OpenSpec propose 一步到位太粗糙?4 步开启 6 个扩展命令 ,从自动挡切手动挡,3 种模式适配不同节奏
原创
OpenSpec propose 一步到位太粗糙?4 步开启 6 个扩展命令 ,从自动挡切手动挡,3 种模式适配不同节奏
原创
运维有术
发布于 2026-05-15 21:08:11
发布于 2026-05-15 21:08:11
OpenSpec propose 一步到位太粗糙?4 步开启 6 个扩展命令 ,从自动挡切手动挡,3 种模式适配不同节奏
🚩 2026 年「术哥无界」系列实战文档 X 篇原创计划 第 112 篇,AI 编程最佳实战「2026」系列第 34
大家好,欢迎来到 术哥无界 | ShugeX | 运维有术。
我是术哥,一名专注于 AI 编程、AI 智能体、Agent Skills、MCP、云原生、AIOps、Milvus 向量数据库的技术实践者与开源布道者!
Talk is cheap, let's explore。无界探索,有术而行。
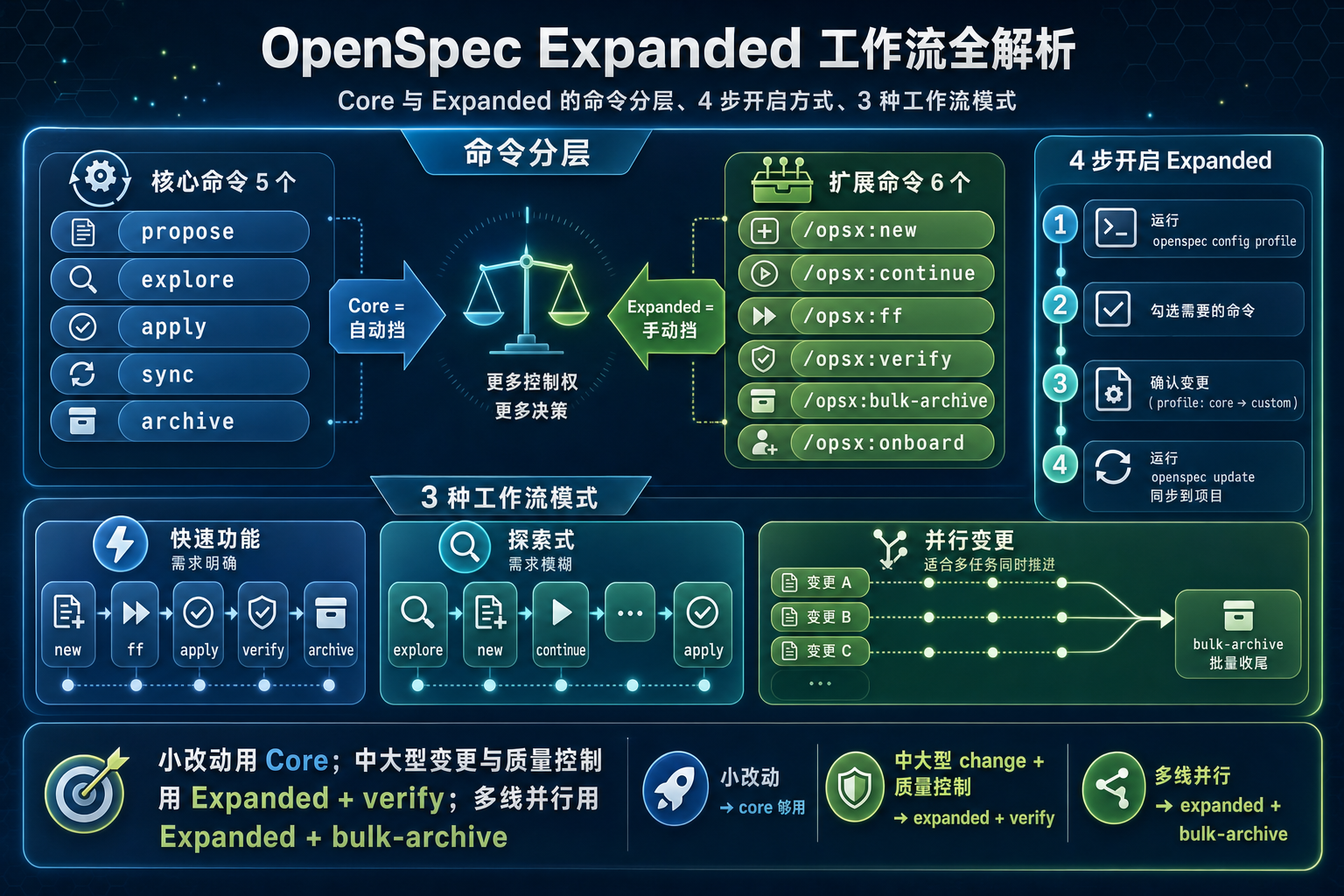
封面图:OpenSpec 工作流对比示意图
图 1:OpenSpec 工作流全景概览
说明:本文内容基于 OpenSpec 源码(Fission-AI/OpenSpec)和官方文档(workflows.md、opsx.md、commands.md、cli.md 等)分析整理而成,所有命令结构和配置逻辑均经过源码验证。文中的配置模板和参数建议仅供参考,实际效果请以你的项目环境测试结果为准。如果有实际使用经验,欢迎在评论区分享交流。
