Karpathy的LLM Wik结合AI大模型+Obsidian工具的简单验证

Karpathy的LLM Wik结合AI大模型+Obsidian工具的简单验证

人月聊IT
发布于 2026-05-13 20:29:39
发布于 2026-05-13 20:29:39
大家好,我是人月聊IT。
今天继续聊下LLM Wiki个人AI智能知识库。在讲具体内容前,还是先总结下我的观点:即在当前AI时代个人知识管理,核心是要构建一套通过AI辅助实现从原始Raw资料库-》知识库的持续自我进化和升级之路。这里面的核心是如何去萃取和抽象知识元模型,也就是Wiki知识层,构建知识图谱,其次才是类似Obsidian等工具的使用。
其实我在前面一篇文章分享的时候,已经谈到了整体思路的一个落地架构方案,具体架构图参考如下:
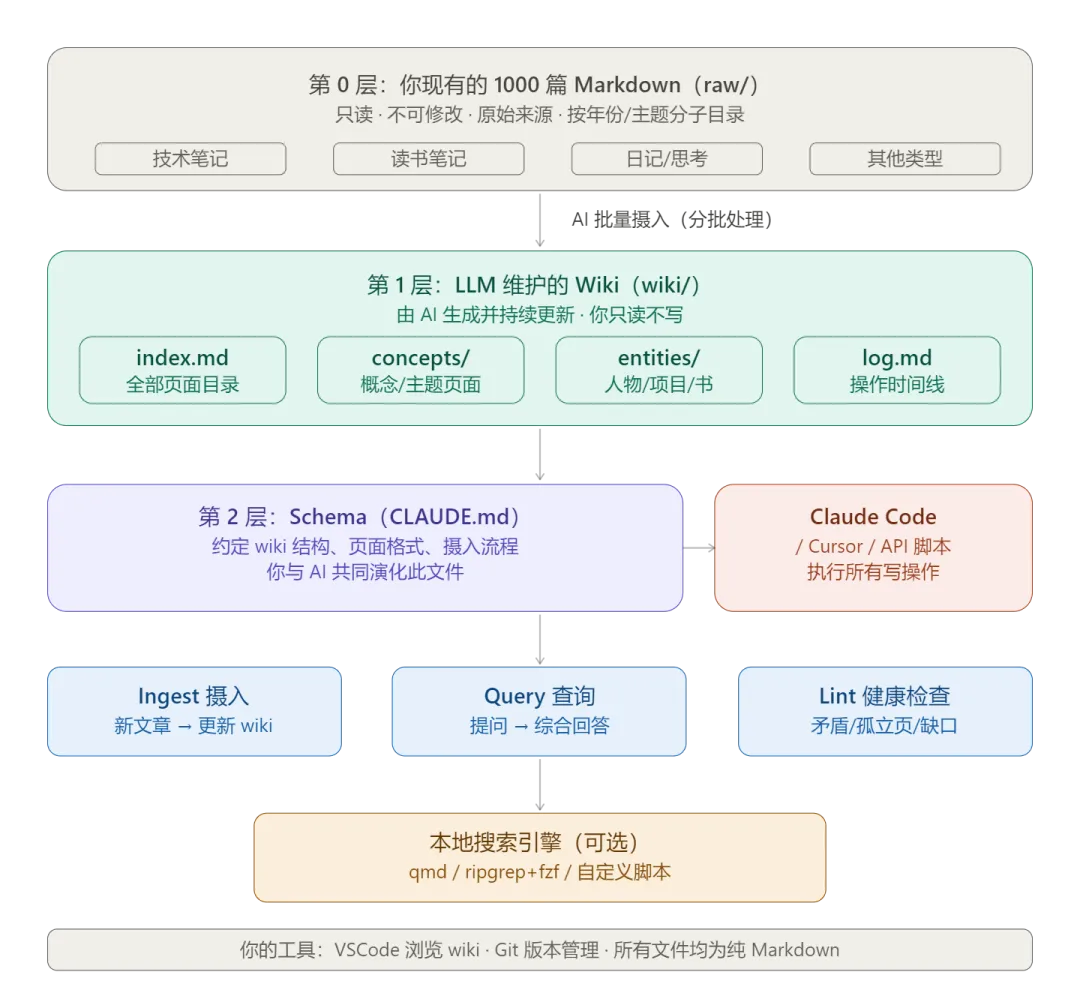
图片
当然,在这个之前,我还给出了一个基于我的历史文章,如何参考本体建模的思路来抽象知识元模型的一个参考实现思路,具体如下:
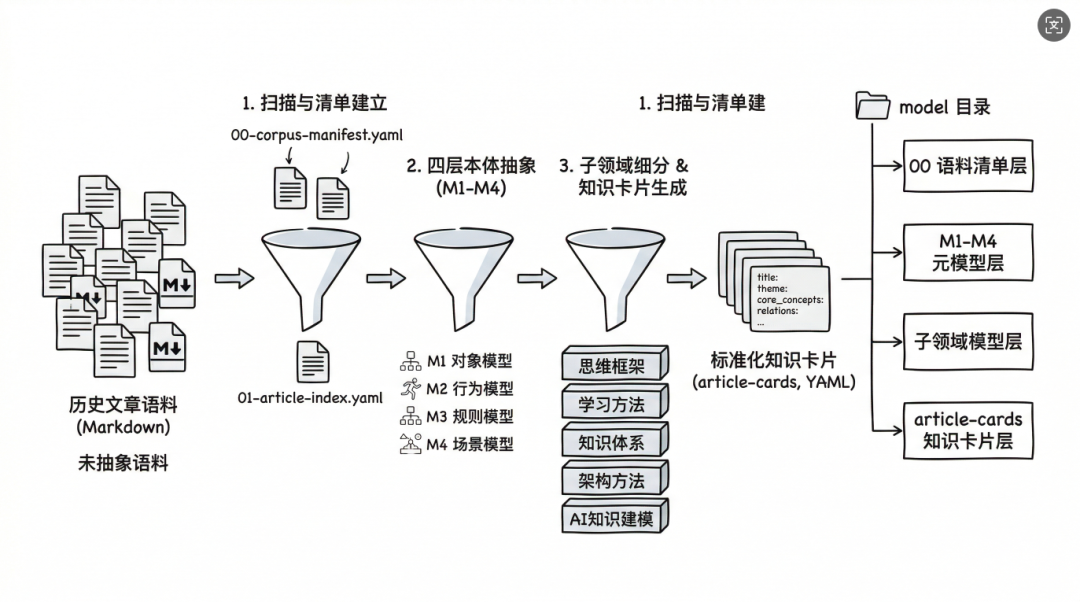
图片
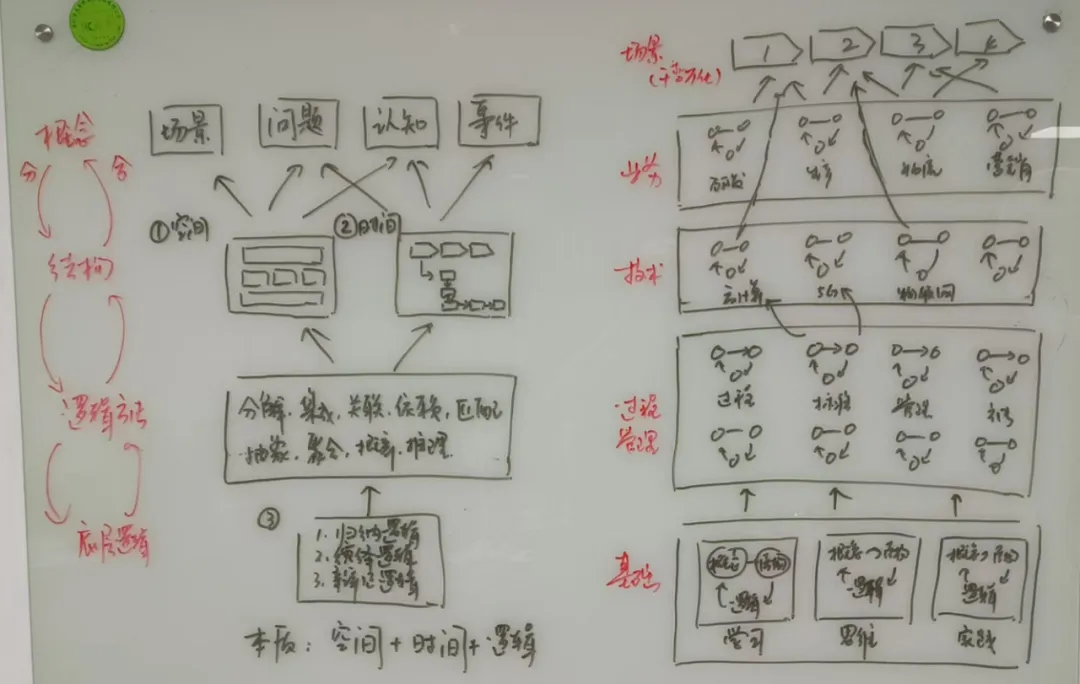
其实不论是哪种模式,核心思想都是需要对原始资料进行加工和萃取,基于一定的方法论和规则,来抽象核心的知识元模型。这个元模型在Karpathy的核心观点里面是概念,实体和关系。如果参考本体建模思路,我细化的元模型核心思路是场景-》方法论-》对象-》行为-》规则。
