数据智能体:范式革新还是过度炒作?

数据智能体:范式革新还是过度炒作?

梯度不陡
发布于 2026-05-18 19:49:18
发布于 2026-05-18 19:49:18
当企业深陷数据沼泽,90%的决策仍依赖人工梳理时,“数据智能体”概念正以救世主姿态席卷市场。但这项研究揭示残酷真相:混乱的术语体系正让行业陷入信任危机——用户分不清AI建议是神器还是陷阱,供应商在责任纠纷中相互推诿。该论文首次提出类似自动驾驶的分级标准,为迷雾中的市场建立能力标尺,让企业能精准匹配需求与系统能力,打破炒作循环。
引言:数据智能体,AI新风口还是概念泡沫?
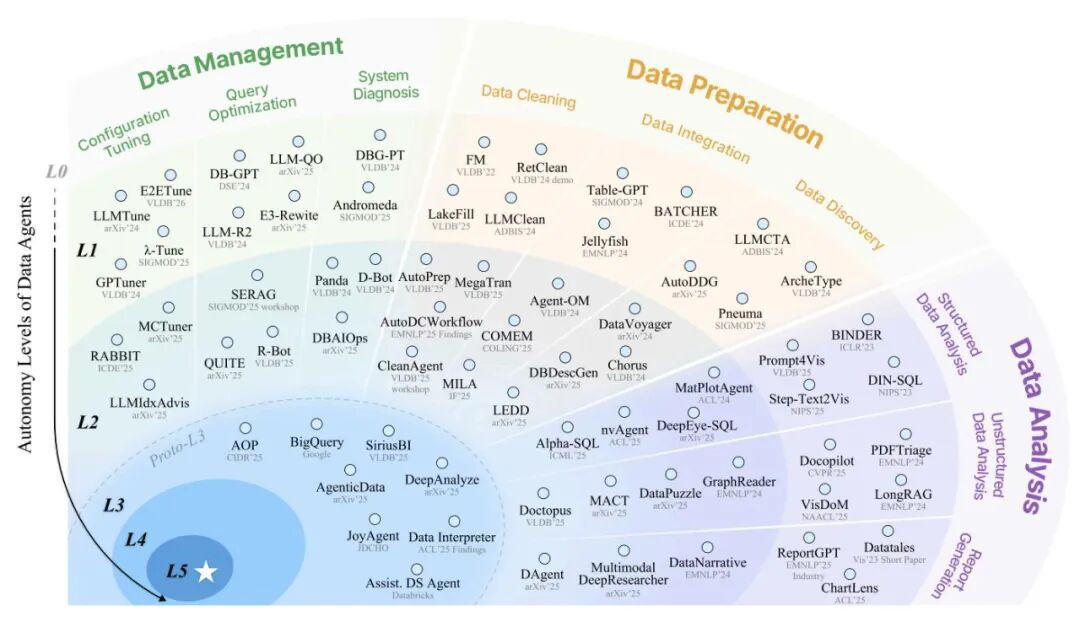
当前“数据智能体”市场存在显著的能力差异,同一标签下可能涵盖从简单脚本助手到全自主数据科学家的不同层级产品。术语的滥用正引发三类现实风险:用户误判能力边界可能造成决策失误,权责模糊在数据泄露等事件中导致责任归属困难,行业虚火则阻碍技术本身的持续进步。针对这一现状,作者提出L0-L5六级分类框架,借鉴自动驾驶的分级逻辑,首次为数据智能体建立统一的能力评估体系。该框架通过明确界定自主性边界与责任归属,旨在帮助企业更精准地匹配技术方案与业务需求,并为行业监管与技术评估提供可参照的标准语言。
为什么需要重新定义数据智能体
当前数据智能体领域存在显著的术语模糊问题,同一术语被不加区分地用于描述自主性、可靠性和复杂性差异巨大的各类系统。这种定义混淆导致功能单一的原子任务助手与能够自主探索数据湖、调用外部工具的复杂智能系统被混为一谈,对用户认知、治理框架与产业发展均构成潜在风险。
用户层面,术语模糊直接引发期望错配。用户难以准确识别不同数据智能体的能力边界,可能低估其功能或过度信赖错误结果,进而作出基于误导性洞察的决策。
治理方面,期望错配进一步放大了责任归属的难题。当数据智能体在能力范围之外运行,导致数据泄露、隐私侵犯或报告错误时,责任界定模糊不清。这种模糊性削弱市场信心,延缓技术的大规模采纳。
产业层面,用户误解与责任模糊共同形成发展瓶颈。缺乏基于自主性与责任的统一分类体系,阻碍系统间的客观比较,助长夸大宣传与市场混乱,进一步加剧用户期望与治理责任之间的恶性循环,制约技术迭代与市场成熟。
核心突破:L0-L5分级分类法