用 OpenSpec 有一段时间了,一直觉得 propose → apply → sync → archive 这条主线挺顺。直到有一天,我想在一个大型 change 里逐步审查每个产物,才发现 core 默认只给了 5 个命令 - 剩下的 6 个被藏了起来。
翻了一圈源码和文档,发现 OpenSpec 把命令分成了两档:core 和 expanded。core 追求快,expanded 追求精细。关键是,切换到 expanded 只需要 4 条命令。
今天这篇就来拆解 OpenSpec 的 Expanded/Full Workflow:它是什么、怎么开、什么时候用。
粉丝福利:关注 + 点赞 + 转发 + 推荐,在评论区聊聊你对 AI 编程的看法或这篇文章的体会,评论前 30 名送价值 $150 GPT Token 使用额度,先到先得。
1. 先搞清楚:Core 和 Expanded 有什么区别
OpenSpec 的命令集不是写死的,而是通过 Profile 系统 动态控制。默认的 core profile 只暴露 5 个命令:
propose → explore → apply → sync → archive这 5 个覆盖了创建规划 → 探索想法 → 实现任务 → 同步规格 → 归档的完整闭环。对于需求明确、规模可控的 change,这条路径够用。
但如果你遇到以下情况,core 就显得力不从心:
- 想在创建规划产物时逐步审查,而不是
propose一步到位 - 实现完成后想验证质量,而不是直接归档
- 同时推进多个 change,需要批量归档
