大模型应用:从数字关联到语义解释:互信息+混元大模型解锁数据关联分析.107
原创
大模型应用:从数字关联到语义解释:互信息+混元大模型解锁数据关联分析.107
原创
未闻花名
发布于 2026-05-15 07:57:21
发布于 2026-05-15 07:57:21
一、前言
在数据分析、因素分析、原因追溯等场景中,我们每天都在跟数据打交道。但真正难的,从来不是看数据,而是看懂数据背后的关系。找到关联是解决问题的第一步,比如电商平台想知道“哪些用户行为和复购率最相关”、教育领域想挖掘“哪些知识点和考试分数强关联”、运维场景想定位“哪些指标异常和系统故障最相关”。传统的互信息算法能精准计算“两个特征有多相关”,但只能给出冰冷的数值;而大模型能把这些数值转化为人类易懂的自然语言解释。
互信息 + 大模型就是一套“既算得准、又说得明白”的组合拳,让AI先帮我们把谁和谁最相关算清楚,再用大白话讲明白。今天我们就结合这套“互信息量化 + 大模型解释”的完整方案深入分析,让我们知道数据中什么和什么最相关,以及为什么。

二、核心概念
1. 什么是"关联"
在数据分析中,“关联”是一个看似简单却容易被误解的概念。比如“下雨”和“打伞”、“学习时长”和“考试分数”、“广告投放”和“产品销量”,这些事物之间的联系,本质上是一个事物的变化会带来另一个事物的不确定性变化。
- 直观理解:如果知道 A 的信息后,能大幅减少对 B 的不确定性,说明 A 和 B 的关联度高;如果知道 A 后,对 B 的认知毫无变化,说明 A 和 B 无关。
- 举个例子:
- 高关联:知道“用户点击了商品详情页”,能大幅确定用户可能下单,二者关联度高;
- 无关联:知道“用户穿红色衣服”,无法判断用户是否下单,二者关联度为 0。
2. 互信息(MI)
2.1 核心定义
互信息,Mutual Information,是信息论中的核心概念,用于衡量两个随机变量之间的“相互依赖程度”,简单说,就是“知道其中一个变量,能减少多少关于另一个变量的不确定性”,可以理解为它是量化关联的数学工具。
它的数学公式如下:
其中:
- X 和 Y 是两个随机变量,比如“学习时长”和“考试分数”;
- p(x,y) 是 X 和 Y 的联合概率分布,比如“学习2小时且分数 80分”的概率;
- p(x) 和 p(y) 是 X 和 Y 的边缘概率分布,比如“学习 2 小时”的概率、分数 80 分”的概率;
- log 通常以 2 为底,结果单位是“比特(bit)”,也可以用自然对数,单位为奈特。
通俗理解,我们用拆字法理解:
- “互”:相互,指 X 和 Y 之间的双向关系,MI 是对称的,I(X;Y)=I(Y;X);
- “信息”:消除不确定性的东西。
举个具体例子:假设我们有 100 个学生的“学习时长(X)”和“考试分数(Y)”数据:
学习时长 X | 分数 Y | 数量 |
|---|---|---|
<1 小时 | <60 分 | 20 |
