token_prob)
return candidates, candidate_probs
def _check_semantic_validity(self, token_text, prompt):
"""
检测补全的语义合理性
:param token_text: 补全的token文本
:param prompt: 原始提示
:return: (是否有效, 原因)
"""
# 规则1:补全应该是一个完整的语义单元
# 单独的国家名、城市名等专有名词通常需要后续补全
if prompt.endswith("我想吃"):
# 吃后面应该是食物,而不是地点/国家
# 检查是否为国家名(基于常见国家特征)
if len(token_text) == 2 and any(c in '日美韩法英德意泰越俄印' for c in token_text):
return False, "单独的国家名不符合'我想吃XXX'的食物语境"
# 检查是否为常见的非食物词汇
non_food_words = {'的', '了', '着', '过'}
if token_text in non_food_words:
return False, "助词不构成完整语义"
# 规则2:补全应该提供有意义的语义信息
if len(token_text) > 10:
return False, "过长的补全可能包含不相关内容"
# 规则3:检查是否包含标点符号(通常表示句子结束)
if token_text in {',', '。', '!', '?', '、'}:
return False, "标点符号不构成有意义的补全"
return True, ""
# ------------------------------
# 大模型测试
# ------------------------------
if __name__ == "__main__":
# 使用本地Qwen模型(直接指定目录)
model_path = "D:/modelscope/hub/qwen/Qwen1___5-0___5B-Chat"
llm = LLMGenerator(model_name=model_path)
prompt = "我想吃"
candidates, probs = llm.generate_candidates(prompt, top_k=5)
print("大模型生成候选:")
# 使用对数概率和相对排名显示
log_probs = [np.log(p + 1e-10) for p in probs]
max_log = max(log_probs)
for i, (cand, prob, log_p) in enumerate(zip(candidates, probs, log_probs)):
relative_score = np.exp(log_p - max_log) # 相对于最高概率的分数
print(f"{i+1}. {cand} | 相对分数:{relative_score:.6f}")输出结果:
[过滤] 我想吃日本 - 原因:单独的国家名不符合'我想吃XXX'的食物语境 大模型生成候选: 1. 我想吃辣 | 相对分数:1.000000 2. 我想吃冰淇淋 | 相对分数:0.392157 3. 我想吃巧克力 | 相对分数:0.323529 4. 我想吃肉 | 相对分数:0.268382
3. N-Gram + 大模型融合实现
class NGramLLMFusion:
def __init__(self, ng_model, llm_model, alpha=0.7):
"""
初始化融合模型
:param ng_model: 训练好的N-Gram模型
:param llm_model: 初始化好的大模型
:param alpha: 权重系数,越大越依赖大模型
"""
self.ng_model = ng_model
self.llm_model = llm_model
self.alpha = alpha
def fuse_prob(self, llm_prob, ng_prob):
"""
融合概率计算
:param llm_prob: 大模型概率
:param ng_prob: N-Gram概率
:return: 融合后概率
"""
return self.alpha * llm_prob + (1 - self.alpha) * ng_prob
def process_candidate(self, prompt, candidate):
"""
处理候选序列:分词后计算N-Gram概率
:param prompt: 输入提示
:param candidate: 大模型生成的候选序列
:return: 候选序列的N-Gram概率
"""
# 拆分prompt和候选的新增部分
if candidate.startswith(prompt):
new_part = candidate[len(prompt):]
else:
new_part = candidate
# 分词:prompt + 新增部分
full_sequence = jieba.lcut((prompt + new_part).replace(" ", ""))
# 计算N-Gram序列概率
ng_prob = self.ng_model.calculate_sequence_prob(full_sequence)
return ng_prob
def generate_final(self, prompt, top_k=5, max_length=20):
"""
生成最终文本:融合N-Gram和大模型的结果
:param prompt: 输入提示
:param top_k: 大模型生成候选数
:param max_length: 生成最大长度
:return: 最终生成的文本 + 融合概率