- 新上手 OpenSpec,需要引导式教程
这些能力都在 Expanded 命令集里。OpenSpec 总共提供了 11 个 workflow 命令,core 只给了 5 个,剩下的 6 个需要手动开启。
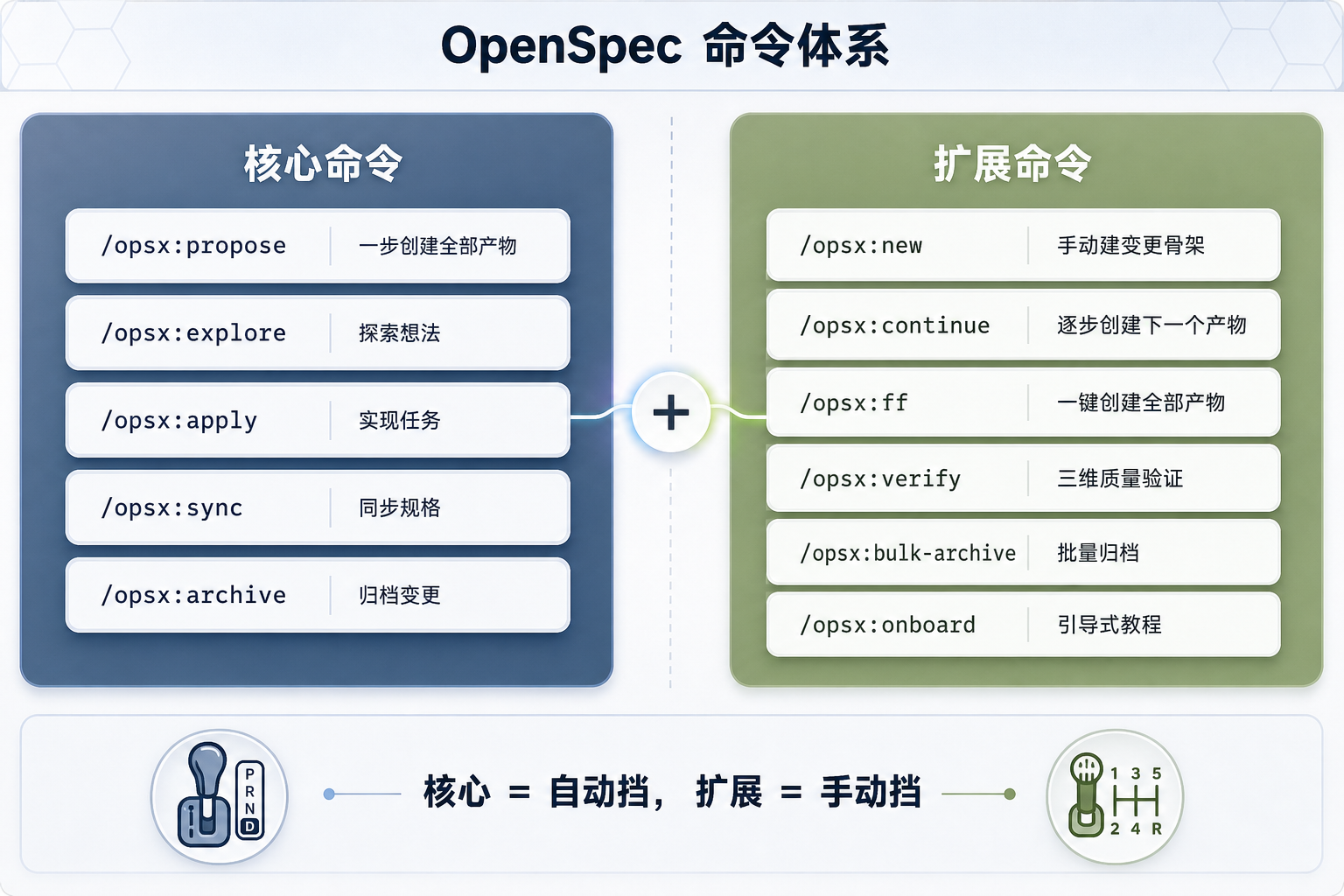
Core 5 个命令 vs Expanded 额外 6 个命令对比
图 2:Core 命令与 Expanded 命令对比
看张对比表更直观:
维度 | Core Profile | Expanded/Full Workflow |
|---|---|---|
启动方式 |
|
|
产物创建 | propose 自动生成全部 | 可逐个创建,每步审查 |
质量验证 | 无,直接 apply → archive |
|
归档能力 |
| 加上 |
入门引导 | 无 |
|
用一句话概括:core 是自动挡,expanded 是手动挡 - 给你更多控制权,但也需要你做更多决策。
2. 4 步开启 Expanded Workflow
切换到 expanded 不复杂,全程交互式操作,不用手动改配置文件。
第一步:运行 openspec config profile
openspec config profile这条命令会启动一个配置向导。首先显示当前状态:
Current profile settings
Delivery: both
Workflows: 5 selected (core)然后提示选择配置范围:
What do you want to configure?
