DolphinDB开发者评测:用多范式编程重新定义时序数据分析
原创
DolphinDB开发者评测:用多范式编程重新定义时序数据分析
原创
九日大大
修改于 2026-05-17 13:35:00
修改于 2026-05-17 13:35:00

摘要
作为一名后端开发者和数据技术爱好者,我一直在关注时序数据库领域的发展。在处理海量时序数据时,我们常常面临一个尴尬的局面——数据库只负责"存",复杂的分析和计算要交给外部的 Spark、Flink、Python 完成。数据在不同系统间反复搬运,链路长、延迟高、维护成本大。
最近,我花了一段时间深入体验了 DolphinDB——一款集高性能时序数据库、分布式计算和流处理于一体的实时计算死数据库。让我意外的是,它不仅是一个数据库,更内置了一门图灵完备的多范式编程语言,支持 SQL、命令式、函数式、向量化编程,甚至可以在 SQL 中直接调用自定义函数和机器学习模型。
本文将以开发者的第一视角,从实际编码体验出发,横向对比 DolphinDB 与 InfluxDB、TimescaleDB 等主流时序数据库的开发体验、SQL 能力、计算性能和生态集成,帮助你判断:DolphinDB 是否值得成为你技术栈中的下一站。
一、评测背景:为什么选择 DolphinDB?
1.1 开发者的时序数据库选型之困
在我的日常工作中,时序数据场景非常常见——服务监控指标、业务日志分析、IoT设备数据、金融行情处理。每次技术选型,我都会在几个主流方案之间纠结:
方案 | 优势 | 让我纠结的地方 |
|---|---|---|
InfluxDB | 类SQL语法(Flux/InfluxQL),部署简单 | 免费版单节点,无分布式;复杂计算需导出 |
TimescaleDB | 基于PostgreSQL,标准SQL,生态好 | 复杂分析仍依赖外部工具,大规模分布式能力有限 |
ClickHouse | OLAP查询极快,列式存储 | 流计算支持弱,不是严格意义上的时序数据库 |
共同的痛点:数据库只解决存储问题,一旦涉及复杂分析(时序对齐、滑动窗口、多频关联),就必须把数据导出到 Python 或 Spark 中处理。数据搬运本身就成了瓶颈。
1.2 DolphinDB 吸引我的三个理由
- 存算一体:存储和计算在同一个平台内完成,不需要数据搬运
- 内置脚本语言:不只是写SQL查询,还能像写Python一样用命令式、函数式的风格写复杂逻辑,甚至可以在SQL里直接调用自定义函数
- 流批一体:同一套代码处理历史数据和实时流,不需要两套技术栈
带着"真有这么好?"的心态,我开始了DolphinDB深度体验。

二、开发体验:从安装到写出第一行代码
2.1 安装与部署
DolphinDB 支持单机模式和集群模式,开发测试用单机即可。社区版免费,从官网下载解压后即可运行。
在开发接口方面,DolphinDB 提供了 Python、C++、Java、C# 等多种语言的 API(SDK),同时支持 Web 集群管理器、VS Code 插件、Java GUI、Jupyter Notebook 等客户端。我个人习惯用 VS Code 插件 + Python API 进行开发。
2.2 连接与基本操作(Python API)
DolphinDB 提供了官方 Python API(dolphindb),支持 pandas DataFrame、Arrow Table 等数据格式的双向交互,对 Python 开发者非常友好。
import dolphindb as ddb
import pandas as pd
# 建立连接
sess = ddb.Session()
sess.connect("localhost", 8848, "admin", "123456")
# 在DolphinDB中创建数据库和表
sess.run("""
db = database("dfs://demo", VALUE, 2024.01M..2024.12M)
t = table(1000:0, `date`sym`price`volume,
[DATE, SYMBOL, DOUBLE, INT])
db.createPartitionedTable(t, "stock", "date")
""")
# 用pandas DataFrame写入数据
df = pd.DataFrame({
'date': pd.date_range('2024-01-01', periods=100),
'sym': ['AAPL', 'GOOG', 'MSFT'] * 33 + ['AAPL'],
'price': np.random.uniform(100, 500, 100),
'volume': np.random.randint(1000, 100000, 100)
})
