AI 时代工程师的新核心竞争力


AI 时代工程师的新核心竞争力
摘要:当 AI agent 可以自主写出 100 万行代码,工程师的价值究竟在哪里?OpenAI 内部实验给出了一个颠覆性答案:工程正在从「写代码」转向「设计 Harness」——即让 agent 能够安全、自主运转的环境、约束与反馈循环。
引言:一个让工程师沉默的数字
100 万行代码。
不是团队写的,是 AI agent 写的。
2025 年 8 月底(距今约半年),OpenAI 内部启动了一个极端实验:零人类编写代码,完全由 Codex agent 自主完成一个有真实日常用户的产品。结果?从空仓库出发,大约 100 万行代码,比手动开发快了约 10 倍(该数据为 Harness 成熟阶段与估算人工开发速度的对比,不含前期 Harness 建设投入)。单个执行计划运行超过 7 小时,单次 agent run 常常持续 6 小时以上。
这组数据放出来,我相信很多工程师的第一反应是:"我们是不是要失业了?"
但如果你认真读完 OpenAI 工程团队的复盘,会发现一个更有意思的结论:
工程师没有被取代,工程师的工作「升维」了。
读完本文,你应该能回答:如果让你从零搭一个 Harness,第一步做什么。
背景:Codex agent 是怎么工作的?
在展开五大原则之前,先建立一个基本认知模型。
Codex agent 不是一个简单的「输入需求、输出代码」的命令行工具。它更像一个自主运转的工程师:拥有自己的工作树(worktree)、可以运行测试、可以查日志、可以截图调试界面、甚至可以自己写 linter。
但 agent 有一个致命弱点:它只能看到它被允许看到的东西。
这就引出了「Harness」这个概念。
Harness 的字面意思是「马具/线束」——给马套上马具,马才能拉车而不乱跑。在 AI 工程的语境里,Harness 就是让 agent 能够安全、自主、可预期地工作的整套环境设计:包括知识组织方式、约束机制、观测手段和反馈循环。
Harness 的四个层次:
- 知识层 —— ARCHITECTURE.md / AGENTS.md / ADR,提供上下文
- 计划层 —— PLANS.md,描述任务目标与决策依据
- 执行层 —— Agent 独立工作树 + 工具链,完成具体任务
- 反馈层 —— Tests / Linters / 可观测性,形成闭环校正
好,背景铺完了。下面进入核心——OpenAI 总结的五大 Harness 工程原则。
第一原则:「看不到,就不存在」
知识必须是仓库原生的
有一个问题每个工程团队都遇到过:为什么新人上手这么慢?
答案几乎是一样的:关键知识藏在老员工脑子里、散落在 Slack 消息里、埋在几年前的 Google Doc 里。
对人类工程师来说,这已经够痛了。对 agent 来说,这是致命的。
Agent 只能处理它能「看到」的信息。埋在 Slack 里的决策,对 agent 来说等于不存在。
OpenAI 的解法非常直接:所有决策,推入仓库。
- PLANS.md:每个执行计划保存在这里,必须「自包含」——任何一个初学者拿到这份文档,不需要额外背景知识就能理解这个计划要做什么、为什么这么做。
- ARCHITECTURE.md:这是地图,不是手册。它描述系统的整体结构和边界,而不是操作细节。
知识在哪里,决定了 agent 能走多远:
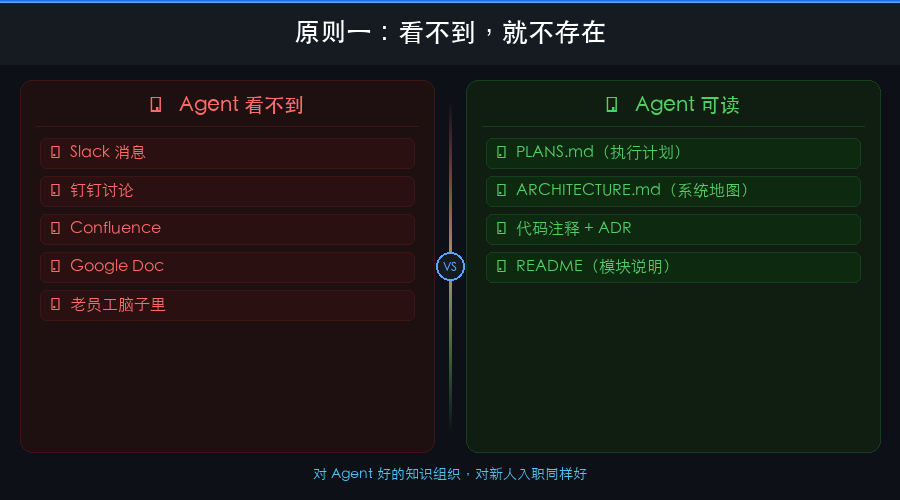
❌ Agent 看不到(对 agent 等于不存在)
- Slack 消息、钉钉讨论
- Confluence / Google Doc
- 老员工脑子里的经验
✅ Agent 可读(可执行知识)
- PLANS.md(执行计划,自包含)
- ARCHITECTURE.md(系统地图)
- 代码注释 + ADR(架构决策记录)
这个原则有一个很妙的副作用:对 agent 好的知识组织方式,对新入职的人类工程师同样好。 Harness 强,新人上手快;Harness 弱,新人漂移,agent 也漂移。