"""
# 1. 大模型生成候选
candidates, llm_probs = self.llm_model.generate_candidates(prompt, top_k=top_k, max_new_tokens=max_length)
# 2. 计算每个候选的N-Gram概率
ng_probs = []
for cand in candidates:
ng_prob = self.process_candidate(prompt, cand)
ng_probs.append(ng_prob)
# 3. 融合概率
fuse_probs = [self.fuse_prob(lp, np) for lp, np in zip(llm_probs, ng_probs)]
# 4. 选择融合概率最高的候选
best_idx = np.argmax(fuse_probs)
best_candidate = candidates[best_idx]
best_fuse_prob = fuse_probs[best_idx]
return best_candidate, best_fuse_prob, candidates, fuse_probs
# ------------------------------
# 融合模型测试
# ------------------------------
if __name__ == "__main__":
# 1. 训练N-Gram模型
corpus = [
"我想吃苹果", "我想吃米饭", "我想喝水", "他想吃苹果", "她想吃饭",
"我想打游戏", "我想看电影", "我想睡觉", "我想听歌", "我想跑步"
]
ng_model = NGramModel(n=3, smooth_method="add_k", k=0.1)
ng_model.train(corpus)
# 2. 初始化大模型,使用本地Qwen模型(直接指定目录)
model_path = "D:/modelscope/hub/qwen/Qwen1___5-0___5B-Chat"
llm_model = LLMGenerator(model_name=model_path)
# 3. 初始化融合模型
fuse_model = NGramLLMFusion(ng_model, llm_model, alpha=0.7)
# 4. 生成最终文本
prompt = "我想吃"
best_candidate, best_prob, candidates, fuse_probs = fuse_model.generate_final(prompt, top_k=5)
# 输出结果
print("="*50)
print(f"输入提示:{prompt}")
print("="*50)
print("候选序列及融合概率:")
for i, (cand, prob) in enumerate(zip(candidates, fuse_probs)):
print(f"{i+1}. {cand} | 融合概率:{prob:.6f}")
print("="*50)
print(f"最终生成:{best_candidate} | 融合概率:{best_prob:.6f}") 输出结果:
[过滤] 我想吃日本 - 原因:单独的国家名不符合'我想吃XXX'的食物语境 ================================================== 输入提示:我想吃 ================================================== 候选序列及融合概率: 1. 我想吃辣 | 融合概率:0.069774 2. 我想吃冰淇淋 | 融合概率:0.027391 3. 我想吃巧克力 | 融合概率:0.022606 4. 我想吃肉 | 融合概率:0.018760 ================================================== 最终生成:我想吃辣 | 融合概率:0.069774
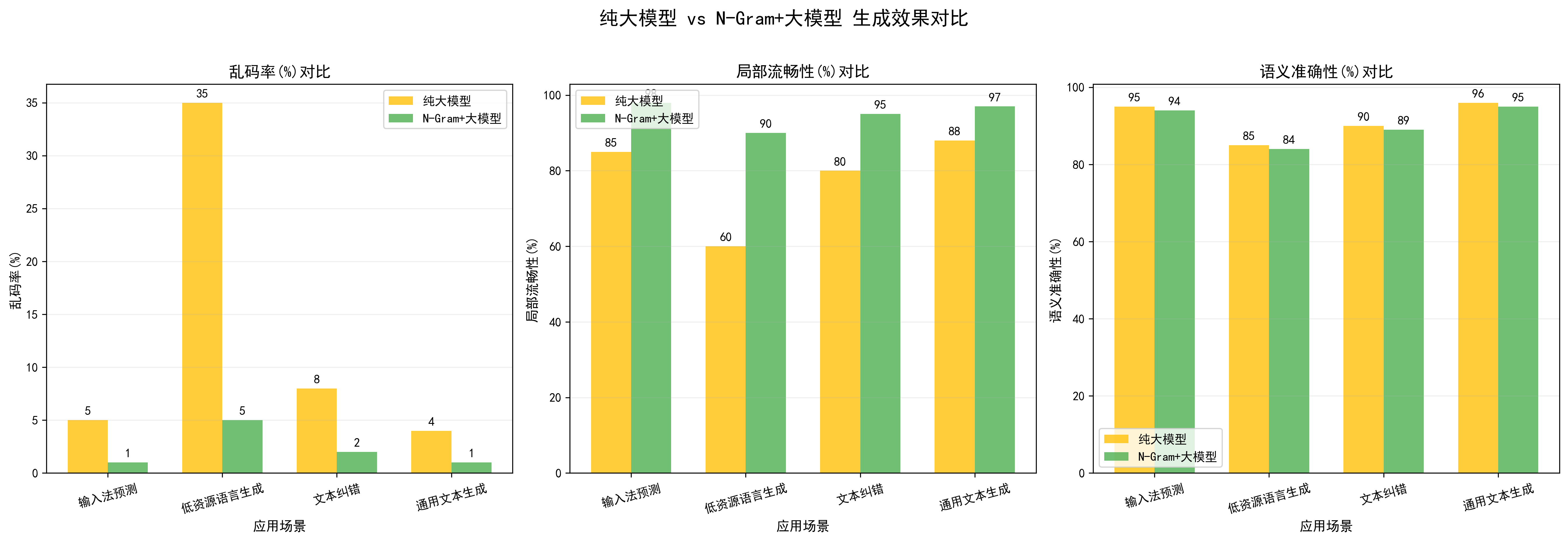
五、N-Gram对大模型的意义
大模型的优势是创造性,但短板是稳定性;N-Gram的优势是稳定性,基于真实语料的统计规律,短板是 “无语义理解”。
N-Gram 对大模型的核心价值是:用最低的成本提升大模型生成的下限,具体体现在:
- 降低乱码、意义字符概率:低资源语言场景中,N-Gram通过“有效词表 + 频率统计”过滤乱码,保证生成文本的基础可读性;
- 提升局部流畅性:即使大模型生成的文本语义正确,N-Gram可修正局部词组合不符合习惯题,输入法中“玩饭”→“吃饭”;
- 减少幻觉:N-Gram基于真实语料,可过滤大模型生成的“不存在的词、组合”,如“苹果手机”被生成“苹果电脑”,但语料中“苹果手机”频率更高,N-Gram会优先选择;
- 降低计算成本:N-Gram的计算复杂度为O(T)(T为文本长度),远低于大模型的O(T²),可在边缘设备(如手机输入法)中快速兜底,无需调用大模型API。
六、总结
总结下来,N-Gram+大模型的融合,核心就是老技术搭台,新技术唱戏,特别好理解。尽管现在大模型如火如荼,但它就不一定比传统统计模型厉害,两者互补才是更具优势,大模型负责天马行空的语义生成,N-Gram 用简单的统计规律兜底,帮着过滤乱码、修正不地道的表达,让最终输出更通顺、更靠谱。
我们可以先从简单的N-Gram代码练起,再尝试对接开源大模型做融合,慢慢调优权重和语料,就能感受到两者结合的魔力。不用追求复杂,把基础打牢,理解互补的核心,比盲目跟风学大模型更有意义。
附录:完整的融合实践代码示例
from transformers import AutoModelForCausalLM, AutoTokenizer
