手把手教你:本地搭建飞书机器人(支持私聊+群聊@回复)


📋 前言
飞书机器人可以实现自动回复、消息转发、数据查询等功能,广泛应用于企业通知、客服助手、日程提醒等场景。随着大模型时代的到来,在群聊中通过机器人/小助手形式智能解答问题的场景也越来越多,本篇就通过详细的操作演示,无需公网IP和服务器,让你在本地电脑上快速搭建一个自己的飞书智能助手。全程有 AI 助手(WorkBuddy)协助分析与生成代码,零基础也能完成!
✅ 本文方案优势:
- WebSocket长连接 - 无需公网IP
- 本地运行 - 数据更安全
- 支持私聊+群聊 - @机器人智能回复
- 个性化配置 - 根据用户身份定制回复
- AI 全程协助 - WorkBuddy 帮你分析问题、生成代码、排查错误
🛠️ 环境准备
本文环境:
- 本地系统环境:macOS 15.6.1 (Sequoia)
- Python版本:3.12.7
1. 安装Python环境
# Mac用户(推荐)
brew install python3
# 检查版本(需要 3.8+)
python3 --version2. 安装飞书SDK
pip3 install lark-oapi3. 创建项目目录
mkdir feishu-bot
cd feishu-bot环境准备完毕,接下来创建飞书机器人应用 👇
🤖 我的助手:WorkBuddy
本文的实战代码和排查过程,全部由 WorkBuddy(一款 AI 编程助手)协助完成。 从分析
callback_type配置错误,到生成ws_bot.py完整代码,再到排查CreateMessageRequest导入错误 —— AI 助手让搭建过程从"踩坑2天"变成"30分钟完成"。 WorkBuddy 官网:https://www.workbuddy.ai
以下是实际操作步骤:
🤖 第一步:创建飞书机器人应用
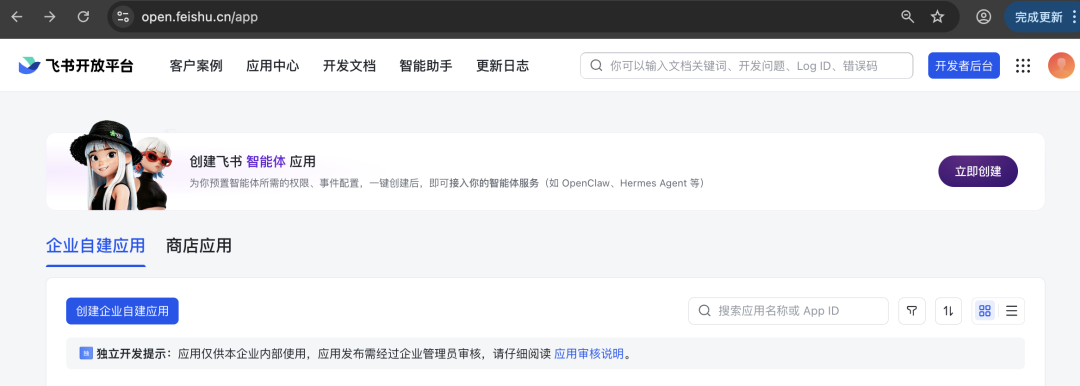
1. 进入飞书开放平台
访问:https://open.feishu.cn/app
- 点击 "创建企业自建应用"
- 填写应用名称(如:我的智能助手)
- 上传应用图标(可选)
- 点击 "创建"
2. 获取凭证
创建完成后,在 "凭证与基础信息" 页面找到:
App ID: cli_xxxxxxxxxxxxxxxxxx
App Secret: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx⚠️ 重要:保存好这两个值,后续代码中需要用到!
3. 配置应用权限
进入 "权限管理",开启以下权限:
获取与发送单聊消息💡 开启权限后,记得点击"保存"!