❯ Workflows only
Delivery only
Delivery and workflows
Keep current settings (exit)选择 Workflows only(只改命令集,不动 delivery 模式)。
第二步:勾选需要的命令
系统会显示全部 11 个命令的 checklist,[x] 表示已选中,[ ] 表示未选中:
Select workflows to make available: (Space to toggle, Enter to confirm)
[x] Propose change
[x] Explore ideas
[ ] New change
[ ] Continue change
[x] Apply tasks
[ ] Fast-forward
[x] Sync specs
[x] Archive change
[ ] Bulk archive
[ ] Verify change
[ ] Onboard用空格键切换勾选,回车键确认。把 new、continue、ff、verify、bulk-archive、onboard 都选上就行。
第三步:确认变更
向导会显示变更摘要:
Config changes:
profile: core -> custom
workflows: added new, continue, ff, verify, bulk-archive, onboard确认后,配置会保存到全局配置文件 ~/.config/openspec/config.json(遵循 XDG 规范)。
如果当时在 OpenSpec 项目目录内,系统还会提示:
Apply changes to this project now? (Y/n)建议选 Y,省得再跑一次。
第四步:运行 openspec update
openspec update这一步把全局配置同步到当前项目的 AI 工具配置文件里(比如 .claude/skills/ 目录下的 skill 文件)。不跑这步的话,AI 编码助手看不到新启用的命令。
到这里,expanded 命令就启用了。总共 4 步,全程不超过两分钟。
有个细节:如果你恰好只选了 core 的 5 个命令,系统会自动把 profile 识别为 core;选了其他任何组合,都会被标记为 custom。这个逻辑在源码里写得很清楚:
// src/core/profiles.ts
export function deriveProfileFromWorkflowSelection(
selectedWorkflows: string[]
): Profile {
const isCoreMatch =