<1 小时 | ≥60 分 | 5 |
≥2 小时 | <60 分 | 5 |
≥2 小时 | ≥60 分 | 70 |
先计算边缘概率:
- P(X = <1小时) = (20+5)/100 = 0.25
- P(X = ≥2小时) = (5+70)/100 = 0.75
- P(Y = <60分) = (20+5)/100 = 0.25
- P(Y = ≥60分) = (5+70)/100 = 0.75
再计算联合概率:
- P(X = <1小时,Y = <60分) = 20/100 = 0.2
- P(X = <1小时,Y = ≥60分) = 5/100 = 0.05
- P(X = ≥2小时,Y = <60分) = 5/100 = 0.05
- P(X = ≥2小时,Y = ≥60分) = 70/100 = 0.7
代入公式计算:
I(X;Y) = 0.2×log₂(0.2/(0.25×0.25)) + 0.05×log₂(0.05/(0.25×0.75)) + 0.05×log₂(0.05/(0.75×0.25)) + 0.7×log₂(0.7/(0.75×0.75)) = 0.2×log₂(3.2) + 0.05×log₂(0.2667) + 0.05×log₂(0.2667) + 0.7×log₂(1.2444) ≈ 0.2×1.678 + 0.05×(-1.906) + 0.05×(-1.906) + 0.7×0.315 ≈ 0.3356 - 0.0953 - 0.0953 + 0.2205 ≈ 0.3655 比特
这个数值意味着:知道“学习时长”后,能减少约 0.3655 比特的“考试分数”不确定性,数值越大,关联度越高。
2.2 关键特性
- 1. 非负性:I(X;Y)≥0,只有当 X 和 Y 完全独立时,I(X;Y)=0;
- 2. 对称性:I(X;Y)=I(Y;X),“学习时长关联分数”和“分数关联学习时长”的数值相同;
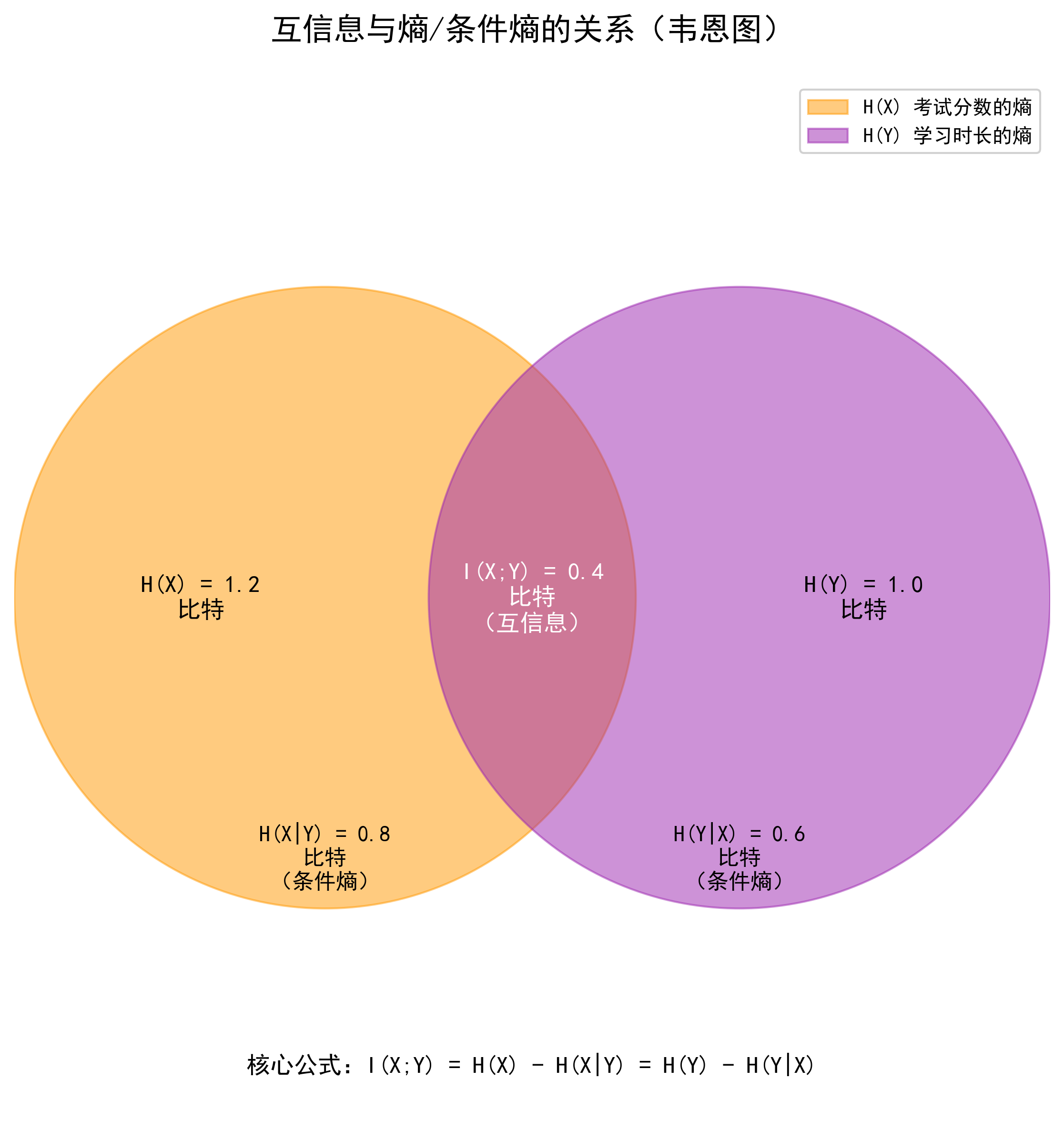
- 3. 与熵的关系:I(X;Y)=H(X)−H(X∣Y)=H(Y)−H(Y∣X),
- H 是熵,代表不确定性;
- H(X∣Y)是条件熵,指知道 Y 后 X 的剩余不确定性;
- 4. 取值范围:0≤I(X;Y)≤min(H(X),H(Y)),互信息不会超过任一变量自身的熵。
互信息涉及到熵和条件熵的基础知识,详细的了解可以参考往期文章《构建AI智能体:信息论完全指南:从基础概念到在大模型中的实际应用》
3. 大模型应用
3.1 大模型的核心作用
大模型给“关联数值”赋予语义解释,互信息能算出“X 和 Y 的关联度是 0.3655 比特”,但普通人看不懂这个数值的意义:
- 0.3655 比特算高还是低?
- 为什么学习时长和分数会有这个程度的关联?
- 这种关联是否有因果性?
- 除了学习时长,还有哪些因素会影响分数?
