IM分布式架构系列(01) 千人群一条消息要扇出 999 次 | 写扩散账单
原创
IM分布式架构系列(01) 千人群一条消息要扇出 999 次 | 写扩散账单
原创
拉丁解牛说技术
修改于 2026-05-17 23:43:00
修改于 2026-05-17 23:43:00
读书心得笔记:著名投资家、巴菲特的黄金搭档 查理.芒格,他最喜欢的一句话“我只想知道我会死在哪里,这样我就永远不去那里。”这是芒格一辈子最核心的思维方法-逆向思维。他总是习惯:反过来想。
大多数人问:我怎么样才能成功?
芒格想的是:什么会导致我失败,我要避开它。
大多数人问:我怎么样才能幸福快乐?
芒格想的是:什么会导致我痛苦、悲伤?然后避开这些。
目录
一、背景
二、具体设计
三、大厂如何设计
四、优化提升
一、背景
某天下午,你在一个 1000 人的项目群里发了一条 7 个字的消息:「今晚九点发版」。
对你来说,这是一次点击、一段 7 字符的字符串、一次"已发送"的小对勾。
但服务端为这条消息做了什么?
按写扩散(Fan-out on Write)的实现思路,最直观的版本是这样的:
1 条消息进入消息服务
↓
群服务展开成员列表(999 人,去掉自己)
↓
为每个成员生成一个"投递任务"副本 (999 份)
↓
每个副本:
- 写一条 MQ 消息到下游消息分发
- 查一次 Redis 看目标是否在线
- 在线 → Dubbo 推到接入网关 → Channel.writeAndFlush
- 离线 → 写离线盒子 + 触发三方推送 (APNs/FCM/HMS)
- 未读数 +1
- 已读位图初始化一位仅消息副本本身就是 999 次扇出。加上路由查询、未读写入、三方推送触发,一条 7 字消息在服务端产生 3000~5000 次后端操作不是夸张。
这就是"写扩散"这个词背后的真实账单。
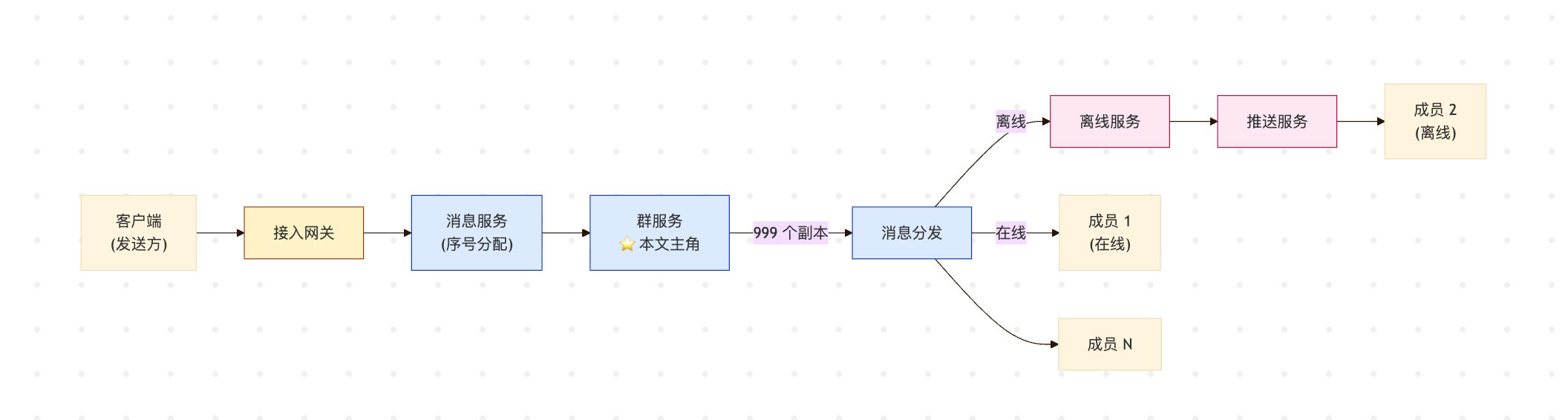
图 1. 群消息的扇出位置。群服务是「1 → N」的关键节点。
1.1 群消息为什么要做扇出?