selectedWorkflows.length === CORE_WORKFLOWS.length &&
CORE_WORKFLOWS.every((w) => selectedWorkflows.includes(w));
return isCoreMatch ? 'core' : 'custom';
}3. 6 个 Expanded 命令详解
开启 expanded 之后,你多了 6 个命令。逐个看。
/opsx:new - 手动建 change 骨架
和 /opsx:propose 不同,new 只创建 change 的基础结构(目录 + 元数据),不生成任何规划产物。
适用场景:你想先建好 change 容器,再决定用什么节奏填充产物。比如先 /opsx:new 建骨架,再手动写 proposal,然后用 /opsx:continue 逐步往下推。
/opsx:continue - 创建下一个产物
这个命令会根据依赖关系,自动创建下一个还缺的产物。Artifacts 之间有严格的依赖图:
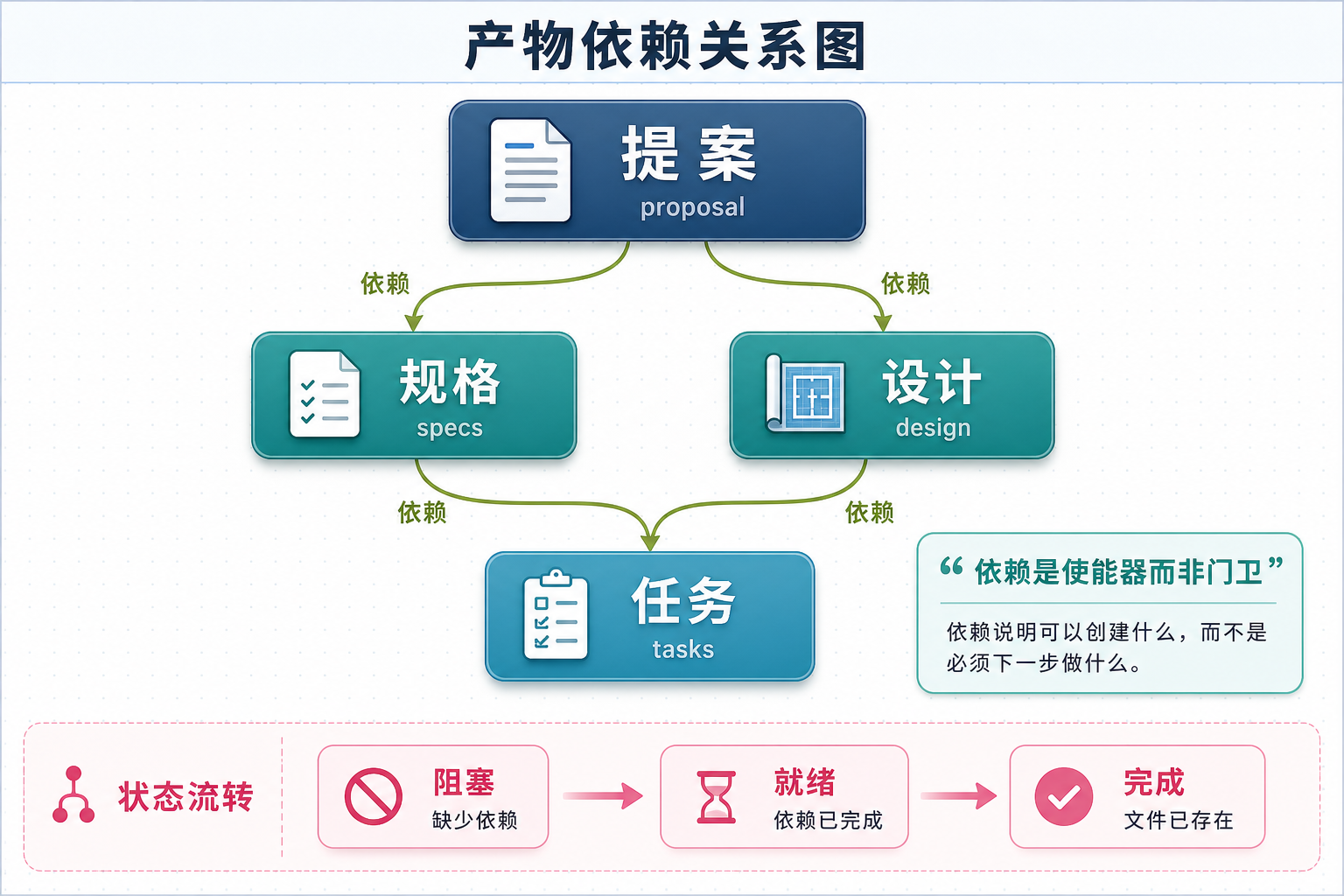
产物依赖关系图
图 3:Artifact 依赖关系与状态流转
每跑一次 /opsx:continue,就创建下一个就绪的产物。你可以审查完一个再推下一个,控制粒度比 /opsx:propose 细得多。
/opsx:ff - 快进创建所有产物
ff 是 fast-forward 的缩写。一键创建 proposal → specs → design → tasks 全部规划产物。
和 /opsx:propose 的区别?ff 是在 /opsx:new 建好骨架之后用的,相当于骨架已经搭好,现在一口气填完所有产物。而 propose 是从零开始,建骨架 + 填产物一步完成。
适用场景:需求很明确,你只想快速进入实现阶段。
/opsx:verify - 三维质量验证
这个命令是 expanded 里最有价值的一个。它从三个维度检查实现质量:
维度 | 验证内容 |
|---|---|
Completeness(完整性) | 所有 tasks 是否完成?所有 requirements 是否有对应代码?场景是否覆盖? |
Correctness(正确性) | 实现是否匹配 spec 意图?边界情况是否处理?错误状态是否匹配? |
Coherence(一致性) | 设计决策是否反映在代码中?命名约定是否与 design.md 一致? |
有一点要注意:verify 不会阻止 archive。它更像是提前给你看体检报告,要不要处理是你的事。
/opsx:bulk-archive - 批量归档
当你同时推进多个 change 时,一个个 /opsx:archive 太繁琐。bulk-archive 可以一次性处理多个已完成的 change,还会检测 specs 之间的冲突,按时间顺序归档。