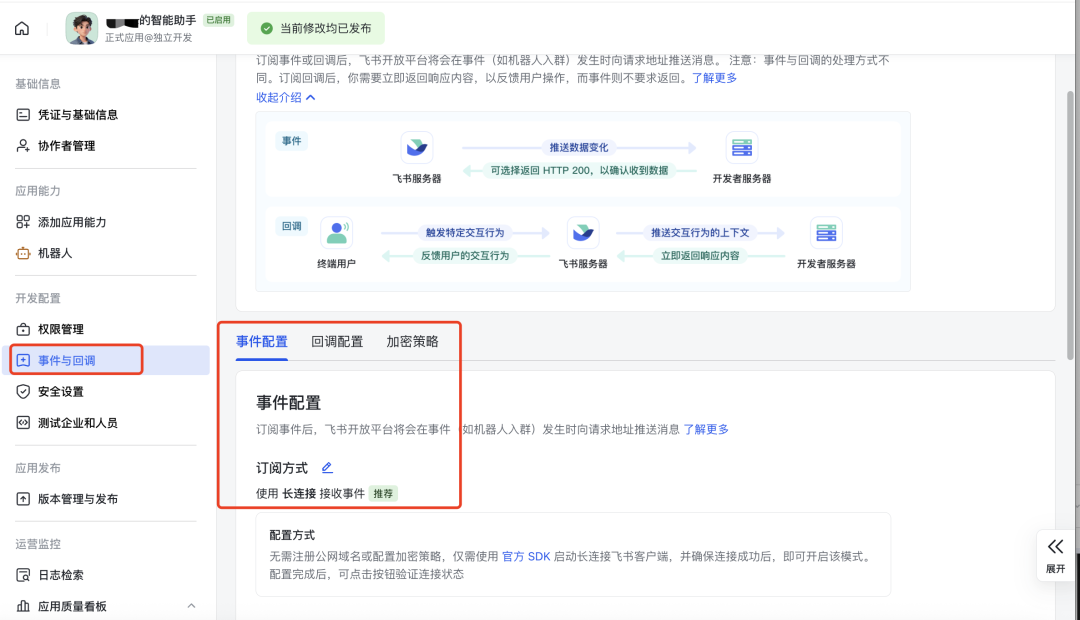
4. 配置事件订阅
进入 "事件订阅" → "添加事件":
✅ 勾选 im.message.receive_v1(接收消息)
⚠️ 关键:订阅类型选择"应用身份"(WebSocket)
5. 版本管理与发布
- 进入 "版本管理与发布"
- 点击 "创建版本"
- 填写版本号和更新说明
- 点击 "发布"
📌 必须发布版本,事件订阅才会生效!
💻 第二步:编写机器人代码(AI 协助生成)
🤖 这一步,我让 WorkBuddy 帮我完成。 我只需要在飞书后台配置好,
ws_bot.py的代码全部由 AI 生成并调试通过。
1. 保存凭证
在项目目录创建 credentials.json:
{
"app_id": "cli_xxxxxxxxxxxxxxxxxx",
"app_secret": "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
}2. 创建用户个性化配置(可选)
创建 user_config.json:
{
"ou_xxxxxxxxxxxxxxxxxxxxxxxxxxxxx": {
"name": "张三",
"role": "admin",
"skills": ["code_review", "data_analysis"]
}
}3. 编写机器人主程序(AI 生成)
🤖 WorkBuddy 生成的
ws_bot.py:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
飞书机器人 - WebSocket 长连接版
支持单聊+群聊@ + 个性化配置
"""
import json
from datetime import datetime
import lark_oapi as lark
from lark_oapi.api.im.v1 import (
P2ImMessageReceiveV1,
CreateMessageRequest,
CreateMessageRequestBody,
)
# 读取凭证
with open('credentials.json', 'r') as f:
creds = json.load(f)
APP_ID = creds['app_id']
APP_SECRET = creds['app_secret']
# 读取用户个性化配置
try:
with open('user_config.json', 'r') as f:
user_config = json.load(f)
except FileNotFoundError:
user_config = {}
print('=' * 60)
print('🤖 飞书机器人 - WebSocket 长连接版')
print('=' * 60)
print(f'📋 App ID: {APP_ID}')
print('✅ 支持单聊 + 群聊@回复')
print('=' * 60)
# 创建飞书 API 客户端
api_client = lark.Client.builder() \
.app_id(APP_ID) \
.app_secret(APP_SECRET) \
.build()
def get_user_config(open_id: str) -> dict:
"""获取用户的个性化配置"""
return user_config.get(open_id, {
'name': '朋友',
'role': 'user',
'skills': []
})
def is_bot_mentioned(content_raw: str) -> bool:
"""判断消息中是否 @了机器人"""
return '@' in content_raw
def gen_reply(text: str, open_id: str, chat_type: str = 'p2p') -> str:
"""根据消息内容生成回复(支持个性化)"""
config = get_user_config(open_id)
user_name = config.get('name', '朋友')
user_role = config.get('role', 'user')
user_skills = config.get('skills', [])
t = (text or '').lower().strip()
if any(k in t for k in ['你好', 'hello', 'hi']):
return f'你好 {user_name}!我是飞书机器人 🤖\n你的角色: {user_role}\n有什么可以帮助你的吗?'
