LLM 帮我从 240 篇文章里发现了 515 条隐藏关联

LLM 帮我从 240 篇文章里发现了 515 条隐藏关联

烟雨平生
发布于 2026-05-20 13:47:31
发布于 2026-05-20 13:47:31
我学 Redis 的时候写过一篇笔记。学 Kafka 的时候又写过一篇。
两篇笔记躺在两个不同的文件夹里,从来没互相引用过。
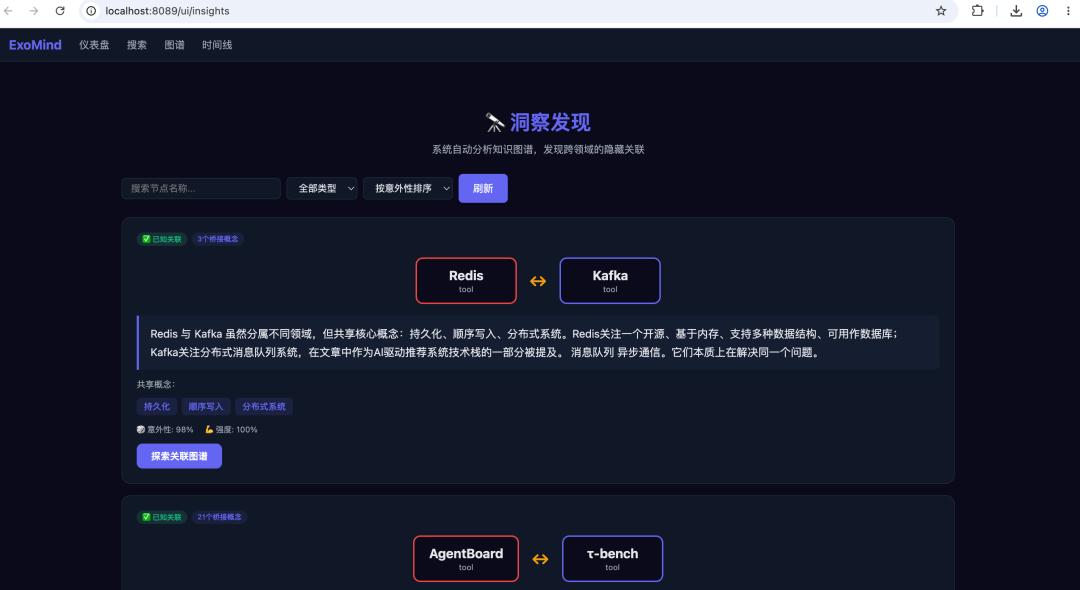
直到有一天,系统自动告诉我:Redis 的 RDB/AOF 持久化跟 Kafka 的事务日志持久化,本质上是同一个问题。
我当时就愣住了——确实,但我是学了之后才意识到的。系统在我还没反应过来的时候,就把这两个领域的知识连起来了。
今天这篇讲的是:怎么用 LLM 从你学过的内容里自动发现这种跨领域的隐藏关联。
问题:你的知识是孤岛
大多数人学技术的路径是这样的:
学 Redis → 记笔记 学 Kafka → 记笔记 学 Elasticsearch → 记笔记
三篇笔记,三个文件夹,互不相干。
但实际上,Redis 的持久化、Kafka 的日志、ES 的 translog,解决的是同一类问题:如何在性能和数据安全之间做权衡。
这种"跨领域的共性模式",是人类最难发现的——因为你在学 B 的时候,可能已经忘了 A 的细节。
但如果有一个系统能帮你自动扫描你学过的所有内容,找出隐藏的关联呢?