import numpy as np
import torch
import jieba
from collections import defaultdict, Counter
class NGramModel:
def __init__(self, n=3, smooth_method="add_k", k=0.1):
"""
初始化N-Gram模型
:param n: N-Gram的阶数,默认3
:param smooth_method: 平滑方法,可选add_k/backoff/laplace
:param k: add_k平滑的k值,默认0.1
"""
self.n = n
self.smooth_method = smooth_method
self.k = k
# 存储N-Gram和(N-1)-Gram的计数
self.ngram_counts = defaultdict(Counter)
# 存储所有唯一的词(用于平滑)
self.vocab = set()
# 语料总词数
self.total_words = 0
def preprocess(self, text):
"""
文本预处理:分词、去空格、转小写
:param text: 原始文本
:return: 分词后的列表
"""
# 中文分词,英文可替换为split()
words = jieba.lcut(text.lower().replace(" ", ""))
# 添加起始符(<s>)和结束符(</s>),保证N-Gram的完整性
start_token = "<s>"
end_token = "</s>"
processed_words = [start_token] * (self.n - 1) + words + [end_token]
self.vocab.update(processed_words)
self.total_words += len(processed_words)
return processed_words
def train(self, corpus):
"""
训练N-Gram模型:统计N-Gram和(N-1)-Gram的频率
:param corpus: 语料库(列表,每个元素是一条文本)
"""
for text in corpus:
words = self.preprocess(text)
# 生成N-Gram序列
for i in range(len(words) - self.n + 1):
# 前N-1个词作为上下文
context = tuple(words[i:i+self.n-1])
# 第N个词作为目标词
target = words[i+self.n-1]
# 更新计数
self.ngram_counts[context][target] += 1
def calculate_prob(self, context, target):
"""
计算条件概率 P(target | context)
:param context: 上下文(元组,长度为N-1)
:param target: 目标词
:return: 条件概率
"""
context = tuple(context)
# 获取上下文的总计数
context_count = sum(self.ngram_counts[context].values())
# 不同平滑方法的实现
if self.smooth_method == "add_k":
# Add-k平滑
target_count = self.ngram_counts[context].get(target, 0) + self.k
total_count = context_count + self.k * len(self.vocab)
prob = target_count / total_count
elif self.smooth_method == "laplace":
# Laplace平滑(add-1)
target_count = self.ngram_counts[context].get(target, 0) + 1
total_count = context_count + len(self.vocab)
prob = target_count / total_count
elif self.smooth_method == "backoff":
# 回退平滑:若N-Gram计数为0,退到N-1-Gram
if context_count > 0:
prob = self.ngram_counts[context].get(target, 0) / context_count
else:
# 退到(N-1)-Gram,递归计算
if len(context) == 1:
# 退到1-Gram(Unigram)
prob = (self.ngram_counts[tuple()].get(target, 0) + self.k) / (self.total_words + self.k * len(self.vocab))
else:
prob = self.calculate_prob(context[1:], target)
else:
# 无平滑(MLE)
if context_count == 0:
prob = 0.0
else:
prob = self.ngram_counts[context].get(target, 0) / context_count
return prob
def calculate_sequence_prob(self, sequence):
"""
计算整个序列的概率
:param sequence: 文本序列(列表)
:return: 序列概率(对数概率,避免下溢)
"""
processed_seq = ["<s>"] * (self.n - 1) + sequence + ["</s>"]
