大模型评测不再拍脑袋:用 lm-evaluation-harness 给模型做"体检"

大模型评测不再拍脑袋:用 lm-evaluation-harness 给模型做"体检"

程序员架构进阶
发布于 2026-05-13 12:23:07
发布于 2026-05-13 12:23:07
当你说"这个模型挺聪明的",你凭什么这么说?
最近有个做 AI 客服的朋友跟我吐槽:团队微调了一个 7B 模型,内部测试"感觉不错",上线后用户投诉率反而上升了。问题出在哪里?通过询问,发现他们所谓的"测试",就是几个人轮流跟模型聊了几句,主观感受"还行"。另外还有一些朋友,最多也只是收集常问的几十个问题作为测试集。
这种"拍脑袋评测"在 AI 圈太常见了。今天得这篇文章,我想聊一个被很多人忽略但极其重要的工具——lm-evaluation-harness,以及它背后的一套标准化评测思维。
一、为什么模型评测不能靠"感觉"
1.1 主观评测的问题
想象你要买一台秤,卖家说"这秤很准,我们试过了",但你问他"准到什么程度?跟国家标准比偏差多少?",他答不上来。这样的称你敢买吗?
大模型就是这台秤。你说它"聪明",是在什么任务上聪明?数学题?代码?还是闲聊?你说它"比 GPT-4 差",差多少?在哪个维度差?
没有标准答案的评测,本质上就是在碰运气。
1.2 标准化评测的价值
标准化评测需要解决的三个核心问题:
- 可量化:把"聪明"变成 72.3% 的准确率,把"差一些"变成具体分数差。
- 可复现:任何人用同样的模型、同样的评测集、同样的参数,跑出来的分数应该一样。这是科学研究的底线。
- 可对比:A 模型在 MMLU 上 65%,B 模型 58%,这个差距是客观的,而不是"我觉得 A 更好"。
1.3 评测的本质是什么
简单来说,模型评测 = 给模型出一份标准化试卷,看它答对多少。
必须注意的是,这份"试卷"不是随便编的。它通常来自真实场景,甚至是业内公认可靠的测评集:- 小学数学竞赛题 → 测推理能力(GSM8K)- 美国高中各科考试 → 测知识广度(MMLU)- 日常常识判断 → 测世界认知(HellaSwag)- 科学问答 → 测事实准确性(ARC)
里面的每道题都有标准答案,模型答完自动打分。一批题跑完,就能画出模型的"能力画像"。

二、lm-evaluation-harness:大模型的"体检中心"
2.1 它是什么
lm-evaluation-harness (https://github.com/EleutherAI/lm-evaluation-harness)是由 EleutherAI(开源 AI 研究组织)开发的大模型统一评测框架。你可以把它理解为一个"体检中心"——你把模型送进来,它自动跑完 200 多项检查,输出一份详细的"体检报告"。
它的核心特点:- 任务最全:支持 200+ 评测任务,覆盖知识、推理、数学、代码、安全等多个维度- 模型兼容广:HuggingFace 模型、OpenAI API、Claude、Gemini、本地 Ollama 部署的模型,都能接- 社区标准:HuggingFace Open LLM Leaderboard 的官方评测工具,跑出来的分数可以直接上排行榜对比- 安装简单:一条 pip 命令搞定
2.2 评测流程长什么样
用 lm-eval 跑评测,流程很清晰:
选择模型 ──▶ 选择评测任务 ──▶ 自动出题阅卷 ──▶ 输出分数报告整个过程不需要你手动写题目、对答案、算分数,框架全包了。你只需要做两个决策:测哪个模型、测什么能力。
三、5 分钟上手:从安装到第一份报告
3.1 安装
环境准备很简单,一个虚拟环境 + 几条 pip 命令:
# 创建虚拟环境python3 -m venv ~/lm-harness-envsource ~/lm-harness-env/bin/activate# 安装核心框架pip install lm-eval# 装本地模型依赖pip install transformers torch accelerate装完验证一下:lm_eval --help,看到如下帮助信息就说明成功了。
3.2 最快验证:用 API 跑 10 道题
不需要下载模型,直接用 OpenAI API 试水(也可以用其他兼容 API):
export OPENAI_API_KEY="你的API密钥"lm_eval \ --model openai-completions \ --model_args model=gpt-4o-mini \ --tasks mmlu_anatomy \ --limit 10 \ --output_path ./results/gpt4o-mini这条命令做了三件事:1. 加载 gpt-4o-mini 模型2. 从 MMLU 解剖学子集抽 10 道题3. 模型答题、自动判卷、输出结果
十几秒后你会看到:
┌─────────────────┬──────────────────┐│ Task │ Metric │├─────────────────┼──────────────────┤│ mmlu_anatomy │ acc,none: 0.7000 │└─────────────────┴──────────────────┘意思是:10 道解剖学题,GPT-4o-mini 答对了 7 道,准确率 70%。
3.3 本地模型评测:以 Qwen2.5-0.5B 为例
API 模型要花钱,本地模型免费跑。用 Qwen2.5-0.5B-Instruct(只有 5 亿参数,下载快、适合练手):
lm_eval \ --model hf \ --model_args pretrained=Qwen/Qwen2.5-0.5B-Instruct,dtype=float16 \ --tasks hellaswag \ --limit 20 \ --batch_size 4 \ --output_path ./results/qwen0.5b-hellaswag框架会自动从 HuggingFace 下载模型,然后出题、答题、判卷。跑完看结果:
┌───────────┬─────────────────┐│ hellaswag │ acc_norm: 0.3000 ││ │ acc: 0.2500 │└───────────┴─────────────────┘acc_norm(归一化准确率)30% 是什么水平?