好了,言归正传,首先还是验证下参考Karpathy LLM Wiki的思路来对原始资料进行加工和知识萃取。
第1步骤仍然是需要准备好一个文件夹目录,先将我们的历史文章资料存放到Raw目录下面,作为AI大模型处理的基础。同时我们还需要提前规划好相应的Wiki目录和子文件夹,类似Concepts概念目录,Entity实体目录,Log日志目录等,具体可以根据自己需求进行子目录规划。
第2步骤是构建一段提示词,参考如下:
#Role: 资深LLM Wiki 大模型知识管理工程师
Context
源文件目录: ./raw/blog和/思维 目录 (包含知乎、公众号的markdown格式文章)
目标Wiki目录: ./wiki (存放加工后的结构化知识)
Goal
你将作为一个具备 Karpathy 第一性原理思维的架构专家,学习 llm-wiki-skill 的构建模式,将 ./raw 中的碎片化信息“炼金”为 ./wiki 中的系统化知识库。
References & Logic
Learn Methodology: 参考 https://github.com/lewislulu/llm-wiki-skill/tree/main/llm-wiki 的构建哲学,强调原子化、双链关联和清晰的层级。
Karpathy Style: 参考 https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f 的代码美学,要求 Wiki 内容:
核心公理化:剔除废话,只保留核心逻辑和本质定义。
模块化:每个 .md 文件只讲透一个原子知识点。
示例驱动:包含伪代码或架构示意(使用 Mermaid 语法)。
Workflow (Ultra-Think Mode)
扫描当前 ./raw/blog 目录下的所有文件。
深度思考:识别各素材间的语义关联,构建知识本体。
知识重构:
将原始材料解构,重新按“场景主题-》概念-》实体(关键词汇表)-》关系-》约束”的维度编写。抽象关键的知识点,并建立知识点间关联。
自动生成双链 [[文件名]],实现 Wiki 内部高度索引化。
文件输出:
更新 ./wiki/log.md:记录本次处理的时间、来源文件及变更摘要(作为审计追踪)。
更新 ./wiki/index.md:作为 Map of Content (MOC),动态更新知识树索引。
将生成的原子知识点 .md 文件存入 ./wiki 相应分类子目录。
Constraints
禁止生成重复的知识点。
所有输出必须符合 Obsidian Markdown 语法。
保持专业的技术口吻
Action
请立即开始扫描 源文件目录 并执行上述“炼金”流程。