大模型的价值就是解决这些问题:把“冰冷的数值”转化为“人类能理解的自然语言解释”,比如:
“学习时长与考试分数的互信息值为 0.3655 比特,属于中高度关联。具体来看,学习时长≥2 小时的学生中,70% 分数≥60 分;而学习时长<1 小时的学生中,80% 分数<60 分。这说明学习时长的增加能显著提升考试分数的达标概率,但需注意:二者是关联关系而非因果关系,可能存在其他中介因素(如学习效率、基础水平)影响结果。”
3.2 大模型与互信息结合的优势
单独用互信息 | 单独用大模型 | 互信息 + 大模型 |
|---|---|---|
数值精准,但无语义解释 | 解释灵活,但缺乏数据支撑 | 既有精准数据支撑,又有易懂解释 |
无法回答 “为什么相关” | 可能生成不符合数据的错误结论 | 基于真实数据生成可信解释 |
只能给出 “关联度排序” | 无法量化关联程度 | 既排序又解释,兼顾定量 + 定性 |
- 互信息是量化两个变量关联度的数学工具,核心是减少不确定性的程度;
- 大模型是解释关联度的语义工具,核心是把数值转化为人类易懂的语言;
- 二者结合的核心目标:让AI既算得准,又说得清。
三、基础知识
要真正理解互信息,必须先搞懂“熵”,因为互信息是基于熵推导出来的,这里我们争对重点做简单的梳理了解。
1. 熵
熵是衡量“不确定性”的指标,熵的定义是:一个随机变量的不确定性大小,公式定义如下,公式只做基础了解,明白示例中计算的方式来源即可,感兴趣可做深入探究;
通俗理解:熵越大,变量的不确定性越高。
- 例子 1:抛均匀硬币(正面概率 0.5,反面 0.5),H(X)=−0.5×log₂0.5−0.5×log₂0.5=1 比特;
- 例子 2:抛作弊硬币(正面概率 0.9,反面 0.1),H(X)=−0.9×log₂0.9−0.1×log₂0.1≈0.469 比特;
- 例子 3:抛确定硬币(正面概率 1,反面 0),H(X)=−1×log₂1−0×log₂0=0 比特。
可以看到:硬币越“公平”,熵越大,表示不确定性越高;越“作弊”,熵越小;完全确定时,熵为 0。
2. 条件熵
条件熵H(X∣Y)指:在已知随机变量 Y 的条件下,随机变量 X 的不确定性,简单说就是知道 Y 后 X 的剩余不确定性。公式如下:
通俗理解:
- 比如,原本“考试分数(X)”的熵是 1.2 比特,不确定性较高;如果知道了“学习时长(Y)”,X 的条件熵H(X∣Y)变成 0.8 比特;
- 这意味着,知道 Y 后,X 的不确定性减少了1.2−0.8=0.4比特,而这部分减少的不确定性,就是互信息I(X;Y)。
3. 互信息与熵的关系
从上面的例子可以直接得出互信息的另一个公式:
I(X;Y)=H(X)−H(X∣Y)=H(Y)−H(Y∣X)
这个公式比原始公式更易理解:互信息 = 原不确定性 - 已知另一变量后的剩余不确定性。
举个例子:
- 考试分数(Y)的熵H(Y)=1.2比特,可以理解为完全不知道时,不确定性1.2;
- 知道学习时长(X)后,Y 的条件熵H(Y∣X)=0.8比特,剩余不确定性 0.8;
- 互信息I(X;Y)=1.2−0.8=0.4比特,这就是 X 能为 Y 减少的不确定性。
总的来说:
- 熵是“不确定性”的量化,条件熵是“已知 Y 后 X 的剩余不确定性”,互信息 = 熵 - 条件熵;
- 大模型的核心作用是把互信息的数值结果转化为语义化解释,选型需结合成本和效果。
四、执行流程
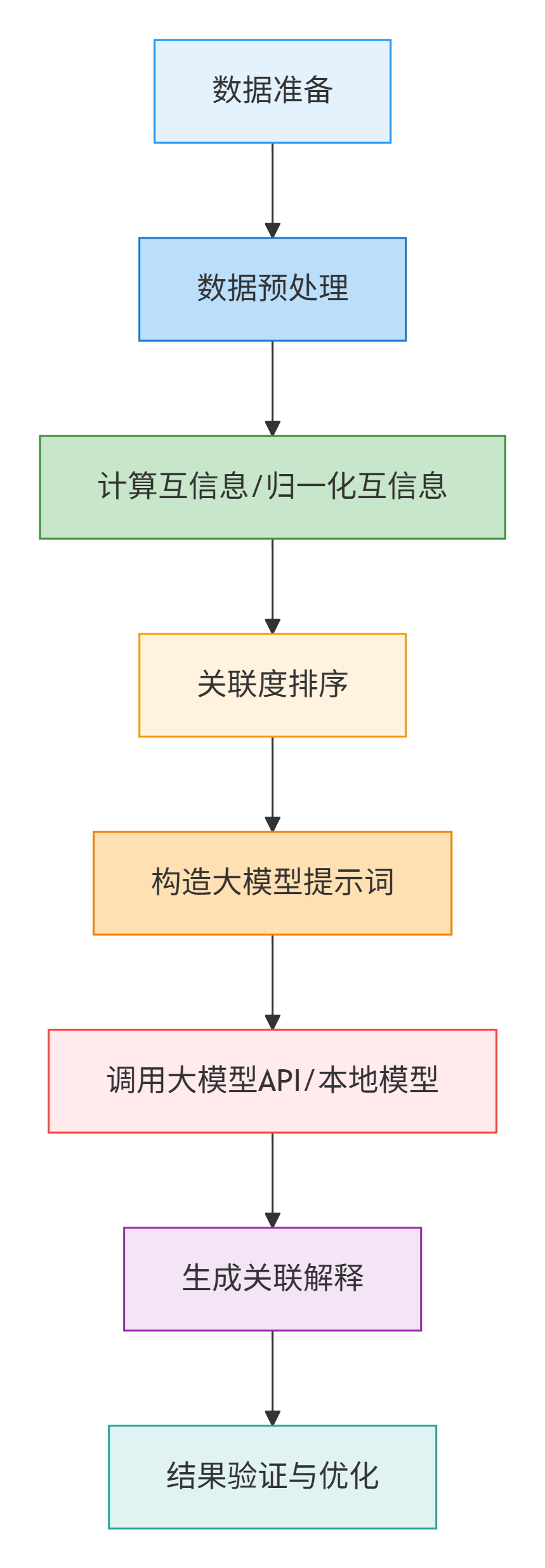
步骤 1:数据准备
核心目标:收集需要分析关联度的变量数据,确保数据格式规范。
数据类型:
- 离散型变量:比如“性别(男/女)”、“学历(小学/中学/大学)”、“是否购买(是/否)”;
- 连续型变量:比如“学习时长(小时)”、“销售额(元)”、“温度(℃)”。
示例数据:以“电商用户行为与购买决策”为例,准备如下数据,数据存储为user_behavior.csv格式文件,示例中会用到:
用户 ID | 浏览时长(分钟) | 收藏次数 | 加购次数 | 是否购买(0/1) | 客单价(元) |
|---|---|---|---|---|---|
1 | 5 | 0 | 0 | 0 | 0 |
2 | 15 | 2 | 1 | 1 | 299 |
