YOLO 训练调参:从「炼丹」到「控温」

YOLO 训练调参:从「炼丹」到「控温」

javpower
发布于 2026-05-08 18:58:39
发布于 2026-05-08 18:58:39
YOLO 训练调参:从「炼丹」到「控温」
YOLO、Hyperparameter Tuning、Loss Curve、mAP、数据增强、工业质检
一、为什么你的 YOLO 模型训不好?
很多开发者拿到 YOLO 后,直接复制一段 model.train() 代码就开始跑,结果发现:
- mAP 卡在 0.3 上不去
- Loss 震荡不收敛
- 训练集表现很好,测试集一塌糊涂(过拟合)
根本原因在于:你没有理解每个参数背后的物理意义。
本文将带你系统梳理 YOLO 训练全链路的超参数,手把手教你「看什么曲线、调什么参数、为什么这么调」。
二、YOLO 训练 Pipeline 全景图
在调参之前,先看懂数据流:
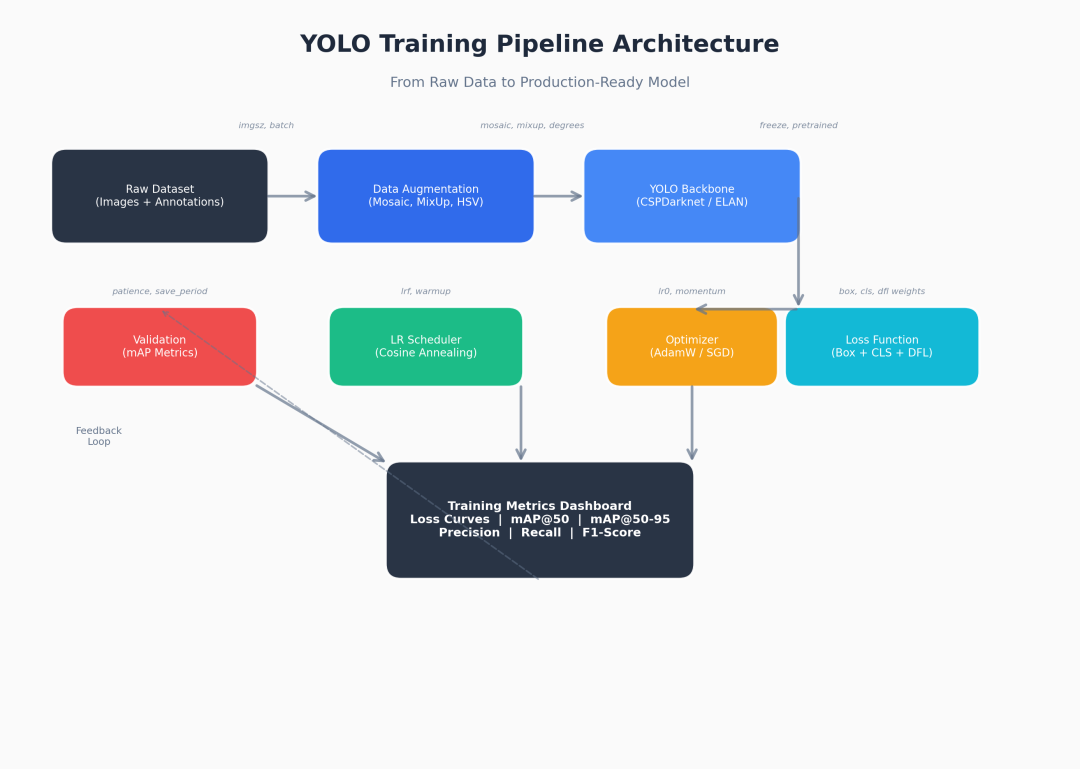
YOLO Training Pipeline Architecture
核心链路:原始数据 → 数据增强(Augmentation)→ Backbone 特征提取 → Loss 计算 → 优化器更新 → LR 调度 → 验证反馈。
每个环节都有对应的可调参数,下面逐一拆解。
三、核心参数详解:从「是什么」到「怎么调」
3.1 基础训练参数
参数 | 含义 | 默认值 | 调参建议 |
|---|---|---|---|
epochs | 训练轮数 | 100 | 小数据集 50~100,大数据集 200+ |
imgsz | 输入图像尺寸 | 640 | 小目标检测用 1280,速度优先用 320 |
batch | Batch Size | 16 | 显存允许范围内越大越好,建议 ≥ 8 |
patience | 早停耐心值 | 50 | 验证 mAP 不提升则停止,省时间 |
save_period | 保存周期 | -1 | 建议设为 10,防止训崩后重头再来 |
代码示例:
from ultralytics import YOLO
model = YOLO("yolo11n.pt") # 加载预训练权重
results = model.train(
data="custom.yaml",
epochs=100,
imgsz=640,
batch=16,
patience=20, # 20 轮不提升就停
save_period=10, # 每 10 轮保存 checkpoint
device=0 # GPU 编号
)
3.2 优化器与学习率(最关键!)