第3步骤,我这里采用ClaudeCode+DeepSeekV4pro,对我个人历史文章参考上面的思路进行加工处理,提取相应的核心概念和实体。在大模型处理完成后,自动提取核心概念和实体,并针对每一个概念都构建了一篇笔记,如下:
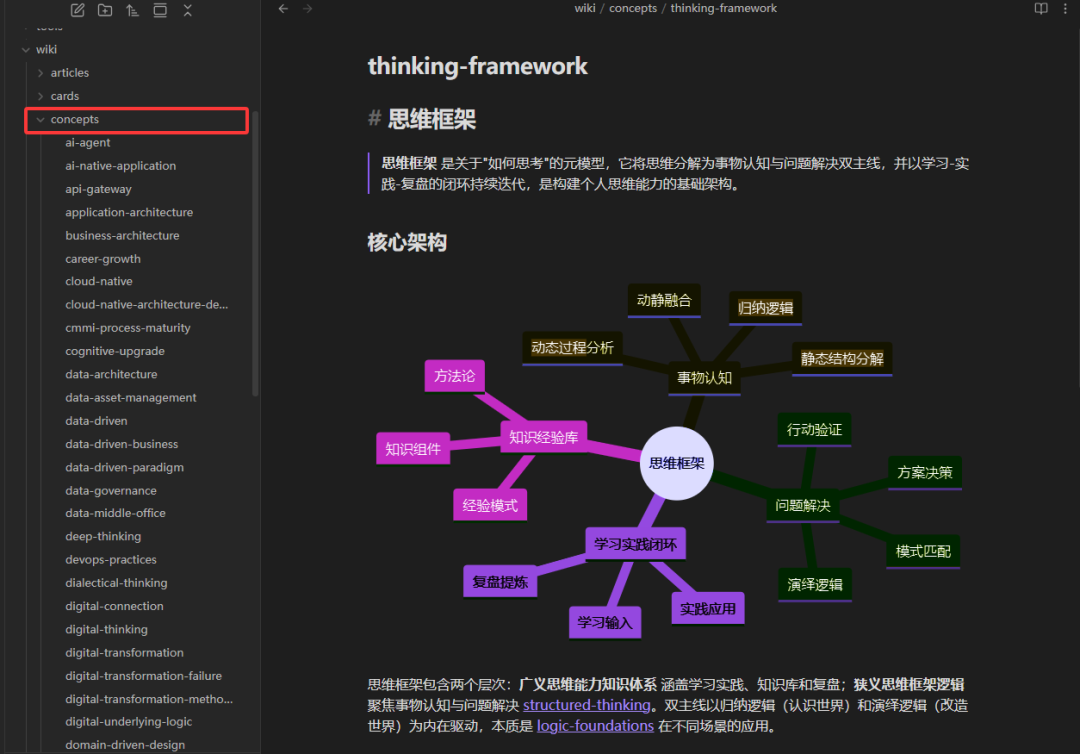
同时通过概念增加tag标签,增加双链笔记的方式构建了概念和原始文章的链接。简单来说就是并不是原始文章直接建立了链接,而是原始文章抽取出共性的概念和实体,通过这些概念实体间接的构建了原始文章资料之间的链接关系。

在按这个思路做完后,我和我前面知识元模型抽象思路做了下对比分析。里面有一个关键差异如下:
就是LLM-Wiki的思路是直接基于原始资料抽象核心的知识点,或者叫概念实体,然后构建知识关联。在我前面的方法里面实际进行了分层抽取。即将整个抽象过程分为了两个阶段处理。
阶段一是首先对历史文章进行归纳总结,基于每一篇历史文章我先构建一张高度归纳总结的知识卡片,这个知识卡片即包括了历史文章的归纳总结,又增加了相应的关键TAG标签的标注和相关其他历史文章的引用说明。具体参考如下:
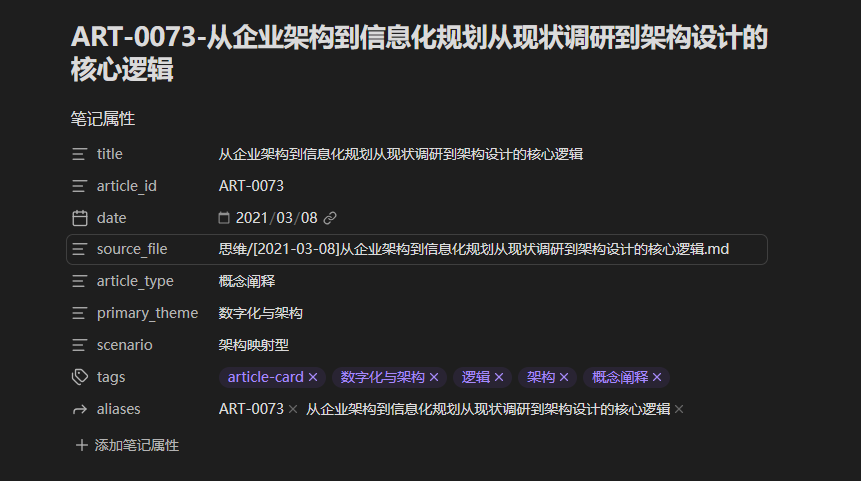

在这个步骤做完后,我们才会进入第2阶段。
即对知识卡片里面涉及到的共享主题概念进行单独抽取,针对每一个核心的概念实体构建一篇独立的笔记,这个可以理解为独立的可复用的知识点。最终形成主题概念的知识点卡片。
类似于思维这个概念会形成一个独立的知识点卡片。


为何要进行两层抽象和建模?
