vLLM 最新版来了,修复 DeepSeek-V4 跑不稳、跑不快的问题

vLLM 最新版来了,修复 DeepSeek-V4 跑不稳、跑不快的问题

Ai学习的老章
发布于 2026-05-08 12:29:05
发布于 2026-05-08 12:29:05
节前我连着写了三篇 vLLM × DeepSeek V4 的文章:
- 大版本更新,vLLM 0.20 来了,支持 DeepSeek V4
- vLLM解密:DeepSeek-V4本地部署为何如此困难
- DeepSeek-V4-Flash 本地部署,2 x H20(96GB版本),性能简测
劳动节假期还没过完,vLLM 团队就给我加了道菜——0.20.1 紧急 patch 出炉了,主线就一句话:把 DSV4 跑不稳、跑不快的问题集中处理一遍
简介
先把版本性质说清楚:v0.20.1 是 v0.20.0 的补丁版本,不是新功能堆料,而是围绕 DeepSeek V4 做稳定化 + 性能调优,外加一批通用 bug 修复
如果你正在本地跑 DSV4 / DSV4-Flash,强烈建议升级;如果你还在用 0.19.x 老老实实跑 V3,那这版意义不大,等 0.21 再说
DeepSeek V4 这一块改了啥
这是这个 patch 的主线,我认真研究了 release notes :
1. 模型支持收口
- 把 DSV4 的 base model 正式接进来(PR #41006)——之前 V4 是带"实验"标签的,这一版算是把基础打牢了
- Pure TP 模式下给 megamoe flag 上了保护(#41522),避免错误配置直接把进程干崩
2. 性能优化(这部分含金量很高)
- Multi-stream pre-attention GEMM(#41061):把 attention 之前的矩阵乘法拆到多个 CUDA stream 上并发跑,解决了 GEMM 等 attention 卡 GPU 利用率的老问题
- 配套加了一个调优旋钮
VLLM_MULTI_STREAM_GEMM_TOKEN_THRESHOLD(#41443、#41526),还顺手把默认值调到了一个比较合理的点上——这就是写过《为何如此困难》那篇里抱怨"参数全靠玄学"的直接回应 - FlashInfer one-sided 通信支持 BF16 + MXFP8 all-to-all(#40960):MoE 跨 GPU 调度的核心通信路径,BF16/MXFP8 双精度都打通,多卡部署 V4 这下顺了
- PTX
cvt指令加速 FP32→FP4 转换(#41015):直接下到指令级别压榨硬件,FP4 推理路径吞吐能再上一档 - head_compute_mix_kernel tile kernel 集成(#41255):head 计算路径专门做了 kernel 优化
3. 一批要命的 Bug 修复
这部分尤其值得贴出来,因为不少都是社区里反复哀嚎过的:
- TopK=1024 时持久化 topk 协作死锁(#41189)——多并发跑久了进程突然卡死,元凶就是这个
- RadixRowState 的 inter-CTA 初始化竞争(#41444)
- 临时把 persistent topk 关掉作为 workaround(#41442)——稳定性优先于性能的取舍
- AOT 编译缓存导致 import error(#41090)——升级后报"模块导入失败",多半就是它
- torch inductor 报错(#41135)
- RoPE cache 重复初始化(#41148)——表现是显存被偷偷吃掉一块
- DSV3.2 / V4 非流式 tool calls 类型转换缺失(#41198)——做 Agent 调用的老板必须升
随机卡死、显存莫名爆涨、tool call 偶发不返回、OOM 之后再起进程报 import error——这次基本都被一锅端了
通用 Bug 修复
不只是 V4,0.20.1 还顺手把几个影响所有用户的 bug 修了:
max_num_batched_token没被 CUDA graph 正确捕获(#40734)num_gpu_blocks_override在max_model_len校验里没被算进去(#41069)——手动调显存块数的老板请抬头- 自动禁用 cumem 内存池附近的
expandable_segments(#40812) - BailingMoE linear layer(#40859)和 V2.5 的 MLA RoPE 旋转修复(#41185)
- reasoning parser 的 kwargs 没传给 structured output(#41199)——对结构化输出影响很大
- ROCm:Quark W4A8 GPT-OSS 的
input_ids和expert_map参数修复(#41165)
ROCm 用户也别走,这版对你们也有礼物
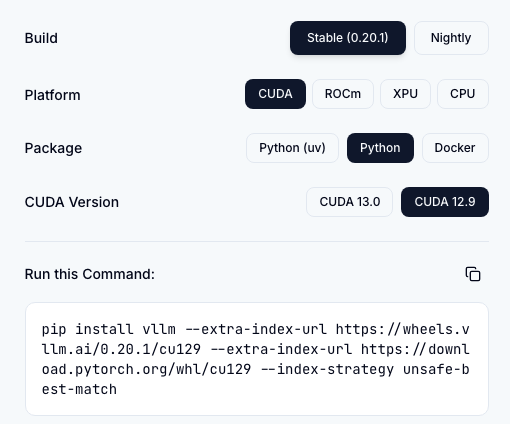
安装
升级方式没变化,CUDA 13.0 + PyTorch 2.11 是 0.20.x 的标配,0.20.1 也跟着这个组合:
# 推荐用 uv
uv pip install --upgrade vllm
# 或者老老实实 pip
pip install --upgrade vllm
如果你还在 CUDA 12.9 的环境上,官方推荐的写法是:
uv pip install vllm --torch-backend=cu129
Docker 镜像:
docker pull vllm/vllm-openai:v0.20.1
升级前如果你跑过 0.20.0,记得清一下 ~/.cache/vllm 下面的 AOT 编译缓存,否则可能命中 #41090 那个 import error
我的建议
❝一句话:正在跑 V4 的,立刻升;其他用户,按部就班升
具体到几类老板:
- 跑 DSV4-Flash 的小机型用户(比如我前面那篇 2×H20 96GB 的配置):直接升,多 stream GEMM + FP4 转换加速对你们这种"卡显存又卡算力"的场景收益最大
- 多卡集群跑满血 V4:FlashInfer all-to-all 的 BF16/MXFP8 支持是核心收益,all-reduce 阶段的瓶颈被进一步打开
- 做 Agent / Function Calling 的:tool calls 类型转换那个 fix(#41198)你必须升,不然偶发返回缺字段会让上层应用一头雾水
- 还在 V3 / V3.2 阵营:升级风险低收益也不大,可以等 0.21 主线版本
One More Thing
看完这次 release notes 我有一个挺直接的感受:vLLM 团队对 DSV4 的投入是真的舍得给资源——从 0.20.0 的"基础支持"到 0.20.1 的"性能 + 稳定性双升",前后才隔了不到两周
这也侧面印证了一件事:DeepSeek V4 这条路线,已经成为开源推理框架第一优先级要支持好的目标模型,没有之一
至于 V4 部署本身那些"硬件门槛高、配置玄学多"的根本性难题,0.20.1 解决了一部分,但远远没全解决。等我假期后摸到 H20 集群,再做一轮升级前后的对比实测,到时候再来跟老板们汇报
#vLLM #DeepSeekV4 #大模型部署 #推理引擎 #开源
制作不易,如果这篇文章觉得对你有用,可否点个关注。给我个三连击:点赞、转发和在看。若可以再给我加个🌟,谢谢你看我的文章,我们下篇再见!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-05,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号