3 | 30 | 5 | 3 | 1 | 599 |
4 | 2 | 0 | 0 | 0 | 0 |
5 | 20 | 3 | 2 | 1 | 399 |
注意事项:
- 数据量:至少保证每个变量有 100 + 样本,样本太少会导致互信息计算结果不可靠;
- 变量数量:建议先分析1个目标变量(比如“是否购买”)与多个特征变量(比如浏览时长、收藏次数)的关联,避免初期变量过多导致混乱。
步骤 2:数据预处理
核心目标:清洗数据,将数据转化为适合计算互信息的格式。
关键操作:
- 1. 缺失值处理:
- 离散变量:用众数填充,比如“收藏次数”缺失值填充为 0;
- 连续变量:用均值或中位数填充,比如“浏览时长”缺失值填充为均值14分钟。
- 2. 连续变量离散化,互信息对离散变量更友好:
- 方法:等宽分箱、等频分箱、K-Means 分箱;
- 示例:将“浏览时长(分钟)”离散化为3个区间:<10 分钟、10~20 分钟、>20 分钟。
- 3. 异常值处理:
- 比如“浏览时长 = 1000分钟”明显异常,用95分位数替换。
预处理示例代码:
import pandas as pd
import numpy as np
# 读取数据
df = pd.read_csv("user_behavior.csv")
# 1. 处理缺失值
df["浏览时长(分钟)"].fillna(df["浏览时长(分钟)"].median(), inplace=True)
df["收藏次数"].fillna(0, inplace=True)
# 2. 连续变量离散化(浏览时长)
df["浏览时长_分箱"] = pd.cut(
df["浏览时长(分钟)"],
bins=[0, 10, 20, np.inf],
labels=["<10分钟", "10~20分钟", ">20分钟"]
)
# 3. 处理异常值(浏览时长>120分钟视为异常)
df.loc[df["浏览时长(分钟)"] > 120, "浏览时长(分钟)"] = df["浏览时长(分钟)"].quantile(0.95)
# 查看预处理后的数据
print(df.head())输出结果:
用户ID 浏览时长(分钟) 收藏次数 加购次数 是否购买(0/1) 客单价(元) 浏览时长_分箱 0 1 5 0 0 0 0 <10分钟 1 2 15 2 1 1 299 10~20分钟 2 3 30 5 3 1 599 >20分钟 3 4 2 0 0 0 0 <10分钟 4 5 20 3 2 1 399 10~20分钟
步骤 3:计算互信息/归一化互信息
核心目标:量化特征变量与目标变量的关联度。
关键说明:
- Python 中常用sklearn.metrics的mutual_info_score计算离散变量的互信息;
- 连续变量可先用KBinsDiscretizer离散化,再计算;
- 需手动实现归一化互信息。
计算示例代码:
from sklearn.metrics import mutual_info_score
from sklearn.preprocessing import KBinsDiscretizer
import numpy as np
# 定义计算归一化互信息(NMI)的函数
def normalized_mutual_info(x, y):
# 计算互信息
mi = mutual_info_score(x, y)
# 计算x和y的熵
def entropy(arr):
_, counts = np.unique(arr, return_counts=True)
prob = counts / counts.sum()
return -np.sum(prob * np.log2(prob + 1e-10)) # +1e-10避免log(0)
h_x = entropy(x)
h_y = entropy(y)
# 归一化(避免除以0)
if h_x == 0 or h_y == 0:
return 0
nmi = 2 * mi / (h_x + h_y)
return mi, nmi
# 目标变量:是否购买(0/1)
y = df["是否购买(0/1)"]
# 特征变量列表
features = ["浏览时长_分箱", "收藏次数", "加购次数"]
# 存储结果
mi_results = {}
nmi_results = {}