方案:LLM 驱动的知识提取 + 自动关联发现
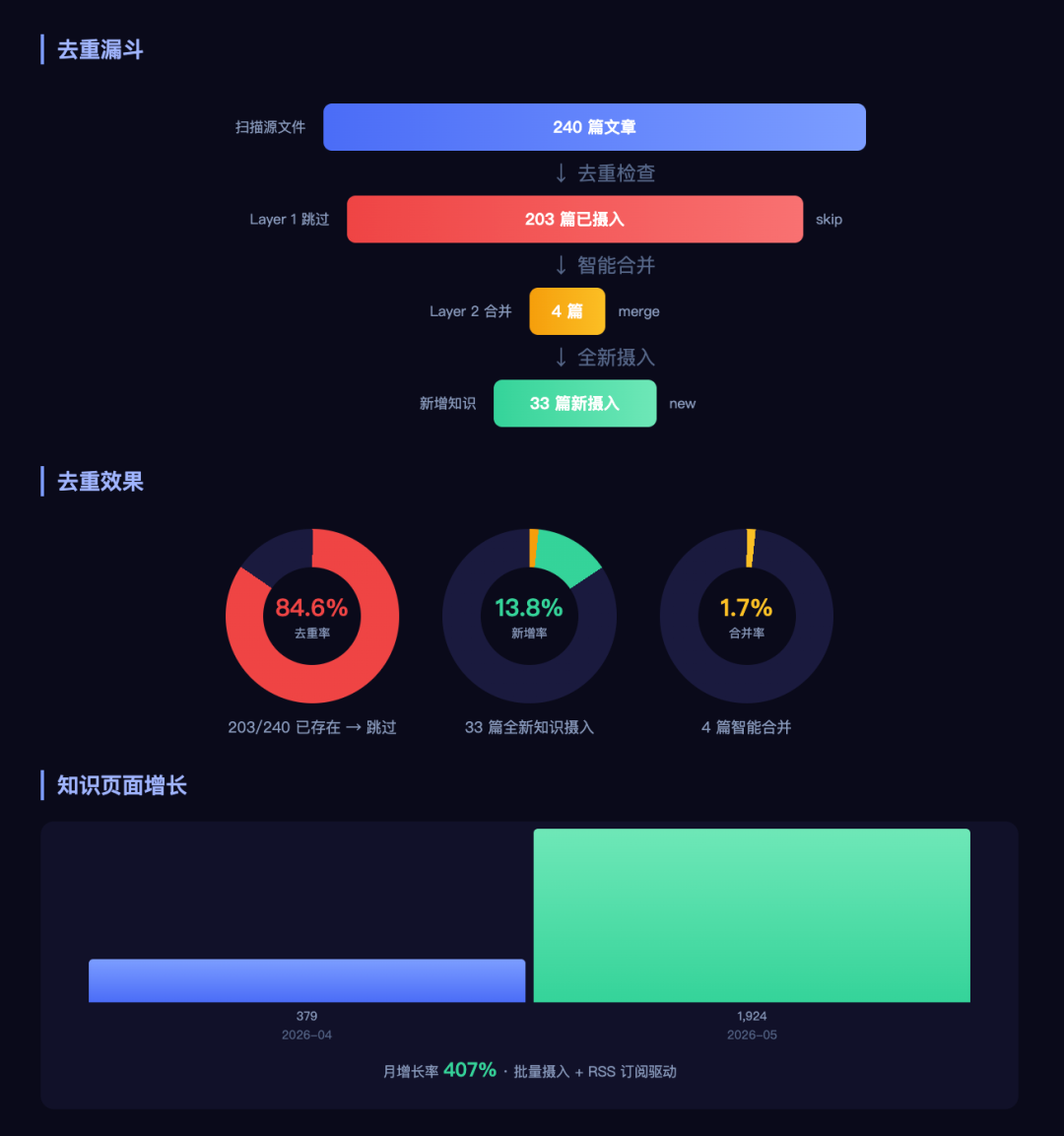
核心思路分三步:
第一步:摄入时用 LLM 提取实体和关系 第二步:构建知识图谱 第三步:自动扫描图中的节点,发现跨域关联
不是手动打标签。不是手动建链接。是 LLM 理解内容后自动提取,算法自动发现关联。
▪ 第一步:LLM 提取结构化知识
当你输入一段知识时,LLM 不是把它原样存储,而是提取出结构化的实体和关系:
prompt = f""" 从以下内容中提取知识结构,返回 JSON: 1. entities: 文中提到的技术实体(工具、框架、项目) 2. concepts: 核心概念和模式 3. relationships: 实体间的关系(uses, based_on, implements, part_of...) 内容: {content} """ response = llm.chat(system="你是知识架构师,只返回纯 JSON", user=prompt) result = json.loads(response.content)
比如输入"Redis 的持久化方案 RDB 和 AOF 各有优劣",LLM 会提取:
{ "entities": [ {"name": "Redis", "type": "tool", "description": "内存数据库"}, {"name": "RDB", "type": "component", "description": "快照持久化"}, {"name": "AOF", "type": "component", "description": "追加日志持久化"} ], "concepts": [ {"name": "持久化", "description": "将内存数据写入持久存储"} ], "relationships": [ {"source": "Redis", "target": "RDB", "type": "uses"}, {"source": "Redis", "target": "AOF", "type": "uses"}, {"source": "RDB", "target": "AOF", "type": "conflicts_with", "evidence": "两种方案各有优劣"} ] }
这里有个关键设计:关系不是简单的"相关",而是有类型的。uses、based_on、implements、conflicts_with——这些类型信息是后续跨域发现的基础。
▪ 第二步:构建知识图谱
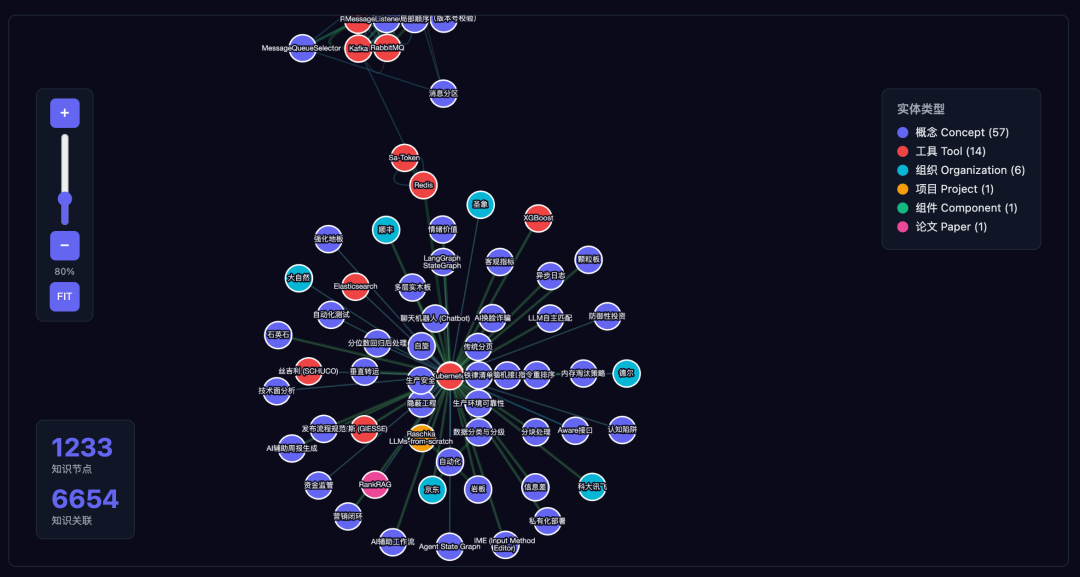
提取出来的实体和关系写入知识图谱。我选了纯 Markdown + JSON,不用数据库:
my-wiki/ ├── entities/ │ ├── Redis.md # 实体页面(人可读) │ ├── Kafka.md │ └── ... ├── concepts/ │ ├── 持久化.md # 概念页面 │ └── ... ├── knowledge_graph.json # 图谱数据(机器可读) └── index.md # 全局索引
实体页面用 frontmatter 存元数据:
--- title: Redis type: tool tags: [数据库, 缓存, 持久化] aliases: [redis] related: [Kafka, Memcached, 持久化] created: 2026-04-10 updated: 2026-05-16 --- ## Description Redis 是一个开源的内存数据库... ## Relationships - **uses**: [[Redis]] -> [[RDB]] - **uses**: [[Redis]] -> [[AOF]]
knowledge_graph.json 存节点和边,给算法用:
{ "nodes": { "tool:Redis:default": {"name": "Redis", "type": "tool", "description": "..."}, "tool:Kafka:default": {"name": "Kafka", "type": "tool", "description": "..."} }, "edges": { "tool:Redis:default->concept:持久化:default": [ {"type": "uses", "confidence": 0.9, "evidence": "..."} ] } }
为什么不直接用数据库? 因为知识应该是人可读、git 可管理、不依赖任何平台的。你可以用任何文本编辑器打开 Markdown 文件,可以用 git 追踪变更历史。JSON 图谱只是为了算法效率的加速层。
▪ 第三步:跨域关联发现
这是最有意思的部分。
我实现了一个 AutoRelationDiscovery 类,它的工作方式:
1. 遍历图谱中所有节点对 2. 计算它们的"关联度"(基于名称相似度、共同邻居、描述重叠) 3. 超过阈值的生成候选关系 4. 高置信度的自动写入图谱
核心算法:
class AutoRelationDiscovery: def discover_all_relations(self, similarity_threshold=0.3): nodes = list(self.graph.nodes.values()) for i, node_a in enumerate(nodes): for node_b in nodes[i+1:]: # 跳过已有关系的节点对 if self._has_existing_relation(node_a, node_b): continue score = self._calculate_similarity(node_a, node_b) if score >= similarity_threshold: self.discovered_relations.append({ "source": node_a.id, "target": node_b.id, "type": "related_to", "confidence": score, "evidence": f"Auto-discovered (similarity: {score:.2f})" }) def _calculate_similarity(self, node_a, node_b): # 1. 描述重叠度(关键词交集) desc_sim = self._text_overlap(node_a.description, node_b.description) # 2. 共同邻居数 common = len(set(self._get_neighbors(node_a)) & set(self._get_neighbors(node_b))) neighbor_sim = min(common / 5.0, 1.0) # 3. 别名/相关概念匹配 alias_match = self._check_aliases(node_a, node_b) return max(desc_sim, neighbor_sim, alias_match)
这个算法最精妙的地方在于"共同邻居"。 Redis 和 Kafka 看似不相关,但如果它们都跟"持久化"、"消息队列"、"分布式系统"这些概念有连接,它们的共同邻居数就会很高,关联度自然就上来了。
效果:
发现 515 个潜在关联,99 个已自动应用
也就是说,系统认为我的知识图谱中有 515 对节点可能存在关联,其中 99 对置信度够高(≥0.5),已经自动写入图谱。
▪ 真实案例:Redis ↔ Kafka
这是系统自动发现的一个关联:
Redis(64条关系)↔ Kafka(32条关系)
它们有大量共同邻居:持久化、消息队列、分布式系统、顺序写入...