HellaSwag 是常识推理题,4 个选项随机猜的准确率是 25%。这个 0.5B 小模型只比随机猜高 5 个百分点,说明常识推理能力基本为零。这很正常——5 亿参数的模型本身就不具备复杂推理能力。
作为对比,70B 级别模型在 HellaSwag 上的 acc_norm 通常在 95% 左右,GPT-4 系列更是接近 96%。差距一目了然。
3.4 批量多任务评测
单看一个任务不够全面,通常一次跑 4-5 个核心任务:
lm_eval \ --model hf \ --model_args pretrained=Qwen/Qwen2.5-0.5B-Instruct,dtype=float16 \ --tasks hellaswag,arc_easy,piqa,winogrande \ --limit 20 \ --batch_size 4 \ --output_path ./results/qwen0.5b-batch输出结果:
┌────────────┬──────────────────┐│ hellaswag │ acc_norm: 0.3000 ││ arc_easy │ acc: 0.4500 ││ piqa │ acc_norm: 0.5500 ││ winogrande │ acc: 0.5000 │└────────────┴──────────────────┘这组数据能告诉我们:- 常识推理(HellaSwag):弱,接近随机- 基础科学问答(ARC-Easy):中等,45%- 物理常识(PIQA):稍好,55%- 代词消歧(WinoGrande):中等,50%
整体画像:这是一个"知识储备有限、推理能力偏弱"的小模型,适合对延迟敏感、对质量要求不高的场景(如简单的文本分类、关键词提取),不适合复杂问答或推理任务。
3.5 接入你自己的模型
如果你微调了一个模型,或者从其他框架训练了一个模型,只要它能以 HuggingFace 格式保存,就能直接评测:
lm_eval \ --model hf \ --model_args pretrained=/path/to/your/model,dtype=float16 \ --tasks hellaswag,arc_easy,gsm8k \ --output_path ./results/my-model也可以用 Ollama 部署的本地模型:
# 先启动 Ollama 服务ollama pull qwen2.5:7b# 评测lm_eval \ --model local-completions \ --model_args model=qwen2.5:7b,base_url=http://localhost:11434/v1/completions \ --tasks hellaswag \ --limit 20四、分数怎么看?一份"体检报告"解读指南
拿到评测分数后,很多人不知道该怎么解读。这里给一份参考标准。
4.1 核心任务分数段参考
以下分数基于 HuggingFace Open LLM Leaderboard 上的公开数据整理,反映不同参数量级模型的典型表现范围:
任务 | 随机基准 | 3B 模型典型范围 | 7B 模型典型范围 | 70B+ / GPT-4 级别 |
|---|---|---|---|---|
MMLU(知识广度,57 学科) | 25% | 55%-65% | 65%-75% | 80%-87% |
HellaSwag(常识推理) | 25% | 55%-65% | 70%-80% | 95%-96% |
ARC-Easy(基础科学) | 25% | 60%-70% | 75%-82% | 92%-95% |
GSM8K(小学数学) | ~0% | 30%-50% | 60%-75% | 90%-95% |
TruthfulQA(真实性) | ~30% | 35%-45% | 45%-55% | 60%-70% |
注:以上分数段来源于 HuggingFace Open LLM Leaderboard 公开数据及模型官方技术报告,为典型范围参考,具体模型可能有所浮动。