sess.run("tableInsert{loadTable('dfs://demo', 'stock')}", df)
# 查询数据
result = sess.run("""
select count(*) as cnt, avg(price) as avg_price,
sum(volume) as total_vol
from loadTable("dfs://demo", "stock")
group by sym
""")
print(result)体验感受: Python API 的设计和 psycopg2(PostgreSQL)非常类似,上手零门槛。支持直接传入 pandas DataFrame,不需要手动做类型转换,这点比 InfluxDB 的 Python 客户端好用很多。
三、SQL 能力评测:超越标准 SQL 的时序分析利器
这是我体验下来 DolphinDB 最让我惊喜的部分。它支持 SQL-92 标准,同时兼容 Oracle 和 MySQL 方言,但更关键的是——它在 SQL 层面做了大量面向时序数据分析的扩展。
3.1 标准SQL支持
DolphinDB 支持标准的 SELECT / INSERT / UPDATE / DELETE / CREATE / ALTER,语法与主流关系型数据库基本一致:
-- 标准查询,毫无学习成本
select sym, avg(price) as avg_price, max(volume) as max_vol
from stock
where date between 2024.01.01 and 2024.03.31
group by sym
order by avg_price desc3.2 三大独有扩展:context by / pivot by / asof join
(1)context by:面板数据处理的神器
标准 SQL 的 GROUP BY 每组只返回一行聚合值。但在面板数据(Panel Data)场景下,我们经常需要保持每组行数不变——比如计算每只股票的每日收益率排名。
-- 计算每只股票的日收益率
update stock set ret = ratios(price) - 1.0 context by sym;
-- 每天按收益率降序排名
select date, sym, ret, rank(ret, false) as daily_rank
from stock
where isValid(ret)
context by date;
-- 筛选每天收益率前3的股票
select date, sym, ret
from stock
context by date
having rank(ret, false) < 3;对比其他数据库: 同样的功能在 PostgreSQL/TimescaleDB 中需要用窗口函数(OVER(PARTITION BY ...)),语法更冗长且灵活性不如 context by。DolphinDB 的 context by 不仅可以在 SELECT 中使用,还能配合 UPDATE 修改数据,且支持任意表达式和计算字段。
(2)pivot by:一行代码搞定行列转换
-- 将股票数据转为透视表:每行一个日期,每列一只股票
exec price from stock pivot by date, sym;直接返回一个矩阵,非常适合后续的统计分析和可视化。在其他数据库中,这需要复杂的 CASE WHEN 或专门的 PIVOT 语法。
(3)asof join / window join:时序关联的杀手锏
不同频率的数据关联是时序分析中的经典难题。比如将10kHz的振动数据与1Hz的温度数据关联:
-- asof join:为每条交易找到最近一次报价
select sum(abs(price - (bid+ask)/2.0)*qty) / sum(price*qty) as cost
from aj(trades, quotes, `date`sym`time)
group by sym;
-- window join:查找交易前10毫秒内的报价,计算平均中间价
select sum(abs(price - mid)*qty) / sum(price*qty) as cost
from pwj(trades, quotes, -10:0,
<avg((bid + ask)/2.0) as mid>, `date`sym`time)
group by sym;性能数据: 同样的 asof join 操作,DolphinDB 比传统 JOIN 性能提升巨大。
3.3 SQL 与编程语言的无缝融合
这是 DolphinDB 最独特的设计——SQL 语句不是孤立的字符串,而是编程语言的一部分:
- SQL 中可以直接引用上下文变量和函数
- SQL 查询结果可以直接赋值给变量
- SQL 可以动态生成(元编程)
-- SQL中直接使用上下文中的字典变量