群消息这个功能在工程上有两条出路:
方案 | 含义 | 代价 |
|---|---|---|
写扩散 | 发送时就为每个成员生成一份"投递任务",写入各自的收件箱 | 写多:千人群 = 999 次写 |
读扩散 | 群消息只存一份,每个成员"读群"的时候再去拉 | 读多:每次进群要算未读 / 拉消息 |
不扇出 | 暴力广播给所有在线 | 离线成员丢消息,已读 / 撤回根本做不了 |
中小 toB 项目大多选写扩散,因为 toB 场景里"已读回执 / 消息撤回 / 离线补全"是硬需求 — 没有每成员维度的"投递记录",这三个功能都立不住。
二、具体设计
2.1 设计目标
中小规模 toB IM 项目里,群消息扇出这一层通常要同时满足:
- 实时性:在线成员从发送到收到 P95 < 100ms
- 可靠性:离线成员上线后必须能补到这条消息
- 可观测:每个副本的投递状态可追踪(用于 SRE 排障)
- 业务能力:支撑已读回执、消息撤回、漫游、未读统计
- 规模:单群默认 1000 人,少数业务场景 3000~5000 人
这些约束串起来,几乎一定走向写扩散。
2.2 副本生成位置
候选 3 种:
方案 | 含义 | 优势 | 致命缺陷 |
|---|---|---|---|
入口层 | API 网关拿到群消息就展开 999 份请求 | 简单 | 入口流量爆炸,鉴权 999 次 |
群服务(主流) | 消息先到群服务,由它加载成员、生成副本 | 责任清晰,便于复用群成员缓存 | 群服务成扇出热点 |
分发层 | 消息发给分发层附带"群 id",分发层按需扇出 | 群服务轻 | 分发层要懂群成员结构,破坏分层 |
主流选择:群服务展开。理由是责任边界清晰 — 群成员、群属性、群配置全在群服务,扇出本来就应该是它的活。
伪代码大致是这样:
on_group_message_arrive(msg):
group = group_cache.load(msg.group_id)
members = group.member_list # 1000 人
members = filter_out_sender(members, msg.from) # 999 人
for member in members:
copy = clone_with_target(msg, member.uid)
copy.uuid = msg.uuid + "|G" + member.short_id // 副本标识
publish_to_dispatcher(copy)注意最后那个 uuid + "|G" + member.short_id — 这是写扩散里的"副本指纹",下游所有组件(历史库、离线、已读聚合)都靠这个区分"原消息"和"副本"。
2.3 扇出执行方式
这是最容易踩坑的设计点。3 种执行方式的对比:
方式 | 1000 人群的代价 | 真实体感 |
|---|---|---|
同步 RPC 一条一条调 | 999 次 RPC,串行 ≈ 5~10 秒 | 不可用 |
异步 MQ 逐条 | 999 次 MQ 写 + 异步消费 | 主流但贵 |
异步 MQ 批量 | ~10~50 次 MQ 写(每条装 20~100 个目标) | 推荐 |
中小项目早期常见的姿势是异步 MQ 逐条 — 简单、容易实现、文档好查。但当群规模到 1000 人级别时,MQ 写入次数会成为系统瓶颈:
- 单条 MQ 写入耗时 ~1~3ms,999 条串行 ≈ 1~3 秒;并行能压到 100ms 内,但 broker 压力大
- 如果有 100 个千人群同时活跃,MQ broker 每秒要接收 ~10 万条扇出消息
改进方向:MQ 批量化。把 999 个目标用户分成 20 批,每批 50 人装在一条 MQ 消息里:
on_group_message_arrive(msg):
members = filter_out_sender(group.member_list, msg.from)
for batch in chunk(members, batch_size=50): // 50 人一批
batch_msg = {
"origin": msg,
"targets": [m.uid for m in batch]
}
publish_to_dispatcher(batch_msg) // 一次 MQ 写下游分发服务消费时再"展开"批次,对批内每个目标做路由 + 投递。MQ 写次数从 999 降到 ~20,吞吐能力提升一个数量级。
2.4 副本指纹与双轨存储
写扩散的一个隐蔽问题是:副本要不要进历史库?