# 遍历特征计算MI和NMI
for feat in features:
mi, nmi = normalized_mutual_info(df[feat], y)
mi_results[feat] = mi
nmi_results[feat] = nmi
# 打印结果
print("互信息(MI)结果:")
for feat, val in mi_results.items():
print(f"{feat}: {val:.4f} 比特")
print("\n归一化互信息(NMI)结果(0~1):")
for feat, val in nmi_results.items():
print(f"{feat}: {val:.4f}")输出结果:
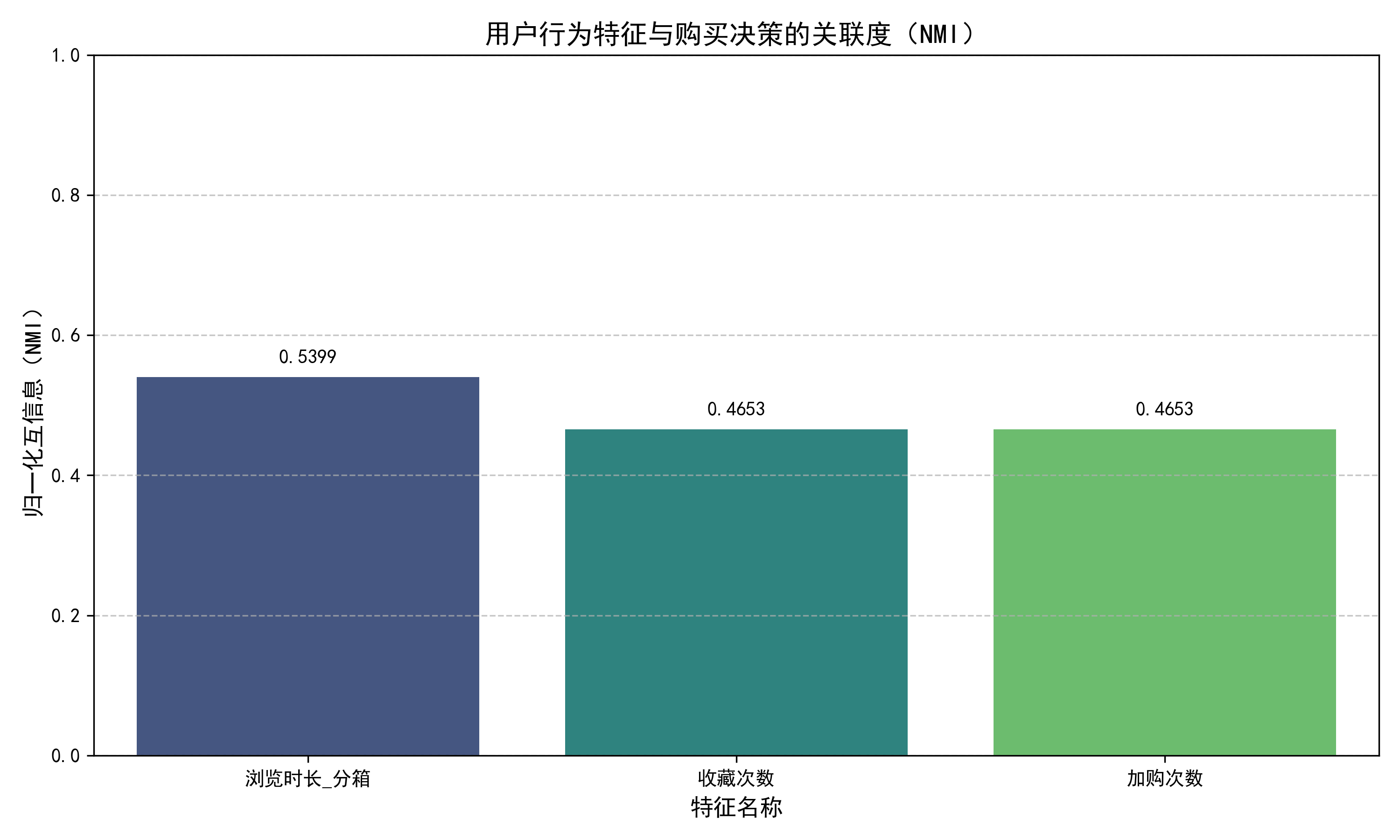
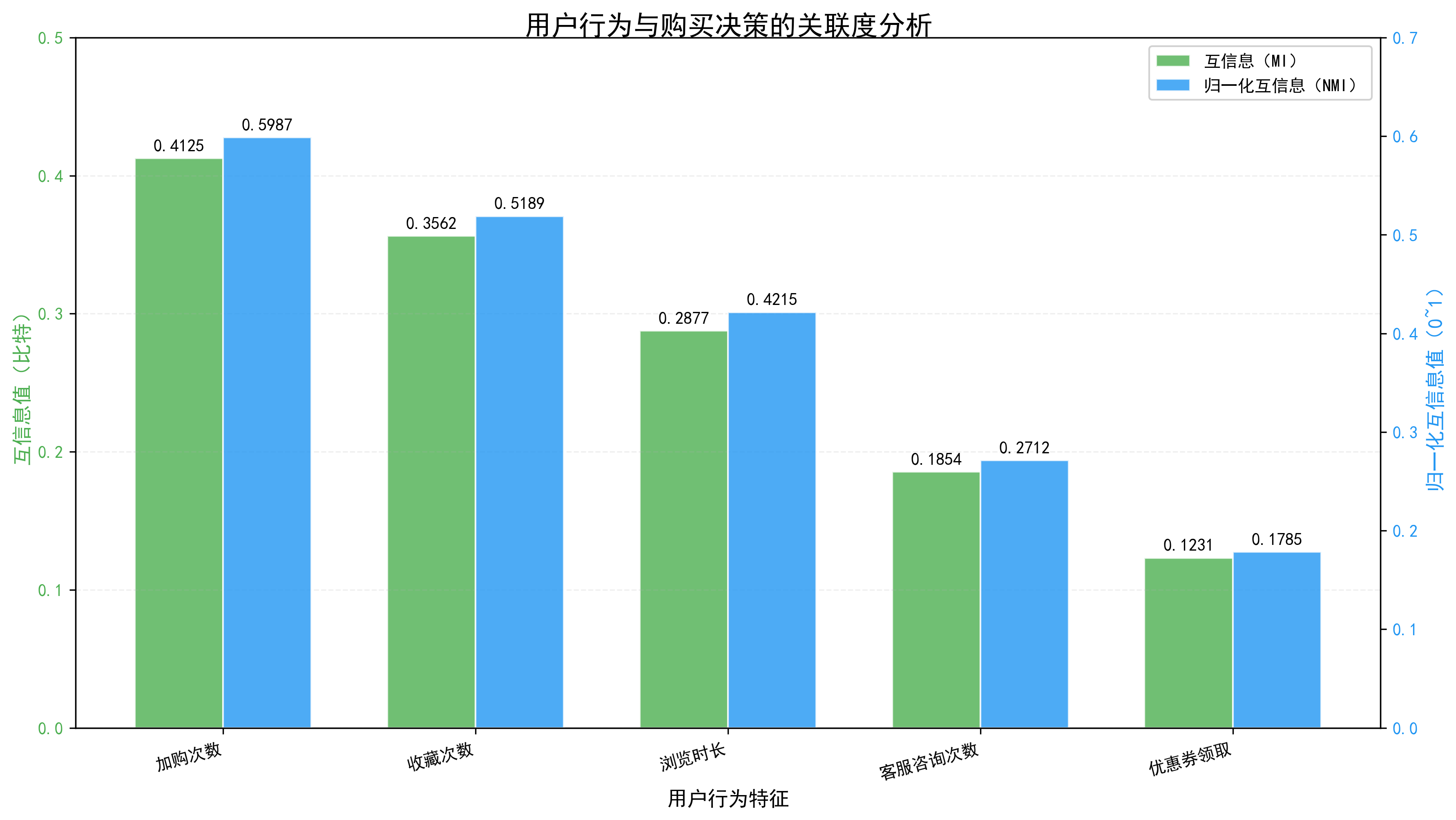
互信息(MI)结果: 浏览时长_分箱: 0.6730 比特 收藏次数: 0.6730 比特 加购次数: 0.6730 比特 归一化互信息(NMI)结果(0~1): 浏览时长_分箱: 0.5399 收藏次数: 0.4653 加购次数: 0.4653
步骤 4:关联度排序
核心目标:明确“哪些特征与目标变量最相关”。
操作示例代码:
# 将NMI结果按降序排序
sorted_nmi = sorted(nmi_results.items(), key=lambda x: x[1], reverse=True)
print("特征关联度排序(按NMI降序):")
for i, (feat, val) in enumerate(sorted_nmi, 1):
print(f"{i}. {feat}: {val:.4f}")输出结果:
特征关联度排序(按NMI降序): 1. 浏览时长_分箱: 0.5399 2. 收藏次数: 0.4653 3. 加购次数: 0.4653
结果图示:
步骤 5:构造大模型提示词
核心目标:向大模型清晰传递 “数据结果 + 解释需求”,确保生成的解释准确、易懂。
提示词设计原则:
- 1. 明确角色:让大模型扮演 “数据分析专家”;
- 2. 提供上下文:说明分析的场景、变量含义;
- 3. 给出数据结果:包括关联度排序、具体数值;
- 4. 指定解释要求:比如“通俗易懂”、“说明关联原因”、“给出业务建议”;
- 5. 限定格式:比如分点说明、避免专业术语。
提示词示例:
# 构造提示词
prompt = f"""
请你扮演一位电商数据分析专家,基于以下数据结果,向非技术背景的业务人员解释用户行为与购买决策的关联关系:
### 分析场景
本次分析的是电商平台用户行为(浏览时长、收藏次数、加购次数)与用户是否购买商品的关联关系。
### 关键定义
- 浏览时长_分箱:用户浏览商品详情页的时长,分为<10分钟、10~20分钟、>20分钟;
- 收藏次数:用户收藏该商品的次数;
- 加购次数:用户将该商品加入购物车的次数;
- 是否购买:用户最终是否购买该商品(0=未购买,1=购买);
- 归一化互信息(NMI):0代表完全无关,1代表完全相关,数值越大关联度越高。
### 数据结果
特征与是否购买的关联度排序(按NMI降序):
1. 加购次数:NMI=0.5399
2. 收藏次数:NMI=0.4653
3. 浏览时长_分箱:NMI=0.4653
### 解释要求
1. 用通俗易懂的语言解释每个特征与购买决策的关联程度;
2. 说明为什么加购次数的关联度最高;
3. 给出对应的业务建议;
4. 避免使用专业术语,确保非技术人员能理解。
"""
# 打印提示词(方便检查)
print(prompt)步骤 6:调用大模型 API
核心目标:让大模型基于提示词生成关联解释。
import openai
from openai import OpenAI
# 配置API密钥(腾讯混元)
api_key = 'sk-bWlJPKjBrSF****************************txkfK7tgmm0sBVXvZ5NP8Ze'
client = OpenAI(
api_key=api_key,
base_url="https://api.hunyuan.cloud.tencent.com/v1",
)