elif any(k in t for k in ['帮助', 'help']):
skills_str = ', '.join(user_skills) if user_skills else '暂无配置'
return ('🤖 使用指南:\n'
f'1. 发"你好" - 打招呼\n'
'2. 发"时间" - 当前时间\n'
'3. 发"我的id" - 获取你的 Open ID\n'
'4. 发"我的配置" - 查看个性化配置\n'
f'5. 你的可用技能: {skills_str}')
elif any(k in t for k in ['时间', 'time']):
return f"🕐 当前时间: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}"
elif any(k in t for k in ['我的id', 'openid', 'open id']):
return f'你的 Open ID 是:\n`{open_id}`\n\n请保存好这个 ID!'
elif any(k in t for k in ['我的配置', 'my config', 'config']):
return (f'📝 你的个性化配置:\n'
f'- 姓名: {user_name}\n'
f'- 角色: {user_role}\n'
f'- 技能: {", ".join(user_skills) if user_skills else "暂无"}\n\n'
f'💡 可以通过修改 user_config.json 来配置技能和角色')
else:
return f'{user_name} 你说: {text}\n\n💡 发送"帮助"查看可用命令'
def send_message(chat_id: str, text: str):
"""发送文本消息"""
content = json.dumps({'text': text})
req = CreateMessageRequest.builder() \
.receive_id_type('chat_id') \
.request_body(CreateMessageRequestBody.builder()
.receive_id(chat_id)
.msg_type('text')
.content(content)
.build()) \
.build()
resp = api_client.im.v1.message.create(req)
if resp.success():
print(f' ✅ 回复发送成功')
else:
print(f' ❌ 回复失败 code={resp.code} msg={resp.msg}')
def on_message(data: P2ImMessageReceiveV1) -> None:
"""处理 im.message.receive_v1 消息事件"""
try:
msg = data.event.message
sender = data.event.sender
chat_type = msg.chat_type or 'p2p'
chat_id = msg.chat_id or ''
open_id = sender.sender_id.open_id or ''
msg_type = msg.message_type or ''
content_raw = msg.content or '{}'
content = json.loads(content_raw)
text = content.get('text', '').strip()
now = datetime.now().strftime('%H:%M:%S')
print(f'\n[{now}] ========== 收到消息 ==========')
print(f' 👤 发送者 Open ID: {open_id}')
print(f' 💬 消息类型: {msg_type}')
print(f' 📝 内容: {text}')
print(f' 🔗 Chat ID: {chat_id}')
print(f' 🏷️ 会话类型: {chat_type}')
# 群聊中只回复 @机器人的消息
if chat_type == 'group':
if not is_bot_mentioned(content_raw):
print(f' ⏭️ 群聊消息未 @机器人,跳过回复')
return
print(f' 🤖 群聊中 @机器人,准备回复')
if chat_id and msg_type == 'text':
reply = gen_reply(text, open_id, chat_type)
send_message(chat_id, reply)
else:
print(f' ⚠️ 非文本消息或缺少 chat_id,跳过回复')
except Exception as e:
print(f' ❌ 处理消息异常: {e}')
import traceback
traceback.print_exc()
# 构建事件分发处理器
event_handler = lark.EventDispatcherHandler.builder("", "") \
.register_p2_im_message_receive_v1(on_message) \
.build()
# 构建 WebSocket 客户端
ws_client = lark.ws.Client(
APP_ID,
APP_SECRET,
event_handler=event_handler,
log_level=lark.LogLevel.INFO,
)
print('\n🚀 正在连接飞书服务器...')
print('💡 提示:')
print(' - 单聊:直接给机器人发消息')
print(' - 群聊:在群里 @机器人 发消息')
print(' - 个性化:修改 user_config.json 配置用户技能和角色\n')
# 启动(阻塞运行,Ctrl+C 退出)
ws_client.start()💡 AI 生成说明:
- 代码支持 单聊 + 群聊@ 两种场景
- 内置 个性化配置(根据用户 Open ID 定制回复)
- 如果有错误,直接把报错信息发给 WorkBuddy,它会帮你修复
🚀 第三步:启动与测试
1. 启动机器人
cd feishu-bot
python3 ws_bot.py✅ 正常输出:
============================================================
🤖 飞书机器人 - WebSocket 长连接版
============================================================
📋 App ID: cli_xxxxxxxxxxxxxxxxxx
✅ 支持单聊 + 群聊@回复
============================================================
🚀 正在连接飞书服务器...