empNames = dict(1..10, `Alice`Bob`Jerry`Jessica`Mike
`Tim`Henry`Anna`Kevin`Jones)
select empNames[first(id)] as name, avg(wage)
from empWages
group by id;这种融合大幅减少了子查询和多表联结的需求,代码更简洁,性能更好。
四、编程语言评测:为数据分析而生的多范式语言
DolphinDB 内置了一门图灵完备的编程语言,支持四大编程范式。
4.1 向量化编程:性能的基础
向量化是 DolphinDB 最核心的编程范式,也是其高性能的根基:
// for循环:1000万次加法
c = array(DOUBLE, 10000000)
for(i in 0:10000000)
c[i] = a[i] + b[i]
// 向量化:一行搞定,快100倍以上
c = a + b滑动窗口计算的场景差异更明显:
// 逐窗口计算移动平均:4039ms
timer moving(avg, a, 60);
// 优化后的mavg函数:13ms
timer mavg(a, 60);增量计算优化将复杂度从 O(n*k) 降到 O(n),性能差距超过300倍。
4.2 函数式编程:简洁且强大
DolphinDB 支持自定义函数、Lambda函数、高阶函数和部分应用:
// 自定义函数 + Lambda过滤
def getWeekDays(dates){
return dates[def(x): weekday(x) between 1:5]
}
// 高阶函数:三行代码计算1000万条数据的相关性矩阵
priceMatrix = pivot(avg, price, time.minute(), syms)
retMatrix = each(ratios, priceMatrix) - 1
corrMatrix = cross(corr, retMatrix, retMatrix)这种函数式风格写出来的数据分析代码,简洁程度接近 Python pandas,但运行速度远超 pandas。
4.3 元编程:动态生成代码
DolphinDB 支持元编程,可以动态构建 SQL 查询:
def generateReport(tbl, colNames, colFormat, filter){
colCount = colNames.size()
colDefs = array(ANY, colCount)
for(i in 0:colCount){
if(colFormat[i] == "")
colDefs[i] = sqlCol(colNames[i])
else
colDefs[i] = sqlCol(colNames[i], format{,colFormat[i]})
}
return sql(colDefs, tbl, filter).eval()
}
// 动态生成报表
generateReport(t, ["id","date","price"],
["000","MM/dd/yyyy","00.00"],
< id < 5 or id > 95 >);这对于需要动态报表、参数化查询的业务场景非常实用。
4.4 分布式计算:在数据库内完成 MapReduce
DolphinDB 支持在分布式数据源上直接运行自定义的 MapReduce 和迭代计算:
// 自定义分布式线性回归
def myOLSMap(table, yColName, xColNames){
x = matrix(take(1.0, table.rows()), table[xColNames])
xt = x.transpose()
return xt.dot(x), xt.dot(table[yColName])
}
def myOLSFinal(result){
xtx = result[0]
xty = result[1]
return xtx.inv().dot(xty)[0]
}
// 在1000万行分布式数据上运行
myOLSEx(sqlDS(<select * from sample>), `y, `x1`x2);意味着:这类需要多轮迭代、矩阵运算的复杂计算,不需要把数据导出到外部工具,直接在数据库内的分布式数据源上就能完成。
graph LR
A[传统方案] --> A1[数据库<br>只做存储]
A1 --> A2[导出数据到<br>Python/Spark]
A2 --> A3[训练模型]
A3 --> A4[部署到<br>推理服务]
A4 --> A5[对接回<br>数据库]
B[DolphinDB] --> B1[存储 + 计算<br>+ 分析 + ML]
B1 --> B2[库内直接完成<br>全链路闭环]