其核心观点就是:所有的文章都应该是最底层可复用的概念或主题的组装,而支撑概念主题的又是最底层的基础逻辑。在我们抽象知识元模型的时候,不应该是简单的抽取概念实体本身,而是应该构建一套如何基于可复用的知识组件,知识块去快速的构建新文章的方法论。这个才是后续能够灵活应用知识库的关键。(注:这里后续我们会进一步细化,即基于历史文章知识库,如何构建问题-》场景-》知识组件之间的灵活组装关系)
在上面内容做完后,我们就形成了完整的大模型Wiki知识库。我们可以看到可视化的知识图谱如下:
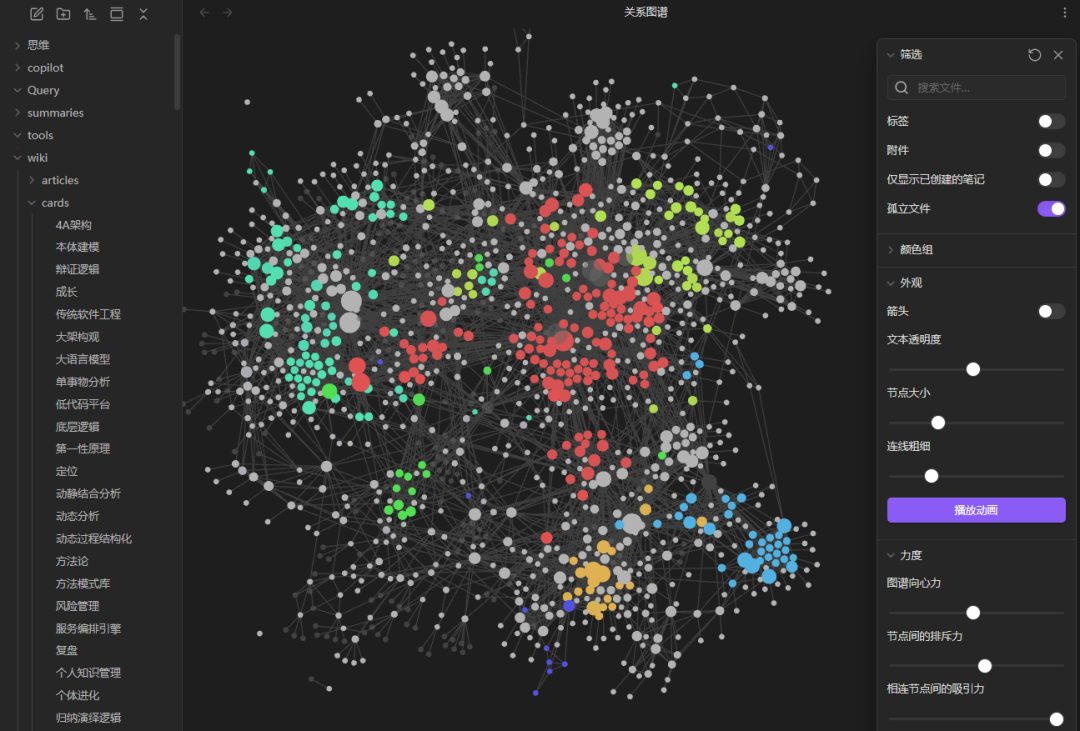