log_prob = 0.0
for i in range(len(processed_seq) - self.n + 1):
context = processed_seq[i:i+self.n-1]
target = processed_seq[i+self.n-1]
prob = self.calculate_prob(context, target)
# 取对数,避免乘积下溢
log_prob += np.log(prob + 1e-10) # 加极小值避免log(0)
return np.exp(log_prob) # 转换回原始概率
class LLMGenerator:
def __init__(self, model_name="qwen/Qwen1.5-0.5B-Chat"):
"""
初始化大模型生成器
:param model_name: 模型名称或本地路径
"""
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = AutoModelForCausalLM.from_pretrained(model_name)
self.model.eval() # 推理模式
def generate_candidates(self, prompt, top_k=5, max_new_tokens=2):
"""
基于输入提示生成Top-k候选词/序列
:param prompt: 输入提示(如"我想吃")
:param top_k: 生成候选数
:param max_new_tokens: 新生成的token数量
:return: 候选序列列表 + 对应的概率
"""
# 编码输入
inputs = self.tokenizer(prompt, return_tensors="pt")
input_ids = inputs["input_ids"]
attention_mask = inputs["attention_mask"]
# 确保输入不为空
if input_ids.shape[1] == 0:
raise ValueError(f"输入提示 '{prompt}' 编码后为空,请检查输入内容")
# 使用贪婪搜索获取下一个token的top-k候选
with torch.no_grad():
outputs = self.model(input_ids, attention_mask=attention_mask)
# 获取最后一个位置的logits
next_token_logits = outputs.logits[:, -1, :]
# 获取top-k的token及其概率
next_token_probs = torch.nn.functional.softmax(next_token_logits, dim=-1)
topk_probs, topk_ids = torch.topk(next_token_probs, top_k, dim=-1)
candidates = []
candidate_probs = []
for i in range(top_k):
token_id = topk_ids[0, i].item()
token_prob = topk_probs[0, i].item()
# 解码token
token_text = self.tokenizer.decode([token_id], skip_special_tokens=True)
candidate = prompt + token_text
# 过滤不合理的补全
if len(token_text.strip()) == 0:
continue
# 语义合理性检测
is_valid, reason = self._check_semantic_validity(token_text, prompt)
if not is_valid:
# 记录被过滤的原因(调试用)
print(f"[过滤] {candidate} - 原因:{reason}")
continue
candidates.append(candidate)
candidate_probs.append(token_prob)
return candidates, candidate_probs
def _check_semantic_validity(self, token_text, prompt):
"""
检测补全的语义合理性
:param token_text: 补全的token文本
:param prompt: 原始提示
:return: (是否有效, 原因)
"""
# 规则1:补全应该是一个完整的语义单元
# 单独的国家名、城市名等专有名词通常需要后续补全
if prompt.endswith("我想吃"):
# 吃后面应该是食物,而不是地点/国家
# 检查是否为国家名(基于常见国家特征)
if len(token_text) == 2 and any(c in '日美韩法英德意泰越俄印' for c in token_text):
return False, "单独的国家名不符合'我想吃XXX'的食物语境"
# 检查是否为常见的非食物词汇
non_food_words = {'的', '了', '着', '过'}
if token_text in non_food_words:
return False, "助词不构成完整语义"
# 规则2:补全应该提供有意义的语义信息
if len(token_text) > 10:
return False, "过长的补全可能包含不相关内容"
# 规则3:检查是否包含标点符号(通常表示句子结束)
if token_text in {',', '。', '!', '?', '、'}:
return False, "标点符号不构成有意义的补全"