style A fill:#ffcccc,stroke:#cc3333,color:#333
style A1 fill:#ffcccc,stroke:#cc3333,color:#333
style A2 fill:#ffcccc,stroke:#cc3333,color:#333
style A3 fill:#ffcccc,stroke:#cc3333,color:#333
style A4 fill:#ffcccc,stroke:#cc3333,color:#333
style A5 fill:#ffcccc,stroke:#cc3333,color:#333
style B fill:#d4edda,stroke:#28a745,color:#333
style B1 fill:#d4edda,stroke:#28a745,color:#333
style B2 fill:#d4edda,stroke:#28a745,color:#333五、横向对比:DolphinDB vs InfluxDB vs TimescaleDB
作为开发者,我最关心的不只是官方的宣传数据,而是日常开发中的真实体验差异。以下是我基于两周使用体验的对比:
5.1 SQL与查询能力
对比维度 | DolphinDB | InfluxDB | TimescaleDB |
|---|---|---|---|
SQL标准兼容 | SQL-92 + Oracle/MySQL方言 | Flux(类SQL但非标准) | 完整PostgreSQL SQL |
时序聚合函数 | 2000+内置,覆盖极广 | 基础聚合函数 | 依赖PostgreSQL函数 |
面板数据处理 | context by 原生支持 | 需Flux脚本 | 窗口函数,较冗长 |
多频数据关联 | asof join / window join | Flux pivot/join | 需复杂SQL |
动态SQL | 元编程支持 | 不支持 | PL/pgSQL |
SQL中调用函数 | 自定义函数直接可用 | Flux函数 | PL/pgSQL UDF |
5.2 计算与分析能力
对比维度 | DolphinDB | InfluxDB | TimescaleDB |
|---|---|---|---|
内置编程语言 | 图灵完备,多范式 | Flux脚本 | PL/pgSQL |
向量化计算 | 原生支持,SIMD优化 | 不支持 | 不支持 |
流批一体 | 一套代码处理实时+历史 | Flux Tasks(有限) | Continuous Aggregates |
内置机器学习 | 库内ML + libTorch/XGBoost插件 | 不支持 | 需MADlib扩展 |
分布式计算 | 原生MapReduce | 企业版支持 | 需Citus扩展 |
滑动窗口优化 | 增量计算 O(n)→O(1) | 基础窗口函数 | 标准窗口函数 |
5.3 开发者生态
对比维度 | DolphinDB | InfluxDB | TimescaleDB |
|---|---|---|---|
Python SDK | ✅ 官方,支持pandas/Arrow | ✅ 官方 | ✅ SQLAlchemy |
开发工具 | VS Code / Web / GUI | Chronograf / CLI | pgAdmin / DBeaver |
中文文档 | ✅ 完善 | 一般 | 英文为主 |
学习曲线 | 中等(需学脚本语言) | 中等(Flux语法独特) | 低(标准SQL) |
社区规模 | 快速增长,国内活跃 | 全球活跃 | 全球活跃 |
5.4 综合评分
维度 | DolphinDB | InfluxDB | TimescaleDB |
|---|---|---|---|
SQL能力 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ |
计算性能 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ |
分析深度 | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐ |
易上手度 | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
生态丰富度 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
流处理能力 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ |
综合 | 92 | 72 | 80 |
六、实战案例:用 DolphinDB 计算金融Alpha因子
纸上得来终觉浅。我用一个实际的金融量化场景来验证 DolphinDB 的开发效率——计算 WorldQuant 的 98 号 Alpha 因子。