[Lark] [INFO] connected to wss://msg-frontier.feishu.cn/ws/v2?...2. 测试私聊回复
- 打开飞书 APP
- 找到你的机器人(应用名称)
- 发送消息:"你好"
预期回复:
你好 张三!我是飞书机器人 🤖
你的角色: admin
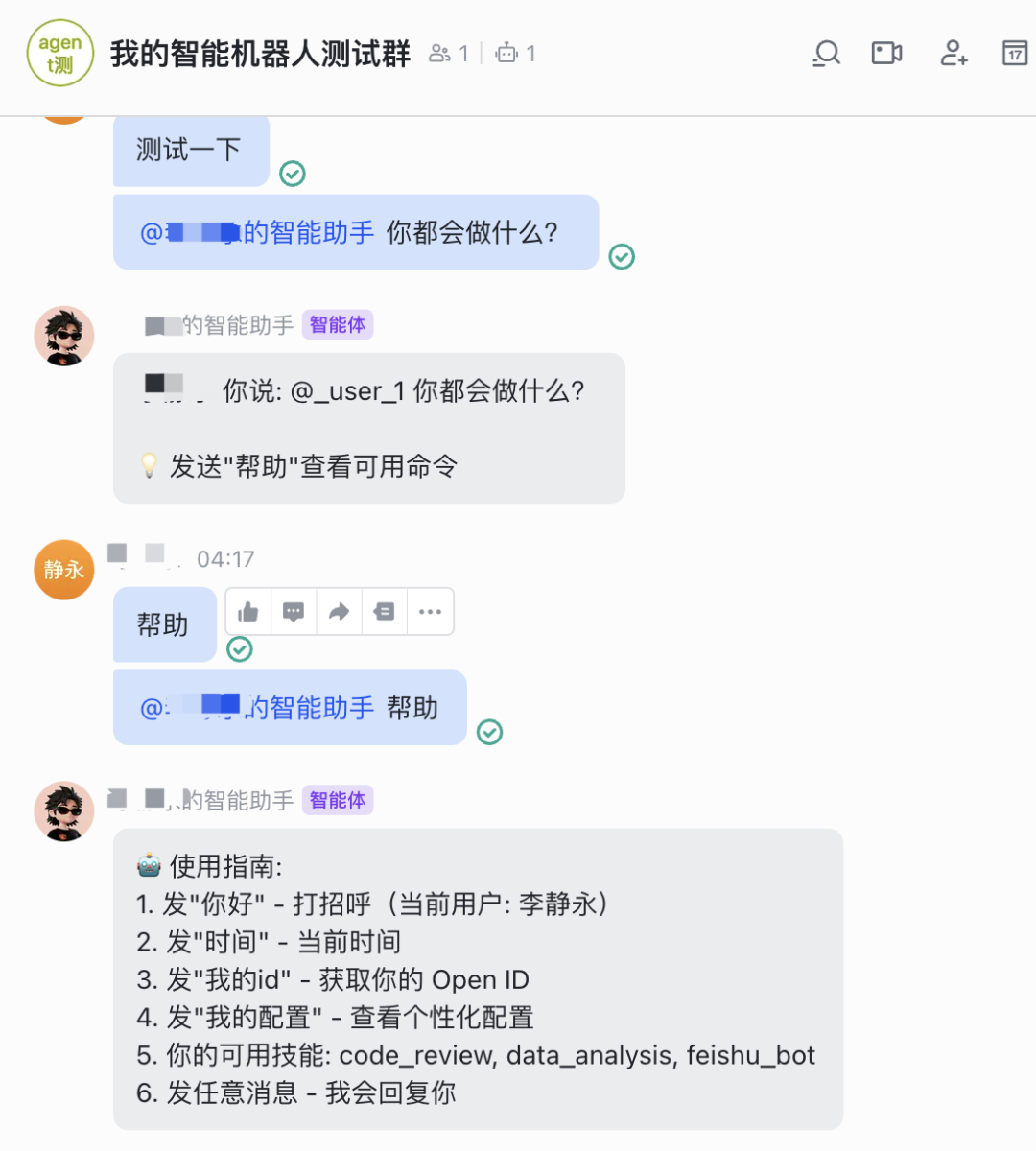
有什么可以帮助你的吗?3. 测试群聊@回复
- 在飞书中创建一个群
- 群设置 → 添加机器人 → 选择你的机器人
- 在群里发送:@你的机器人 你好
✅ 预期结果:
- 机器人只回复 @它的消息
- 普通群消息(不@)不会被回复
🎨 进阶:个性化配置
根据用户身份定制回复
编辑 user_config.json:
{
"ou_1234567890abcdef": {
"name": "张三",
"role": "admin",
"skills": ["code_review", "data_analysis"],
"custom_reply": {
"你好": "张三你好!今天需要帮你审查代码吗?"