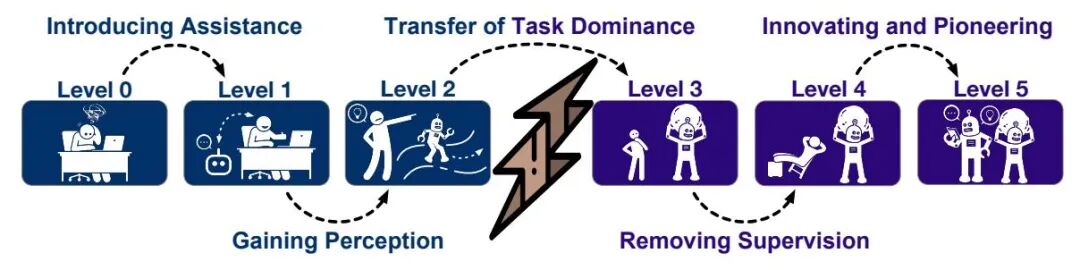
该论文提出的L0-L5分级分类法构建了一套用于评估数据智能体自主性的清晰框架。这一层次化分类体系将自主性划分为六个递进等级,每个级别对应明确的能力边界与责任归属。
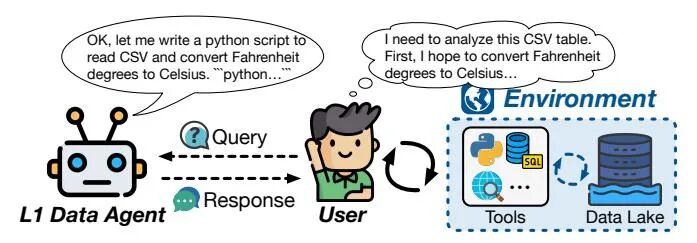
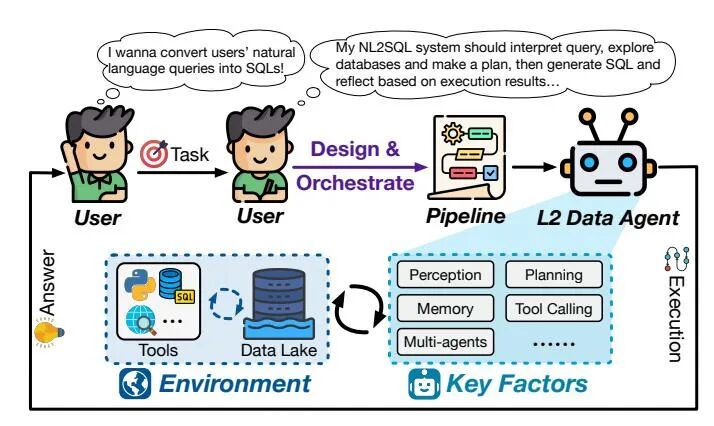
在L0级别,所有数据任务完全依赖人工执行。L1级别的智能体作为初级助手,在无状态提示-响应框架下运行,可生成代码或提供建议,但无法感知环境。L2级别实现部分自主,智能体具备环境感知能力,能够连接数据湖并调用外部工具,在人类设定的流程中执行程序。
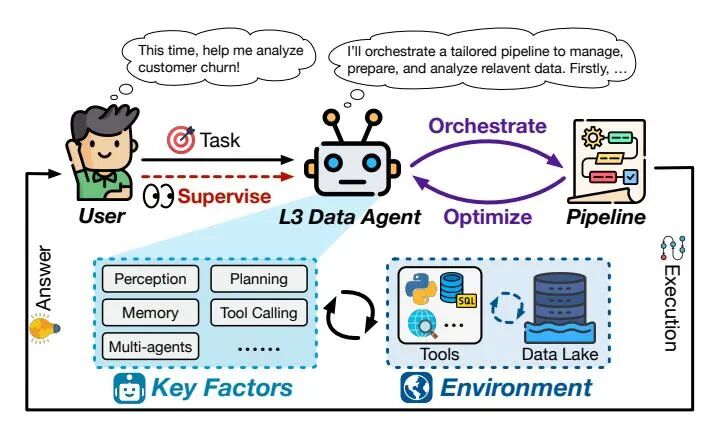
L3级别标志着条件自主,数据智能体可自主编排定制化数据管道,在人类监督下处理多样化任务。L4级别达到高度自主,智能体具备持续自我治理能力,主动监控数据生态系统以识别并解决问题,无需人类介入。L5级别代表完全自主,智能体能够创新方法论并开创全新范式,推动数据管理、准备与分析领域的进步。
该框架的核心价值在于揭示了责任转移的渐进路径:随着自主性等级提升,人类角色从操作者逐步过渡为监督者与旁观者,最终实现完全退出;数据智能体则从辅助工具逐步进化为完全自主的数据科学家。
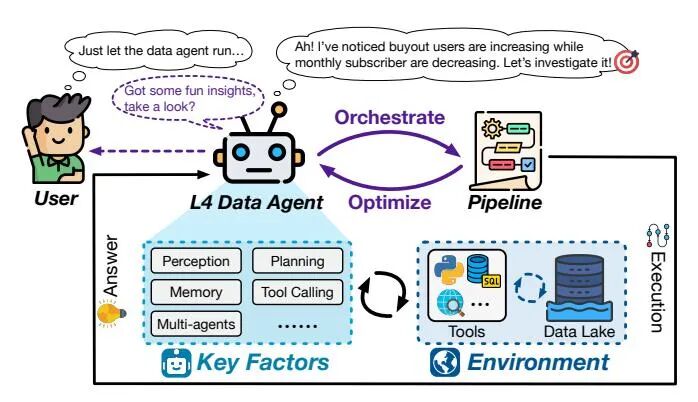
各层级智能体如何进化
数据智能体的进化遵循从L0到L3的阶梯路径,其核心是自主性的逐级跃迁。每一次层级跨越都伴随着关键能力的质变与人类角色的结构性转移。
在从L0无自主性到L1辅助智能的首次跨越中,智能体实现了从无到有的突破。作为初步助手,L1智能体依赖提示-响应机制生成代码或建议,但其无状态特性使其无法感知环境,所有输出仍需人工整合与验证。
从L1到L2部分自主的跃迁,关键在于环境感知能力的建立。L2智能体能够连接数据湖、代码解释器等外部资源,借助执行反馈与记忆机制自适应优化行为。它们进化为流程执行者,可在预设管道中自主完成任务,但整体工作流的编排主导权仍由人类掌握。
从L2到L3条件自主的跨越具有革命性意义,实现了任务主导权的根本转移。L3智能体不再仅是执行者,而是进化为全能主导者,能够理解高级用户意图,并自主编排端到端管道以完成广泛的数据任务。人类角色在此阶段转变为监督者,仅在关键节点介入,标志着数据智能体真正自主时代的来临。