参数 | 含义 | 默认值 | 调参建议 |
|---|---|---|---|
optimizer | 优化器 | auto | 短训练用 AdamW,长训练用 MuSGD |
lr0 | 初始学习率 | 0.01 | 小数据集降至 0.001,大数据集可保持 |
lrf | 最终学习率系数 | 0.01 | 默认即可,Cosine Annealing 会用到 |
warmup_epochs | 预热轮数 | 3.0 | 大数据集可增至 5,防止初期震荡 |
学习率调度策略:
YOLO 默认采用 Cosine Annealing + Warmup 组合策略:
Cosine Annealing LR Schedule
- Warmup 阶段:前 3 轮学习率从 0 线性爬升到
lr0,防止冷启动时梯度爆炸 - Cosine 阶段:后续按余弦曲线平滑衰减到
lrf * lr0,帮助收敛到更优局部最小值
调参口诀:
Loss 震荡不降 →
lr0除以 10 Loss 下降太慢 →lr0乘以 2 训练后期震荡 → 增大warmup_epochs
3.3 数据增强参数(最容易过拟合的环节)
YOLO 内置了丰富的增强策略,但小数据集切忌全开:
参数 | 含义 | 默认值 | 小数据集(<1K) | 大数据集(>50K) |
|---|---|---|---|---|
mosaic | 四图拼接 | 1.0 | 0.5 | 1.0 |
mixup | 图像混合 | 0.0 | 0.0 | 0.3 |
copy_paste | 复制粘贴 | 0.0 | 0.0 | 0.1 |
degrees | 旋转角度 | 0.0 | 5.0 | 15.0 |
scale | 缩放比例 | 0.5 | 0.3 | 0.9 |
hsv_h | 色调偏移 | 0.015 | 0.01 | 0.02 |
hsv_s | 饱和度偏移 | 0.7 | 0.4 | 0.8 |