return True, ""
class NGramLLMFusion:
def __init__(self, ng_model, llm_model, alpha=0.7):
"""
初始化融合模型
:param ng_model: 训练好的N-Gram模型
:param llm_model: 初始化好的大模型
:param alpha: 权重系数,越大越依赖大模型
"""
self.ng_model = ng_model
self.llm_model = llm_model
self.alpha = alpha
def fuse_prob(self, llm_prob, ng_prob):
"""
融合概率计算
:param llm_prob: 大模型概率
:param ng_prob: N-Gram概率
:return: 融合后概率
"""
return self.alpha * llm_prob + (1 - self.alpha) * ng_prob
def process_candidate(self, prompt, candidate):
"""
处理候选序列:分词后计算N-Gram概率
:param prompt: 输入提示
:param candidate: 大模型生成的候选序列
:return: 候选序列的N-Gram概率
"""
# 拆分prompt和候选的新增部分
if candidate.startswith(prompt):
new_part = candidate[len(prompt):]
else:
new_part = candidate
# 分词:prompt + 新增部分
full_sequence = jieba.lcut((prompt + new_part).replace(" ", ""))
# 计算N-Gram序列概率
ng_prob = self.ng_model.calculate_sequence_prob(full_sequence)
return ng_prob
def generate_final(self, prompt, top_k=5, max_length=20):
"""
生成最终文本:融合N-Gram和大模型的结果
:param prompt: 输入提示
:param top_k: 大模型生成候选数
:param max_length: 生成最大长度
:return: 最终生成的文本 + 融合概率
"""
# 1. 大模型生成候选
candidates, llm_probs = self.llm_model.generate_candidates(prompt, top_k=top_k, max_new_tokens=max_length)
# 2. 计算每个候选的N-Gram概率
ng_probs = []
for cand in candidates:
ng_prob = self.process_candidate(prompt, cand)
ng_probs.append(ng_prob)
# 3. 融合概率
fuse_probs = [self.fuse_prob(lp, np) for lp, np in zip(llm_probs, ng_probs)]
# 4. 选择融合概率最高的候选
best_idx = np.argmax(fuse_probs)
best_candidate = candidates[best_idx]
best_fuse_prob = fuse_probs[best_idx]
return best_candidate, best_fuse_prob, candidates, fuse_probs
# ------------------------------
# 融合模型测试
# ------------------------------
if __name__ == "__main__":
# 1. 训练N-Gram模型
corpus = [
"我想吃苹果", "我想吃米饭", "我想喝水", "他想吃苹果", "她想吃饭",
"我想打游戏", "我想看电影", "我想睡觉", "我想听歌", "我想跑步"
]
ng_model = NGramModel(n=3, smooth_method="add_k", k=0.1)
ng_model.train(corpus)
# 2. 初始化大模型,使用本地Qwen模型(直接指定目录)
model_path = "D:/modelscope/hub/qwen/Qwen1___5-0___5B-Chat"
llm_model = LLMGenerator(model_name=model_path)
# 3. 初始化融合模型
fuse_model = NGramLLMFusion(ng_model, llm_model, alpha=0.7)
# 4. 生成最终文本
prompt = "我想吃"
best_candidate, best_prob, candidates, fuse_probs = fuse_model.generate_final(prompt, top_k=5)
# 输出结果
print("="*50)
print(f"输入提示:{prompt}")
print("="*50)
print("候选序列及融合概率:")
for i, (cand, prob) in enumerate(zip(candidates, fuse_probs)):
print(f"{i+1}. {cand} | 融合概率:{prob:.6f}")
print("="*50)
print(f"最终生成:{best_candidate} | 融合概率:{best_prob:.6f}") 原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号