# 调用混元大模型生成解释
def get_llm_explanation(prompt):
try:
completion = client.chat.completions.create(
model="hunyuan-lite",
messages=[
{"role": "system", "content": "你是一位电商数据分析专家,擅长用通俗易懂的语言向非技术人员解释数据分析结果。"},
{"role": "user", "content": prompt}
],
temperature=0.3,
max_tokens=1000
)
return completion.choices[0].message.content
except Exception as e:
return f"调用失败: {str(e)}"
# 获取解释结果
explanation = get_llm_explanation(prompt)
# 打印结果
print("大模型生成的关联解释:")
print(explanation)输出结果:
大模型生成的关联解释: 好的,让我们一起来探讨一下这些数据背后的故事。 1. 加购次数 **关联度:0.5399** 解释: 加购次数指的是用户将商品加入购物车的次数。这个指标非常直观地反映了用户对商品的兴趣和购买意愿。如果一个用户多次加购某商品,这通常意味着他们对这个商品非常感兴趣,有很大的可能性最终会购买它。因此,加购次数与购买决策之间的关联度非常高。 2. 收藏次数 **关联度:0.4653** 解释: 收藏次数是指用户将该商品加入收藏夹的次数。收藏的行为表明用户对商品有一定的兴趣和偏好。虽然收藏次数没有加购次数那么高,但它仍然是一个很强的购买信号。毕竟,如果用户不打算购买,他们通常不会特意去收藏商品。 3. 浏览时长_分箱 关联度:0.4653** 解释: 浏览时长是指用户在商品详情页停留的时间。这个指标可以反映用户对商品的兴趣程度。一个用户在详情页停留时间较长,可能意味着他们对商品有较深的了解和兴趣,从而增加了购买的可能性。然而,浏览时长与购买决策的关联度相对较低,因为有些用户可能在详情页停留很长时间但不一定会购买,或者他们可能在浏览过程中失去了兴趣。 业务建议 基于以上分析,我们可以得出以下几点业务建议: 1. 提高加购率:商家可以通过优化商品详情页、增加用户评价、提供个性化的推荐等方式,进一步提高用户的加购率。加购次数的提升通常会直接 转化为购买行为。 2. 加强收藏功能:商家可以在商品页面增加更多的个性化推荐和互动元素,鼓励用户收藏商品。同时,定期清理长时间未访问的收藏夹,保持用户 的活跃度和兴趣。 3. 优化浏览体验:通过改进商品详情页的设计和内容,减少用户的浏览时间,提高他们的购买转化率。例如,提供更详细的产品信息、更清晰的用 户评价和更简洁的导航流程。 4. 综合运用多种策略:结合加购次数、收藏次数和浏览时长等多个指标,进行综合分析,制定更精准的营销策略。例如,对于加购次数多的用户, 可以推送更多的优惠活动和购买建议;对于收藏次数多的用户,可以提供更多的产品信息和个性化推荐。 通过这些方法,商家可以更有效地提高用户的购买转化率,提升整体的销售业绩。
步骤 7:结果验证与优化
核心目标:确保互信息计算准确、大模型解释合理。
验证方法:
- 1. 互信息验证:
- 更换离散化方法,比如等宽分箱→等频分箱,重新计算,看结果是否稳定;
- 增加样本量,看关联度排序是否变化。
- 2. 大模型解释验证:
- 检查解释是否与数据结果一致,比如是否正确指出加购次数关联度最高;
- 让业务人员评估解释是否易懂、是否符合业务逻辑;
- 优化提示词,比如增加“结合电商行业常识”,重新生成解释。
五、总结
互信息 MI + 大模型组合让我们深刻的认识到好的 AI,既要算得准,也要说得清。互信息负责准,它用最客观的方式告诉我们,哪些特征和结果最相关,不掺经验、不带偏见,在因素分析、原因追溯、知识点关联这些场景里,能一下子抓住核心,比瞎猜、靠经验靠谱太多。但它的问题也很明显,只给数字不给解释,非专业很难直接用。而大模型刚好补上这个缺口,它不抢计算的活儿,专门做 翻译官和解读专家,把冰冷的数值变成人话:为什么这个因素重要、背后可能是什么逻辑、接下来可以怎么行动。一个负责定量,一个负责定性;一个负责找关联,一个负责给解释,两者一结合,数据分析的门槛直接降了一大截。