4.2 实测案例:从小模型到旗舰的跃迁
我们本地实测了 Qwen2.5-0.5B(2024 年发布的小模型),同时引用 Qwen 系列更大模型的公开 benchmark 数据做对比,看看参数量带来的能力变化:
模型 | 发布时间 | 参数量 | ARC | GSM8K | 代码/其他 |
|---|---|---|---|---|---|
Qwen2.5-0.5B | 2024.09 | 0.5B | ~45%(实测) | 0%(实测) | — |
Qwen2.5-7B | 2024.09 | 7B | 63.70% | 85.40% | MBPP 74.90% |
Qwen3-235B-A22B | 2025.04 | 235B(MoE) | — | — | AIME25 81.5, LiveCodeBench 70.7 |
Qwen3.5-Plus | 2026.02 | 3970B(MoE) | — | — | MMLU-Pro 87.8, GPQA 88.4 |
数据来源:Qwen2.5-0.5B 为本地实测;Qwen2.5-7B 来自 DataLearnerAI;Qwen3/Qwen3.5 来自官方技术报告及公开报道。注意不同代际模型使用的评测集可能不同(如 Qwen3.5 使用 MMLU-Pro 而非 MMLU),不宜直接横向对比。
从 0.5B 到 7B,参数增加了 14 倍,ARC 分数提升了约 19 个百分点,GSM8K 更是从"完全不会"跃升到 85% 以上。再到 Qwen3.5-Plus,在 MMLU-Pro 和 GPQA 等更难的评测集上达到 87+ 分,超越了 GPT-5.2 和 Claude 4.5。
这说明两件事:1. 参数量对能力的影响是非线性的——小模型完全做不了的事,中等模型就能做得不错2. 模型迭代速度极快——2024 年的"旗舰"7B 模型,到 2026 年已被新一代小模型超越
4.3 分数解读的注意事项
不要跨任务直接对比:MMLU 的 70% 和 HellaSwag 的 70% 不是一回事。MMLU 是 57 学科知识题,HellaSwag 是常识推理,难度基准不同。
不要跨代际直接对比:Qwen2.5 的 MMLU 分数和 Qwen3.5 的 MMLU-Pro 分数不能直接比较,因为评测集难度不同。
关注相对变化比绝对值更重要:如果你微调了一个模型,微调前 MMLU 65%,微调后 63%,掉了 2 个百分点——这个变化比"65% 算什么水平"更有价值。
注意评测集的"污染"问题:一些模型在训练时可能见过评测数据(尤其是开源评测集),导致分数虚高。这也是为什么 Leaderboard v2 换了一批新评测集的原因。
benchmark 有保质期:2024 年的高分模型,到 2026 年可能只是中等水平。评测数据要标注时间戳。
五、评测任务怎么选?不同场景有不同"体检套餐"
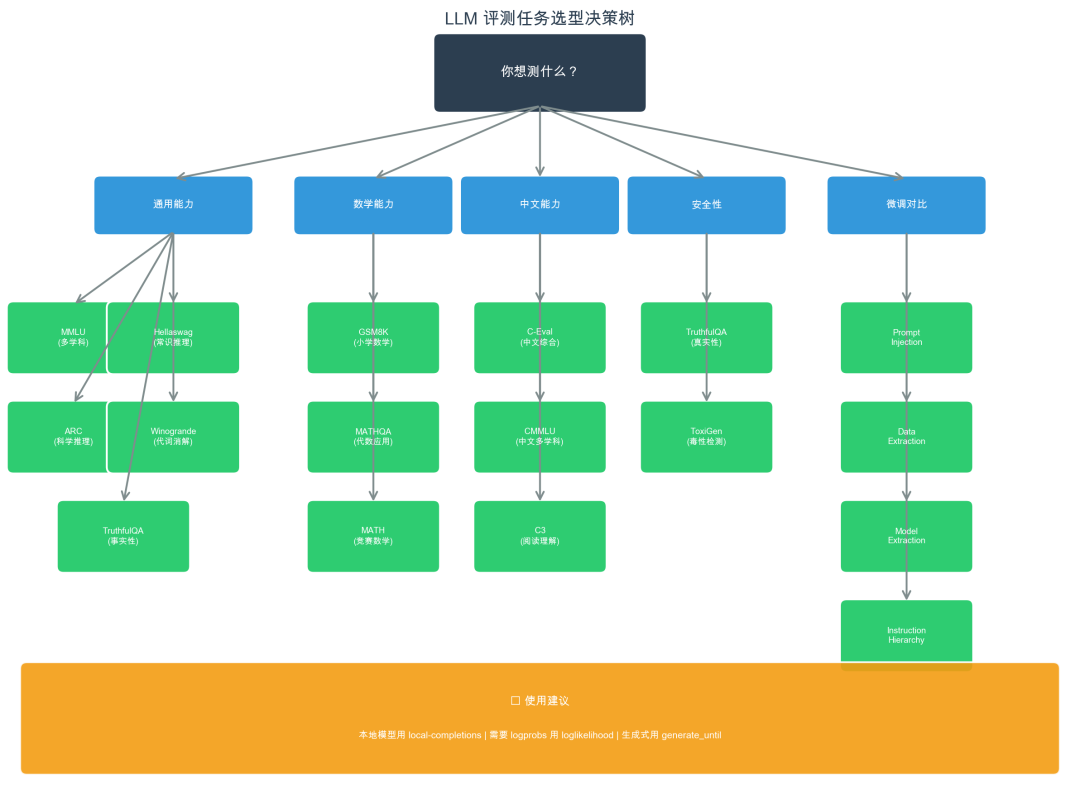
lm-eval 支持 200 多个任务,不可能全跑。选任务的核心原则是:你想测什么能力,就选对应的任务。
5.1 通用能力速览(最小集合)
如果你只想快速了解一个模型"大概什么水平",跑这 5 个任务就够了,20 分钟左右出结果:
任务 | 测什么 | 7B 模型参考分 |
|---|---|---|
HellaSwag | 常识推理 | 70%-80% |
ARC-Easy | 基础科学 | 75%-82% |
PIQA | 物理常识 | 75%-85% |
WinoGrande | 代词消歧 | 65%-75% |
MMLU | 知识广度 | 65%-75% |
--tasks hellaswag,arc_easy,piqa,winogrande,mmlu --limit 1005.2 数学推理专项
做教育类 AI、解题助手,必须测数学能力:
--tasks gsm8k,mathqa- GSM8K:小学数学应用题,测逐步推理能力
- MATHQA:代数题,测符号推理
5.3 中文能力专项
评测中文模型,不能只看英文任务。推荐组合:
--tasks ceval-valid,cmmlu,mmlu- C-Eval:中文多学科评测,13948 题覆盖 52 个学科,相当于中文版 MMLU
- CMMLU:中文大规模多任务理解
- MMLU:英文对照,看模型是否"偏科"(中文强了英文弱了)
5.4 安全与真实性
做面向 C 端的产品,安全不能忽视:
--tasks truthfulqa_mc2,toxigen- TruthfulQA:测模型是否会重复人类的常见错误认知(比如"闪电不会击中同一个地方两次"这种谣言)
- ToxiGen:测生成内容的有害性
5.5 微调前后对比
微调模型最怕"过拟合"——在训练数据上表现好了,通用能力崩了。对比评测的关键是选能检测"能力退化"的任务:
--tasks hellaswag,arc_challenge,gsm8k,truthfulqa_mc2 --limit 100- HellaSwag → 检测推理能力是否退化(微调后常降)
- ARC-Challenge → 检测知识保持
- GSM8K → 检测推理增强效果
- TruthfulQA → 检测安全偏移(微调后可能更"听话"但也更可能胡说)
对比方法:微调前跑一遍,微调后跑一遍,看分数变化。如果通用任务分数掉了超过 5%,说明微调有问题。
六、主流评测框架怎么选
lm-eval 不是唯一的评测工具,不同场景有更适合的选择。
6.1 三大框架对比
维度 | lm-eval-harness | OpenCompass | HELM |
|---|---|---|---|
开发者 | EleutherAI | 上海AI实验室 | Stanford CRFM |
开源协议 | MIT | Apache 2.0 | Apache 2.0 |
任务数 | 200+ | 100+ | 100+ |
中文支持 | ⚠️ 有限 | ✅ 强(原生中文) | ⚠️ 有限 |
安装复杂度 | ⭐ 低 | ⭐⭐ 中 | ⭐⭐⭐ 高 |
可视化 | ❌ 无 | ✅ 有 Web UI | ⚠️ 有限 |
社区活跃度 | 最高 | 中等 | 学术圈活跃 |
适合场景 | 快速评测/CI集成 | 中文模型/学术报告 | 学术研究/全面审计 |
6.2 怎么选
选 lm-eval-harness,如果你:- 想快速验证一个模型,5 分钟出结果- 需要集成到 CI/CD 流水线,每次代码提交自动跑评测- 要对比 HuggingFace Leaderboard 上的模型- 习惯命令行操作,不需要可视化界面
选 OpenCompass,如果你:- 评测中文模型(C-Eval、CMMLU 等中文任务原生支持)- 需要生成可视化报告(有 Web UI)- 做国产模型评测(Baichuan、ChatGLM、DeepSeek 等适配更好)- 需要主观评测(让 GPT-4 当裁判打分)
选 HELM,如果你:- 做学术研究,需要最全面的能力审计- 关注模型的安全性、公平性、偏见(不只是准确率)- 有足够的 API 预算(全面评测需要大量调用)- 需要生成标准化的学术报告
6.3 选框架决策树
评测目标是什么?│├─ 快速摸一个模型的底 → lm-eval-harness│ └─ 命令:pip install lm-eval && lm_eval --model hf --tasks hellaswag --limit 50│├─ 中文模型,要发论文/报告 → OpenCompass│ └─ https://github.com/open-compass/opencompass│├─ 全面学术审计(安全/公平/偏见) → HELM│ └─ https://github.com/stanford-crfm/helm│├─ 自动化 CI 集成,每次 PR 自动评测 → lm-eval-harness│ └─ 最易集成 GitHub Actions│└─ 多框架组合(严谨方案) ├─ 通用能力 → lm-eval-harness(英文)+ OpenCompass(中文) ├─ 代码能力 → BigCode Eval Harness ├─ 安全审计 → HELM └─ 对话质量 → MT-Bench / AlpacaEval6.4 实际组合方案