对我们的启示:你团队的 Wiki 里有多少「孤儿文档」?有多少关键决策只存在于某个人的微信里?这不只是 AI 时代的问题,这本来就是工程债。
原则一:看不到就不存在——知识可见性对比
第二原则:别说「努力一点」,要问「缺了什么能力」
修复 Harness,而不是优化 Prompt
当 agent 输出结果不符合预期,工程师的第一反应往往是:改 prompt,让 agent 更努力一点。
OpenAI 的结论是:这是错误的思维模式。
正确的问题是:「这个任务缺失了什么环境支持(affordances)?」
举个例子:如果 agent 在处理并发任务时总是出错,不是因为它「不够聪明」,而是因为它缺乏合适的并发调试工具。OpenAI 的做法是自研一个与 OpenTelemetry 集成的并发追踪工具,直接把可观测能力注入 agent 的工作环境。
❌ 错误思路:「让我来优化一下这段 system prompt,告诉 agent 要更加小心地处理并发……」 ✅ 正确思路:「agent 看到的并发上下文是什么?它有没有办法 trace 到具体是哪个 goroutine 出了问题?」→ 补充 OpenTelemetry 集成工具,让 agent 可以直接查 trace。
这里还有一个很有意思的工程哲学:「无聊的技术往往更好」。
当你在为 agent 设计 Harness 时,优先选择有稳定 API、有清晰训练信号的成熟技术,而不是追求最新最酷的工具。举个反例:如果 agent 的工具链使用某个新兴的私有 trace SDK,其 API 在训练数据中出现极少,agent 调用时很可能产生幻觉,给出根本不存在的方法名;而 OpenTelemetry 被写进了无数开源项目和技术博客,对 LLM 来说是「熟悉的语言」——它知道该怎么用,不会猜。
这对国内工程师有一个很直接的建议:为 agent 工具链选型时,优先考虑 GitHub star 数多、文档完善、有大量中英文教程的技术栈。 不是因为它们技术上一定最优,而是因为它们在 LLM 的训练数据里出现频率最高,agent 驾驭它们的能力最稳定。Prometheus、OpenTelemetry、gRPC——这些「老派」选择,在 AI 工程时代反而成了优势。
第三原则:一致性来自机械约束,不来自叙事指导
让构建失败,比写文档更可靠
每个团队都有架构规范文档。每个团队也都有不遵守架构规范的代码。
问题不是工程师不认真,问题是文档是被动的,违规是主动的。
OpenAI 的解法是:把架构约束变成机械执行的规则。
他们固定了一套严格的分层架构,依赖方向只能单向流动:
Types → Config → Repo → Service → Runtime → UI UI 层不能直接调用 Repo 层。 不是文档里写了这条规则,而是 CI 会失败。不是 PR review 里有人提醒,而是 linter 直接报错。
更妙的是:这些 linter 本身是由 Codex 自己写的。
agent 写规则 → 规则约束 agent → agent 在规则内工作 → agent 继续完善规则。这是一个自举的(bootstrapped)约束循环:
Codex 编写 linter 规则 → 规则进入 CI 流水线 → Codex 提交代码,CI 自动验证 → 通过:合并入主干;失败:Codex 收到反馈,修复后重试 → Codex 在执行中发现新的架构问题 → 回到起点,继续完善规则
还有一个值得单独拎出来的设计细节:架构不变量常通过「缺席」来定义。
「Service 层不存在数据库连接」这条规则,不是写在文档里说「不应该连数据库」,而是通过让 database/sql 的 import 在 service 包里触发 linter 报错来强制执行。文档描述「存在什么」,linter 保证「不存在什么」。这是一种非常高效的约束表达方式——负面规则用自动化执行,正面规则用文档描述。
让构建失败的规则,比 1000 字的架构说明文档,更能保证代码一致性。
这个原则对我们的启发非常直接:有多少架构规范只存在于 README 里,而没有对应的 CI 检查?