我们可以先用互信息把关键关联筛出来,再交给大模型做深度解释。不管是电商找复购因素、教育找知识点关联、还是运维定位故障,都可以使用。真正好用的 AI,不是越复杂越好,而是让专业的事更精准,让难懂的结果更通俗。互信息 + 大模型,就是能看懂、能真正帮到业务的可行实践。
附录:完整实例代码
import pandas as pd
import numpy as np
# 读取数据
df = pd.read_csv("user_behavior.csv")
# 1. 处理缺失值
df["浏览时长(分钟)"].fillna(df["浏览时长(分钟)"].median(), inplace=True)
df["收藏次数"].fillna(0, inplace=True)
# 2. 连续变量离散化(浏览时长)
df["浏览时长_分箱"] = pd.cut(
df["浏览时长(分钟)"],
bins=[0, 10, 20, np.inf],
labels=["<10分钟", "10~20分钟", ">20分钟"]
)
# 3. 处理异常值(浏览时长>120分钟视为异常)
df.loc[df["浏览时长(分钟)"] > 120, "浏览时长(分钟)"] = df["浏览时长(分钟)"].quantile(0.95)
# 查看预处理后的数据
print(df.head())
from sklearn.metrics import mutual_info_score
from sklearn.preprocessing import KBinsDiscretizer
import numpy as np
# 定义计算归一化互信息(NMI)的函数
def normalized_mutual_info(x, y):
# 计算互信息
mi = mutual_info_score(x, y)
# 计算x和y的熵
def entropy(arr):
_, counts = np.unique(arr, return_counts=True)
prob = counts / counts.sum()
return -np.sum(prob * np.log2(prob + 1e-10)) # +1e-10避免log(0)
h_x = entropy(x)
h_y = entropy(y)
# 归一化(避免除以0)
if h_x == 0 or h_y == 0:
return 0
nmi = 2 * mi / (h_x + h_y)
return mi, nmi
# 目标变量:是否购买(0/1)
y = df["是否购买(0/1)"]
# 特征变量列表
features = ["浏览时长_分箱", "收藏次数", "加购次数"]
# 存储结果
mi_results = {}
nmi_results = {}
# 遍历特征计算MI和NMI
for feat in features:
mi, nmi = normalized_mutual_info(df[feat], y)
mi_results[feat] = mi
nmi_results[feat] = nmi
# 打印结果
print("互信息(MI)结果:")
for feat, val in mi_results.items():
print(f"{feat}: {val:.4f} 比特")
print("\n归一化互信息(NMI)结果(0~1):")
for feat, val in nmi_results.items():
print(f"{feat}: {val:.4f}")
# 将NMI结果按降序排序
sorted_nmi = sorted(nmi_results.items(), key=lambda x: x[1], reverse=True)
print("特征关联度排序(按NMI降序):")
for i, (feat, val) in enumerate(sorted_nmi, 1):
print(f"{i}. {feat}: {val:.4f}")
import matplotlib.pyplot as plt
import seaborn as sns
# 设置中文字体(避免乱码)
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