- 进 — 千人群 1 条消息进历史库 999 条,分表空间爆炸
- 不进 — 那历史消息只存原消息,未读 / 已读怎么对账?
主流做法是双轨:
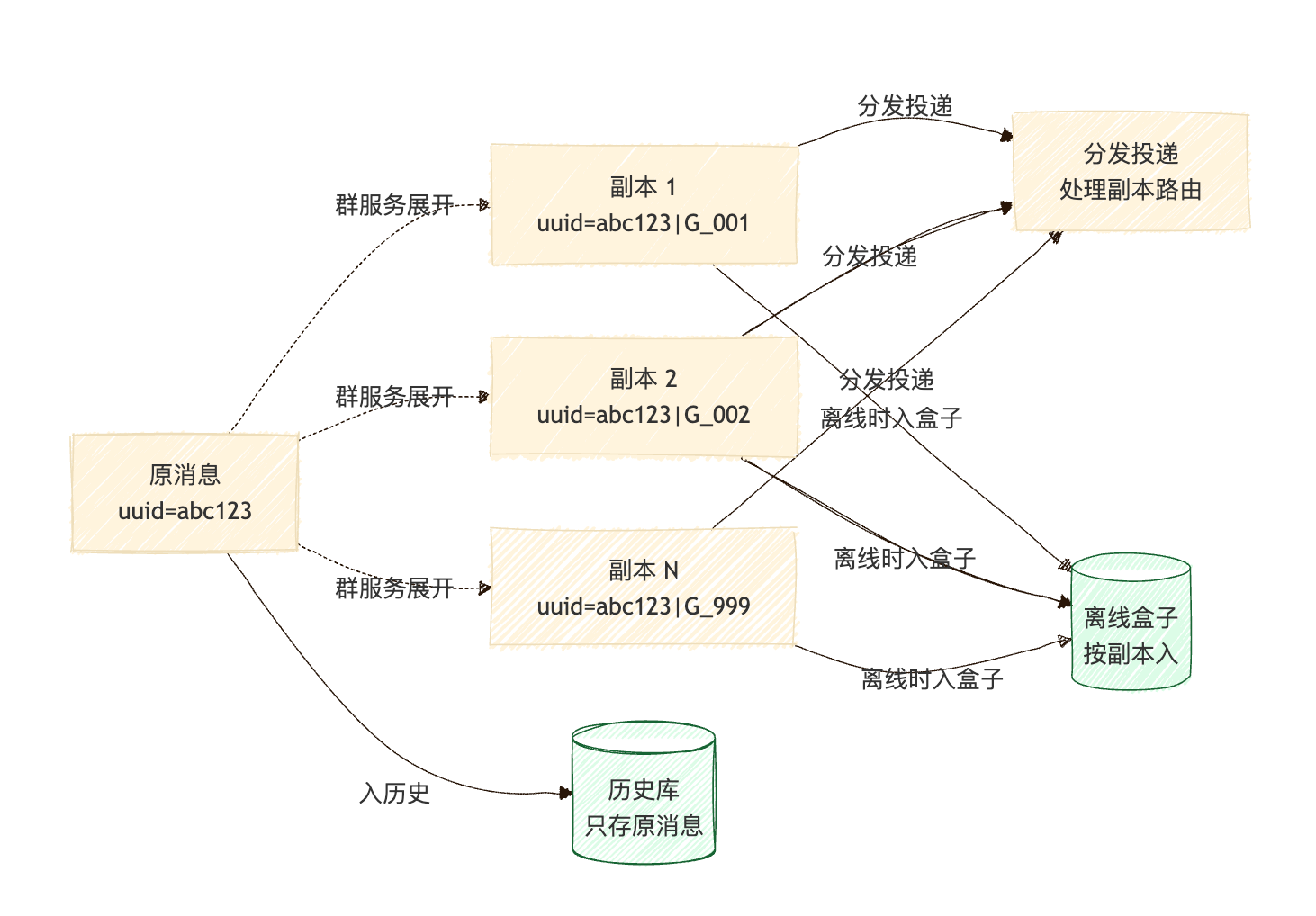
图 2. 写扩散的双轨存储:历史库只有 1 条,离线盒子可能有 N 条。
判断规则:
数据写入点 | 入历史库吗 | 入离线盒子吗 |
|---|---|---|
原消息(uuid 不含 |G) | ✅ | ❌(不针对某个具体成员) |
副本(uuid 含 |G) | ❌(过滤掉) | ✅(针对每个离线成员) |
历史库消费者扫一眼 uuid 里有没有 |G 就知道丢弃还是入库。这是工程上极简但关键的判断。
2.5 失败处理
写扩散场景下,"完全成功"是个奢侈品。需要承认部分失败常态,设计要点:
- 失败必须可重试 — 副本本身就是 MQ 消息,失败 = 不 ACK,broker 自动重投
- 重试要有上限 — 重试 3~5 次仍失败的进死信队列,由 SRE 人工处理
- 不让发送方感知 — 发送方在原消息入库时就 ACK 了("消息已发送"),扇出失败是后台事故,不回传到发送方
- 失败可定位 — 每个副本带原消息 uuid + 目标 uid,死信里能精确知道"哪条消息没投到哪个人"
伪代码:
on_dispatcher_consume(copy_msg):
try:
route_and_deliver(copy_msg)
except RetryableError as e:
if copy_msg.retry_count < 5:
reject_and_requeue(copy_msg) // MQ 重投
else:
send_to_dead_letter_queue(copy_msg) // 死信,SRE 处理
metrics.inc("group.fanout.dead_letter")
except FatalError as e:
send_to_dead_letter_queue(copy_msg)2.6 规模分档
写扩散有个无法跨越的物理上限:群越大,扇出代价越接近不可承受。