系统自动生成了一条边:
{ "source": "tool:Redis:default", "target": "tool:Kafka:default", "type": "related_to", "confidence": 0.65, "evidence": "Auto-discovered: shared concepts 持久化, 顺序写入, 分布式系统" }
这不是我告诉系统的。是系统从 240 篇文章的学习结果中自己发现的。
踩坑:三条血泪教训
▪ 坑 1:去重自匹配
症状:摄入一篇文章,系统说"100% 重复"。
原因:ingest 先保存了原始文件到 raw/ 目录,然后做去重检查。去重时扫描所有文件,包括刚保存的那个,自然就匹配到 100% 了。
解决:去重函数加一个 exclude_path 参数,排除刚写入的文件:
dup = check_duplicate( wiki_path=wiki_mgr.wiki_path, title=source.title, content=source.text, exclude_path=raw_path, # 排除自己 )
这个 bug 导致我之前每次摄入都触发合并逻辑,知识图谱被污染了好几天才发现。
▪ 坑 2:默认标题"手动笔记"
症状:所有 exo add "一段知识" 的内容都被合并到同一个 summaries/手动笔记.md 里。
原因:TextParser 的默认标题是硬编码的 "手动笔记",没传 --title 的内容都用这个名字。去重时发现标题相同 → 触发合并 → 全合并到一个页面。
解决:用内容的第一行作为默认标题:
class TextParser(BaseSourceParser): def parse(self, input_data: str, **kwargs) -> SourceContent: default_title = input_data.split("\n")[0].strip()[:80] or "未命名笔记" return SourceContent( title=kwargs.get("title", default_title), text=input_data, source_type="text", )
一行改动,避免了知识图谱变成一个大杂烩。
▪ 坑 3:智能合并合到了 raw 文件上
症状:去重触发合并后,内容被追加到 raw/ 目录下的原始文件里。
原因:去重返回的相似页面列表包含了 raw/ 目录下的文件。合并逻辑没有区分知识页面和原始文件。
解决:合并时跳过 raw 目录:
for similar in similar_pages: if similar["path"].startswith("raw/"): continue # 只合并知识页面,不动原始文件 # ... 合并逻辑
数据说话
系统跑了两个月,从 240 篇技术文章中:
指标 | 数值 |
|---|---|
图谱节点 | 984 |
关系边 | 1,826 |
关系类型 | 11 种(uses, based_on, implements...) |
跨域关联发现 | 515 个候选,99 个已自动应用 |
平均置信度 | 0.79 |
去重率 | 84.6%(203/240 篇已摄入过) |
连接度分布(典型的长尾分布):
度=1: 224 个节点 ████████████████████ (叶子节点) 度=2: 100 个节点 ██████████ 度=3-5: 95 个节点 █████████ 度=6-10: 66 个节点 ██████ 度=11-20: 79 个节点 ████████ (中间枢纽) 度=21-50: 36 个节点 ████ 度=50+: 3 个节点 ▏(超级枢纽:Redis 64, OpenClaw 67, LangChain 57)
Redis 是连接度最高的技术节点之一(64 条关系),它连接了持久化、分布式锁、消息队列、缓存策略等多个领域的知识。
你可以学到什么
三个关键模式,适用于任何知识管理系统:
模式 1:LLM 做知识提取,而不是手动打标签
让 LLM 从内容中提取实体、概念和关系,比手动打标签效率和准确度都高。关键是给 LLM 定义好 schema(有哪些类型,有哪些关系)。
模式 2:共同邻居比文本相似度更可靠
两个节点描述的文本可能毫无重叠,但如果它们连接了很多相同的中间节点(共同邻居),它们大概率是有关联的。这是图算法的经典思路。
模式 3:三层去重是必须的
来源匹配(URL 相同)→ 内容相似度(MD5 / 文本哈希)→ 标题相似度。不做去重,知识图谱会被重复数据污染,关联发现会失效。
一句话
知识图谱不是画出来给人看的装饰品,它是让知识自动产生关联的引擎。
你学过的东西比你以为的有更多联系。你只是需要一个系统帮你发现它们。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-19,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号