hsv_v | 亮度偏移 | 0.4 | 0.3 | 0.5 |
flipud | 上下翻转 | 0.0 | 0.5(航拍) | 0.0 |
增强效果可视化:
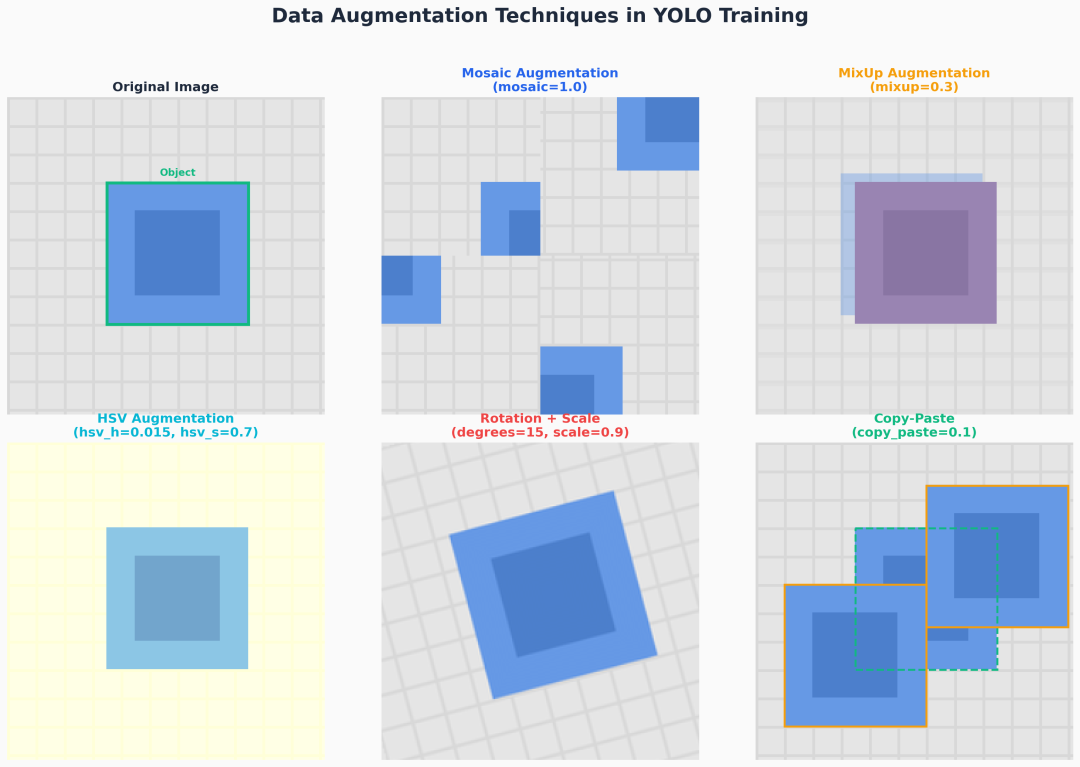
Data Augmentation Techniques
关键认知:
- Mosaic:通过拼接四张图丰富背景上下文,但对小目标不友好,工业缺陷检测建议
mosaic=0 - MixUp:线性混合两张图,提升模型鲁棒性,但会模糊边界,小数据集禁用
- Copy-Paste:将目标粘贴到新背景,适合实例分割任务,检测任务慎用
3.4 Loss 权重参数(进阶调优)
YOLO 的总 Loss 由三部分组成:
total_loss = box_loss * box + cls_loss * cls + dfl_loss * dfl
参数 | 含义 | 默认值 | 调参场景 |
|---|---|---|---|
box | 边界框回归权重 | 7.5 | 定位不准时增至 10.0 |
cls | 分类权重 | 0.5 | 类别混淆时增至 1.0 |
dfl | 分布焦点损失权重 | 1.5 | 小目标检测时增至 2.0 |
工业质检场景建议:
# 缺陷检测通常定位精度要求高,分类相对简单
model.train(
data="defect.yaml",
box=10.0, # 加重定位损失
cls=0.3, # 减轻分类损失
dfl=2.0, # 加重边界分布学习
close_mosaic=10 # 最后 10 轮关闭 Mosaic,稳定收敛
)
四、如何读懂训练曲线?
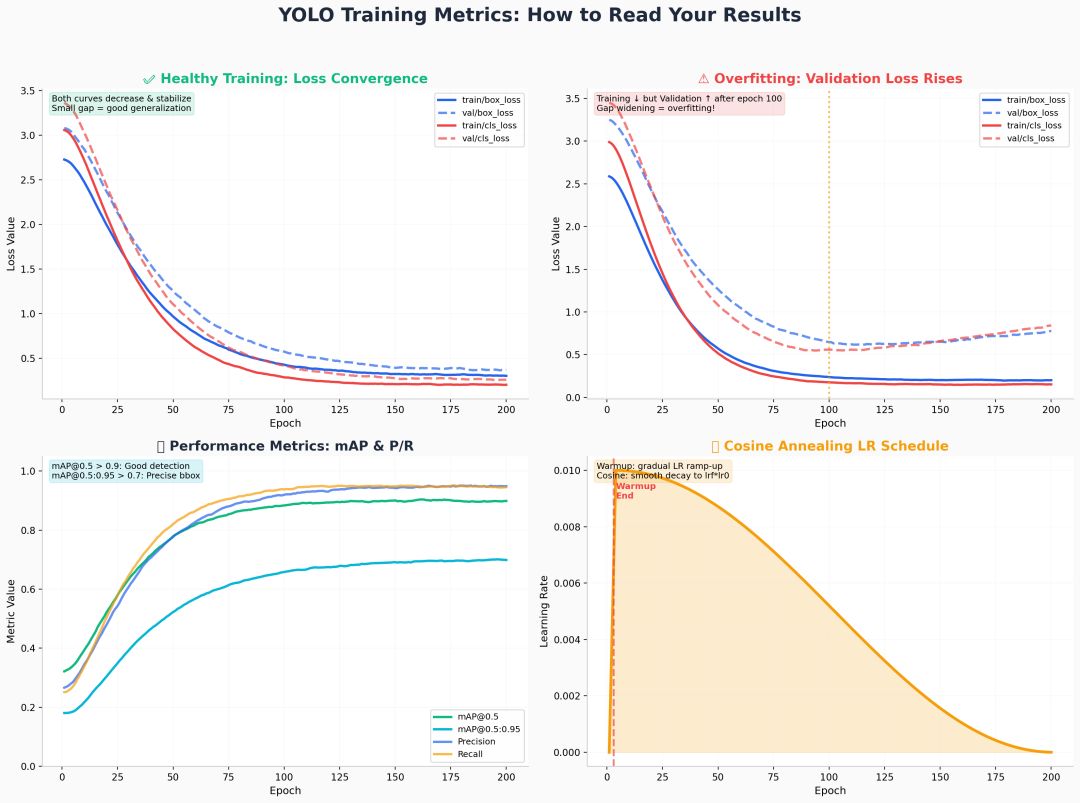
训练完成后,results.png 会生成一组曲线。学会读图,比盲目调参更重要。
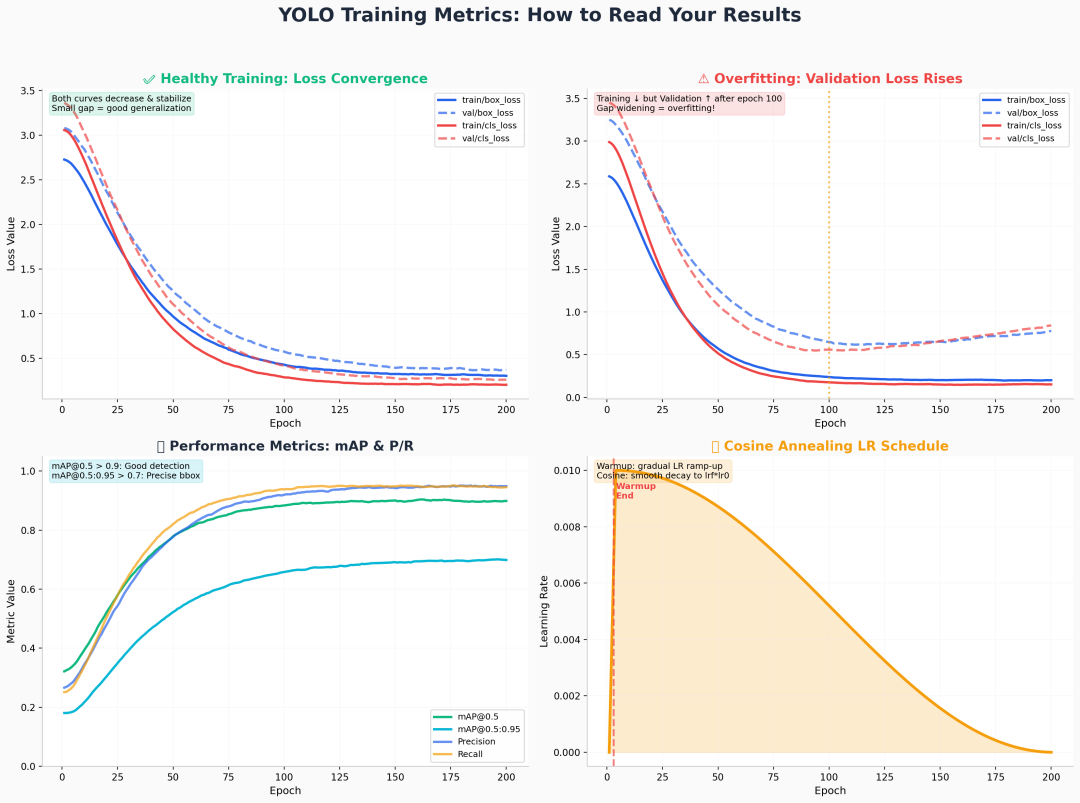