- 100 人群 — 100 次副本,舒服
- 1000 人群 — 999 次副本,已经要做批量化
- 5000 人群 — 4999 次副本,需要专门优化策略
- 10000 人群 — 写扩散根本走不通
工程上必须明确一条线:超过 N 人的群切换策略。主流做法:
群规模 | 策略 |
|---|---|
< 500 | 朴素写扩散,逐条 MQ |
500 ~ 2000 | 批量化写扩散(设计点 2) |
2000 ~ 5000 | 批量 + 在线优先(先扇在线成员,离线异步补) |
5000 | 切读扩散 或专门的"广播"模式 |
2.7 群消息扇出时序全貌
把上面 5 个设计点串起来:
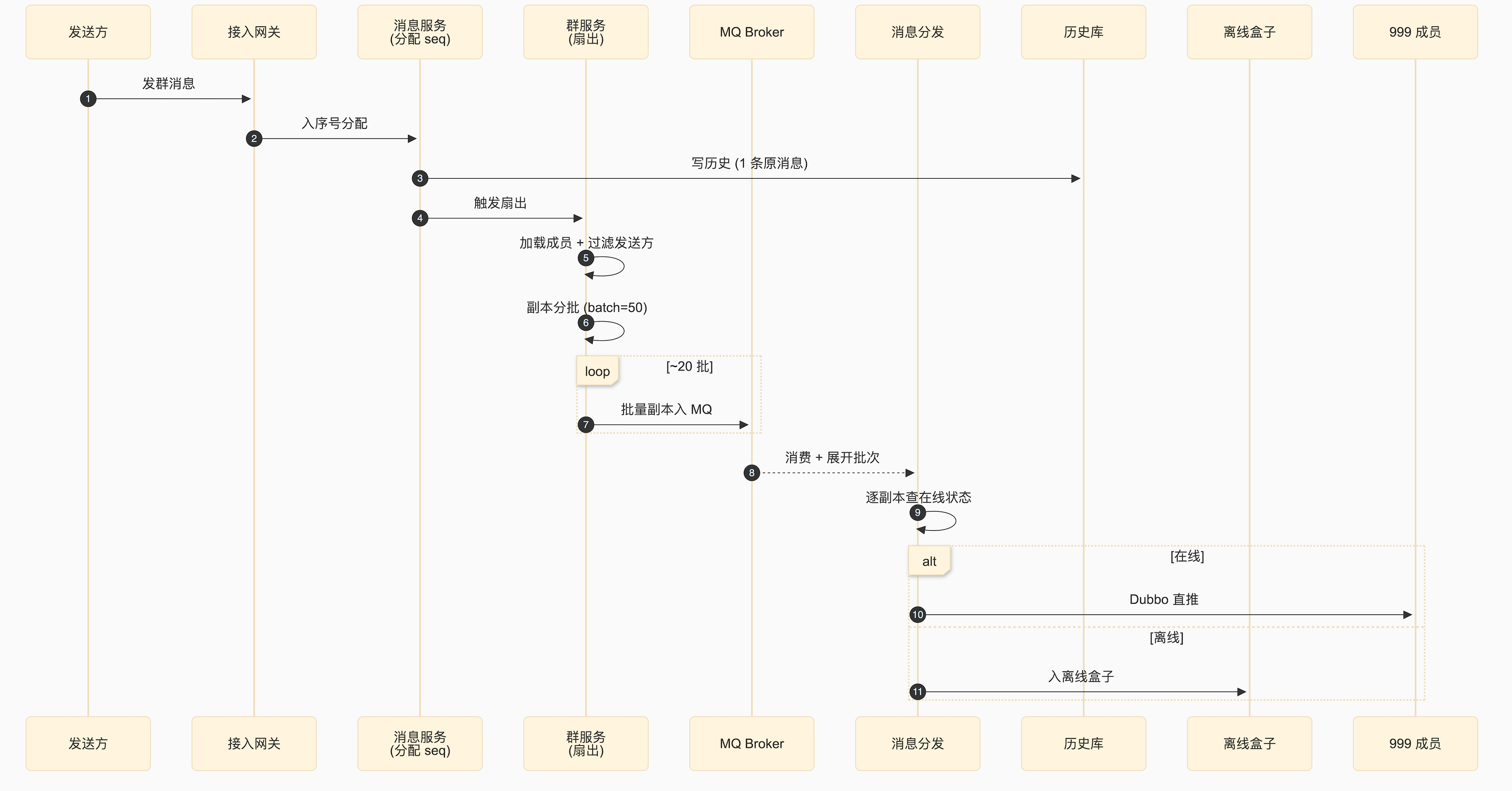
图 3. 群消息扇出的完整时序
三、大厂如何设计
不同体量的 IM 系统在这一层的设计差异极大。写扩散不是唯一解 — 当规模到某个临界点,读扩散反而是更合理的选择。
3.1 某钉IM
钉IM,最早也走写扩散,但在万人群场景下扛不住,演进为读扩散为主 + 推拉结合 + 多级缓存[1]。
核心思路:
- 群消息只存一份(不再为每个成员复制)
- 成员"读群"时按订阅关系拉取
- 实时性靠"近期消息推送 + 历史消息客户端按需拉取"补足
- 多级缓存(万人群成员缓存)让"反查群成员"快到毫秒级
优势 | 万人群一条消息从 1 万次写降到 1 次写;群规模上限大幅提高;存储成本下降 |
代价 | 已读回执的实现复杂度暴增(要在读时做聚合计算); 客户端逻辑更重(需要主动拉取、判断本地是否完整); 推拉结合的协议设计成本高 |
最终:他们用智能限流和万人群成员多级缓存来支撑超级大群的运营。
3.2 某信IM架构
在群消息"存一份还是存多份"的存储架构权衡上,相关高级研发工程师在技术博客分享中提到,采用写扩散路线[2]:每条群消息按成员数复制成多份存储,换取读路径的极致简单(撤回、漫游、未读计数都只需操作单成员的消息流)。代价是写放大与存储成本随群规模线性上涨。
优势 | 实现简单,已读 / 撤回 / 漫游都好做;离线补消息逻辑极简(拉 inbox 即可) |