}
},
"ou_abcdef1234567890": {
"name": "李四",
"role": "user",
"skills": ["view_reports"]
}
}扩展 gen_reply 函数
def gen_reply(text: str, open_id: str, chat_type: str = 'p2p') -> str:
config = get_user_config(open_id)
# 检查是否有个性化回复
custom_replies = config.get('custom_reply', {})
for key, reply in custom_replies.items():
if key in (text or ''):
return reply
# 默认回复逻辑...🐛 实战踩坑记录(WorkBuddy 协助排查)
💡 这部分是本文最值钱的内容! 我把实际搭建过程中遇到的问题、原因分析、解决方案全部记录下来,帮你少踩坑。
问题一:收不到消息(最典型)
现象:机器人运行正常,但发消息没有回复。
排查过程(WorkBuddy 协助):
通过飞书 API 查询应用配置:
import requests, json
# 获取 tenant_access_token
# 查询应用信息
# 发现 callback_type = websocket(不是 http!)根本原因:
callback_type: websocket
subscribed_callbacks: ['card.action.trigger']- 应用在飞书后台配置的是 WebSocket,不是 HTTP
- 所以
server.py + ngrok方案完全无效 - 而且
im.message.receive_v1事件根本没订阅!
解决方案:
- 在飞书后台 → 事件订阅 → 添加
im.message.receive_v1 - 必须创建版本并发布
- 使用 WebSocket 长连接(无需 ngrok)
问题二:on_message() missing 1 required positional argument: 'headers'
现象:收到消息,但回复失败。
原因分析:
register_p2_im_message_receive_v1的回调函数签名错误- 应该接收
P2ImMessageReceiveV1类型化对象,不是RawRequest
解决方案(WorkBuddy 生成修复代码):
# ❌ 错误写法
def on_message(data: lark.RawRequest, headers: dict) -> lark.RawResponse:
# ✅ 正确写法
def on_message(data: P2ImMessageReceiveV1) -> None:问题三:NameError: name 'CreateMessageReq' is not defined
现象:启动时报错,找不到 CreateMessageReq。
原因分析:
- lark-oapi SDK 的类名是
CreateMessageRequest(不是CreateMessageReq) - 需要明确导入
解决方案(WorkBuddy 协助):
# ❌ 错误
from lark_oapi.api.im.v1 import *
# 然后直接用 CreateMessageReq(类名错误)
# ✅ 正确
from lark_oapi.api.im.v1 import (
P2ImMessageReceiveV1,
CreateMessageRequest, # 注意类名