/opsx:onboard - 引导式教程
新用户入门用的。第一次接触 OpenSpec 的人可以跑一遍 /opsx:onboard,它会引导你走完一个完整的 change 生命周期。
4. 3 种工作流模式组合
Expanded 命令的价值不在于单个命令,而在于不同的组合方式能适配不同的开发节奏。根据官方文档,有三种典型模式。
模式一:Quick Feature - 需求明确,直接开干
/opsx:new → /opsx:ff → /opsx:apply → /opsx:verify → /opsx:archive流程很清晰:建骨架 → 快进填充产物 → 实现 → 验证 → 归档。
和 core 的 propose → apply → archive 相比,多了一步 verify。如果你的团队对代码质量有要求,这一步能省不少 code review 的时间。
模式二:Exploratory - 需求不明确,边探索边做
/opsx:explore → /opsx:new → /opsx:continue → ... → /opsx:apply先用 explore 调研问题空间,确认方向后再 new 建骨架,然后 continue 逐步创建产物。每一步都可以审查和调整,适合复杂度高、需求模糊的场景。
这其实是 OpenSpec 官方推荐的 迭代式 用法 - 先想清楚再动手,而不是一上来就 propose 砸出一个完整方案。
模式三:Parallel Changes - 多线并行
Change A: /opsx:new → /opsx:ff → /opsx:apply(进行中)
│
切换到 Change B
│
Change B: /opsx:new → /opsx:ff → /opsx:apply → /opsx:archive完成后用 /opsx:bulk-archive 一次性归档。
这种模式适合同时推进主线功能和紧急修复。/opsx:apply <name> 可以按名称切换当前工作的 change,不会互相干扰。
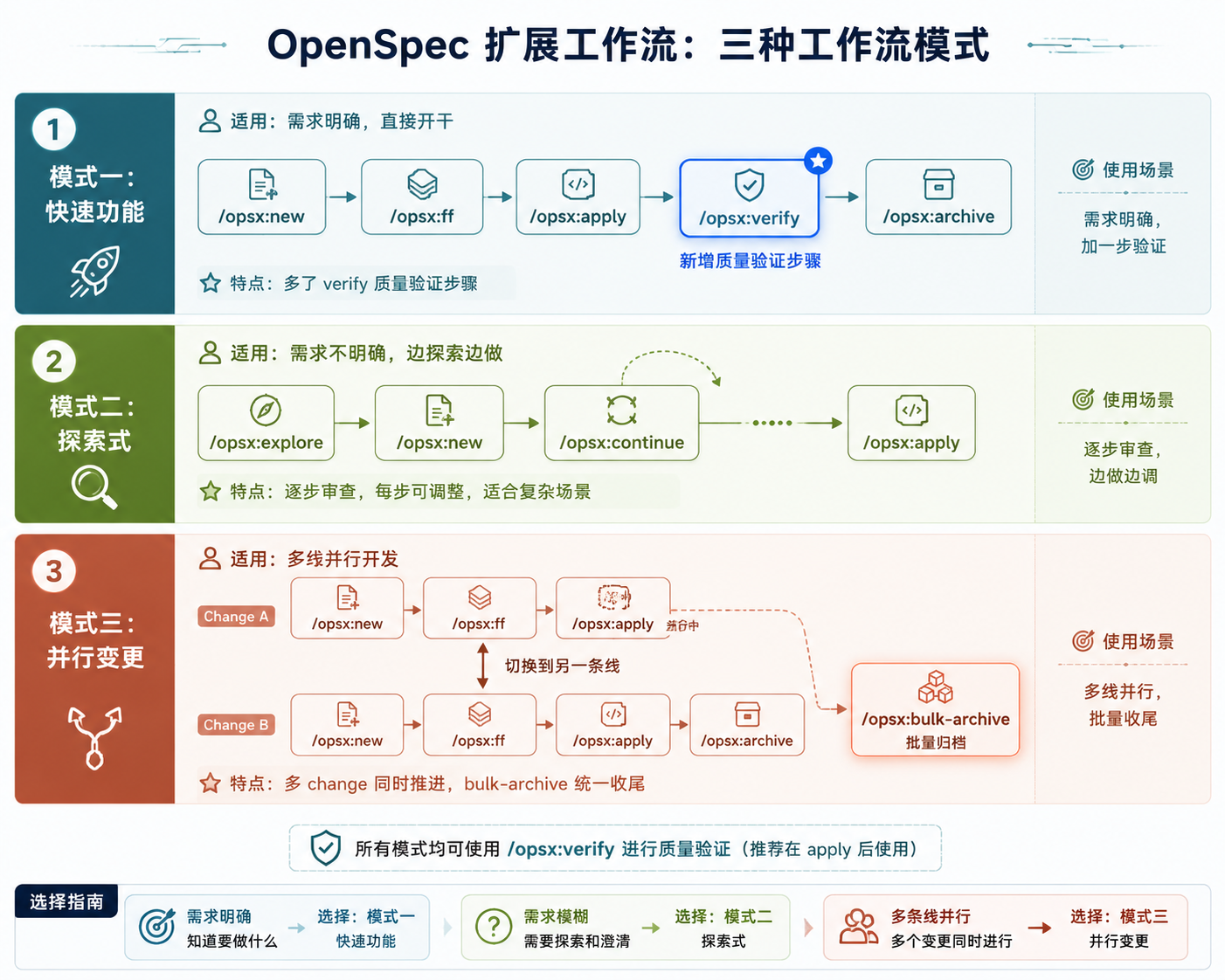
三种工作流模式对比
图 4:三种工作流模式对比
/opsx:ff 还是 /opsx:continue?
两种命令都能创建产物,选择看场景:
场景 | 推荐 |
|---|---|
需求明确,准备开干 |
|
探索中,想逐步审查 |
|
想先迭代 proposal 再写 specs |
|
有时间压力,需要快速推进 |
|
复杂变更,需要精细控制 |
|
一个简单的判断标准:能提前描述完整范围的用 ff,边做边摸索的用 continue。
5. 底层机制:Profile 和依赖图