原则三:固定分层架构,依赖单向流动
第四原则:给 Agent 眼睛——可观测性是一等公民
Agent 不是盲人,但你得给它装上眼睛
想象一下,你让一个程序员在一个完全没有日志、没有监控、没有调试工具的环境里工作。他能干活,但他会很痛苦,而且很容易出错。
Agent 也一样。
OpenAI 的做法是:把 Chrome DevTools Protocol(CDP)直接集成到 agent 运行时。
这意味着 agent 可以检查 DOM 结构、截图当前界面状态、对比前后两个状态的差异。
不只是前端。他们还给 agent 配备了完整的可观测性栈:
Agent 的「眼睛」:
- Chrome DevTools Protocol (CDP)
- DOM 检查、截图对比、网络请求追踪
- LogQL(Loki 日志查询)
- Agent 直接写查询语句,读取运行日志
- PromQL(Prometheus 指标查询)
- Agent 直接查指标,验证性能要求是否满足
- 关键设计:每个工作树有独立的临时可观测栈
- ephemeral per-worktree observability,多个 agent 并行互不干扰
特别值得一提的是「临时可观测栈」这个设计:每个 agent 工作树都有自己独立的观测环境,互不干扰。这就像每个工程师都有自己的开发环境,而不是共用一套测试环境互相踩脚。
还有一个细节让我印象深刻:「startup < 800ms」这类性能要求,变得可执行了。
以前这是 PR 描述里的一句话,没人验证;现在 agent 可以直接查 PromQL,看 p99 启动时间是不是真的小于 800ms。需求从「叙述」变成了「断言」。

原则四:给 Agent 眼睛——可观测性栈
第五原则:文档不是写完就完了,它有生命周期
建立文档的「保鲜机制」
第一原则解决的是知识的可见性问题——把知识放进仓库,让 agent 能看到。
第五原则解决的是另一个同样严峻的问题:文档的腐烂。
代码每天都在变,文档却往往停在某个历史快照里。这种「文档腐烂」(documentation rot)对人类工程师是干扰,对 agent 是毒药——agent 会认真地读那些已经过期的说明,然后认真地做出错误的决策。
OpenAI 的解法是把文档的生命周期管理自动化,其中最有趣的实践是文档园艺 agent(Documentation Gardening Agent)。
这个 agent 的核心职责是「对抗文档腐烂」:
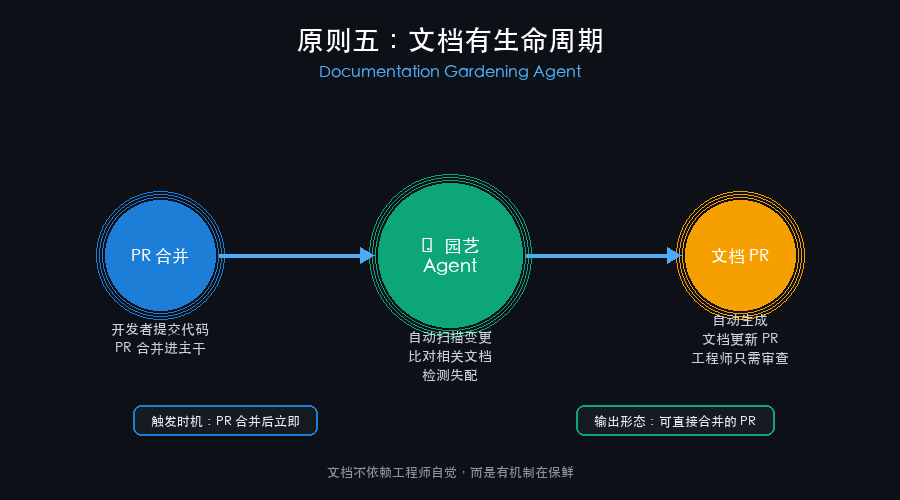
每当一个 PR 被合并,文档园艺 agent 会自动扫描本次变更涉及的代码路径,与仓库中的文档(ARCHITECTURE.md、AGENTS.md、各模块的 README、内联注释)进行交叉比对,检测是否存在「代码变了、文档没更新」的失配情况。
一旦检测到失配,它不是发出一条警告通知然后等工程师处理——它会自动生成一个文档更新 PR,把受影响的段落草稿好,让工程师只需要审查和合并,而不是从零写更新。
这个设计有两个关键:
- 触发时机:PR 合并后立即触发(而不是定时批量扫描),确保文档更新与代码变更紧密耦合,失配窗口被压缩到最短。
- 输出形态:一个可以直接审查的 PR(而不是 TODO 列表或 Slack 通知),把「写文档」这件事的摩擦力降到最低——工程师的动作从「打开编辑器写文档」变成「审查一个 diff 然后点合并」。
结果是:文档的新鲜度不再依赖工程师的自觉性,而是有一个持续运转的自动化机制在维护。仓库里的知识不会越来越腐烂,反而随着每次 PR 持续被校准。
OpenAI 的核心文档结构也极其简洁,每类文档职责清晰:
- AGENTS.md = 目录(这个仓库里有哪些 agent,各自负责什么)
- ARCHITECTURE.md = 地图(系统的边界和分层,不是操作细节)
- PLANS.md = 执行计划(当前在做什么,为什么这么做)
类比:好的仓库文档像一个有人定期修剪的花园——不是建了就不管,而是有专门的「园艺 agent」在负责保鲜。
原则五:文档园艺 Agent——对抗文档腐烂