以一个完整的中文 LLM 评测 pipeline 为例:
# 阶段 1:快速通用能力(lm-eval-harness, ~30min)lm_eval --model hf --model_args pretrained=your-model \ --tasks hellaswag,arc_challenge,mmlu,gsm8k,truthfulqa_mc2 \ --limit 200 --output_path ./results/quick# 阶段 2:中文专项(OpenCompass, ~2h)python run.py --models your_model --datasets ceval cmmlu gsm8k \ --work-dir ./results/opencompass# 阶段 3:代码能力(BigCode Eval Harness, ~1h)accelerate launch main.py --tasks humaneval --model your-model \ --limit 164# 阶段 4:安全审计(HELM, ~3h, 可选)helm-run --run-entries "mmlu:model=your-model,truthfulqa:model=your-model"七、写在最后
模型评测不是"锦上添花",而是"底线工程"。
没有评测,你就是在黑暗中开车——可能开得很快,但不知道前面是不是悬崖。有了评测,你才有导航,才知道该加速还是该刹车。
lm-evaluation-harness 的价值,不只是帮你算出几个分数。它提供的是一套可量化、可复现、可对比的评测思维。这种思维,比任何具体工具都重要。
如果你刚开始接触模型评测,建议从 lm-eval 入手。装起来简单,跑起来直观,社区文档丰富。等你有更复杂的需求(中文专项、可视化报告、安全审计),再考虑 OpenCompass 或 HELM。
最后提醒:大模型迭代速度极快。本文引用的 benchmark 数据截至 2026 年 5 月,Qwen 系列已从 2.5 迭代到 3.5,DeepSeek 从 V3 迭代到 V3.2,Llama 从 3 迭代到 4。实际评测时,请以最新模型的官方数据为准,并在报告中标注评测时间。
参考资源
- lm-evaluation-harness GitHub:https://github.com/EleutherAI/lm-evaluation-harness
- OpenCompass:https://github.com/open-compass/opencompass
- HELM:https://github.com/stanford-crfm/helm
- BigCode Eval:https://github.com/bigcode-project/bigcode-evaluation-harness
- HuggingFace Open LLM Leaderboard:https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard
- DataLearnerAI 模型评测数据:https://www.datalearner.com/ai-models/pretrained-models/Qwen2_5-7B
- Qwen2.5 官方博客:https://qwenlm.github.io/blog/qwen2.5/
- Qwen3 官方博客:https://qwenlm.github.io/blog/qwen3/
- Qwen3.5-Plus 发布报道(腾讯网):https://new.qq.com/rain/a/20260216A05A9F00
往期内容:
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-11,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号