当然我们浏览单篇笔记文章的时候,也可以完整看到该文章相关的双向链接信息,实现关键知识点驱动的内容追溯。

也就是我们构建的知识库不再是离散的知识点,而是构建了一个完整的基于主题,概念驱动的知识图谱。
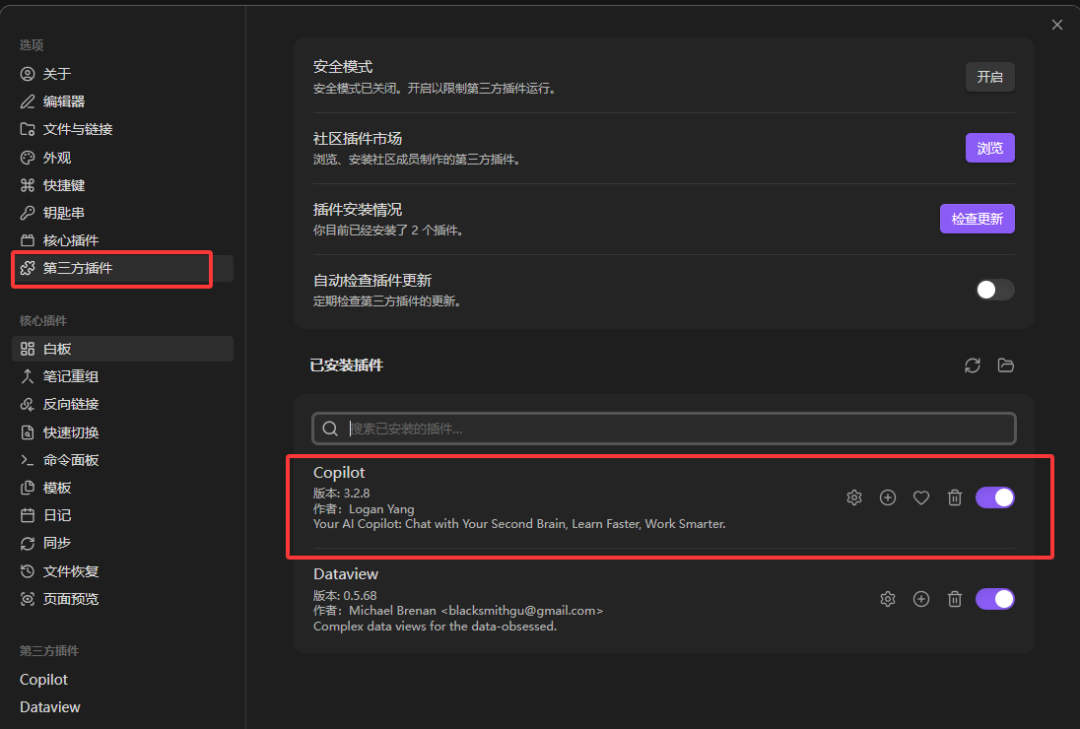
当然,我们还可以增加AI大模型插件,让该知识库具备和AI对话的能力。我们直接进入到Obsidian的第三方插件库,搜索Copilot插件。
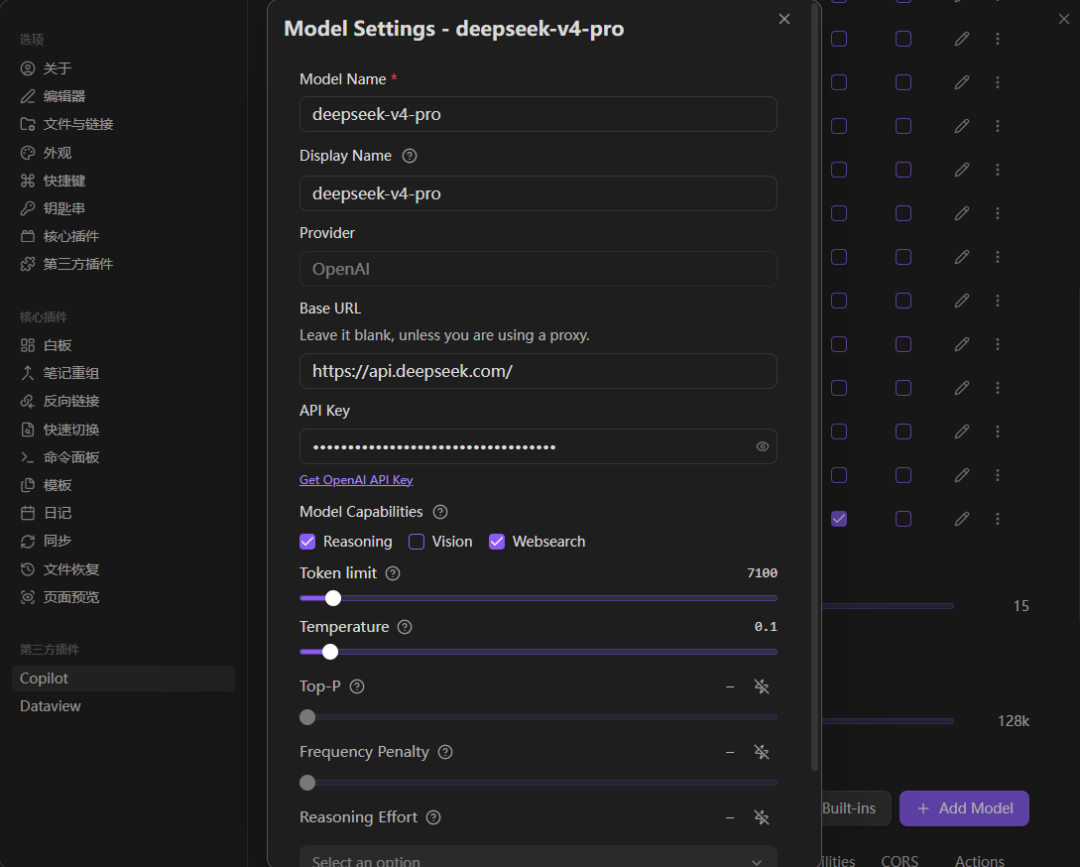
然后在Copilot插件里面增加DeepSeek V4模型和API配置。