代价 | 群规模上限限制了应用场景;一条消息写 N 次,存储成本明显 |
3.3 企某信的IM架构
企某信和总所周知的微信,是两个系统,企某信的设计目标是支持万人群 + 已读回执[3]。
它的做法是:仍然走写扩散,但投入更多硬件资源 + 各种局部优化(批量、缓存、异步)来支撑万人群的扇出成本。
优势 | 已读回执对企业用户是刚需,写扩散下实现自然;撤回、漫游全部继承写扩散的优势 |
代价 | 单条消息的服务端成本明显高于某钉; 群规模仍有上限(应该是10000,远超微信群人数的 500) |
3.5 对比
维度 | 某钉 | 微信 | 企某信 |
|---|---|---|---|
扇出策略 | 读扩散 + 推拉 | 写扩散 + 异步队列 | 写扩散 + 资源换 |
群规模上限 | 万人级 | 500 | 万人级 |
已读回执 | ✅(聚合实现) | ❌ 无 | ✅ 强 |
撤回 | ✅ | ✅ | ✅ |
客户端复杂度 | 高(推拉协议) | 低 | 中 |
服务端单条消息成本 | 低 | 中 | 高 |
工程复杂度 | 高 | 低 | 中 |
典型适合规模 | 千万级 DAU + 大群 | 限规模产品 | 大企业级 |
四、优化提升
中小规模 toB IM 在群扇出这一层有一条清晰的演进路径 — 但具体怎么走,要从你的产品定位、规模分布、工程团队能力倒推。下面是几个值得反复思考的点。
4.1 群规模上限
你的产品定位决定了上限的硬约束。如果业务场景就是大企业、需要万人群(如政府客户、大型集团内部沟通),那从 day 1 就应该认真评估读扩散方案 — 等到业务跑起来再切,技术债的复利会让人后悔。但如果只是一个中小企业协作工具,500 人甚至 1000 人上限其实没问题(参考微信群限制 500 人的判断)。先决定群规模的产品上限,再决定架构 — 这个顺序反过来就麻烦。
4.2 MQ 批量化
观察过的几乎所有中小规模 toB IM 项目都在 MQ broker 上付过血泪学费。Broker 的瓶颈往往不是磁盘 IO,而是连接数和单 partition 的串行化处理。批量化(batch=20~50)能让 MQ 写入次数降一个数量级,是收益明显的优化方向。但要注意批量化引入的复杂性 — 一批 50 个目标,其中 3 个失败该怎么处理?个人在中等规模 IM 项目里观察到的常见做法是"批内失败拆分重投"(把失败的 3 个重新打包成新的小批次发回 MQ)。