如果你对 OpenSpec 的内部实现感兴趣,这里简单拆一下两个关键设计。
Profile 推导
OpenSpec 的全局配置结构长这样:
interface GlobalConfig {
featureFlags?: Record<string, boolean>;
profile?: 'core' | 'custom';
delivery?: 'both' | 'skills' | 'commands';
workflows?: string[];
}配置存储在 ~/.config/openspec/config.json。当你通过 openspec config profile 选择了命令后,系统会自动判断 profile 类型 - 如果恰好是 core 的 5 个命令,profile 就是 core;否则自动设为 custom。
这个设计的好处是:你不需要手动声明 custom profile,选了命令它自动推导。
Artifact 依赖图
前面提到过产物之间的依赖关系,这里补充一下状态流转:
BLOCKED → READY → DONE
│ │ │
缺少依赖 所有依赖 文件已
已完成 存在于磁盘官方文档里有个说法很精辟:依赖是使能器而非门卫。它们告诉你什么可以创建,而不是下一步必须创建什么。这意味着你有选择权 - 可以先做 specs 再做 design,也可以反过来。
总结
OpenSpec 把 11 个命令分成 core(5 个)和 expanded(+6 个)两档,默认只给 core。这不是阉割,而是设计哲学:先帮你做减法,等你需要精细控制的时候再解锁。
如果你正在用 OpenSpec,建议根据实际场景选择工作流模式:
- 小改动、需求明确 → core 的
propose → apply → archive就够了 - 中大型 change、需要质量控制 → 开启 expanded,加上
verify - 多线并行开发 → 开启 expanded,用
bulk-archive批量收尾
说到底,工具的价值不在于功能多,而在于你能不能在合适的场景用上合适的功能。OpenSpec 的 expanded workflow 给了更多选择,但什么时候用、怎么组合,还是得看你的项目节奏。
你在用 OpenSpec 的时候更倾向于 core 快速路径还是 expanded 精细控制?评论区聊聊。
相关资源
OpenSpec GitHub 仓库:https://github.com/Fission-AI/OpenSpec
好啦,谢谢你观看我的文章,如果喜欢可以点赞转发给需要的朋友,我们下一期再见!敬请期待!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号