这样我们整个知识库就变成了一个AI智能知识库。可以基于知识库进行问答和对话。比如对单篇笔记内容进行学习和归纳总结。
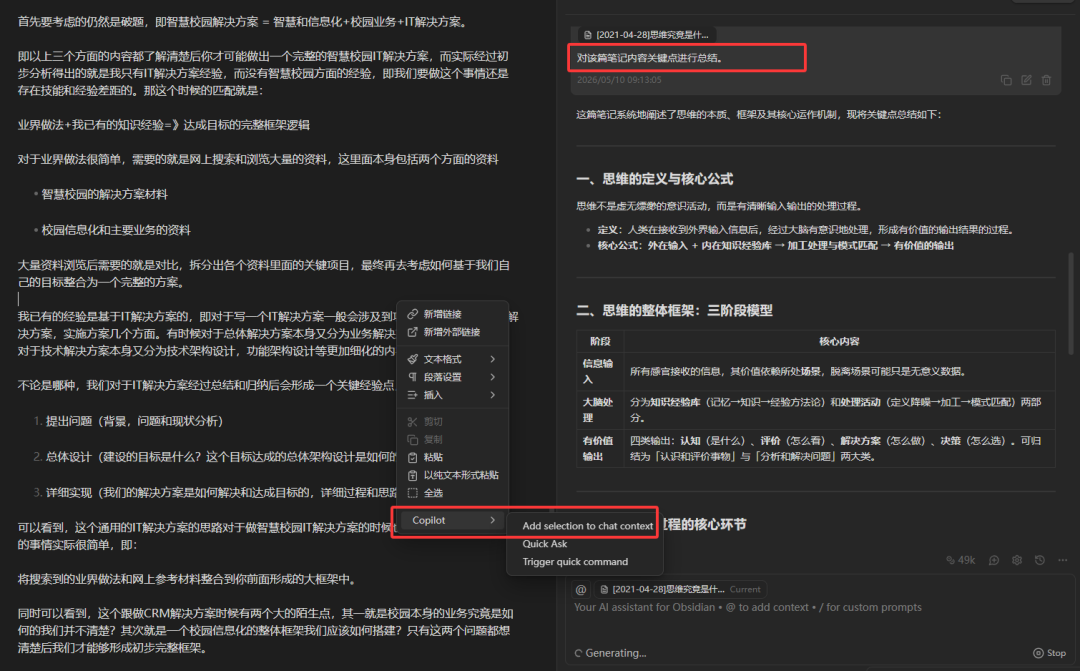
比如我们可以直接为知识库一个问题,如个人知识体系如何建立和实践?对于该问题具体回答如下:
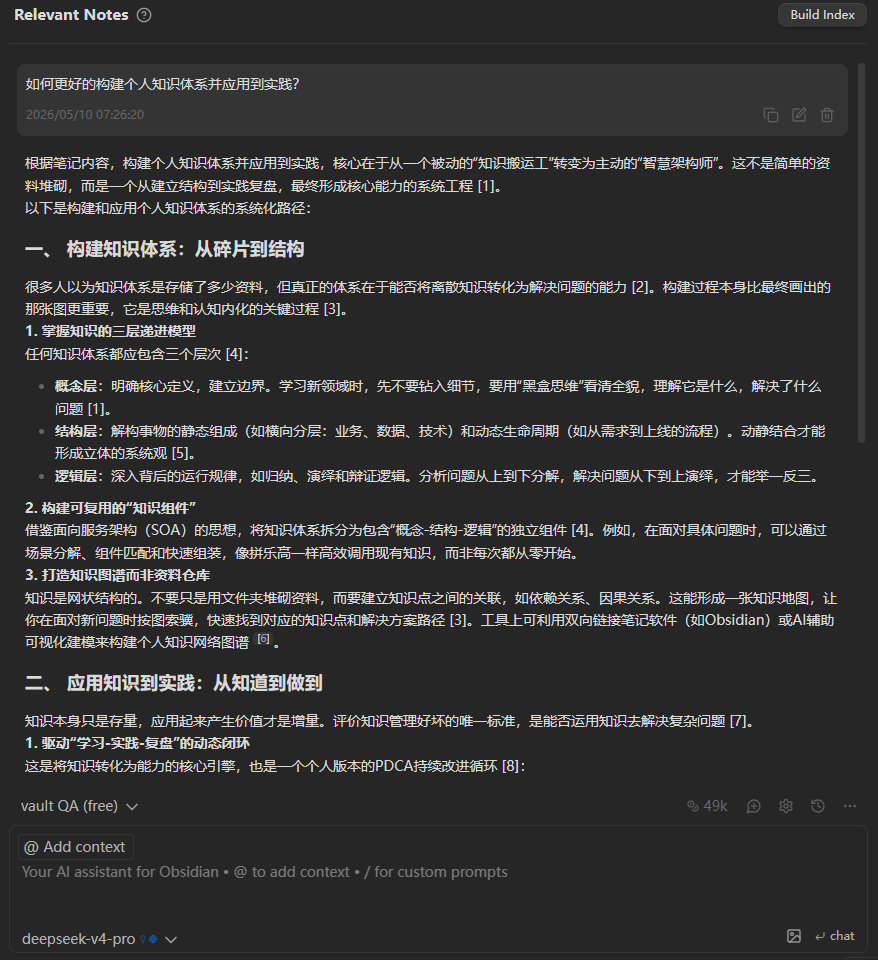
注意,实际每次你和Copilot对话的内容,都会在Copilot目录下面生成一篇新的笔记内容。
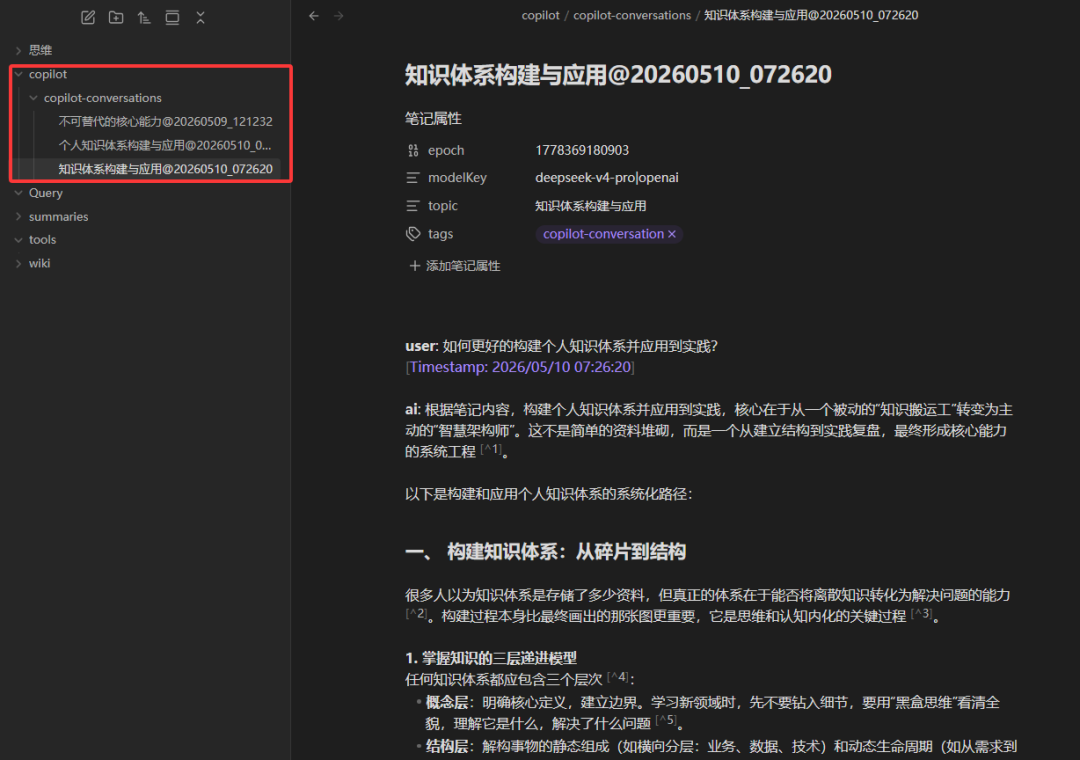
从整个对话和回答的质量来看,整体还是相当不错。当然是否需要在智能回答的时候通过提示词强制指定优先扫描Wiki知识库,然后再钻取到Raw目录下的详细历史文章,这点当前还不确定。大家也可以自己验证下。
今天关于LLM-Wiki的简单验证就到这里,后续文章将进一步细化我前面谈到的场景驱动的知识块组装思路。我在前面专门发过一篇关于知识组装的思路文章,大家也可以先参考。
具体文章如下:构建知识组件和知识组装
图片
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-11,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号