4.3 副本瘦身
副本带不带完整 payload 是个分歧点。带 payload 简单(下游消费者不需要反查原消息)但浪费带宽(千人群 1 条 1KB 消息 = 1MB 流量);不带 payload 省带宽但下游消费者要做一次 KV 反查。比"完全瘦身"更工程化的做法是分档:消息体 < 1KB 时带 payload;超过就拆 — 副本只带 uid + uuid + 摘要(首 100 字符做消息预览),下游展开时按 uuid 反查全文。这种"内嵌摘要 + 按需反查"的混合方案,既能保留消息列表的预览体验,又能控制带宽峰值。
4.4 可观测体系
很多中小项目的扇出层处于"出问题时翻日志、平时不看"的状态,这是个隐患 — 当你发现"群消息延迟变高"时,往往已经在客服工单里出现了。最值得加的三个指标分别是:
单条群消息的扇出 RT P99(衡量端到端时长,是不是有慢扇出);
副本投递失败率按时间窗口分桶(衡量是否有阶段性故障);
批内部分失败率(如果做了批量化,衡量批是不是被"少数失败拖累整批")。
这三个指标加起来,P0 故障定位时间能从"翻半小时日志"压缩到"看一眼大盘"。
4.5 大群临界点
如果业务真的开始需要 5000 人以上的群,参考某钉从写扩散切到读扩散的演进经验,关键经验是 — 切换不是一蹴而就的。中间过渡期通常是混合模式:千人以下继续写扩散(保留已读 / 撤回的低成本实现),千人以上的群单独走读扩散通道(客户端读消息时按 uuid 范围拉取,已读用 bitmap 聚合)。这种"按规模分流"的混合策略可以让团队渐进切换,不需要一刀切的大重构。关键是分流的判断点要明确(在群创建时就标记类型),而不是在每次消息扇出时动态判断 — 后者会让代码路径越来越复杂。
写扩散不是终点,是某个规模下的最优解。真正的工程能力,是知道什么时候该走,什么时候该停。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号