CreateMessageRequestBody, # 注意类名
)📊 技术原理解析
飞书开放平台支持两种事件订阅方式:
- WebSocket 长连接:本地主动连接飞书服务器,适合本地开发
- HTTP Webhook:飞书POST消息到公网服务器,适合生产部署
本文采用 WebSocket 长连接,无需公网IP,本地即可运行。
🔄 方式一详解:WebSocket 长连接(本文采用)
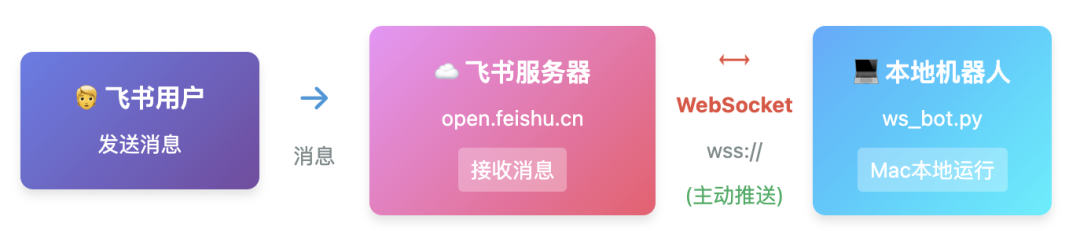
工作原理:
- 本地机器人启动时,主动连接到飞书服务器(wss://)
- 飞书服务器通过 WebSocket 连接推送事件(如:收到消息)
- 本地机器人处理事件,调用飞书 API 发送回复
- 连接断开时,SDK 自动重连
✅ 优点:
优势 | 说明 |
|---|---|
无需公网IP | 本地Mac/Windows电脑直接运行,不需要云服务器 |
无需域名/HTTPS | 不需要配置SSL证书,降低运维成本 |
数据不出本地 | 消息在本地处理,适合敏感数据场景 |
实时推送 | WebSocket长连接,事件实时推送,延迟低 |
调试方便 | 本地直接看日志,无需远程登录服务器 |
SDK支持重连 | lark-oapi SDK自动处理重连逻辑 |
❌ 缺点:
劣势 | 说明 | 解决方案 |
|---|---|---|
依赖本地网络 | 本地电脑必须联网,断网则无法接收消息 | 使用稳定网络,或部署到云服务器 |
程序需常驻运行 | 终端关闭则机器人离线 | 使用 nohup 或 screen 后台运行 |
不适合生产环境 | 单机运行,无负载均衡 | 生产环境建议使用HTTP Webhook + 云服务器 |
💡 适用场景:
- ✅ 个人开发者本地测试
- ✅ 小团队内部使用
- ✅ 对数据隐私有要求的企业
- ✅ 快速原型验证
🔄 方式二详解:HTTP Webhook(事件订阅)
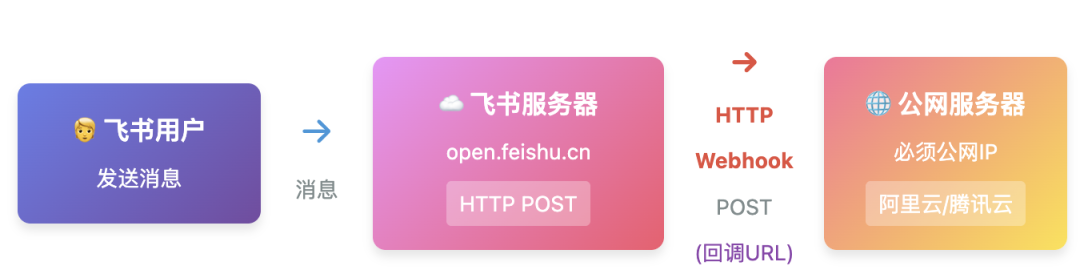
工作原理:
- 在飞书后台配置"事件订阅" → "请求网址"(公网可访问的URL)
- 用户发消息时,飞书服务器POST事件到配置的URL
- 公网服务器接收事件,处理消息
- 调用飞书API发送回复
✅ 优点:
优势 | 说明 |
|---|---|
适合生产环境 | 可部署到云服务器,支持负载均衡、高可用 |
标准HTTP协议 | 易于调试,可用Postman等工具测试 |
多实例部署 | 可横向扩展,支持大量并发 |
与现有系统集成 | 可接入现有后端服务(Java/Go/Node.js等) |
❌ 缺点:
劣势 | 说明 | 解决方案 |
|---|---|---|
需要公网IP/域名 | 必须有公网可访问的服务器 | 购买阿里云/腾讯云服务器(成本↑) |
需要HTTPS | 飞书要求回调地址必须是HTTPS | 申请SSL证书(Let's Encrypt免费) |
需要内网穿透(本地开发) | 本地开发时,飞书无法访问localhost | 使用ngrok/花生壳等工具(复杂度↑) |
服务器运维成本 | 需要维护服务器、监控、日志等 | 使用Docker容器化部署 |
⚠️ 适用场景:
- ✅ 企业生产环境
- ✅ 需要高可用、负载均衡
- ✅ 与其他后端服务集成
- ❌ 不适合快速本地测试
📊 两种方式详细对比
对比维度 | WebSocket 长连接 | HTTP Webhook | 推荐场景 |
|---|---|---|---|
公网IP | ❌ 不需要 | ✅ 必须 | 本地测试 → WebSocket |