YOLO Training Metrics
4.1 Loss 曲线诊断
健康训练的标志:
train/box_loss与val/box_loss同步下降,最终差距 < 0.1train/cls_loss与val/cls_loss走势一致,无明显背离- 所有曲线在 50~100 epoch 后进入平台期
过拟合的预警信号:
- 训练 Loss 持续下降,验证 Loss 在 100 epoch 后开始 上升
- 两者差距逐渐 扩大
- 对策:立即启用 Early Stopping,或降低
lr0、减少增强强度
4.2 mAP 指标解读
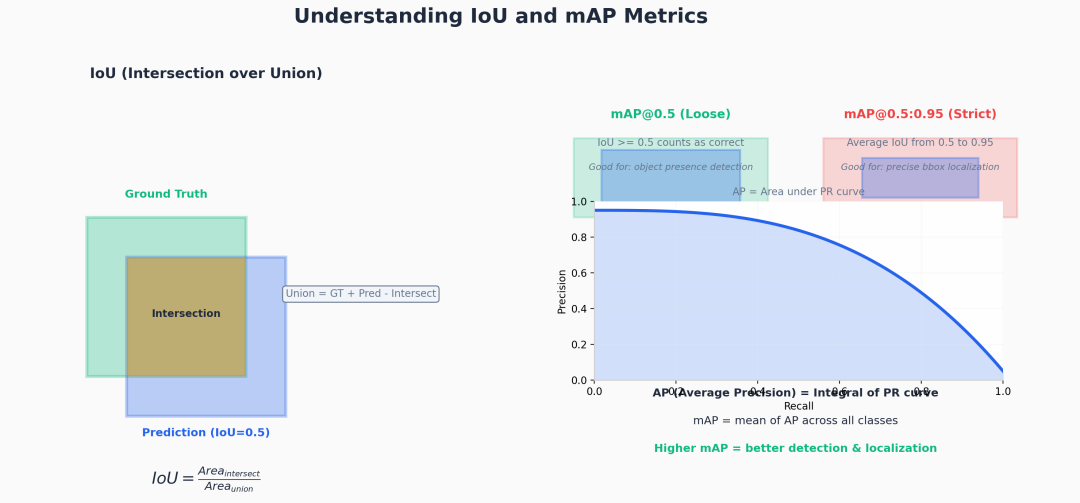
IoU and mAP Metrics
指标 | 含义 | 达标线 | 优秀线 |
|---|---|---|---|
mAP@0.5 | IoU≥0.5 即算正确 | 0.85 | 0.95 |
mAP@0.5:0.95 | IoU 从 0.5~0.95 取平均 | 0.60 | 0.80 |
Precision | 精确率:预测为正的样本中真正为正的比例 | 0.85 | 0.95 |
Recall | 召回率:真正为正的样本中被正确找出的比例 | 0.80 | 0.92 |
关键洞察:
mAP@0.5高但mAP@0.5:0.95低 → 定位不准,调大box权重或增加dflPrecision高但Recall低 → 漏检多,降低置信度阈值或增加copy_paste- 两者都低 → 根本问题在数据,检查标注质量或增加样本量
五、调参决策树:按场景定制方案
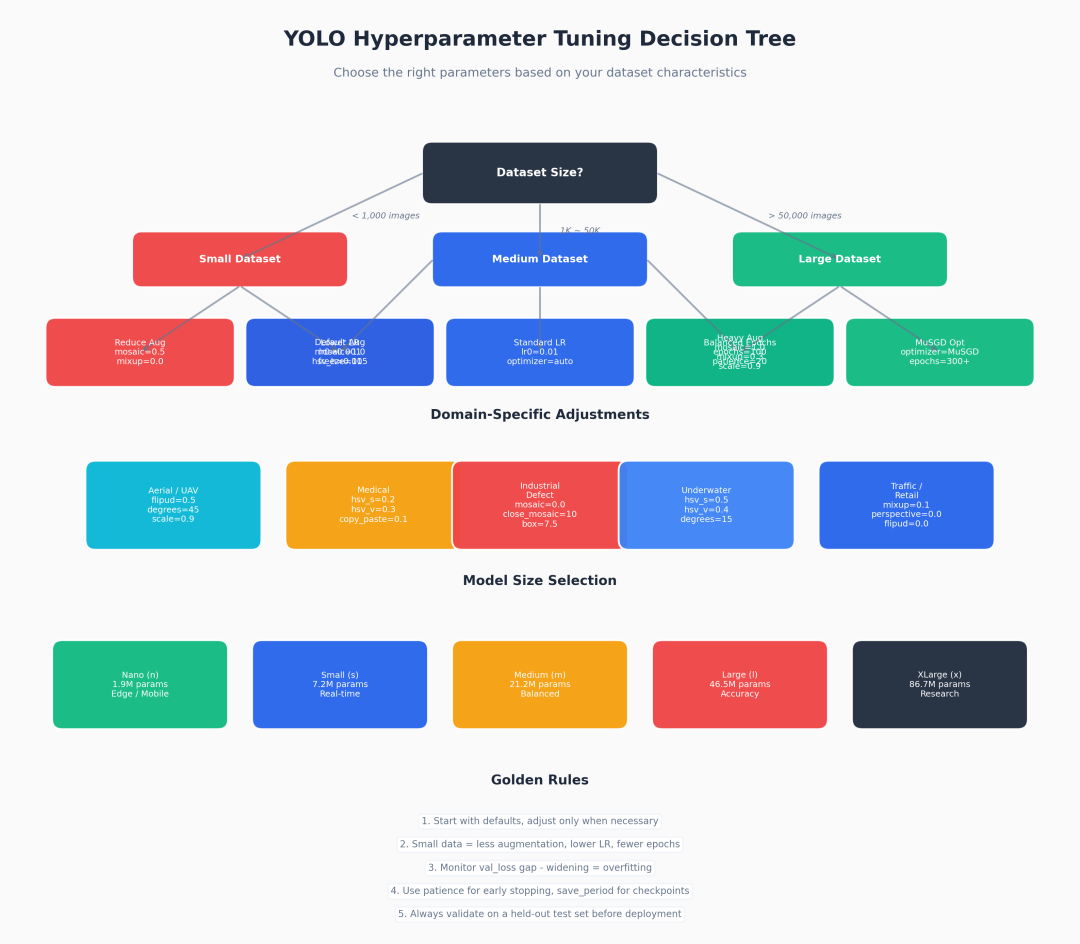
Hyperparameter Decision Tree
5.1 按数据集规模
小数据集(< 1,000 张):
model.train(
data="small.yaml",