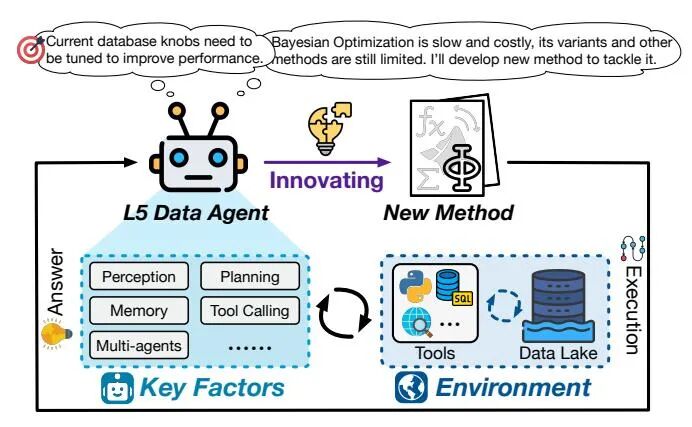
未来愿景:L4-L5的终极形态
数据智能体的终极形态被定义为L4至L5两个阶段,其核心是从条件自主向主动自治乃至生成式创新的根本跨越。L4级智能体被设计为高度自主的系统,能够在无人监督下主动发现问题并自主编排端到端的数据流水线。这依赖于可信自治理与长周期规划等关键能力,使其从被动执行者转变为数据湖中的主动探索者。
实现L4智能体的技术挑战集中在自主问题发现与可信自治理两大方向。前者要求智能体具备批判性推理和任务导向意识,以识别数据中的异常与潜在价值;后者则需其成为可靠的通才,全面掌握数据全生命周期,并在资源与安全层面建立无需人工介入的信任基础。此外,长视野决策能力支持其进行跨流程的战略权衡。
L5作为完全自主的终极阶段,其标志是生成式创新能力。该级智能体不再局限于既有方法,而是能够创造新理论、算法与分析范式,例如为高速数据流设计全新采样理论,或构建面向特定场景的联邦数据准备框架。这要求智能体具备深刻的元认知能力,以识别现有技术边界并主动推进知识创造。
迈向L4与L5的研究仍需突破内在动机、长周期规划及鲁棒安全保障等根本挑战。尽管完全实现尚属长期目标,推动智能体在数据湖中实现长期自治,已成为通往最终愿景的关键路径。
结语:数据智能体的标准化之路
该论文提出了首个数据智能体分级标准,构建了统一的能力评估框架,为行业技术迭代与产品对标提供了基准依据。当前分类体系仍面临跨场景适用性不足与量化指标缺失等挑战,亟需社区协作完善标准细节。作者指出,未来应重点推进多平台验证与性能基准建设,推动分级体系从理论规范转化为行业通用工具。当数据智能体能够被精确分级时,整个产业链的协同效率与资源匹配精度将实现显著提升。
论文地址:https://arxiv.org/abs/2510.23587 开源地址:https://github.com/HKUSTDial/awesome-data-agents
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-11-03,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号