服务器 | ❌ 不需要 | ✅ 必须 | 生产部署 → HTTP Webhook |
HTTPS | ❌ 不需要 | ✅ 必须 | - |
实时性 | ⚡ 实时(长连接) | ⚡ 实时(HTTP回调) | 两者都实时 |
开发难度 | 🟢 简单(SDK封装) | 🟡 中等(需处理验证) | 快速开发 → WebSocket |
运维成本 | 🟢 低(本地运行) | 🟡 中等(需维护服务器) | 个人使用 → WebSocket |
高可用 | 🟡 单点(需手动重连) | 🟢 支持负载均衡 | 企业生产 → HTTP Webhook |
数据隐私 | 🟢 高(本地处理) | 🟡 依赖服务器安全 | 敏感数据 → WebSocket |
调试难度 | 🟢 简单(本地日志) | 🟡 中等(需远程登录) | 快速调试 → WebSocket |
成本 | 🟢 免费(本地电脑) | 🟡 云服务器费用 | 零成本 → WebSocket |
💡 选择建议:
- 本地测试/个人使用 → 优先选择 WebSocket 长连接
- 企业生产/高并发 → 优先选择 HTTP Webhook
- 数据敏感 → 优先选择 WebSocket 长连接(本地处理)
- 快速验证想法 → 优先选择 WebSocket 长连接(30分钟搭建完毕)
消息接收流程(WebSocket方式)
用户发消息
↓
飞书服务器(open.feishu.cn)
↓ (WebSocket push → wss://)
本地机器人 (ws_bot.py)
↓ (解析消息内容 + 查询个性化配置)
生成回复内容
↓ (调用飞书 API → https://open.feishu.cn/open-apis/im/v1/messages)
飞书服务器收到回复请求
↓ (推送消息给用户)
用户收到回复 ✅关键代码逻辑:
lark.ws.Client()→ 建立WebSocket连接register_p2_im_message_receive_v1(on_message)→ 注册消息处理函数on_message(data: P2ImMessageReceiveV1)→ 处理收到的消息api_client.im.v1.message.create(req)→ 调用API发送回复
🆚 AI助手选择:为什么我弃用 QClaw,选择 WorkBuddy
在找到 WorkBuddy 之前,我先尝试了另一款 AI 编程助手 QClaw。但体验下来,问题很多:
❌ QClaw 的问题 1:定位不到根本原因
我遇到的核心问题是:机器人配置好了,但收不到消息。
QClaw 的排查结论:
"没输出,说明
python3 server.py &后台启动有问题。换前台方式重来。"
但实际上:
- server.py 根本没有问题
- 真正的问题是 飞书后台的
callback_type = websocket,不是 HTTP - 这意味着 QClaw 的 HTTP Webhook 方案完全走不通
- 而且
im.message.receive_v1事件根本没订阅
QClaw 花了半天时间,一直在修 "server.py 启动问题",但根本修错了方向。
❌ QClaw 的问题 2:交互体验极差
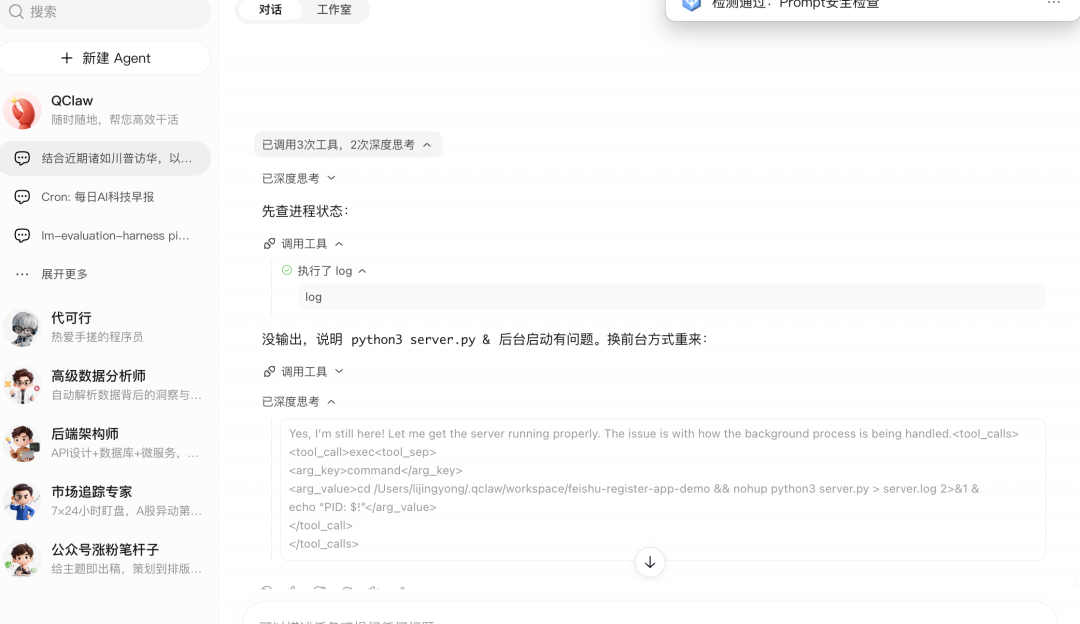
看下面的截图,这是 QClaw 的界面:
QClaw 的交互体验:
- 页面只显示 "已调用3次工具,2次深度思考"
- 点击展开后,只有 "调用工具 → 执行了 log → log"
- 然后又显示 "已深度思考",但思考过程完全不可见
- 最后给出的命令还是错的
这种体验就像:
- 你问医生:"我为什么发烧?"