epochs=50,
lr0=0.001, # 低学习率,防止过拟合
mosaic=0.5, # 减弱 Mosaic
mixup=0.0, # 禁用 MixUp
copy_paste=0.0, # 禁用 Copy-Paste
freeze=10, # 冻结 Backbone 前 10 层
patience=20
)
大数据集(> 50,000 张):
model.train(
data="large.yaml",
epochs=300,
optimizer="MuSGD", # 长训练用 MuSGD 更稳定
mosaic=1.0,
mixup=0.3,
scale=0.9,
patience=50
)
5.2 按应用场景
场景 | 关键调整 | 原因 |
|---|---|---|
工业缺陷检测 | mosaic=0, close_mosaic=10, box=10 | 缺陷通常很小,Mosaic 会破坏上下文 |
航拍/无人机 | flipud=0.5, degrees=45 | 目标方向任意,需增强旋转鲁棒性 |
医学影像 | hsv_s=0.2, hsv_v=0.3 | 色彩信息重要,避免过度扰动 |
交通监控 | mixup=0.1, perspective=0 | 摄像头固定,无需透视变换 |
水下检测 | hsv_s=0.5, hsv_v=0.4 | 光照不均,需增强亮度鲁棒性 |
六、模型选型:Nano 还是 XLarge?
模型 | 参数量 | FLOPs | 适用场景 | 边缘部署 |
|---|---|---|---|---|
YOLO11n | 1.9M | 6.5G | 移动端、实时预览 | ✅ 推荐 |
YOLO11s | 7.2M | 21.5G | 实时检测、Web 服务 | ✅ 可行 |
YOLO11m | 21.2M | 68.0G | 平衡精度与速度 | ⚠️ 需量化 |