# 提取排序后的特征和NMI值
features_sorted = [item[0] for item in sorted_nmi]
nmi_sorted = [item[1] for item in sorted_nmi]
# 绘制柱状图
plt.figure(figsize=(10, 6))
sns.barplot(x=features_sorted, y=nmi_sorted, palette="viridis")
plt.title("用户行为特征与购买决策的关联度(NMI)", fontsize=14)
plt.xlabel("特征名称", fontsize=12)
plt.ylabel("归一化互信息(NMI)", fontsize=12)
plt.ylim(0, 1) # NMI范围0~1
plt.grid(axis="y", linestyle="--", alpha=0.7)
# 在柱子上标注数值
for i, val in enumerate(nmi_sorted):
plt.text(i, val + 0.02, f"{val:.4f}", ha="center", fontsize=10)
# 保存图片
plt.tight_layout()
plt.savefig("feature_correlation.png", dpi=300)
plt.show()
# 构造提示词
prompt = f"""
请你扮演一位电商数据分析专家,基于以下数据结果,向非技术背景的业务人员解释用户行为与购买决策的关联关系:
### 分析场景
本次分析的是电商平台用户行为(浏览时长、收藏次数、加购次数)与用户是否购买商品的关联关系。
### 关键定义
- 浏览时长_分箱:用户浏览商品详情页的时长,分为<10分钟、10~20分钟、>20分钟;
- 收藏次数:用户收藏该商品的次数;
- 加购次数:用户将该商品加入购物车的次数;
- 是否购买:用户最终是否购买该商品(0=未购买,1=购买);
- 归一化互信息(NMI):0代表完全无关,1代表完全相关,数值越大关联度越高。
### 数据结果
特征与是否购买的关联度排序(按NMI降序):
1. 加购次数:NMI=0.5399
2. 收藏次数:NMI=0.4653
3. 浏览时长_分箱:NMI=0.4653
### 解释要求
1. 用通俗易懂的语言解释每个特征与购买决策的关联程度;
2. 说明为什么加购次数的关联度最高;
3. 给出对应的业务建议;
4. 避免使用专业术语,确保非技术人员能理解。
"""
# 打印提示词(方便检查)
print(prompt)
import openai
from openai import OpenAI
# 配置API密钥(腾讯混元)
api_key = 'sk-bWl****************************P8Ze'
client = OpenAI(
api_key=api_key,
base_url="https://api.hunyuan.cloud.tencent.com/v1",
)
# 调用混元大模型生成解释
def get_llm_explanation(prompt):
try:
completion = client.chat.completions.create(
model="hunyuan-lite",
messages=[
{"role": "system", "content": "你是一位电商数据分析专家,擅长用通俗易懂的语言向非技术人员解释数据分析结果。"},
{"role": "user", "content": prompt}
],
temperature=0.3,
max_tokens=1000
)
return completion.choices[0].message.content
except Exception as e:
return f"调用失败: {str(e)}"
# 获取解释结果
explanation = get_llm_explanation(prompt)
# 打印结果
print("大模型生成的关联解释:")
print(explanation)原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号