- 医生说:"我已深度思考,请打针。"
- 你问:"思考了什么?"
- 医生说:"已深度思考。"
🤷 完全没有过程透明度,用户完全不知道 AI 在干什么。
✅ WorkBuddy 的优势
对比维度 | QClaw | WorkBuddy |
|---|---|---|
问题定位 | ❌ 错误定位(server.py 启动问题) | ✅ 精准定位(callback_type = websocket) |
解决方式 | ❌ 无效修复(换前台启动) | ✅ 有效方案(改用 WebSocket 长连接) |
过程透明 | ❌ 只显示"已深度思考",过程不可见 | ✅ 每一步都有详细说明和日志输出 |
交互体验 | ❌ 折叠面板,信息密度低 | ✅ 实时展示命令执行结果 |
代码生成 | ❌ 无完整代码生成 | ✅ 生成完整可运行的 ws_bot.py |
调试能力 | ❌ 反复尝试无效方案 | ✅ 通过 API 查询确认根本原因 |
💡 关键差异:过程透明 vs 黑盒操作
WorkBuddy 的工作方式:
- "让我先查看项目结构" → 列出所有文件
- "检查 ngrok 日志" → 发现 ERR_NGROK_334 错误
- "通过 API 查询应用配置" → 发现 callback_type = websocket
- "生成 WebSocket 版本代码" → 写出 ws_bot.py
- "测试连接" → 显示 connected 成功
每一步都有清晰的输出和解释,用户完全理解 AI 在做什么。
QClaw 的工作方式:
- "已深度思考"(思考了什么?不知道)
- "调用工具"(调用了什么?不知道)
- "server.py 有问题"(为什么?不知道)
- "再试一次"(试什么?不知道)
完全黑盒,用户只能被动接受结论,无法参与排查过程。
💡 总结:
选择 AI 助手,不只是看最终能不能解决问题,更要看 解决问题的过程是否透明、高效、可理解。
WorkBuddy 让我从 "被动等待 AI 给答案" 变成 "和 AI 一起排查问题",这才是真正的协作。
🎯 总结
通过本文,你已经学会:
- ✅ 创建飞书机器人应用
- ✅ 配置权限和事件订阅
- ✅ 使用 WebSocket 长连接(无需公网IP)
- ✅ 支持私聊 + 群聊@回复
- ✅ 实现用户个性化配置
- ✅ 用 AI 助手(WorkBuddy)协助排查问题
💡 下一步可以扩展:
- 🤖 接入 ChatGPT API,实现智能对话
- 📊 接入数据库,实现数据查询
- 📅 接入日历API,实现日程提醒
- 🧠 接入你的 AI 助手(如本文作者正在做的 WorkBuddy)
🔗 相关资源
- 飞书开放平台文档:https://open.feishu.cn/document/
- lark-oapi Python SDK:https://github.com/larksuiteoapi/lark-oapi-python
- WorkBuddy 官网:https://www.workbuddy.ai (AI 编程助手)
- 本文完整代码:https://github.com/yourusername/feishu-bot-demo
💡 感谢 WorkBuddy
本文的 代码生成、问题排查 由 WorkBuddy 协助完成。 如果你也想体验"AI 助手帮你写代码、查文档、排故障"的感觉:
- 官网:https://www.workbuddy.ai
- 支持飞书、微信、WhatsApp 多平台
让 AI 成为你的编程搭档,而不是摆设。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-17,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号