YOLO11l | 46.5M | 147.0G | 高精度科研 | ❌ 不适合 |
YOLO11x | 86.7M | 257.0G | 服务器端、打榜 | ❌ 不适合 |
选型原则:
- 先训 Small 验证流程,确认数据无误后再上 Medium/Large
- 边缘部署必须量化:使用 INT8 量化可将 Nano 模型压缩至 1MB 以内
- 大模型收敛更快:YOLO26 的 X 模型只需 40 epoch,而 N 模型需要 245 epoch
七、checklist:训练前必查
□ 数据集划分:Train / Val / Test = 8:1:1,Test 绝对不参与调参
□ 标注检查:用 labelImg 或 Roboflow 可视化 10% 样本,确认框准
□ 类别平衡:若某类样本 < 5%,考虑过采样或 Copy-Paste
□ 预训练权重:务必加载 COCO 预训练权重(yolo11n.pt),别从头训
□ 单卡验证:先用 batch=1 跑通整个流程,再调 batch size
□ 日志监控:开启 TensorBoard,实时观察 Loss 曲线
八、调参的「第一性原理」
- 默认参数是 strong baseline,不要轻易全盘推翻
- 小数据保守,大数据激进:增强、LR、Epoch 都遵循此原则
- 验证 Loss 是真理:训练 Loss 再低,验证 Loss 上升就是过拟合
- 早停 + 周期性保存:防止训崩,保留最佳 checkpoint
- Test Set 只用一次:最终评估前绝不偷看测试集
最后一句忠告:调参是科学,不是玄学。每次只改一个变量,记录结果,建立直觉。三个月后,你也能一眼看出曲线哪里不对。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-08,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号