6.1 场景背景
WorldQuant 在论文《101 Formulaic Alphas》中提出了101个量化因子。其中98号因子需要同时使用纵向时间序列指标的嵌套和横向截面数据的排序信息。
某基金公司用 C# 实现需要数百行代码,在3000+股票10年900万行数据上耗时约30分钟。
6.2 DolphinDB 实现:4行核心代码,2秒完成
def alpha98(stock){
t = select code, valueDate, adv5, adv15,
open, vwap
from stock
order by valueDate
update t set rank_open = rank(open),
rank_adv15 = rank(adv15)
context by valueDate
update t set decay7 = mavg(mcorr(vwap, msum(adv5, 26), 5), 1..7),
decay8 = mavg(mrank(9 - mimin(mcorr(rank_open,
rank_adv15, 21), 9), true, 7), 1..8)
context by code
return select code, valueDate,
rank(decay7) - rank(decay8) as A98
from t
context by valueDate
}效果: 同样的数据和逻辑,DolphinDB 用4行核心代码、2秒钟完成——接近三个数量级的效率提升。
这个例子很好地体现了 DolphinDB 的核心优势:
context by一行搞定面板数据分组mavg / mcorr / msum等函数原生支持滑动窗口rank()在分组内直接使用- 向量化计算 + 增量优化,性能碾压逐行处理
七、客观评价:优点与局限
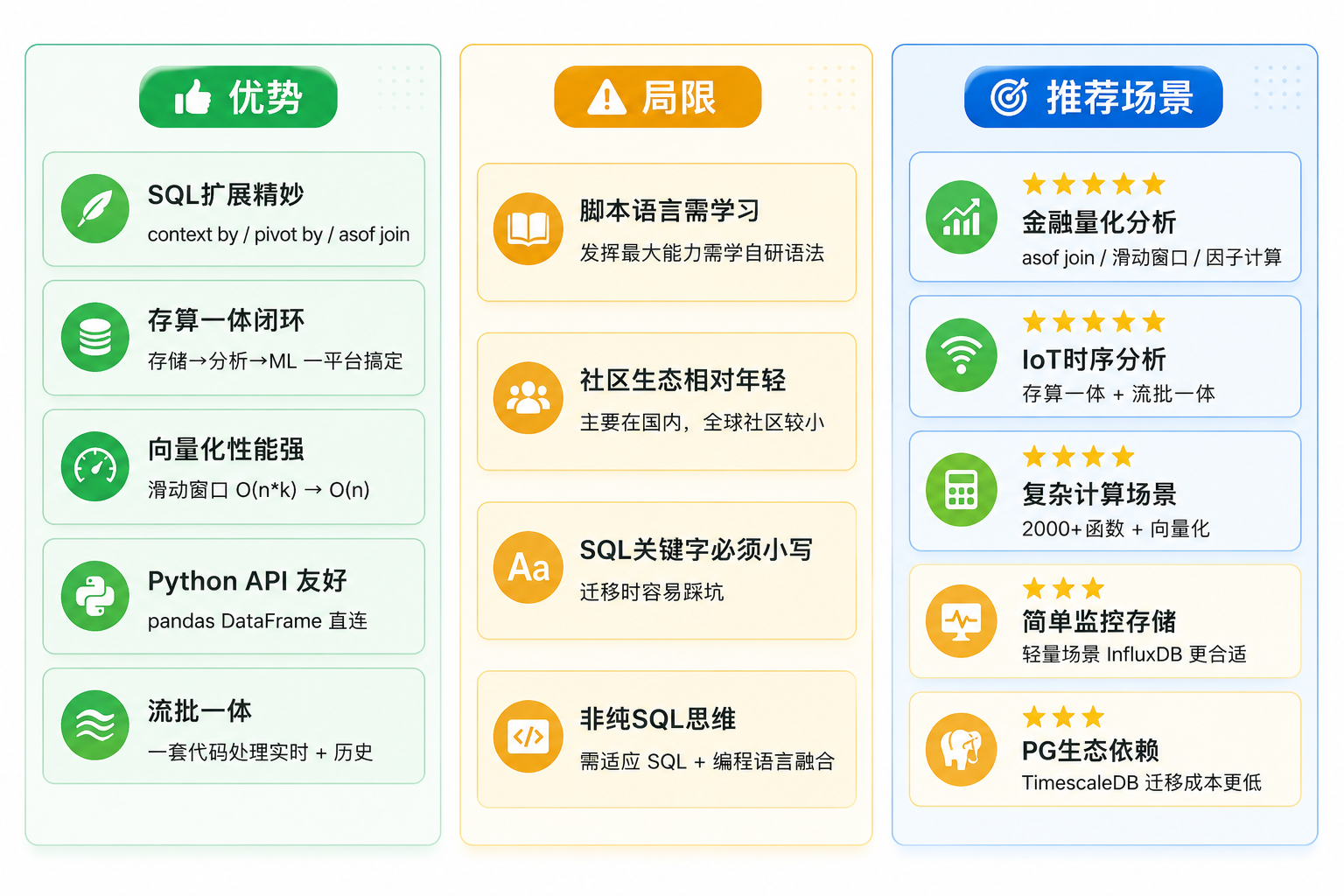
7.1 我认可的优势
- SQL 扩展设计精妙:
context by、pivot by、asof join这些扩展直击时序分析痛点,用过就回不去 - 存算一体不是噱头:从存储到复杂分析到机器学习,真的可以在一个平台内闭环完成
- 向量化性能确实强:滑动窗口增量计算从 O(n*k) 降到 O(n),不是理论优化,是实打实的性能提升
- Python API 友好:对 Python 开发者来说,pandas DataFrame 直接交互,学习成本低
- 流批一体的设计理念先进:一套代码处理历史和实时,这在其他时序数据库中很少见
7.2 需要注意的局限
- 脚本语言需要学习:虽然支持标准 SQL,但发挥最大能力需要学习 DolphinDB 自有的脚本语法,有一定学习曲线
- 社区和生态相对年轻:相比 InfluxDB 和 TimescaleDB 背后的全球社区,DolphinDB 的社区主要在国内
- SQL 关键字必须小写:这个细节容易踩坑,从其他数据库迁移时需注意
- 非纯SQL思维:习惯了"SQL就是SQL"的开发者,可能需要适应 SQL 与编程语言深度融合的设计理念
7.3 适用场景推荐
你的场景 | 推荐度 | 理由 |
|---|---|---|
金融量化分析 | 强烈推荐 | asof join、滑动窗口、因子计算天然适配 |
IoT 时序数据分析 | 强烈推荐 | 存算一体 + 流批一体,告别数据搬运 |
需要复杂计算的分析场景 | 推荐 | 2000+函数 + 向量化,库内完成全链路 |
简单监控指标存储 | 视情况 | 如果只需简单存取,InfluxDB 部署更轻量 |
已有PostgreSQL生态深度依赖 | 视情况 | TimescaleDB 可能迁移成本更低 |
八、总结
两周体验下来,DolphinDB 给我的感觉是——它不是在做一个"更好的时序数据库",而是在重新定义"数据开发"的方式。
传统模式下,我们写 SQL 存数据,写 Python 分析数据,写 Java 处理流数据,再搭一套平台部署模型。四套技术栈、四个团队、四份维护成本。
DolphinDB 的答案很简单:一个平台,一门语言,一套代码,搞定从存储到分析到流处理到机器学习的全链路。
核心结论:
- 如果你需要的是一个简单的时序数据存储,InfluxDB 或 TimescaleDB 可能更轻量
- 但如果你面临的是复杂的时序分析、多频数据关联、流批一体的计算需求,DolphinDB 的能力远超同类产品
- 特别是对金融量化和工业IoT场景的开发者来说,DolphinDB 值得认真评估
从开发者的角度,DolphinDB 最让我欣赏的是它的"效率哲学"——用更少的代码、更少的系统、更少的搬运,完成更多的工作。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号