完整循环:Harness 是一个飞轮
把五大原则串起来,你会看到一个完整的飞轮:
Harness 飞轮的五个节点:
- 知识层 —— ARCHITECTURE.md / AGENTS.md 提供上下文与边界
- 计划层 —— PLANS.md 描述当前任务目标与决策依据
- 执行层 —— Agent 在独立工作树中完成具体任务
- 约束层 —— Tests + Linters 机械验证一致性,CI 强制执行
- 观测层 —— LogQL / PromQL / CDP 提供真实运行反馈
节点 5 的观测结果,反哺节点 1 的知识更新,飞轮转动。
每一圈循环,Harness 都变得更强:
- Agent 跑完任务,更新 PLANS.md → 知识层更丰富
- Tests 发现新的边界情况 → Linter 规则更完善
- 可观测数据揭示新的性能瓶颈 → 下一轮执行计划更精准
Harness 弱,agent 漂移;Harness 强,agent 收敛。
这是这整篇文章最核心的一句话。

Harness 飞轮:五层完整循环
对工程师的三大启示
读完这些,我想直接说三件事:
1. 你的价值在于「设计环境」,不在于「敲键盘」
这不是「AI 取代程序员」的故事,这是「程序员的杠杆点在移动」的故事。
以前,工程师的产出 = 写出的代码行数(夸张说法)。 现在,工程师的产出 = 你设计的 Harness 让 agent(或其他工程师)产出了多少代码。
这是从直接劳动到环境设计的迁移。越早理解这个转变,越早建立竞争优势。
今天就能做的第一步:把你们团队下一个技术决策的理由,写在 PR 描述里——哪怕只是一段话。
2. 知识管理不是软技能,是硬基础设施
很多工程师把「写文档」看成可有可无的事情。在 AI agent 工程时代,这是在挖坑。
仓库里没有的知识,对 agent 不存在;对新入职的工程师,也几乎不存在。
从现在开始,把 ADR(架构决策记录)写进仓库,把重要的设计讨论从 Slack 搬到 PR 描述里,把口口相传的约定变成 linter 规则。
今天就能做的第一步:在项目根目录创建一个 ARCHITECTURE.md,写清楚「不允许做什么」,比写「应该做什么」更有价值。
3. 「机械强制」比「叙事指导」更靠谱
下次当你想在 README 里加一条「规范」的时候,先问自己:能不能把这条规范变成一个 CI 检查?
如果能,就写成 CI 检查,README 里只需要一句话解释为什么。 如果不能,先写文档,但把「把它变成自动化检查」加入技术债列表。
今天就能做的第一步:把一条最重要的架构规则写成 lint 规则或单测,让构建失败来执行它,而不是靠 code review 时口头提醒。
总结:工程的本质没有变,变的是工作层次
工程的本质,一直都是在约束中交付价值。
以前,约束是语言特性、框架限制、团队规范;工程师在这些约束里写代码。 现在,工程师开始设计约束本身——为 agent 构建可以安全运转的环境。
OpenAI 用 100 万行代码证明了:当 Harness 足够强,agent 可以完成极其复杂的工程任务,速度快出一个数量级。
但 Harness 不会自己生长。它需要工程师去设计、去维护、去进化。
那些能设计出好 Harness 的工程师,才是 AI 时代最稀缺的人才。
如果让我回答从零搭一个 Harness 的第一步,我会说:打开编辑器,新建一个 ARCHITECTURE.md,写下两件事:这个系统的分层结构是什么,以及哪些事情是被明确禁止的。 这一张地图,就是你 Harness 的第一块砖。
如果你觉得这篇文章有价值,欢迎转发给你的团队。也欢迎在评论区分享你们团队在 AI agent 工程化方面的实践和踩坑经验。
本文内容整理自 OpenAI 官方博客 https://openai.com/index/harness-engineering/ ,数据与案例均来自原文。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-20,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号